さて、今回はBERTの改良版であるERNIEについて解説したいと思います。
ERNIEというのは2種類あり、こちらが今回ご紹介する論文“ERNIE: Enhanced Language RepresentatioN with Informative Entities”です。
https://arxiv.org/abs/1905.07129
もう一つは、“ERNIE: Enhanced Representation through KNowledge IntEgration”という論文です。論文によると、偶然ほぼ同じタイミングで同じネーミングになったそうです。

目次
ERNIEとは
ERNIEとは、“Enhanced Language RepresentatioN with Informative Entities”の略で、簡単に言うと、固有名詞に関する知識を使うことにより、予測精度を改善させようというものです。
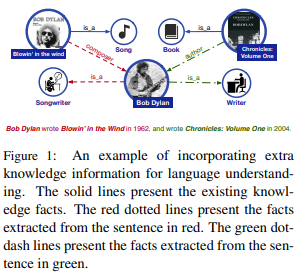
論文ではBob Dylanの例が挙げられています。
例えば、“Bob Dylan wrote Blowin' in the Wind. in 1962, and wrote Chronicles: Volume One in 2004.”という文章があったとします。
そして、Bob Dylanが何者か、といった情報をKnowledge Graphの形で別で与えることにより、knowledge-drivenのタスクをうまく解こうというものです。
では、モデルの仕組みについて見ていきましょう。
ERNIEの仕組み
まず大きな流れですが、ERNIEでは、インプットとして単語列とエンティティ情報を使います。エンティティ情報は、エンティティに関する説明などではなく、あらかじめ、埋め込み表現に変換されたものを使います。論文ではTransEというモデルを使っています。TransEの詳細については説明しませんが、(head, label, tail) 組をインプットとして、埋め込み表現を計算していくものです。headとtailがエンティティ、labelがそれらの関係を表します。興味がある方は、こちらの論文をご参照ください。非常にシンプルな方法です。
https://papers.nips.cc/paper/5071-translating-embeddings-for-modeling-multi-relational-data
そして、これら単語とエンティティという違う空間上にあるデータを同じ空間に移すことで処理をしてきます。
事前学習の方法もBERTを参考に作られていますが、ERNIEでは単語のマスクだけでなく、エンティティにもマスクをします。それにより、エンティティの情報を捉えることができるということです。もう一つのERNIE(Enhanced Representation through KNowledge IntEgration)でもエンティティをマスクしています。
では、詳細に移りたいと思います。
まず、ノーテーションの説明です。単語列を\(\{w_1, \cdots, w_n\}\)とします。そして、これらの単語に出てくる固有名詞の埋め込み表現を\(\{e_1, \cdots, e_m\}\)とします。\(m\le n\)となります。
ボキャブラリー全体を\(\mathcal{V}\)、エンティティ全体を\(\mathcal{E}\)とします。
全体図は以下の図です。左側が大まかな図になっており、インプットは単語列とエンティティの埋め込み表現です。そして、Transformer blockで単語列をエンコードし(T-Encoder)、その次にエンティティ情報をエンコードしたものをInformation Fusion層でまとめます(K-Encoder)。最後に、単語のとエンティティの埋め込み表現にまた分解し、次の層に送ります。右側がK-Encoderの詳細です。
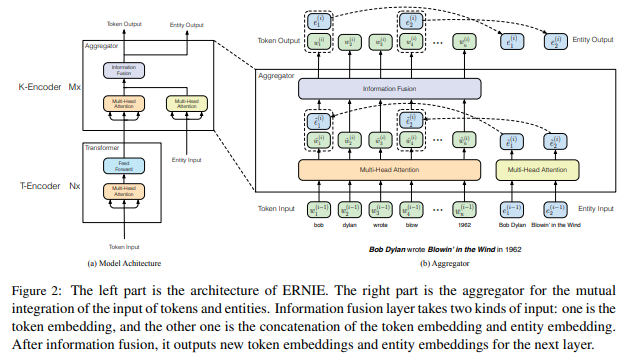
T-Encoder, K-Encoder
T-Encoderインプットは、単語列の\(w_1,\cdots,w_n\)です。これをTransformer blockでエンコードします。Transformer blockの詳細については、Transformerの記事を参照してください。

$$\{\hat{w}_1,\cdots, \hat{w} _n\} = \text{T-Encoder}(\{w_1, \cdots, w_n\})$$
これを\(N\)レイヤー繰り返します。
そして、アウトプットを次のK-Encoderに渡します。K-EncoderのインプットはT-EncoderのアウトプットとTransEであらかじめ学習されたエンティティの埋め込み表現\(\{e_1, \cdots, e_m\}\)です。
$$\{w_1^o, \cdots, w_n^o\}, \{e_1^o, \cdots, e_m^o\} = \text{K-Encoder}(\{w_1, \cdots, w_n\}\, \{e_1, \cdots, e_m\})$$
K-Encoderは上記の通り単語に関するインプットとエンティティに関するインプットの2種類を受け取ります。これをそのまま結合すると2種類の全く違う空間上のベクトルがくっつく形になってしまいますので、それはよくありません。
ですので、この2つをInfomation fusionという層で一度同じ空間に持ってきて結合し、その後またそれぞれの空間に戻してやるという操作をします。
まずは、それぞれをTransformerのMulti-head attention層を通します。
$$\begin{align}
\{\tilde{w}_1^{(i)}, \cdots, \tilde{w}_n^{(i)}\}&=\text{MH-ATT}(\{w_1^{(i-1)}, \cdots, w_n^{(i)}\}), \\
\{\tilde{e}_1^{(i)}, \cdots, \tilde{e}_n^{(i)}\}&=\text{MH-ATT}(\{e_1^{(i-1)}, \cdots, e_n^{(i)}\}),
\end{align}$$
それから、単語\(w_j\)に対応するエンティティ\(e_k\)が存在する場合、以下の式で一度一つのベクトルにします。
$$h_j=g\left(\tilde{W}_t^{(i)}\tilde{w}_j^{(i)} + \tilde{W}_e^{(i)}\tilde{e}_k^{(i)} +\tilde{b}^{(i)} \right)$$
\(g(\cdot)\)は活性化関数で以下のGELUを使っています。
$$\begin{align}
\text{GELU}(x)&=x\Phi(x)\\
&\sim0.5x\left(1+\tanh\left[\sqrt{2/\pi}\left(x+0.044715x^3\right)\right]\right)
\end{align}$$
そして、もう一度単語とエンティティのアウトプットに分けてやります。
$$\begin{align}
w_j^{(i)}&=g(W_t^{(i)}h_j+b_t^{(i)}), \\
e_k^{(i)}&=g(W_e^{(i)}h_j+b_e^{(i)})
\end{align}$$
対応するエンティティがない単語については、エンティティの情報は使わず、
$$\begin{align}
h_j&=g\left(\tilde{W}_t^{(i)}\tilde{w}_j^{(i)} + \tilde{b}^{(i)} \right), \\
w_j^{(i)}&=g(W_t^{(i)}h_j+b_t^{(i)})
\end{align}$$
でアウトプットを計算します。これを\(M\)回繰り返して、最終的なアウトプット\( \{w_1^o, \cdots, w_n^o\}\)と\(\{e_1^o, \cdots, e_m^o\} \)を計算します。
知識を使った事前学習
モデルの仕組みはできたので、ここから実際に言語モデルにエンティティに関する知識を入れていくように事前学習を行います。
まず、ERNIEでは3つの事前学習のタスクを解きます。二つはBERTで使われていたMasked LMとNext Sentence Predictionです。これについては説明しませんので、BERTの記事をご参照ください。
もう一つはERNIE特有のタスクで、dEA(Denoising Enttity Autoencoder)です。これは、まず、
- 5%は単語に対応するエンティティを違うエンティティに入れ替えます。
間違ったエンティティを正しくすることを学習します。 - 15%はエンティティをマスクします。
すべてのエンティティ情報を使わずに学習をするためです。 - 残りの80%はそのままです。
ちょっとわかりにくいですので図を描いてみると、こういうことかなと思います(違ったらすみません)。
entity IDをランダムに変える、マスクする、そのまま、として、マスク以外の部分(青色の網掛け部分)の情報を使いながら、その部分を予測するのかと思います(間違っていたらご指摘ください)。

予測の方法は、以下のようにK-Encoderの 単語に対応するアウトプット\(\{w_1^o,\cdots,w_n^o\}\)を線形変換し、それとエンティティの埋め込み表現をかける形で行います。
$$p(e_j|w_i)=\frac{\exp(\text{linear}(w_i^0)\cdot e_{j})}{\sum^m_{k=1} \exp(\text{linear}(w_i^0)\cdot e_{k}) }$$
dEA、Masked LM、NSPのそれぞれの損失を合計したものを損失とします。
ファインチューニング
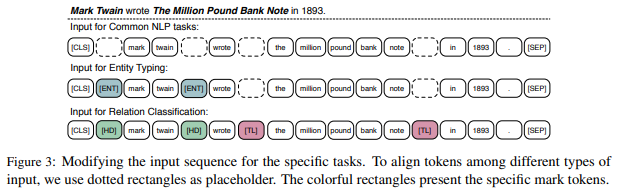
ファインチューニングは変わったところは特にありません。インプットはタスクによって以下の図のようにしています。
まず、文書分類などでは、文章の初めに[CLS]を付加します。これは、BERTなどでも行っている一般的な方法です。
エンティティの種類を予測するEntithi Typingでは、エンティティを[ENT]で囲んでやります。また、2つの特定されたエンティティ間の関係を予測するRelation Classificationについては、エンティティ名をそれぞれ[HD]と[TL]で囲むようにします。分類に使う隠れ層は、[CLS]に対応する箇所で変わりはありません。
実験
初期パラメータはBERTのパラメータを使用し、事前学習には、English Wikipediaを使います。そして、140Mエンティティの情報を使い、エンティティ数が3個以下の文章は除きます。
エンティティの埋め込み表現はWikipediaのデータを使って、TransEにより学習します。
そして、NSP(Next Sentence Prediction)、Masked Language Model(Masked LM)、denoising Entity Autoencoder(dEA)の3つのタスクを解くことで事前学習します。
ハイパーパラメータは、
- 単語の埋め込み表現の次元\(H_w\):768
- エンティティの埋め込み表現の次元 \(H_e\):100
- 単語のTransformer blockのattention head数 \(A_w\):12
- エンティティのTransformer blockのattention head数 \(A_e\) :4
- T-Encoderのレイヤー数 \(N\) :6
- K-Encoderのレイヤー数 \(M\) :6
- 文章の長さ:256
となっています。
事前学習のバッチサイズは512、ファインチューニングのバッチサイズは32です。ファインチューニングのAdamの学習率は\(5e-5, 3e-5, 2e-5\)、エポック数は3から10とタスクによって変えています。
ファインチューニングのデータセットはエンティティについてアノテーションされていないので、TAGMEというものを使ってエンティティを特定しています。
Entity Typing
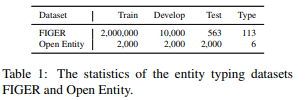
FIGERとOpen Entityというデータセットを使って検証しています。Entity Typingとは文章中のエンティティの種類を予測するタスクです。
各データセットの統計量は以下の通りです。Open EntityはFIGERと比べてかなり小さいデータセットになっています。
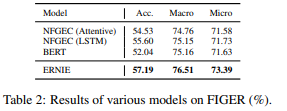
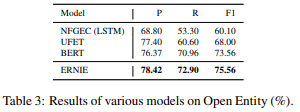
そして、結果は下表のようになっています。左側がFIGERデータセットで右側がOpen Entityデータセットです。両方ともBERTやそれ以外のモデルの結果を上回っていることがわかります。
BERTが他のモデルより精度(Acc)が劣っていますが、これはFIGERデータセットの学習データがdistant supervision(ざっくり言うと人手でアノテーションされたのではなく、knowledgeデータベースを使って予測されたもの)を用いて作成されており、テストデータは人手でアノテーションされていることから、BERTの強力な能力により、間違った学習データにも合わせてしまっている可能性があるとのことです。ERNIEでは、事前知識を使うことで、そういった間違った学習データに対しても、うまく対応できていることがわかります。
Relation Classification
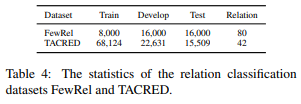
続いてRelation Classificationです。Relation Classificationは文章中の2つのエンティティの関係を予測するタスクです。FewRelというデータセットとTACREDという2つのデータセットを使って検証しています。
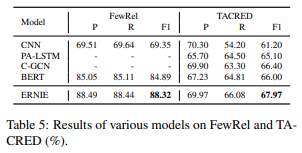
結果は下の図の通り、Precision、Recall、F1スコアすべてでBERTや他のモデルを超えています。BERTと同じ仕組みですので、この超えた分が外部知識を導入したことによる効果と考えられます。
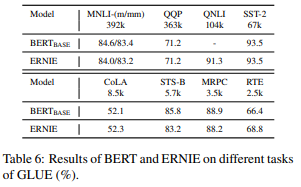
GLUEベンチマークを評価した結果は、データセットによって差はありますが、BERTとほぼ同じです。GLUEデータセットでは外部知識を使うメリットは大きくなさそうです。
まとめ
今回はエンティティに関する外部知識をBERTに注入したモデルERNIEの論文を読んでみました。個人的には、なかなか面白いと考えており、より実践的なアプリケーションにおいて使えるのではないかと思っています。
では、次回はALBERTを読んでみたいと思います!!