では、今回は今まで見てきたモデルを中心に、自然言語処理の発展の歴史を確認していきたいと思います。
最近話題のBERTやその発展形であるXLNetなども歴史を追っていくと、どこがどうすごいのか、どういった経緯で考え出されたアイデアなのかということがわかり、より理解が深まると思います。
ニューラルネットワークによる自然言語処理の前知識
まず、直接的にニューラルネットワークを使った自然言語処理ではありませんが、非常に大きな影響を与えたモデルや考え方を予め説明しておきます。
時系列データ処理としての再帰的ニューラルネットワーク(Recurrent Neural Network; RNN)の誕生 - 1997年
時系列データにおいて将来の数値を予測するためのモデルとしてRNN(Recurrent Neural Network)というものが提案されました。これは、インプットを時系列の過去データとして将来の数値を予測するもので、今でも様々な分野で使用されています。
ただし、シンプルなRNNでは、長い文章を取り扱えないという問題があったため、それに対応するために、LSTM(Long Short-Term Memory)やGRU(Gated Recurrent Unit)というより複雑なモデルが提案されてきました。
詳細はこちらの記事をご覧ください。

Bag-of-Wordsモデル
長い間、文書の分類や感情分析にはこのn-gramやBag-of-Wordsと呼ばれるモデルが用いられてきました。
文章や文書の単語の順番を考慮せず、すべての単語を袋(bag)の中に入れて、処理をすることからBag-of-Words名称になっています。例えば、文章の中で「キレイ」や「気持ちいい」などといった単語が多く出現し、その文章に付けられているラベルがポジティブであれば、こういった単語が多く出てくる文章はポジティブな文章であると学習します。
シンプルでわかりやすいことから、今でも問題設定によってはこのモデルが使われており、そこそこの精度を出すことが出来ます。

以下の記事では、実際の口コミ情報をネットから収集し、Bag-of-Wordsを使って簡単な分析をしていますので興味がある方は見ていただければと思います。

ニューラルネットワークを使った自然言語処理
~ BERTまで
ニューラルネットワークを使った言語モデル - 2003年
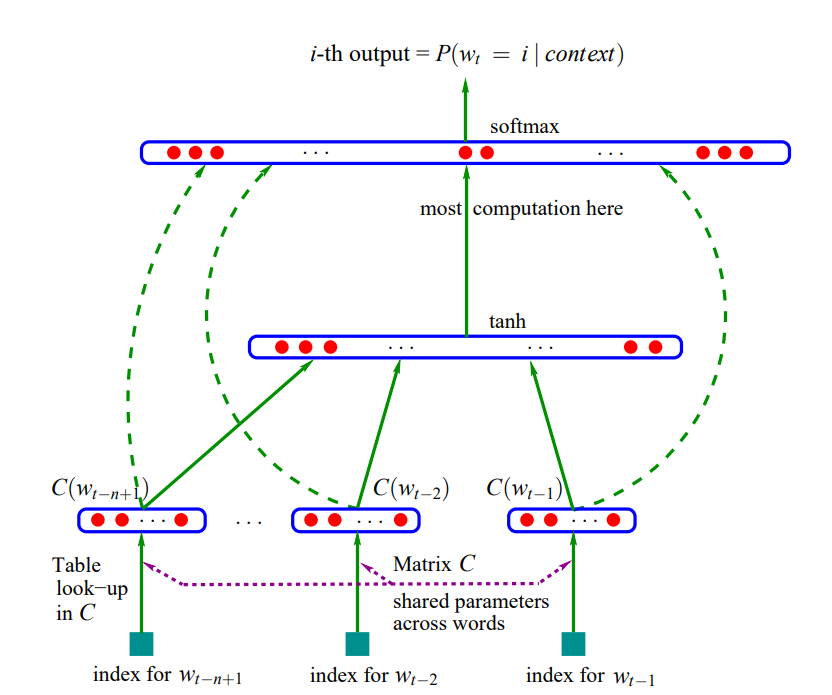
単語の出現頻度などではなく、単語自体をインプットとしたニューラルネットワークによる自然言語処理は、ディープ・ラーニング研究における第一人者であるYoshua Bengioが2003年に発表した論文“A Neural Probabilistic Language Model”が最初になります。
下の図のように、文章を単語に区切り、各単語のIDをインプットとしています。そしてそれをニューラルネットワークに投入します。ここでは、まだ文章が前から後ろへ流れていくという時系列の流れは考慮されていませんでした。
時系列モデルを使った言語モデル - 2010年~
n-gram、Bag-of-Wordsなどといった単語の並びを無視したモデルから一歩進み、文章を単語が順番に並ぶデータとして扱い、時系列のモデルを適用していきます。
再帰的ニューラルネットワーク(Recurrent Neural Network; RNN)を使ったモデル - 2010年
上記の、Bengioらによる通常のニューラルネットワークを使った言語モデルにはいくつか問題がありました。
一つは、文章というのはそれぞれ違う長さを持ちますが、それを固定長に区切らなければならなかったことです。
そしてもう一つは、文章では決まった場所に決まった単語が出てこないということです。どういうことかというと、テーブルデータなどを取り扱う通常のニューラルネットワークでは、特定の場所に特定の意味を持つ数値(特徴量)が与えられます。例えば、マンションの価格を予測する際に、1つ目の説明変数の値は広さを表し、2つ目の説明変数の値は築年数、3つ目の説明変数の値は駅からの距離、などといった具合です。そして、何番目の数字がどれだけ重要か?を学習させます。
しかしながら、文章はそうではありません。「昨日(1) 観た(2) 映画(3) は(4) 最高(5) でした(6)」では、5番目の「最高」という単語からポジティブな文章と判断できますが、「昨日(1) 映画館で(2) 観た(3) 映画(4) は(5) 最高(6) でした(7)」では、5番目の単語「は」は大きな意味を持ちません。
これらの2つを解決するために、Mikorovらが2010年に、時系列データの予測で利用されていた再帰的ニューラルネットワーク(Recurrent Neural Network; RNN)を使った言語モデルを提案しました。
詳細はこちらの記事で解説しています。
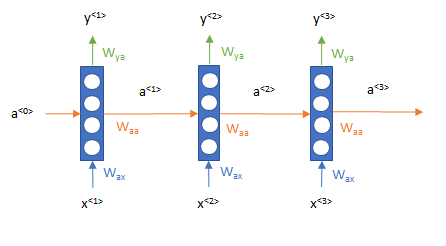
イメージで言うと、まず「昨日」という単語をインプットとして処理をし(下図\(x^{<1>}\))、そこから出てきた値(下図\(a^{<1>}\))と「観た(2)」という単語 (下図\(x^{<2>}\)) を次のインプットとして処理をし、さらに次は、その出力値(下図\(a^{<2>}\))と「映画(3)」(下図\(x^{<3>}\))をインプットとして順番に処理をしていきます。
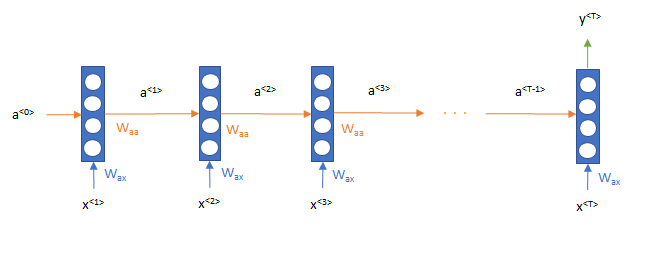
この仕組みにより文章を単語の時系列データと捉えたモデリングが可能になりました。
そこから数年間はこのRNNをベースにしたモデルが主流になります。
Long Short-Term Memory(LSTM)を使った言語モデル - 2014年
RNNを使った言語モデルは通常のニューラルネットワークを使った言語モデルよりも優れていましたが、RNNにはまだ大きな問題がありました。それが“勾配消失”や“勾配爆発”といった現象です。これは、自然言語処理に限った話ではなく、一般的な時系列データの取り扱いの問題です。
RNNでは長い文章を処理しようとすると、パラメータを更新するための勾配が爆発したり、消失してしまいパラメータを調整できないため、長い文章をうまく取り扱えませんでした。
その欠点を克服したのがLong Short-Term Memory(LSTM)です。LSTMというのはRNNにメモリーセルやリセットゲートなどの仕組みを導入して、長期の時系列データの取り扱いを可能にしたモデルです。すでに時系列モデルとして使われていましたが、それを自然言語処理に適用しました。
ここでは仕組みについて深くは説明しませんので、詳細は“再帰的ニューラル・ネットワーク(Recurrent Neural Network; RNN)を理解する”をご参照ください。
その後、通常のRNNはあまり使われずLSTMやGRUといった勾配消失や勾配爆発に対応し、長期の記憶ができるモデルが主流になっていきます。GRUはGated Recurrent Unitの略で、LSTMよりも若干シンプルな構造になっています。
Attentionメカニズムの導入 - 2015年
さて、かなり主流になったLSTMやGRUによる言語モデルですが、それでもまだ改善できる部分はあります。
LSTMやGRUでは各時点で1つの出力値(ベクトル)を次の時点に伝えるという処理を順番に行い、最終的には最後の出力値(ベクトル)のみを使って分類するといったことを行います。この場合、最後の1つのベクトルに過去のすべての情報が集約されますので、長い文章だと最終出力よりもはるか前にある情報は失われてしまいます。つまり遠い昔のの記憶は曖昧になってしまうのです。以下の論文によると最後の50単語は順番も含めてきちんと記憶していますが、それより前は存在は記憶しているものの順番は記憶していないことがわかっています。
https://arxiv.org/abs/1805.04623
ですので、各時点のアウトプットを処理するような畳み込みニューラルネットワーク(Convolutional Neural Network; CNN)と組み合わせたモデルも提案されていました。
もう一つの方法として、非常に画期的な手法が提案されました。これがAttentionメカニズムです。
Attentionメカニズムは、どこに注意を向けるか?ということをデータから学習するモデルです。もともとは翻訳用のモデルとして提案されたのですが、例えば、「I have a dog.」という英語を日本語に翻訳する際に、“I”なので「私(は)」、次の単語は“a dog”に注目して「犬(を)」、そして次の単語は、“have”に注目して「飼っています」という形で翻訳するように学習していきます。

Attentionメカニズムの面白いところは、以下のようにどこに注意を向けているか?を視覚的にプロットできるところです。以下は英語をフランス語に翻訳する問題ですが、白い部分が大きな注意を向けている部分です。例えば“agreement”は“accord”という単語に注意を向けています。
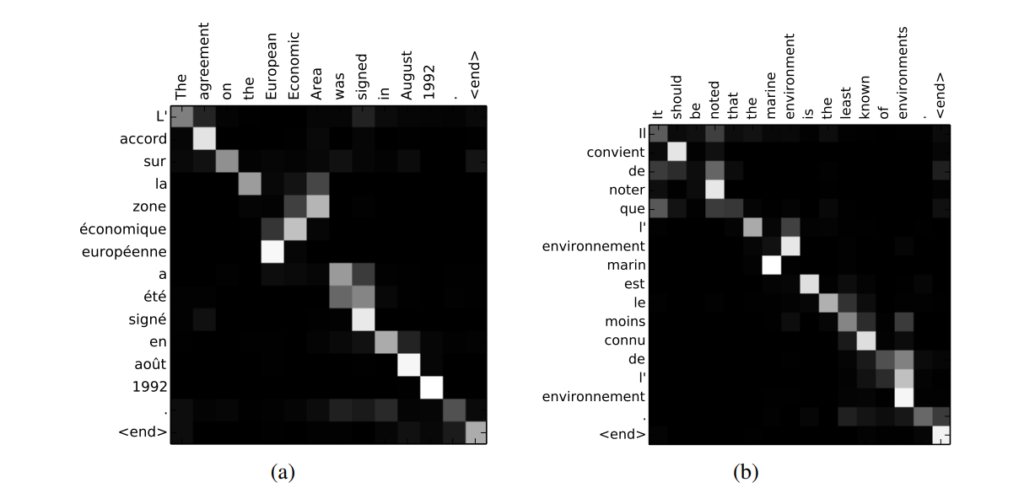
これはキャンプ場の口コミのポジティブ/ネガティブを評価する際にも使えます。これは悪い評価の例で、赤が濃いところがより大きく注意を払っている部分で、どこを見て悪いと判定しているか?がわかります。

この仕組みにより、長期の記憶ができるようになり、タスクの性能を向上させることができました。そして、このattentionメカニズムがBERTに繋がるブレイクスルーの要因の一つになります。
脱RNN ~ Transformer - 2017年
2010年以降、言語モデルの主流は時系列データを得意とするRNNでしたが、それがTransformerの出現により一気に変わっていきます。
なぜTransformerというモデルが出現したかというと、RNNは処理が遅いという欠点があったことです。RNNでは、一つの時点の処理を行って次に伝え、次の時点の処理をしてまた次に伝えてという形で、順番に処理を行う必要があるため、前の時点の処理を待つ必要があり、同時に処理をすることができません。そのためGPUの能力をフルで使うことができなかったのです。
そこで、Transformerが“Attention is All You Need”という論文で提案され、それはタイトルの通り、RNN(再帰的ニューラルネットワーク)やCNN(畳み込みニューラルネットワーク)は使わず、Attentionメカニズムだけを使うモデルでした。これにより、GPUをフルで使うことが可能になり、処理の速度を大幅に向上させ、大きなモデルを学習することが可能になりました。

Transformerは、positional encodingという手法で、単語の埋め込み表現(単語の意味を表すベクトル)に単語の“位置情報”を付加します。これにより、RNNを使わなくても単語が順序を持っていることを認識させることが可能になります。
そして、attentionメカニズム、特に自分自身に注意を向けるself-attentionという仕組みを使ったニューラルネットワークで、各時点の単語を同時に処理をすることにより高速に処理をできるようにしました。
事前学習(pretraining) & ファインチューニング(fine-tuning) - 2015年
Transformerから若干時代は遡りますが、2015年の論文で非常に重要なアイデアが提案されていました。それが転移学習と呼ばれる手法で、事前学習-ファインチューニングというステップを踏むというものです。転移学習自体は画像処理などの分野では当たり前になっていましたが、それを自然言語処理にも応用するというものでした。

まず、根本的な問題として、例えばセンチメント分析をするにも、ラベル付きのデータが少ないという問題があります。例えば、映画の評価をしているデータセットも高々数万件程度しかなかったりします。実務でも数千件程度しかないという場合もよくあると思います。そういった場合は、少量の文章だけ読んで、センチメントがポジティブかネガティブかを学習するのですが、少量ではどこが重要かわからず、どうしても学習データにオーバーフィッティングしてしまいます。
そこで、解きたいタスクの前にまず言語モデルを学習するという事前学習ステップを導入します。事前学習は、例えば、文章を初めから読んで、次の単語をどんどん予測するというようなタスクを解くことで行います。これにより、単語の出現傾向、つまり文章の構造を学習することができるのです。そして重要なのは、この事前学習にはラベルデータが必要がありません。単に文章をたくさん読ませればよいのです。
そして、ファインチューニングのステップで実際のラベルデータを使って、解きたいタスクに合わせて調整します。
つまり、今までは予測したいタスクの文章だけを読んで、正解ラベルを説明できるような特徴をひたすら探していたのに対し、事前学習-ファインチューニングでは、まずWikipediaなどで大量の文章を読み、文章の構造を理解した上で、予測したいタスクの文章を読んで、その文章のラベルを予測します。
実際のデータで検証してみた結果が以下です。ラベル付きデータを3000件に絞って実験しています。確かに事前学習していない場合はオーバーフィッティングが激しいですが(青の実践)、事前学習-ファインチューニングをした場合(緑の実践)ではほとんどオーバーフィッティングしていません。(この実験ではラベルなしデータは使用せず、ラベル付きデータの文章で事前学習し、その後ファインチューニングしています)。
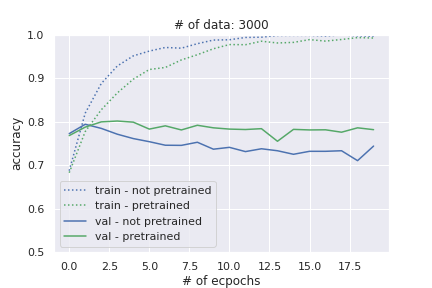
詳細は以下の記事をご参照ください。

そして、この事前学習-ファインチューニングという考え方が、モデルの発展と合わさり、非常に大きな成果につながっていきます。
Transoformerと事前学習-ファインチューニングの合わせ技 - 2018年
前述の2017年のTransformerというモデルと、2015年の大量のラベルなしデータによる事前学習-ファインチューニングという処理が合わさり、強力なモデルが出来上がります。それがOpenAI GPTとBERTです。
ちなみに2018年は他にもULMFiTやELMoという重要なモデルが提案されているので、そちらを読んでみるのも面白いと思います。

OpenAI GPT ~ Transformer & Fine-tuning - 2018年
前述のTransformerをベースにし、BooksCorpusという大量のラベルなしデータにより事前学習を行っています。それにより、特定のタスクだけではなく汎用的で強力なモデルになっています。
詳細は以下の記事をご参照ください。

BERT ~ 双方向Transformer & Fine-tuning - 2018年
BERTも基本的には、Transformerの仕組みに事前学習-ファインチューニングのステップを導入したものになります。ただし、Transformer + 事前学習-ファインチューニングは前述のOpenAI GPTで既に行われていました。
それとはどこが違うかというと、事前学習に工夫をし、“Masked Language Model”というタスクを学習することでTransformerを双方向にしたことと、そして事前学習に“Next Sentence Predction”という、ある文章が前の文章の続きかどうかを予測するタスクを加えたことにより、文章間の関係を学習させたことです。
OpenAI GPTのTransformerの事前学習は、文章を読んで次の単語を予測する、というタスクを解いていました。つまり、文章を左から右にしか読んでいない、単方向のモデルでした。それをBERTでは、文章中のいくつかの単語をマスキングし、そのマスキングされた単語を予測するMasked Language Modelというタスクを課すことでTransformerを双方向にしたのです。
そして、このMasked Language ModelとNext Sentence PredictionというタスクをWikipediaやBooksCorpusという大量のデータを使って解くことにより、非常に汎用的で強力なモデルが構築されました。

BERT以降
BERT以降も引き続き発展してきていますが、基本的には考え方は大きく変わらず、大きなモデルを大量の文章を使って事前学習をしっかりとするというものです。モデルの方もTransformerが主流になっています。
Maked Language ModelからPermutation Language Modelへ
XLNet - 2019年
BERTは文章にマスクをし、そのマスクをされた単語を予測する事前学習Masked Language ModelによりTransformerを双方向にしましたが、この方法ではマスクされている単語間の依存関係が捉えられません。つまり、2つマスクされた単語があり、その単語同士に関連性があったとしてもそれを学習することができません。
そこで、マスクされた単語間の依存関係も捉えられるように改良されたのがXLNetです。XLNetでは“Permutation Language Modeling”という、単語の順番を変えて学習させることにより、マスクを使わず双方向の言語モデルを学習させました。
また、 2019年に提案されたTransformer-XLという、より長い文章の処理もうまくできるような仕組みも取り入れています。
そして、このXLNetはBERTの精度を上回ることになりました。

BERTに工夫を加えたモデル
BERTの仕組みを大きく変えるのではなく、BERTの設定を変えたり、少しパラメータの持ち方を工夫することにより精度をさらに改善させたモデルが提案されています。
RoBERTa - 2019年
RoBERTa(Robustly Optimized BERT Approach)はBERTの仕組みそのままで、より大量のデータを使って事前学習し、バッチサイズを大きくするなど設定を工夫することで、BERTの仕組みの持っている本来の力を発揮させることを可能にしました。

ALBERT - 2019年
ALBERT(A Lite BERT)も基本的にはBERTと同じ仕組みです。BERTのレイヤー数や隠れ層の次元をもっと増やして、より大きなモデルにできれば精度は向上するはずだが、メモリが限界にきているし、というのに対応しています。
複数のTransformerブロック間でパラメータを共有したりすることで、パラメータ数を劇的に減らし、必要なメモリを減らすことで、レイヤー数や隠れ層の次元を増やし、より大きなモデルの学習を可能にしました。

固有名詞の情報を学習するモデル
ERNIE
それ以外にも固有名詞の情報を事前学習で学習するERNIEといったモデルも提案されており、非常に面白くなっています。偶然のようですが、2つのERNIEがほぼ同時期に提案されています。
論文では、Bob Dylan(!)の例が挙げられており、今までは何の事前知識もなく学習していましたが、そこにBob DylanやBlowin' in the windといった固有名詞の情報を付加することによって、タスクの精度を上げようとするモデルです。
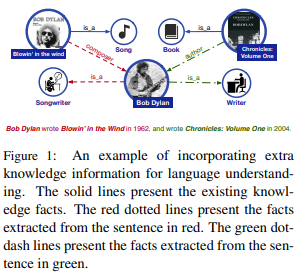

もう一つのERNIEは、固有名詞やフレーズをマスキングするEntity-Level maskingやPhrase-level maskingという事前学習を取り入れることによって、固有名詞などの情報をより理解することを目的としています。

まとめ
ニューラルネットワークによる自然言語処理の流れを一通り見てきました。
なるほどなぁと感心しつつも、後から見ると非常に自然な流れで発展しているように感じますね。
もちろん他にも重要な論文は多数ありますので、いつかまとめられればいいなと思っています。
引き続き色々な論文を読んでキャッチアップしていきたと思います!!