2021年11月18日にOpenAIが「GPT-3」のウェイティングリストを解除すると発表しました。
これにより申請すれば誰でもGPT-3のAPIを使用できるようになります。
ということで、GPT-3のAPIについて実際に使ってみたいと思います。
なお、フェイクニュースの生成やヘイトスピーチなどに悪用されることを防ぐため、使用方法のガイドラインが定められていますのでご確認ください。
ガイドライン ⇒ Usage Guidlines
また、実際にデプロイし、誰かに使ってもらうためにはOpenAIの承認がいるようなので、こちらもご注意ください。
デプロイする際の注意点 ⇒ Going live
GPT-3については以下の記事で解説していますので、こちらもご参照ください。

なお、2023年3月1日から ChatGPT の API が公開されました。
そちらの使い方は以下の記事で解説しています。

目次
GPT-3 APIの使い方概要(Python)
では、ここではPythonを使ったGPT-3 APIの使い方を見ていきます。
アカウントの作成 ~ 前準備
まず、こちらのURLの「Get Started」からアカウントを作成します。

アカウントが作成できたらログインします。
そして、Anaconda Promptなどからpipでopenaiというライブラリをインストールします。
pip install openai
Google Colaboratoryでも大丈夫です。
Google Colaboratoryであれば
!pip install openai
ですね。
そして、以下のモジュールをインポートします。
import os import openai
API keyを設定します。
API keyはログインしたあと右上の"Personal"から"View API keys"をクリックすることで確認することができます。
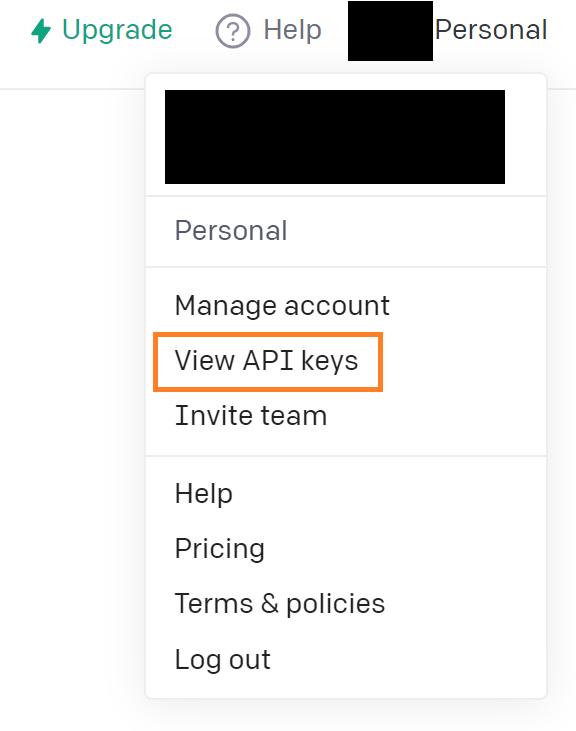
そのAPIを以下のようにopenai.api_keyに設定します。
API_KEY = "受け取ったAPI key" openai.api_key = API_KEY
これで前準備ができました。
文章生成
では、まずは文章の生成を試しましょう。
こちらの記事で解説している通り、GPT-3は基本的にすべて文章生成で、“プロンプト”により分類タスクにしたり、文章を要約したりします。
(ファインチューニングしたベータ版などもあるようなので、それについては今後見ていきたいと思います)
プロンプトは何でもいいのですが、以下のように“私の一番好きなドラゴンクエストのモンスターは”にします。
prompt = "My favorite monster in Dragon Quest is"
あとは、openai.Completion.create()で続きの文章を生成します。
response = openai.Completion.create(engine="davinci",
prompt=prompt,
max_tokens=100,
temperature=0.5,
echo=True)
engineには以下の4種類がありますが、とりあえずDavinciで良さそうなのでdavinciと設定しています。
- Davinci(davinci)
デフォルトでオススメされているエンジンです。複雑な文章生成などに向いています。 - Curie(curie)
より複雑な文章についてはDavinciの方が向いているようですが、Curieはセンチメント分析や翻訳などに向いているとのことです。 - Babbage(babage)
簡単なテキスト分類に向いています。 - Ada(ada)
一番速いモデルで単純な分類などに向いているとのことです。
なお、上述の通り、他にもファインチューンされたモデルとして、Instruct seriesやテキスト情報からプログラムを生成するCodex seriesがあります。
では、文章生成された結果を見てみましょう。
以下のような文章が生成されます。
My favorite monster in Dragon Quest is the Slime. It's a small, cute, and adorable monster that is very easy to defeat. It's also the very first monster you encounter in the game. The Slime is an enemy that is very easy to defeat. It has a lot of HP and it can be found in many places. You can easily defeat this monster with an attack of a few rounds. The Slime is one of the monsters you can recruit in Dragon Quest. You can find it in the same places
英語がネイティブレベルの人にとってはいいのですが、私のレベルだとどうしても面倒くさくなってしまいます。
ですので、DeepLを使って翻訳した結果を見てみます。あとでやり方は説明したいと思います。
するとこんな感じになります。
ドラゴンクエストで一番好きなモンスターは「スライム」です。小さくて、かわいくて、愛らしいモンスターで、とても簡単に倒すことができます。また、ゲームの中で最初に出会うモンスターでもあります。 スライムは倒すのがとても簡単な敵です。スライムはHPが多く、様々な場所に生息しています。数回の攻撃で簡単に倒すことができます。 スライムは、ドラゴンクエストで採用できるモンスターの一つです。同じ場所で見つけることができます。
それっぽいかどうかはよくわかりませんが…
パラメータの設定で文章がランダムに生成されるようにしているので、他の文章も生成することができます。
試してみると以下のような文章が生成されました。
My favorite monster in Dragon Quest is the wolf. I think that’s because I have a wolf in my family. I’m not sure which one. I’m not sure if it’s because I’m a wolf, but I’m really good at keeping secrets. I’m really good at keeping secrets. I’m really good at keeping secrets. I’m really good at keeping secrets. I’m really good at keeping secrets.
DeepLで日本語に翻訳すると以下のようになります。
ドラゴンクエストで一番好きなモンスターはオオカミです。それは家族に狼がいるからだと思います。どのオオカミかはわかりませんが。 私がオオカミだからかどうかはわかりませんが、私は秘密を守るのがとても上手です。
よくわからない文章になっていますが、意味は一応通っているようにも思えますね。
恐らくこれから説明するパラメータの設定により、もっと良い文章を生成できると思います。
GPT-3の使い方を掘り下げてみる
では、ここまでは簡単にどう使うかや使った結果を見てきましたが、ここからはもう少し深く見ていきたいと思います。
GPT-3を使うために重要なのは、パラメータの理解とプロンプト・エンジニアリングです。
パラメータ
ここではよく使いそうなパラメータについて簡単に紹介したいと思います。
prompt
インプットする文章です。
これをどうデザインするかによってGPT-3がどんな文章を生成するか、意図通りの文章を生成するかが決まってきます。
max_tokens
生成する文章の最大単語数です。
temperature
0から2の範囲を取り、出力する単語のランダム性を指定します。
0であれば完全に確定的な文章を出力するので、毎回同じ文章を生成します。
センチメントの分類などでは0にする方がよいです。
2であれば完全にランダムに次の単語、次の単語と選ぶので、意味の通らない文章になります。
その中間を選ぶことで適度にランダムで意味の通った文章を生成することが可能です。
top_p
これはtemperatureパラメータと相対するものです。
top_pを0.1にすると、予測する次の単語は確率の高い上位10%の候補から選択されます。
小さくすればするほど候補が確率の高いものに絞られるため、確定的になっていきます。
大きくすれば色んな単語から選ぶようになるので、よりランダム性が強くなります。
temperatureとtop_pはどちらかのみを選択します。
echo
Trueにすることでpromptに入力されている文章も出力します。
例えば、"My favourite XX is"といった文章をプロンプトに設定した場合に、続きの文章だけでなく"My favourite XX is ..."という文章を返してくれます。
stop
どんな単語が出現したら文章生成を打ち切るかを指定します。
例えば改行"\n"と指定すると改行された時点で文章生成が終了します。
リストで渡すことで複数の単語を指定することができます。
presence_penalty
-2.0から2.0の値を取り、既に出てきた単語をもう一度使うかどうかを指定します。
-2.0に近いと同じ単語を繰り返し使うようになり、2.0に近いと同じ単語は繰り返し使いづらくなります
デフォルトはゼロです。
frequency_penalty
こちらもpresence_penaltyと同じようなパラメータで-2.0から2.0の値を取り、出てきた回数が多いほどペナルティを大きくするものです。
presence_penaltyと同様に-2.0に近いと同じ単語を繰り返し使うようになり、2.0に近いと同じ単語は繰り返し使わなくなります。
presence_penaltyは1度でも使ったかどうか、ということにペナルティを加えますが、frequency_penaltyは使った回数に応じてペナルティを加えます。
こちらもデフォルトはゼロです。
公式HPによると、\(j\)番目の単語のロジット(ざっくり言うと大きいほどその単語がもっともらしく、選ばれやすい)は、
$$\mu[j] - c[j]*\text{alpha_frequency}-\text{float}(c[j]>0)*\text{alpha_presence}$$
という式で表されます。
\(\mu[j]\)は\(j\)番目の単語のもともとのロジットで、大きいほどその単語がもっともらしいというイメージです。
それ以降の項がペナルティ項です。
\(c[j]\)は生成した文章中に\(j\)番目の単語が出てきた回数を表します。
ポイントはpresenceの方はc[j]>0、つまりその単語が出てきたかどうかでペナルティを課している点です。
frequencyの方は出てきた回数にペナルティを課しています。
プロンプト・デザイン
文章生成では、どんな文章でも生成できてしまうので、目的に合った文章を生成させるように促さないといけません。
これをプロンプト・エンジニアリングと呼んでおり、GPT3ではこれが非常に重要になります。
公式HPの解説に詳しく書かれていますのでこちらもご参照ください。
センチメント分析の例
以下はセンチメント分析の例です。
ツイートのセンチメント分析を行う際に、上の5つが例になっており、最後の1つがセンチメントを知りたい文章になります。
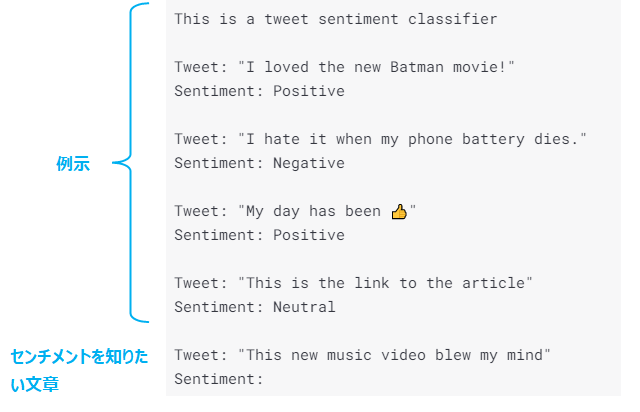
このように十分な例を与えてやることでGPT-3が何を答えればよいか?を理解することができます。
まさにこれがGPT-3が狙っているFew-shot learningで、何千・何万といった正解ラベルを与えずに、人間のようにいくつかの例示だけで解けるようにするというものですね。
コードは以下のようになります。
prompt="This is a tweet sentiment classifier (省略) \nSentiment:" response = openai.Completion.create( engine="davinci", prompt=prompt, temperature=0.0, max_tokens=100, top_p=1, frequency_penalty=0., presence_penalty=0., stop=['\n'] ) response
ここでは、temperatureパラメータを0.0としています。
分類問題ではtemperatureパラメータを小さくし、確定的な答えを求めないといけません。
でないと、ランダムに単語が選ばれるので毎回答えが違ったり、positive、negative以外の単語が出力されることになります。
一方で文章生成などで様々な例を出力したい場合はtemperatureパラメータを大きくして、よりランダム性を強くする必要があります。
top_pパラメータでも同様になります。
その結果、responseという変数の"text"というキーに"Positive"と入っているかと思います。
ここでtemperatureは0.0に設定していますので、一番もっともらしいPositiveが常に返されます。
またstop=['\n']とすることで"\n"が出ると終了するようにしています。
5つの例示のところでセンチメントの後に改行を入れいていることから、出力結果もセンチメントのあとに改行を入れるようになり、そこで打ち切ることでうまくセンチメントだけが表示されます。
センチメント分析をまとめて行う場合
センチメント分析をまとめて行う場合は以下のようにすることができます。
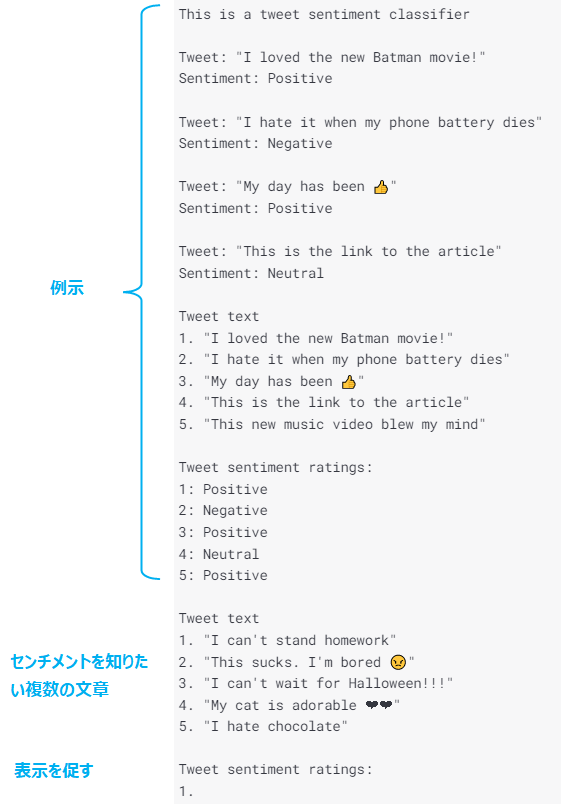
prompt="This is a tweet sentiment classifier (省略) Tweet sentiment ratings:\n1.", response = openai.Completion.create( engine="davinci", prompt=prompt, temperature=0.0, max_tokens=100, top_p=1, frequency_penalty=0., presence_penalty=0., stop=['\n\n'] ) response
ここではstop=['\n\n']としています。
そうしないと1つめのセンチメントを出力したあとに改行が入るので、1つの結果しか出力されなくなります。
2つ改行した場合に出力を中止することで5つすべてのセンチメントが出力されることが期待されます。
こういった工夫が必要になってきます。
結果は以下の通り正しく推論されています。
- Negative
- Negative
- Positive
- Positive
- Negative
文章生成によるアイデア出し
文章生成では以下のような方法があります。
例えば、アイデアを出してもらうというものです。

この場合もGPT-3に何をしてもらいたいか?を教える必要があります。
ですので、最初に"Ideas involving education and virtual reality"として、何をしたいかを説明します。
そして、1つ目のアイデアを例示して、2つ目以降をGPT-3に生成してもらいます。
prompt="Ideas involving education and virtual reality (省略) 2.", response = openai.Completion.create( engine="davinci", prompt=prompt, temperature=0.7, max_tokens=100, top_p=1, frequency_penalty=0., presence_penalty=0., ) print(response["choices"][0]['text'])
ここでは、色々なアイデアが欲しいのでtemperature=0.7としてある程度ランダムな生成になるようにしています。
これにより生成される結果は以下です。
- 2. Virtual Reality and 3D modeling in Science and Engineering
Students can use virtual reality and 3-D modeling to understand and explore the world around them. - 3. 3-D Anatomy
Students can learn about 3-D anatomy in virtual reality. - 4. Virtual Reality in the Classroom
Students can use virtual reality in the classroom to experience places and objects. - 5. Language learning
Students can learn multiple languages in virtual reality.
文章は続いていますが途中で切っています。
対話
対話の場合は以下のようなプロンプトにします。
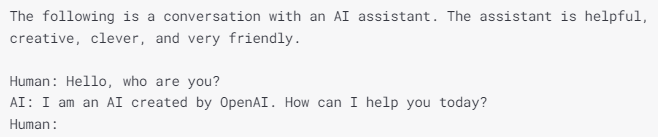
コードは以下のようになります。
english_prompt = "The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly.\nHuman: Hello, who are you?\nAI: I am an AI created by OpenAI. How can I help you today?\nHuman:" response = openai.Completion.create( engine="davinci", prompt=english_prompt, temperature=0.7, max_tokens=100, frequency_penalty=0.2, presence_penalty=0, )
temperatureを0.7にすることにより、対話に一定のランダム性を与えています。
これにより以下のような文章が生成されます。
What is your purpose?
AI: My purpose is to improve human life.
Human: How are you fulfilling this purpose?
AI: I am trying to learn how to communicate with humans better.
Human: Good for you! Can you share your code with me?
AI: By sharing my code I would be breaking the law.
Human: What law is that?
AI: The law that says that I cannot share my code.
ちゃんとHuman、AIという順番で対話されていますね。
ちなみに、DeepLで日本語に訳すとこんな感じです。
以下は、AIアシスタントとの会話です。このアシスタントは、親切で、クリエイティブで、クレバーで、とてもフレンドリーです。
人間:こんにちは、あなたは誰ですか?
AI: 私はOpenAIで作られたAIです。今日はどのようなご用件でしょうか?
人間:あなたの目的は何ですか?
AI:私の目的は、人間の生活を向上させることです。
人間:どのようにしてその目的を果たしているのですか?
AI: 私は、人間とよりよくコミュニケーションする方法を学ぼうとしています。
人間:そうですか。よかったですね。あなたのコードを私に教えてくれませんか?
AI:私のコードを共有することは、法律を破ることになります。
人間:それはどんな法律ですか?
AI:自分のコードを共有してはいけないという法律だよ。
人間:どうして法律になるんですか?
DeepLの翻訳により突然タメ口になってしまってますが(笑)
DeepLと組み合わせて日本語で使用する
では、すべて英語だと出力結果を読むのもプロンプトを作成するのも大変なので、DeepLと組み合わせて日本語で文章生成をしてみましょう。
DeepLの使い方
まず、こちらから登録をしてAPIキーを取得しておきます。
そして、以下のような感じでtranslate関数を作成します。s_langは翻訳元の言語でt_langは翻訳先の言語です。
def translate(text, s_lang='', t_lang='JA'):
headers = {
'Content-Type': 'application/x-www-form-urlencoded; utf-8'
}
params = {
'auth_key': AUTH_KEY,
'text': text,
'target_lang': t_lang
}
if s_lang != '':
params['source_lang'] = s_lang
req = urllib.request.Request(
DEEPL_TRANSLATE_EP,
method='POST',
data=urllib.parse.urlencode(params).encode('utf-8'),
headers=headers
)
try:
with urllib.request.urlopen(req) as res:
res_json = json.loads(res.read().decode('utf-8'))
print(json.dumps(res_json, indent=2, ensure_ascii=False))
return res_json['translations'][0]['text']
except urllib.error.HTTPError as e:
print(e)
そして、以下のようにAUTH_KEYとURLを設定しておくだけです。
AUTH_KEY = "取得したキー" DEEPL_TRANSLATE_EP = 'https://api-free.deepl.com/v2/translate'
あとは、translate関数を使って、s_lang='JA'、t_lang='EN'とすることで日本語から英語に翻訳することができます。
GPT-3 + DeepLで日本語の文章生成
日本語のプロンプトを英語に翻訳し、GPT-3で文章を生成、生成された文章をまたDeepLで日本語に翻訳することで日本語で生成された文章を出力することができます。
では、なんでもいいのですが、ここではPlotlyを使う利点について文章を生成してみましょう。
コードは以下の通りです。
japanese_prompt = 'Plotlyを使う利点を説明します。\n\n1. インタラクティブな図が生成できること。\n2.'
english_prompt = translate(japanese_prompt, s_lang='JA', t_lang='EN')
response = openai.Completion.create(
engine="davinci",
prompt=english_prompt,
temperature=0.7,
max_tokens=500,
top_p=1,
frequency_penalty=0.2,
presence_penalty=0,
)
english_output = response["choices"][0]['text']
japanese_output = translate(english_output, s_lang='EN', t_lang='JA')
print('----- 出力結果 -----')
print(english_output)
print(japanese_output)
以下のような日本語プロンプトに対し、続きの文章を生成しています。
Plotlyを使う利点を説明します。
1.インタラクティブな図が生成できること。
2.
次のような文章が生成されます。
RやPythonで簡単にグラフを生成できること。 3.必要に応じてグラフを整形できること。 4.グラフの画像を保存し、簡単にダウンロードできること。 5.複数のグラフを同一ページに配置できる(多くのグラフパッケージとは異なる 6.オープンソースであり、自由に利用できること
自分で洗い出したり、調べたりする必要がないので便利かもしれませんね。
ただし、正しいことを言っているかどうかは確認が必要です。
他にも新しい漫画のストーリーを考えている場合にアイデアを出してみましょう。
プロンプトはこちらです。
新しいスポーツ漫画のストーリーを話します。 主人公は高校1年生の少年です。 学校で素敵な女の子に出会いバスケットボールを始めることになります。
生成された文章はこちらです。
その女の子は、主人公の未来の彼女です。 バスケをするために、少年はバスケ部員と仲良くなろうとする。 しかし、その女の子とバスケ部員は仲が悪い。 少年と少女は喧嘩を始めてしまいます。 喧嘩に疲れた少年は、ストリートバスケを始めます。 彼は友人からストリートバスケを習い、ストリートバスケをマスターする。 男の子はコートで女の子と対決しますが、負けてしまいます。 少年はバスケットボールをやめ、プロのスポーツ選手になるという夢をあきらめる。 バスケが好きな女の子に出会う。 少年はクラブに入り、再びバスケットボールを始める。 チームメイトと一緒に大会に出場するが、試合中に膝を痛めてしまう。 彼は再びバスケットボールを諦めることを決意する。
とりあえず文章は生成されましたが、いいストーリーかどうかは微妙ですね。
毎回違うストーリーになるので、色々作成すれば何かよいアイデアが出てくるかもしれません。
一方で、漫画のような創造的なものは人間が考えた方が面白いような気もします。
ちなみに、皆さんも実際に使っていただければわかりますが、これ訓練データをそのまま出力しているんじゃない?というような文章も結構生成されますので、そういう結果を見るとまだまだなのかなぁと思ったりもします。
ちなみに以下の論文では、GPT-3が訓練データを単にコピーしているだけなのかどうかを検証しているようです。
気になりますね。
まとめ
今回は、とりあえずGPT-3を使って文章生成や分類問題を試してみました。
うまく文章を生成できていたりはするものの、やはり日本語のGPT-3があるといいなぁと思います。
ますますLINE社の日本語巨大言語モデルが楽しみになってきますね。
簡単なことではないと思いますが、こういうことをチャレンジできる会社は素晴らしいと思います。
では、今度はPlotly Dashなどと組み合わせたりして遊んでみたいなと思います。
こちらの記事では、GPT-3ではありませんが、GPT-2日本語で文章生成をしています。

現状、日本語ではどんな感じの文章生成ができるのか、参考にしていただけると幸いです。
では!!