では、今回は2017年に論文「Attention Is All You Need」で提案された “Transformer” について詳しく解説したいと思います。
Transformer とは、ChatGPT (GPT-4 などのGPT シリーズ) を含む重要な LLM (Large Language Model; 大規模言語モデル) や、BERT などのファインチューニングをすることによって高い精度を得ることができるモデルなど、現在重要な自然言語処理モデルで幅広く使われている重要な仕組みです。
ですので、自然言語処理を学ぶ人、業務で LLM を使って開発する人などは是非押さえておきたいモデルです 。
モデルの構造は知っているので、どのように実装するかを知りたい、という方は以下の記事をご参照ください。
Tensorflowを使ってセンチメント分析用のTransformerを実装しています。

ご参考 - 参考書籍
こちらの本では PyTorch を使って Transformer と BERT のモデル部分を実装していますので、真似をしながら自分の手で実装することで、Transformer と BERT をしっかりと理解することができると思います。
Transformer や BERT が理解できれば、自然と GPT も理解できると思いますので、是非この本も参考に学んでいただければと思います。
自然言語処理については最後の方の一部だけですが、逆に言うと画像認識などの勉強もできて非常に参考になります。
PyTorch も学べるオススメの一冊です。
目次
Transformerとは
まず、重要なので非常にざっくりとした概要を言っておきます。
Transformer とは
計算速度向上のため、主流であった再帰的ニューラルネットワーク (RNN) を使わずに、Attention メカニズムを使って並列計算を可能にするモデル
こちらのイメージを押さえていただいた上で、もう少し細かい話をしたいと思います。
Transformer は機械翻訳のためのモデルとして提案されました。
その背景としては、2014年に提案された Attention メカニズムがあります。
その論文では、LSTM や GRU といった再帰的ニューラル・ネットワーク (RNN) をベースとして、長期の依存関係を捉えるメカニズムとして Attention メカニズムが提案されており、そのモデルは成功を収めました。
Attentionメカニズムについてはこちらの投稿をご参照ください。

しかしながら、RNN + Attention メカニズムの RNN の部分には問題がありました。
それは、実際に作ってみるとわかるのですが、RNN は計算時間が長いということです。
Seq2Seq、Encoder-Decoder と呼ばれる翻訳のモデルでは以下のような RNN の仕組みを使いますが、時点2の隠れ層の値 \(h^{<2>}\) を計算するためにはまず時点1の隠れ層 \(h^{<1>}\) を計算しなければならず、 時点3の隠れ層の値 \(h^{<3>}\) を計算するためには \(h^{<2>}\) を計算するという風に、前から順番に計算しなければなりません。
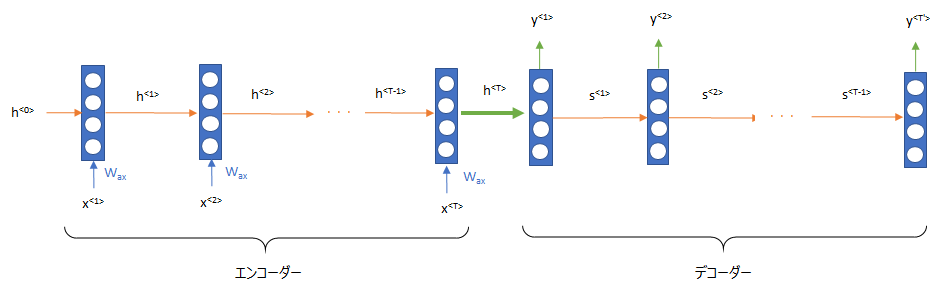
したがって、並列計算ができず、GPU などを使っても、その能力をフルに活用できないのです。
特に長い文章であればあるほど、時間はどんどん長くなってしまいます。
そこで、RNN を使わない仕組みである Transformer が考えられました。
この論文のタイトルは「Attention Is All You Need」ですが、これは文章の処理に従来の RNN や CNN はいらず attention だけがあれば十分である、という意味です。
この Transformer ではより少ない学習時間で精度の高いモデルが構築できるようになります。
そして実際、このあとに出てくる GPT や BERT といった非常に巨大な言語データを学習するモデルが出てきます。
また Attention はどこに注意を向けるか?を学習するので RNN や CNN に比べて非常に自由度の高いモデルであることから、大量のデータを学習することにより、さらに性能が向上するという特徴があることがわかってきます。
これが BERT はもちろんですが、ChatGPT に繋がっていきます。
一旦、ここまでの Transformer の特徴をまとめておきます。
Transformer の特徴
RNN を使わず、Attention のみを利用することで並列計算が可能になったことで、計算時間たの短縮が図れる。
それにより、大量のデータを学習することが可能になる。
Attention はどこに注意を向けるか?を学習するため、自由度が非常に高い。
大量データを学習することで、高精度なモデルができる
繰り返しになりますが、これらの特性により、ChatGPT のような大量の文書を学習した汎用性の非常に高いモデルの登場に繋がります。
それでは、RNN を使わずに、どのように自然言語を処理するモデルを作るのか、を見ていきたいと思います。
Transformerの仕組み
では、Transformerを 論文にしたがって説明していきます。
Transoformer の論文では GPT とは違い、翻訳タスクについて考えていますので、GPT の仕組みとは若干違います。
ただ、GPT の方がシンプルなのでこの論文を理解できていれば GPT の理解も簡単です。
ニューラル機械翻訳では、まず、インプットの単語の列から文章の埋め込み表現を計算し(エンコード)、それを別の言語の単語の列をアウトプットします(デコード)。
これを Transformer では、RNN を使わず、Self-Attention という仕組みを使って実現します。
Self-Attention とは、attention の実践のところで紹介しましたが、もともとの論文にあった 翻訳語の単語から翻訳前の単語に注意を向ける attention ではなく、自分自身のどこが重要かに注意を向けるものです。
つまり、文章中の単語の列に対して、そのタスクにはどの単語が重要なのかなぁ?といったことを学習していきます。
Self-Attention については、こちらをご参照ください。

ではまず、Transformer の全体像を見てみましょう。全体像は論文の図を借りるとこのようになっています。
図の左側が、エンコーダーであり、単語をインプットとして、文章の埋め込み表現 (ベクトル) を求めます。
この文章の埋め込み表現は、デコーダーで翻訳する際に使われます。
そして、右側がデコーダーで、翻訳語の単語列をと埋め込まれた文章をインプットとして、次の単語を予測します。
例えば、以下の翻訳の例を考えてみましょう。
“私が昨日見た映画はすごくよかったです。” → “The movie I watched last night was very good.”
まず、日本語の文章をエンコーダーのインプットとして、埋め込み表現を計算します。
その際、例えば“映画”という単語を処理する場合、"私は” や “昨日”、“見た” という単語に注意を向けながら埋め込み表現を計算します。
注意を向けるというのはわかりにくいですが、この場合だと“映画”という単語との何等かの関連性を学習しているというイメージです。情報を共有していると考えても良いかもしれません。
そして、デコーダーでは逐次的に次の単語を予測していきます。
例えば、まずは “The” をインプットとして、次の単語を予測し、その次は “The movie" をインプットとして次の単語を予測します。
このままでは次に何が来るか全くわかりませんが、翻訳前の日本語の文章を手掛かりにします。
それがデコーダーのもう一つのインプットであるエンコーダーのアウトプットです。
日本語の文章では “私が昨日見た映画” とありますので、“The movie” の次は “I” が来るかな、と予測します。
このときも Attentionを使っており、“The movie” から日本語のどこに注意を向けるべきかや、“movie” は “The” に注意を向けるべきか(つまり前の単語を意識する)、というのを学習していきます。
ちょっと長くなるので、ここで一度簡単にまとめておきます。
- Transformerは通常のAttentionに加えて、Self-AttentionというAttentionメカニズムを使っている。
- Self-Attentionは、自分自身のどこが重要か?を学習する仕組み。
- エンコーダーで翻訳前の文章(例えば日本語の文章)について、どこが重要かや各単語の関連性を考えながら埋め込み表現を計算する。
- デコーダーで翻訳後の単語列をインプットとし、次の単語を予測する。
その際に、エンコーダーで埋め込まれた翻訳前の文章の埋め込み表現をインプットして、参考にしながら予測する。
つまり、自分自身の単語と翻訳前の単語を見比べながら、次の単語を予測するイメージ。
では、以下でより細かいパーツをひとつずつ見てみましょう。
Positional Encoding
まず、インプットとなる単語から embedding レイヤーを通して、単語の埋め込み表現に変換します。
ただし、Transformer は RNN を使わないので単語の順番の概念がありません。
そこで、Positional Encoding という仕組みを組み込むことで単語の位置を考慮した埋め込み表現を作成します。
これにより RNN などを使わずに位置情報を考慮することができます。
どのように位置情報を埋め込むかというと、以下の式で Positional Encoding (位置情報)を計算し、単語の埋め込み表現に足します。
$$\begin{align}
PE_{pos, 2i} &= \sin\left(pos/100000^{2i/d_{model}} \right) \\
PE_{pos, 2i+1} &= \sin\left(pos/100000^{2i/d_{model}} \right)
\end{align}$$
\(pos\) というのが、単語列の何番目か?を表し、\(i\) が埋め込み表現の何番目の次元か?を表します。
なぜこのように sin / cos を使うかと言うと、別にこのような方法でなくてもよいのですが、論文によると
$$PE_{pos+k, 2i}=\alpha PE_{pos, 2i} $$
というように、 \(PE_{pos+k, 2i}\) の値が \(PE_{pos, 2i}\) の線形関数になっていることから都合が良いとのことです。
BERT などではこの positional encoding 自体を学習させるので sin / cos による positional encoding は使いません。
上記の式を図にするとこのようになります。Tensorflow の tutorial より拝借しています。
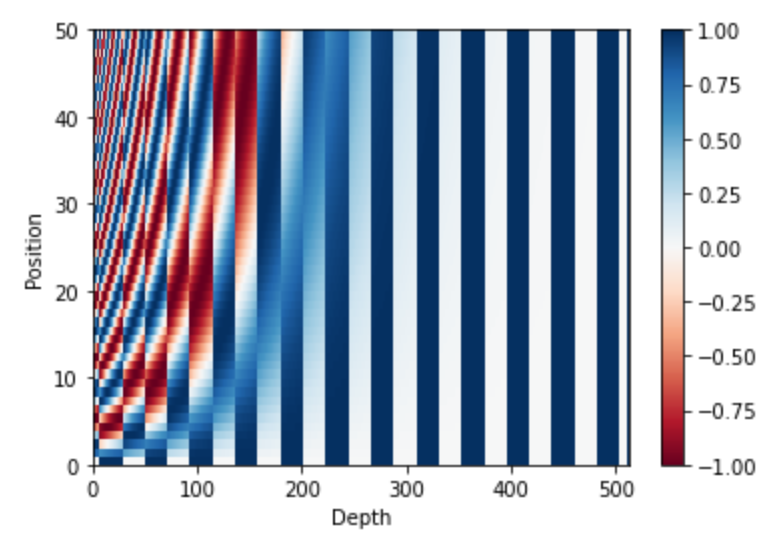
この positional encoding の値は単語の場所や埋め込み表現の次元によって異なりますので、単語の場所や埋め込み表現の次元を表していると考えられます。
これを単語の埋め込み表現に足すことにより、位置情報を考慮した単語の埋め込み表現ができるということです。
Encoder
ではエンコーダーを見ていきましょう。
エンコーダーは、以下のように表されます。
まず、Multi-Head Attention という attention のレイヤー、それに続いて、Add & Norm と書かれているのが、“残差結合 (skip connection) + 正規化層”です。
残差結合
残差結合とは、画像認識で画期的な成果を残した ResNet で使われた方法で、Multi-Head Attention へのインプットと、Multi-Head Attention のアウトプットをインプットとして、足す方法です。
式で書くとこのようになります。
$$h(x)=x+f(x)$$
\(x\) を attention へのインプットで \(f(x)\) が attention のアウトプットです。
残差結合は次のレイヤーに \(h(x)\) を流します。
つまり、attention のアウトプットは \(f(x)=h(x)-x\) となり、attention は残差 \(h(x)-x\) に合わせるようにパラメータを調整します。
attention レイヤーの存在によりパフォーマンスが悪化するようであれば、attention レイヤーのアウトプットをゼロにするように学習されるので、パフォーマンスの悪化を防ぎます。
そのため、レイヤーをたくさん追加してもパフォーマンスが悪化しにくいという利点があります。
レイヤー正規化(Layer Normalization)
そして、レイヤーの正規化(Layer Normalization)です。これは単にアウトプットの正規化を行うだけですので、詳細の解説は省略します。
バッチ正規化(Batch Normalization)の改良版と思っていただければ結構です。
詳細が知りたい方はこちらをご参照ください(Batch Normalizationがわかっていれば簡単に理解できると思います)。

この2つで1つのサブレイヤーが構成されています。
Feed Forwardレイヤー
次のサブレイヤーは、全結合層であるFeed Forwardレイヤーと、先ほどと同じように残差結合レイヤーとレイヤー正規化です。
Feed Forwardレイヤーは、2つのレイヤーからなり、1つ目のレイヤーの活性化関数はReLUになっています。
$$\text{FFN}(x)=\max\left(0, xW_1+b_1\right)W_2 + b_2$$
以上がエンコーダーですが、この仕組みを[(N_x\)回繰り返します。
論文では6回繰り返すことになっています。
ですので、インプットの次元とアウトプットの次元は揃える必要があり、論文では\(d_{\text{model}}=512\)とされています。
Decoder
では、次はデコーダーです。デコーダーはこのようになっています。
それほど大きくは変わりませんが、若干違います。
まず、初めが Masked Multi-Head Attention レイヤーで、そのあと、残差結合と正規化です。
Masked Multi-Head Attention はあとで説明しますが、先の単語を見ないようにマスクをかけた attention です。
その次は、また同じ Multi-Head Attention からの残差結合と正規化のレイヤーですが、インプットは前の層のアウトプットと、左側から矢印が来ているエンコーダーのアウトプットになっています。
ここが“エンコーダーで埋め込まれた翻訳前の文章の埋め込み表現をインプットして、参考にしながら予測する”という部分です。
ここもポイントですので後程 Attention のところで説明します。
最後は、全結合層と残差結合・正規化層です。
Scaled Dot-Product Attention
attention の考え方自体は以前の投稿で説明した attention と同じなのですが、Transformer では Scaled Dot-Product Attention という仕組みを使います。
以前の Attention の記事で説明したものは Additive Attention (加法注意) と言われます。
一方で、Transformer の Scaled Dot-Product Attention では query と key-value のペアを使ってattention を計算します。
Scaled Dot-Product Attention は以下の図の形で、計算方法自体は極めてシンプルです。
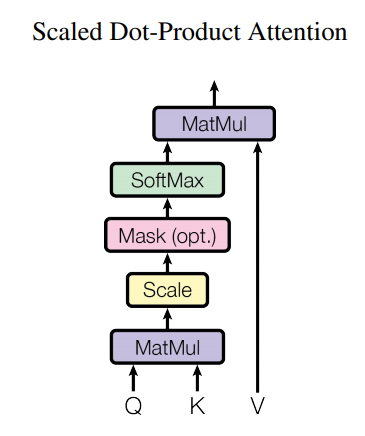
Q が query、K が key、V が value を表しています。
query とは検索対象の単語で、key - value が答えになる単語の key とその値になります。
つまり、query から key-value に注意を向けることになります。
前回の attention でもそうでしたが、context vector は、
$$\text{context vector} = \text{attention} \cdot \text{source}$$
で計算しました。
Transformer では key-value という仕組みを使うので若干違いますが、ほぼ前回と同様で、
$$\text{context vector} = \text{attention} \cdot \underline{\text{value}}$$
で context vector を計算します。
ですので、考え方としては、value が注意を向ける先で、attention に value をかけることで value の注意による加重平均を取り、注意で加重平均された埋め込み表現を計算しています。
では、attention の計算方法ですが、こちらになります。
$$Attention=\text{softmax}\left(\frac{QK^T}{\sqrt{d_{\text{model}}}}\right)V$$
attention weight は Dot-Product Attention というものを使い、\(QK^T\) で計算します。
\(QK^T\in \mathbb{R}^{length\times length}\) の意味ですが、これは query ベクトルと key ベクトルの内積を計算しており、これが大きいところが大きな注意を向けるところになります。
つまり、\(QK^T\) の \(i\) 行目 \(j\) 列は、\(i\) 番目の単語から \(j\) 番目の単語に向ける注意の大きさになります。
この計算では、各queryから各のkeyに向ける注意を一発ですべて計算することができます。
アウトプットは \(QK^T\in \mathbb{R}^{length\times length}\) なので、Query の各単語から Key の各単語に向ける注意がすべて詰まっています。
そして、この Dot-Product Attention の方が Additive Attention よりも速く、効率的だとのことです。
ちなみに、前述の通り、Q と K のサイズは“文章の長さ × \(d_k\)”なのですが、上記の行列計算をした結果は“文章の長さ × 文章の長さ”になり、文章が長くなると非常にメモリを消費します。
ですので、例えば長文のセンチメント分析や文書分類をする場合は、これが大きなネックになってしまいます。
この問題を解消しようとしているのが例えばや "Sparse Transformer" や “Reformer”、"Longformer" といったモデルです。
最近の ChatGPT や Google の Gemini などではかなりの長文を扱えるようになっていますが、これらの技術が使われています。
最後に、\(QK^T\) の要素の値が大きくなりすぎないように調整するために、Q と K の次元である \(d_k\) の平方根 \(\sqrt{d_k}\) で割ってやります。
\(V\) が上記の Value を表します。
Mask はざっくり言うと将来の情報を使わないようにマスキングするものですが、後程解説したいと思います。
Multi-Head Attention
Multi-Head Attention は上記の attention を複数並べることにより、精度の向上を図るものです。
head 数を \(h\)とすると、query、key、value に \(W_i^Q\)、\(W_i^K\)、\(W_i^V\)、\(i=(1,2,\cdots, h)\) をそれぞれかけて、\(h\) 個の \(Q_i\) 、\(K_i\) 、\(V_i\) を作ります。
そして、それぞれに Scaled Dot-Product Attention を適用することにより、\(h\) 種類の注意を使います。
それにより、head が1つの attention よりも精度が良くなるようです。
図でいうと、全体のインプットが Q、K、V で、Linear というレイヤーで \(Q_i\) 、\(K_i\) 、\(V_i\) , \(i=(1,2,\cdots, h)\) を求めています。
式で書くと、
$$\begin{align}
\text{MultiHead}(Q, K, V) &= \text{Concat}\left(\text{head}_1, \cdots, \text{head}_h\right)W^O \\
\text{where } \text{head} _i &= \text{Attention}\left(QW_i^Q, KW_i^K, VW_i^V\right)
\end{align}$$
となります。
haed ごとの context vector を計算して、それを結合し、最後に \(W^O\) を掛けています。
さて、このインプット V、K、Q ですが、何が入るかは使われている場所によって違います。
それをこれから解説したいと思います。
エンコーダーのSelf-Attention
この部分の attention は、自分自身のどの部分が重要かを判断する Self-Attention を使います。
つまり、Q も K も V も自分自身で、すべて同じ前の層からのアウトプットです。
デコーダーのSelf-Attention
デコーダーの Self-Attention はこちらの青で囲んだ部分です。
この部分も Self-Attention なのでエンコーダーと同じで、前の層のアウトプットを Q、K、V すべて同じように設定します。
ただ、こちらは普通の Self-Attention ではなく、使うべきでない情報にマスクをかけた Masked Self-Attention になります。
何故マスクをするかというと、学習時のデコーダーのインプットは、翻訳後の単語列になりますが、翻訳語の単語列は前から順番に作成していく必要があり、i 番目の翻訳語の単語を予測する際は、i-1 番目までの情報しか使うべきではないからです。
そうしないと、その単語より前の単語だけでなく先の単語の答えも見て当てるということになってしまい、自明になってしまいます。
エンコーダー・デコーダーのAttention
エンコーダー・デコーダーは以下の図の青で囲んだ部分です。
このインプットは、これまでのようにすべて同じではありません。
key、value は“注意を向ける先”なのでエンコーダーのアウトプットを使用、query は“どこから注意を向けるか”なので、デコーダーにおける前の層のアウトプットを使用します。
これにより、翻訳後 (query) の単語から翻訳前 (key-value) のどの部分に注意を向けるか、ということを学習することができます。
まとめ
論文「Attention Is All You Need」をもとに説明してきましたが、 如何でしたでしょうか?こちらで何となく理解できたという人は、実際に論文を読んでみることをオススメします。論文にはこれ以外にも、学習率の設定やドロップアウト、正則化など細かい工夫についての説明がありますし、仕組みについてももう少し詳しく説明されています。
以下の記事でTransformerによる分類モデルを実装し、実際のデータを使って精度を確認したりしていますので、こちらをご参照いただければ、より深く理解できると思います。
こちらの本では、Transformer と BERT を PyTorch で実装していますので、真似をしながら自分の手で実装することで、Transformer、さらにはその後続の BERT、そして話題の GPT をしっかりと理解することができると思います。
説明も丁寧でわかりやすいのでオススメです。
ということで、だいぶ GPT や BERT、XLNet に近づいてきました。次は、Pre-training - Fine-tuning の論文解説をする予定です。