さて、今回もBERTをベースとした改良版であるALBERTについて解説したいと思います。
一言で言うと、ALBERTはBERTをさらに大きなモデルにすることにより、精度の向上を図るものです。
ただ、メモリの容量などを考えると、単純にモデルを大きくすることはできないので、いくつかの工夫をすることにより大きなモデルを作ることを可能にしています。
BERTを理解していれば、それほど難しいという点は多くないと思います。
BERTをまだあまり理解していないという方はこちらをご参照ください。

それでは見ていきましょう。
目次
ALBERTとは
ALBERTは、“A Lite BERT”の略で、その名の通りBERTを軽量にするモデルです。
それにより、レイヤー数や隠れ層の数などを大きくすることができ、モデルのスペックを向上させています。
モデルを大きくして事前学習である言語モデルをしっかりと学習することで、下流のタスクの精度を上げることは可能だと考えられます。
しかしながら、単純にモデルを大きくと言っても、すでに\(\text{BERT}_\text{LARGE}\)では3億4000万というパラメータ数であり、ここでレイヤー数を二倍にして…、と言ってもメモリの容量を考えると現実的ではありません。
そこでALBERTでは、大きく以下の2点の工夫により、BERTを軽量化しています。
- 単語の埋め込み表現の行列を2つの小さな行列に分解
Transformerは単語の埋め込み表現の次元と隠れ層の次元を同じにする必要があります。
これを分離することで隠れ層の次元のみを増やすことを可能にします。 - パラメータの共有
各レイヤーのパラメータを共有することにより、パラメータ数を削減します。
そして、さらにBERTで用いられていた事前学習のタスクであるNext Sentence Prediction(NSP)を改良します。
XLNetやRoBERTaの記事でも解説しましたが、これらの論文ではNSPの有効性が明確でないことから、NSPを使用しないという結論になっています。
ALBERTでは、NSPの代わりにより難しいSentence Ordering Prediction(SOP)という文章の順番を予測するタスクを用いることで、2つの文の関係の理解を深めています。
これら大きく3つの工夫により、モデルを大きくすることを可能にし、また2文の理解をより深めることができ、最終的にはBERTの結果は大きく超えることになります。
では、詳細について見ていきましょう。
ALBERTの仕組み
ALBERTの仕組みは、基本的にはBERTと同じです。そこに上記で簡単に説明した3つの工夫を用いています。それらを一つずつ説明していきたいと思います。
embedding matrixの分解
BERTというよりTransformerがそうなのですが、Transformerの仕組み上、Transformer blockのインプットの次元とアウトプットの次元が同じにする必要があるので、単語の埋め込み表現の次元と隠れ層の次元は同じになっています。
これにより、隠れ層の次元を増やそうとすると単語の埋め込み表現の次元も大きくする必要がでてきます。
そこで、ALBERTでは、単語の埋め込み表現の次元と隠れ層の次元を分離するように試みます。
どのように分離するかですが、まず単語の埋め込み表現の次元を\(E\)、隠れ層ベクトルの次元を\(H\)、ボキャブラリーサイズを\(V\)とします。BERTでは\(E=H\)のなっています。
この場合、embedding matrixは\(V\times E\)になります。
つまり、\(V\times H\)です。ですので、\(H\)を増やすと embedding matrixもどんどん大きくなります。
そこで、embedding matrixを、\(E\neq H\)として、\(V\times E\)と\(E\times H\)の2つに分解します。
このようにすることで、パラメータ数は\(V\times H\)から\(V\times E+E\times H\)になります。
基本的にボキャブラリーサイズ\(V\)は数万になることもあり、数千オーダーである隠れ層の次元\(H\)よりもはるかに大きいです。
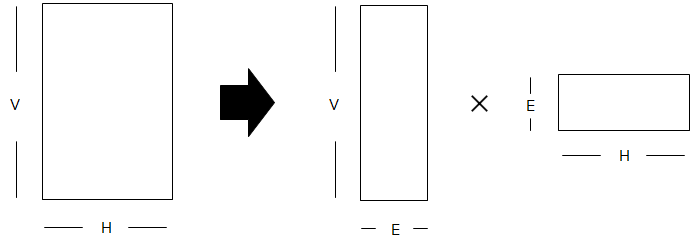
したがって、\(V \gg H\)のとき\(V\times E+E\times H=E\times(V+H)\simeq E\times V \)となることからもわかるように、 \(E\)を小さくすることでパラメータ数を減らすことができ、\(H\)を大きくしてもパラメータ数に大きな影響を与えません。
レイヤー間でのパラメータの共有
BERTは複数のTransformer blockで構成されますが、複数のTransformer blockのパラメータ、つまりウェイトを共有するものです。
Bai et al.(2019)のDeep Equilibrium Modelsという論文では、パラメータを共有することでレイヤーをどんどん増やした場合、どこかでインプットとアウトプットが同じになったという実験結果が示されています。
本論文の実験結果では、完全に同じになるというよりは、ある程度同じに近づいていくという結果です。
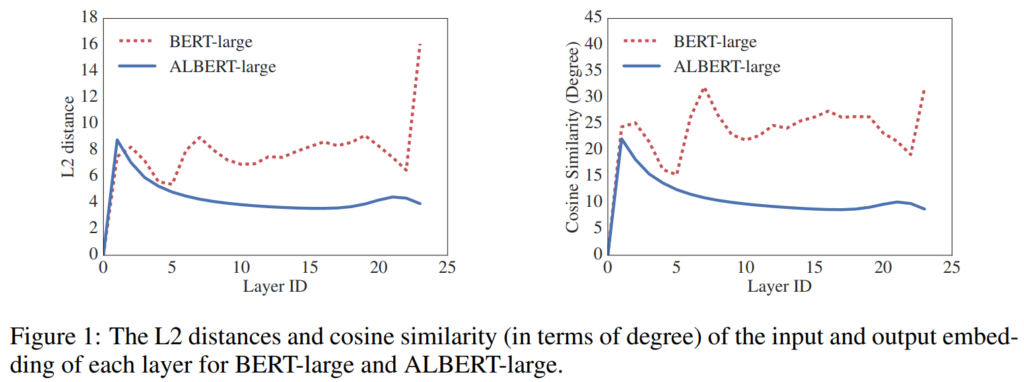
以下の図は、左側がレイヤー間のインプットとアウトプットのL2距離で、右側がcosine similarityです。
BERTはパラメータをシェアしていないのでバラバラですが、パラメータをシェアしているALBERTはあるレイヤーからだんだんとインプットとアウトプットが似てきていることがわかります。
Next Sentence PredictionからSentence Order Prediction
こちらは、今まで見てきた2つのようにパラメータを削減することが目的ではなく、2つの文章の関係性をBERTよりもうまく捉えられるように試みるものです。
BERTではNext Sentence Prediction(NSP)という2つ目の文章が1つ目の文章の続きか、それとも違う文書から持ってきた文章かを当てるタスクを解くことで2文の関係性を学習しています。
そしてこのNSPはBERTではよい効果が見られていましたがが、XLNetやRoBERTaの実験では、ほとんど効果が見られず、結局これらのモデルでは採用されていません。
その原因として、本論文ではNSPは問題が簡単過ぎるのでは?と推測されています。
確かに簡単なタスクを解いても精度が上がらない、もしくは悪化するという現象は他のタスクでも見られます(サンプルを増やすために当てやすいサンプルを増やしても精度が逆に悪化するということもあります)。
そこで、ALBERTではNSPの代わりに、より難しいと考えられるSentence Order Prediction(SOP)という2つの文章のうちどちらが最初の文書か?を予測するタスクを解きます。
NSPでは実質的には2つの文章が同じトピックか違うトピックかどうかを当てるのに対し、SOPは同じトピックの中で文章の順番を当てるので、より難しいと考えられます。
パラメータ数の比較
では、これらの改良によりパラメータがどれぐらい変わるかを見てみましょう。
BERT-baseからALBERT-baseになると、パラメータ数は108Mから12Mと96M個減少、BERT-largeからALBERT-latgeになると、パラメータ数は334Mからたったの18Mと316M個も減少しています。
かなり削減できていますね。
それにより、ALBERT-xlargeやALBERT-xxlargeといったレイヤー数や隠れ層の次元を大幅に増やした場合においてもBERT-largeよりもパラメータ数が減少しています。

では、念のためlargeの場合において、ざっくりどのようにパラメータ数が減少したかを確認してみましょう。
Layer Normalizationなどはパラメータ数が少ないので考慮はしません。
まず、単語の埋め込み表現の部分は、BERTが
$$\\V\times H=30,000\times 1,024=30,720,000$$
に対し、ALBERTは
$$V\times E+E\times H=30,000\times 128+128\times 1,024=3,971,072$$
です。
したがって、その差は約27Mになります。
次に、Multi-Head Attentionの部分のパラメータですが、式を思い出すと、
$$\begin{align}
\text{MultiHead}(Q, K, V) &= \text{Concat}\left(\text{head}_1, \cdots, \text{head}_h\right)W^O \\
\text{where } \text{head} _i &= \text{Attention}\left(QW_i^Q, KW_i^K, VW_i^V\right)
\end{align}$$
であり、今回の設定ではそれぞれの次元は、\(W_i^Q, W_i^Q, W_i^Q=\mathbb{R}^{H\times H/A}\)で、 Attention head数は\(A\)なので、この\(A\)倍あります。
そして、\(W^O\in\mathbb{R}^{H\times H}\)なので、まとめると、パラメータ数は、
$$\begin{align}
\text{#multi-attention parameters} &= 3 \times (H\times H/A) \times A + H\times H \\
&=3 \times (1,024 \times 1,024 / A) \times A + 1,024\times 1024 \\
&= 4,194,304
\end{align}$$
になります(Attention head数はパラメータ数に影響を与えません)。さらにFeed Forwardレイヤーがあるので、Feed Forwardレイヤーのパラメータ数は、
$$\text{FFN}(x)=\max\left(0, xW_1+b_1\right)W_2 + b_2$$
で、\(W_1\in \mathbb{R}^{H\times 4H}, b\in \mathbb{R}^{4H}\)、 \(W_2\in \mathbb{R}^{4H\times H}, b\in \mathbb{R}^{H}\)
$$\begin{align}
\text{#feed-forward parameters} &= (H\times 4H + 4H) + (4H\times H + H) \\
&=(1,024 \times 4\times 1,024 + 4\times 1,024) \\
&+ (4\times 1,024 \times 1,024+1,024) \\
&=8,393,728
\end{align}$$
になります。
この合計が、1つのTransformer blockのパラメータ数です。BERTではこれが\(L=24\)個ありますが、ALBERTはそのままです。
ですので、差は\((4,194,304+8,393,728)\times 24 - (4,194,304+8,393,728)=289M\)になります。
大幅に減少していますね。
ということで、最終的なモデルパラメータの減少数は、単語の埋め込み部分とattention部分の合計なので\(27M+289M=316M \) になります。
どちらかというとTransformer blockの影響の方が大きそうですね。
実験
設定は概ねBERTと同じなので詳細は省きますが、Masked LMは1つの単語をマスクするのではなく、以下の式に従って、n-gram単位でマスクします。
$$p(n)=\frac{1/n}{\sum^N_{k=1} 1/ k}$$
で、n-gramの最大数を\(N=3\)として、確率的に選んでマスクします。
バッチサイズは4,096でLAMB optimizerというものを使っています。
実験結果を見てみましょう。
BERTとの比較
まず、SQuAD、MNLI、SST2、RACEデータセットでBERTとパフォーマンスを比較しています。
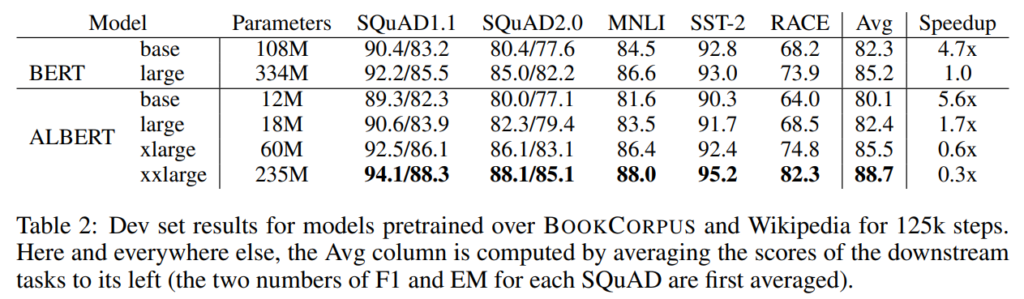
まず、精度ですが、ALBERT xxlargeはBERT largeよりもパラメータは大幅に少ないにも関わらず平均で2.5%も改善しています。
計算速度(一番右の列)については、BERT largeとALBERT largeが同じ構造(同じレイヤー数、同じ隠れ層の次元)ですが、その場合、ALBERT largeはBERT largeよりも1.7倍も速くなっています。
一方で、ALBERT xxlargeはパラメータ数はBERT largeよりも少ないですが、隠れ層の次元自体は4倍も多いため計算量が多いことから、3倍も遅くなっています。
パラメータ数は減少し軽量にはなっていますが、計算量はやはり増えるということですね。
Embedding size
続いて、単語の埋め込み表現を分解したときのサイズ(\(E\))を変えて精度を見ています。
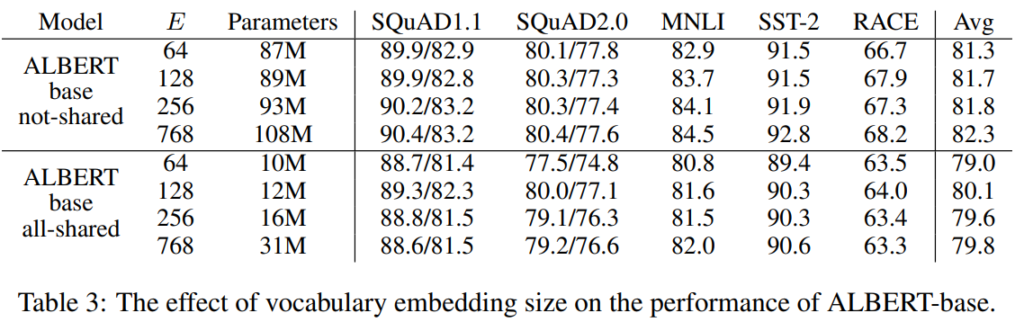
\(E\)を増やしても1%程度の改善とそれほど効果は大きくありません。
そして、パラメータを共有する場合だと、一番精度が良いのは\(E=128\)の場合になっています。
Cross-layer Parameter Sharing
では、次にパラメータを共有した場合の影響について見ていきたいと思います。
以下の表は、\(E=768\)(上段)と\(E=128\)(下段)において、パラメータを共有した場合、アテンション部分のパラメータのみを共有した場合、Feed-forwardレイヤーのパラメータのみを共有した場合、パラメータを共有しない場合で比較しています。
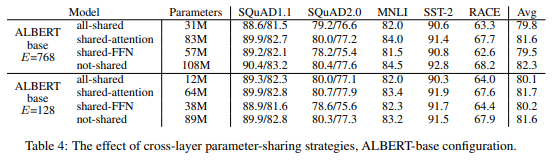
まず、\(E=768\)と\(E=128\)で、パラメータを共有することによってどれぐらい精度が変わるを見てみると、\(E=768\)の場合で▲2.5%(82.3%→79.8%)、(E=128\)の場合で▲1.5%(81.6%→80.1%)と\(E=128\)の場合の方が影響は小さくなっています。
では、\(E=128\)の場合において、どのレイヤーのパラメータを共有した影響が大きいかを見てみると、Feed-forwardレイヤーのパラメータを共有することにより▲1.4%(81.6%→80.2%)、アテンションのパラメータを共有することにより+0.1%(81.6%→81.7%)と、Feed-forwardレイヤーのパラメータを共有する影響が大きいことがわかります。
\(E=768\)の場合においても、大きさの差はありますが、同じような傾向になっています。
Sentence Order Prediction(SOP)
では、Next Sentence Prediction(NSP)をSentence Order Prediction(SOP)に変えた場合の影響を検証します。
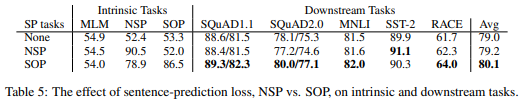
1行目がNSPもSOPも使わない場合、2行目がNSPを行う場合、3行目がSOPを行う場合です。そして、Intrinsic TasksのMLM、NSP、SOPはそれぞれのタスクの精度になります。
1行目のNoneだとNSPもSOPも学習していないので、その精度はほぼランダムな50%強の精度になっています(TrueラベルとFalseラベルが半々に入っているので)。
NSPを行った場合は、当然NSPの精度は高く90.5%ですが、SOPタスクはランダムとほぼ同じ52.0%です。
つまり、NSPではSOPは学習できていないことになります。まぁ、感覚的にもそうですよね。
そして、SOPを学習した場合は、SOPタスクの精度は86.5%で、NSPタスクも78.9%になっています。
つまり、SOPを行うことで、NSPも一定程度学習できていることになります。
レイヤー数
ALBERTではパラメータを共有しているためレイヤー数が増えてもパラメータ数は増えません。
ですので、メモリ上はレイヤー数を増やしても大した影響はないので、レイヤー数を増やした場合の精度への影響を見ています。
以下はALBERT-largeの設定、つまり\(H=1,024\)でレイヤー数を変えた場合の精度の結果です。
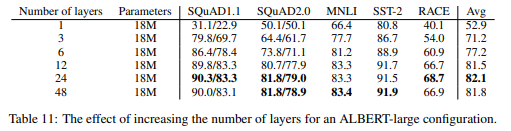
レイヤー数を増やしていくと基本的に精度は上昇していきますが、24から48に増やした場合、逆に精度は低下しています。
ALBERT-xxlarge(\(H=4096\))の設定で、レイヤー数を12とした場合と24とした場合の比較を行っています。

この場合、12でも24でも大きな差はありません。
以上の分析からALBERT-xxlargeで評価する場合はレイヤー数を12としています。
隠れ層の次元
では隠れ層の次元を増やしていくとどうなるのでしょう。
こちらはサイズを大きくすればするほどパラメータ数は増えていきますが、4096次元で一番精度が良くなっており、それ以上増やしても精度が悪化しています。

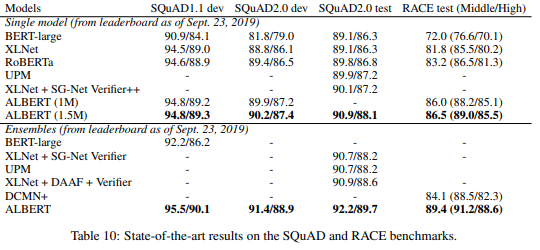
GLUE、SQuAD、RACEデータセットの結果
さて、論文では他にもいくつかBERTとの比較分析はされているのですがそこは省略して(興味がある方は論文をご参照ください)、ベンチマークデータセットの比較をした結果を見てみたいと思います。
まず、GLUEベンチマークです。
上段が一つのモデル、下段がアンサンブルの結果になっていますが、ほぼすべてのデータセットでRoBERTaを抜きSoTAを達成しています。
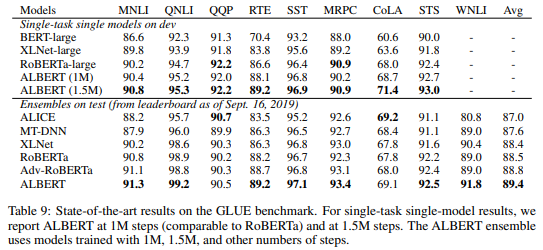
SQuADとRACEデータセットの結果は以下です。こちらもSoTAを達成しています。
RACEの方は、BERT-largeからの改善が素晴らしいですね。
まとめ
今回は、BERTを軽量にしたモデルALBERTを見てきました。
Next Sentence Predictionは効果がない!と言って終わるのではなく、もっと難しいタスクに変えたらどうか?という発想は非常に面白いし、参考になりますね。
今後もBERTをベースにした改良モデルが続々と出てくるのではないかと思います。
では!