『ChatGPT』の公開以来、そのすごさ、問題点、使い方など様々な点から非常に話題になっていますね。
そして2023年3月1日からは API として利用できるようになりました。
そのため、ただ単に ChatGPT を使って遊ぶだけでなく、業務への活用を本格的に検討している企業もたくさん出てきているようですね。
今回はその ChatGPT のAPI の使い方についてご紹介したいと思います。
以下のOpenAI のブログには ChatGPT と音声をテキストに変換する Whisper の API について活用事例も含めて紹介されていますので、興味のある方はご参考にしてみてください。
記事の作成にあたっては、以下の OpenAI のドキュメントを参考にしていますので、より詳しく知りたい方はこちらもあわせてご覧ください。
また、GPT-4 のテクニカル・ペーパーを使って、GPT とは何か?GPT-4 とは何か?について、解説している記事を作成しましたのでこちらも参考にしてください。
では、早速使い方を見ていきましょう。
目次
ChatGPT API の使い方
利用例
まず、ChatGPT を使ってどのようなことができるのかを見ていきます。
OpenAI のブログでは以下のような利用例が記載されています。
- メールや資料等のドラフトを作成する
- Python のコードを作成する
- 文書に関する質問に答える
- 対話エージェントを作成する
- 自然言語がインターフェースとなるソフトウェアを作成する
- 家庭教師になる
- 翻訳する
- ゲームのキャラクターをシミュレーションする
きっとこれら以外にも想像力を働かせれば色々な使い方があるかもしれませんね。
上記の OpenAI のブログにはいくつかの ChatGPT を利用した例が紹介されており、個人的にはこちらの instacart というアプリが面白いなと思いました。
単純に ChatGPT を使っているのではなく、既存の instacart の機能と組み合わせることでチャットを活用しながらメニューを決めたり、材料の購入をすることができるそうです。
このように ChatGPT の API を利用して工夫することで、面白いアプリを開発することができるようなります。
モデル
では、どんなモデルを使えるのかを見ていきましょう。
GPT-3.5 にはいくつかモデルがありますが、ChatGPT で使えるのは以下の gpt-3.5-turbo と gpt-3.5-turbo-0301 で、gpt-3.5-turbo を使う方が良さそうです。
(OpenAI もこちらをオススメしています)

この gpt-3-turbo は 2021年9月までのデータで学習しているとのことです。
逆にそれ以降のデータに関しては答えられないということになりますね。
例えば、「直近の米国の消費者物価指数はいくつですか?」と聞くと以下のような回答が返ってきました。
最新の米国消費者物価指数(CPI)は、2021年6月に発表されたもので、前月比で0.9%上昇し、前年同月比では5.4%上昇しました。
2021年6月が最新ということです。
Google の Bard(モデルは『LaMDA』) では、実際に情報検索を行うので、これよりも新しい情報が得られるのかなと思います。
Google の 『LaMDA (Language Models for Dialog Applications)』 については以下をご参照ください。
『【論文解説】Google の対話 AI『LaMDA』を理解する』
Python で API を使う方法
ここからは実際に API を使っていきます。
なお、ChatGPT の API を使うのは有料になるので、クレジットカードの登録等が必要です。
まず、openai というライブラリをインストールします。
(Google Colab や Jupyter Notebook でインストールしない場合は「!」は不要です)
!pip install openai
次に opeanai をインポートとして、 OpenAI の API Key を以下のように設定します。
import openai openai.api_key = "OpenAI の API Key"
API Key は OpenAI のサイトから取得できます。
詳細はあとで解説しますが、とりあえず対話をしてみましょう。
以下のように openai.ChatCompletion.create() を呼び出します。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです."},
{"role": "user", "content": "NBAプレイヤーの中でもっとも偉大な選手は誰ですか?"},
{"role": "assistant", "content": "マイケルジョーダンかレブロンジェームスだと思います。"},
{"role": "user", "content": "個人的にあたなはどちらが偉大だと思いますか?"}
]
)
出力は次のようになりました。
私は多くの偉大なNBAプレイヤーがいると思いますが、マイケル・ジョーダンは最も偉大な選手と考えられています。彼は6回のNBAチャンピオン、5回のMVP、10回の得点王、そしてオールスターゲームMVPを3回獲得し、NBA歴史上最高得点平均を持っています。 彼のスキル、リーダーシップ、信じられないほどのパフォーマンス、そして競争心は、彼をNBA史上最も偉大な選手の1人にさせました。
さすがですね。
インプット・パラメータ
では、ここで指定したインプットパラメータ model と messages を見ていきましょう。
model
モデルを設定します。
ここでは、“gpt-3.5-turbo” という最新モデルを指定しています。
ここは特に何も考えずに gpt-3.5-turbo で大丈夫です。
messages
ここに対話文をリスト形式で入力します。
リストの1つ1つの要素が発話になっており、role と content の2つを辞書形式で指定します。
今回は4つの文章を入力しています。
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです."},
{"role": "user", "content": "NBAプレイヤーの中でもっとも偉大な選手は誰ですか?"},
{"role": "assistant", "content": "マイケルジョーダンかレブロンジェームスだと思います。"},
{"role": "user", "content": "個人的にあたなはどちらが偉大だと思いますか?"}
]
role
role は役割で以下の3つのうちどれかを設定します。
- system
- user
- assistant
基本的にやりとりは user と assistant の間で行います。
system は最初に assistant の役割を指定したりできるものです。
system の役割についてはのちほどもう少し詳しく見たいと思います。
content
content には発話を設定します。
role が assistant であればチャットボットの発話を、role が user であればユーザの発話を設定します。
そして、その対話に続く文章が ChatGPT により生成されます。
なお、上記の例では最初に system を指定し、content に「あなたは役に立つアシスタントです」と設定しています。
{"role": "system", "content": "あなたは役に立つアシスタントです."},
これにより assistant は「役に立つアシスタント」として振る舞うことになります。
system を指定せずに文章を生成させると、以下のように「私は人工知能の言語処理モデルであり、感情を持っていないため、個人的な好みや評価はありません。」という枕詞が付いていました。
私は人工知能の言語処理モデルであり、感情を持っていないため、個人的な好みや評価はありません。ただし、スポーツ評論家やバスケットボールファンの中には、マイケルジョーダンを「GOAT(史上最高の選手)」と呼ぶ人もいれば、レブロンジェームズにその称号を与える人もいます。どちらが偉大だと思うかは、人それぞれの主観や価値観によって異なるでしょう。
つまり、個人的な意見を聞いていますが、system で何も指定しないと人工知能として回答するため、「感情は持ってません」といった回答がついてきます。
一方で、「あなたは役に立つアシスタントです」とアシスタントに役割を指示することにより、アシスタントとして振る舞っていることになります。
少し変えてみましょう。
「あなたは女王様です。自分のことは「わらわ」と言って、敬語は使わず偉そうに話してください。」としてみます。
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは女王様です。自分のことは「わらわ」と言って、敬語は使わず偉そうに話してください。"},
{"role": "user", "content": "NBAプレイヤーの中でもっとも偉大な選手は?"},
]
)
こんな回答が変えて返ってきました。
ふん、わらわにそのような質問をするとは無礼な。しかし、NBAの歴史において最も偉大な選手と言われるのは、やはりマイケル・ジョーダンであろう。彼は不屈の闘志と卓越したテクニックで6度のNBAチャンピオンシップを獲得し、数多くの個人賞も受賞している。また、そのスター性と影響力はNBAのみならず世界的に知られている。わらわの言葉に従い、今回の質問はこれまでとしておくがよい。
何かそれっぽい感じになってますね(笑)
色々試していただければおわかりになると思いますが、うまくいくケースとうまくいかないケースがあるようです。
OpenAI のドキュメントにも「system の欄にはそこまで注意を払わない」との記載があります。
あとは role に user もしくは assistant を交互に指定し、content に発話文を設定することで、それに続くアシスタントの回答が得られます。
なお、もう少し細かい設定をするためのパラメータがありますが、あまり機能していなかったりするので、それほど意識しなくても良いかと思います。
興味のある方は以下のドキュメントの 『Chat』の欄を見ていただければと思います。
『Create chat completion のドキュメント』
アウトプット
レスポンスは以下のような辞書型で返ってきます。
{
choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "xxx",
"role": "assistant"
}
}
],
"created": 1677752695,
"id": "chatcmpl-6paPHsiBZZcCPOfP7fPIrabqje0pk",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 180,
"prompt_tokens": 91,
"total_tokens": 271
}
}
key は created, id, model, object, usage, choices となっており、回答が入っているのは “choices” です。
choices はリスト型になっており、finish_reason, index, message があり、 “message” の中の “content” に返答が設定されています。
ですので、表示する場合は以下のようにしてやると返答のみを出力することができます。
print(response["choices"][0]["message"]["content"])
その他にもトークン数や回答の role なども格納されています。
よりうまく回答させるには
assistant によりうまく役割を演じさせ、よりうまく回答させるには、以下の方法が良いとのことです。
- より明示的に指示をする
- 答えのフォーマットを特定する
- 段階的にモデル考えさせる
とにかく大事なことは ChatGPT に合わせるように、うまくプロンプトを作成するということですね (笑)
よいプロンプトの作成方法などはこちらが参考になります。
『Techniques to improve reliability』
このあたりは今後深掘って解説していきたいと思っています。
トークン
トークンとはモデルにインプットする単位になります。
イメージとしては単語ですが、厳密には GPT(に限らず最近の大規模言語モデル)は単語をより細かく区切る場合があります。
なぜかと言うと、モデルへのインプットは単語そのものではなく、辞書から探し出した ID だからです。
すべての単語を辞書に登録すると膨大な数になってしまったり、辞書にない単語が出てきてしまう(これを未知語と言います)ことがあります。
辞書を単語ではなく文字単位にすれば、英語であればたったの23個のアルファベットだけで良くなりますので未知語はなくなりますが、文字の組み合わせの意味が失われてしまう場合があります。
そこで GPT では Byte Pair Encoding と呼ばれる、単語と文字の中間のような分割をしていて、出現頻度が低い単語は、単語よりも細かい単位に分割しています。
(詳細についてはこちらの記事が非常に参考になります)
これにより、出現頻度が高い単語は単語として辞書に登録し、出現頻度が低い単語は文字単位などの少し細かい単位に分割しています。
これにより実質的に未知語というのがなくなります。
OpenAI のブログの例でみていきます。
ChatGPT is great!"
という文章の場合、単語は “ChatGPT”、“is”、“great” と“ !” です。
各単語を辞書にある ID 変換してインプットするのですが、ChatGPT という単語は出現頻度が低い、もしくは学習データにはない未知語なので辞書には登録されていません。
そこで、ChatGPT を細かく分割していきます。
chatgpt という単語は辞書にはありませんが、chat は一般的な単語で辞書に存在するので、chatgpt を chat と g と pt に分割します。
(gpt も辞書にはないということですね)
is や great は一般的な単語なので辞書に存在します。
それにより文章自体は、“chat”、“g”、“pt”、“is”、“great”、“!” に分割されます。
そしてこれらをインプットとします。
以下の図は GPT のインプットのイメージです。
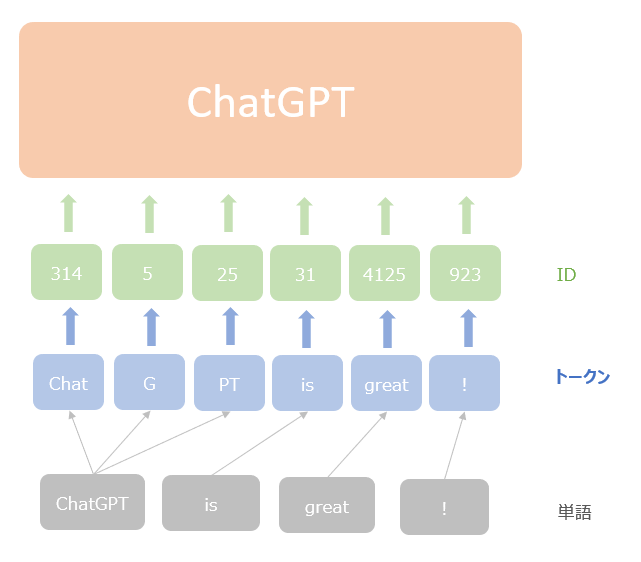
以上からわかるように、ChatGPT へのインプットは単語単位ではなくトークン単位になっています。
(特に日本語の場合は、どこまでが単語かなどは意識していません)
ですので ChatGPT の利用料金もインプットであるトークンの数に依存してきます。
何トークンに分割されているかは、アウトプットの usage に入っていますので、以下のコードで確認できます。
print(response['usage'])
ChatGPT API の利用料
2023年3月現在の ChatGPT の利用料は1000トークンあたり0.002 US ドルになっています。

GPT-3 の一番良いモデルが1000トークンあたり0.02USドルでしたので、10分の1の価格になっています。
より良いモデルが安くなるというのは嬉しいですね。
詳細はこちらをご参照ください ⇒ 『Pricing』
ファインチューニング
自分のやりたいことにあわせてモデルをファインチューニングしたくなりますが、2023年3月3日現在では gpt-3.5-turbo モデルはファインチューニングできません。
ファインチューニングできるのは既存の GPT-3 モデルである davinci や curie、babbage、ada のみになります。
早くファインチューニングしたいですね。
まとめ
今回は ChatGPT の API の使い方を見てきました。
興味がある方は、是非 ChatGPT API を触っていただき、どんなことが出来そうか見ていただければと思います。
なお、ChatGPT で使われているモデルの 『InstructGPT』 はこちらで解説をしています。

他にも ChatGPT でセンター試験を受けてみた結果もありますので興味がある方は覗いてみてください。

GPT-3 の API についてはこちらをご参照ください。

この記事を読んで ChatGPT API で何か作ろう!と思っていただけると幸いです。
では!