2022年1月にrinna社が13億パラメータを持つGPT-2の日本語モデルを公開し話題になっています。
rinna社は2021年8月にGPT2-mediumという3億強のパラメータを持つモデルを公開していましたが、今回のGPT-1b(これもGPT
)はその4倍のパラメータ数です。
もともとGPT-2というモデル自体はOpenAI社がが開発した、巨大なモデルを巨大な文章データを使って事前学習することで、いちいち解きたいタスクにあったデータセットで学習しなくて済むような汎用言語モデルです。

ただ、上記の記事でも紹介していますが、日本語に特化したモデルではなく、やっぱり日本語で生活している人にとっては日本語のGPTが欲しくなりますね。
そこで、13億パラメータを持つGPT-2のモデルを日本語で学習して、公開してくれたのがこの「rinna」社です。
ということで今回は、この日本語GPT-2を触ってみたいと思います。
なお、今回はモデルの説明は一切ありませんので、詳細についてはこちらの記事を参照していただければと思います。
- GPT ... 『【論文解説】OpenAI 「GPT」を理解する』
一番仕組みを詳しく解説しています。 - GPT-2 ... 『【論文解説】OpenAI 「GPT-2」を理解する』
仕組みはGPTと大きく変わらないので、変わった点だけ解説しています。 - GPT-3 ... 『【論文解説】OpenAI 「GPT-3」を理解する』
基本的には結果の紹介です。
目次
GPT-1bの概要
ここでは、GPT2-mediumとの比較を中心にGPT-1bの概要を説明したいと思います。
GPT-1bの事前学習に使ったデータセットはこちらです。
GPT2-mediumで使ったデータセットからJapanese C4というデータセットが追加されています。
C4データセット(Colossal Clean Crawled Corpus)はGoogleのTransformerベースのモデルであるT5(Text-to-Text Transfer Transformer)で使われた“Webから収集された文章を集めたデータセット”で、その日本語のデータになります。
そして、パラメータ数はGPT2-mediumの3億強から13億に増えています。
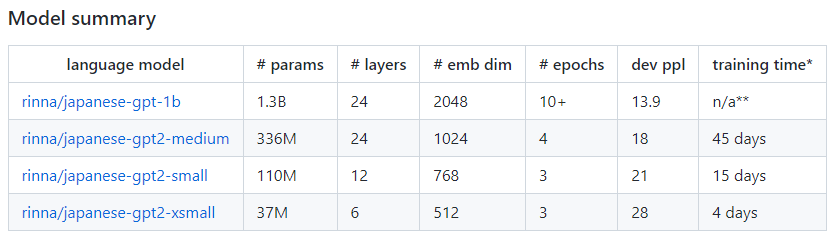
レイヤは同じ24ですが、埋め込みの次元が1024から2048になって、モデルが大きくなっています。
学習するエポック数が多くなっており、パラメータと学習データセットが増えた分、より多く計算しています。
そして、perplexityは13.9とgpt2-mediumの18よりもかなり減少しています。
イメージとしては、今までは次の単語を予測する際に平均的に18語の候補となる単語があったものが、約14語に絞られているようになったということです。
(perplexityの詳細はこちらの記事をご参照ください『【入門者向け】Perplexityを直観的に理解する』)
学習時間は、以前と環境が違うので記載されていませんが、そもそもmediumで45日間かかっていました。
なかなか個人でできるレベルではありませんし、企業でも大変そうです。
そういう意味でも、こういったモデルを公開してもらえるのは本当にありがたいですね。
gpt-1bの使い方
では、ここからは実際にGPT-1bを使ってみましょう。
Prompt Engineering
GPTでの文章生成ではprompt engineeringというものが重要になってきます。
prompt engineeringとは、目的に合った文章を生成するために、入力文章を工夫することです。
例えば、以下はrinna社のプレスリリースの例ですが、宮本武蔵についてどんな人かという文章を生成したい場合は、入力に「宮本武蔵は、」としています。
GPTの入力:宮本武蔵は、
GPTの出力:生涯人生を修行に費やし心を鍛え精進した人でした。そして宮本武蔵の弟子たちの記録も数多く残されています。
それによりその続きの文章が生成されます。
また、GPT-2、GPT-3はセンチメント分析をするように特別な学習されてはいませんが、以下のような入力をすることでセンチメント分析をすることが可能です。
GPTの入力:最悪だよはネガティヴ。いいねはポジティブ。素晴らしいはポジティブ。良くはないは
GPTの出力:ネガティブ。
何がネガティブで、何がポジティブという知識を与えてやり、それに従って「良くはない」のセンチメントを推論します。
この発想は人間がたくさんの例なしに、少数の例示や手ほどきがあれば、うまく答えを導きだせることを模倣しています。
続いて、翻訳です。
同様にGPTは翻訳のために特別な学習はしていません。
しかしながら、以下のように翻訳させるように入力を調整することでうまく翻訳してくれます。
GPTの入力:Helloは、こんにちはという意味です。Good morningは、おはようという意味です。Thank youは、
GPTの出力:ありがとうという意味です。感謝の気持ちを表す簡単なフレーズになります。
以上が、GPTを使った文章生成で重要なプロンプト・エンジニアリングです。
GPT-1bで文章生成
では、GPT-1bという学習済みモデルを使って文章生成をしてみましょう。
通常の文章生成
事前準備
まずは、トークナイザとしてT5Tokenizerを、文章生成のモデルとしてAutoModelForCausalLMをインポートします。
from transformers import T5Tokenizer, AutoModelForCausalLM import torch
そして、トークナイザとモデルを取得し、設定します。
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt-1b")
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-1b")
基本的にGPUを使いたいので以下のように設定します。
device = "cuda:0" if torch.cuda.is_available() else "cpu" model = model.to(device)
GPUを使わないと文章生成に結構時間がかかります。
文章生成
準備が整ったので、文章を生成してみます。
プロンプトに以下を設定してみます。
prompt = "人生を楽しくポジティブに生きていくための3つのこと。1."
「3つのこと」と言っているので、「1. ..., 2. ..., 3. ...」となって欲しいですが、どうなるのでしょうか。
以下のようなコードで文章を生成します。
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to(device)
with torch.no_grad():
output = model.generate(
input_ids,
max_length=100,
min_length=100,
do_sample=True,
top_k=500,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=5
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
for i in range(num_return_sequences):
print(decoded[i])
1行目でプロンプトを単語のインデックスの列に変換し、2行目から15行目で文章を生成しています。
16行目で生成された文章のインデクスの列を日本語に変換し、17、18行目で文章を表示しています。
パラメータの意味
簡単にパラメータの説明をしておきます。
- min_length、max_length
それぞれ最短の文章長、最長の文章長を表しています。 - do_sample
Trueとするとランダムに文章を生成します。
Falseを設定すると、決まった文章しか生成されなくなります。 - top_k
500を設定していますが、予測される文章のうち確率の高い500個のみを保持して文章を生成するということです。
(かなり粗い説明なので詳細は『ビームサーチ(Beam Search)を理解する』をご参照ください) - top_p
0から1までの値を取り、top_p=0.95は上位95%の単語から選んでいるという意味です。
top_p=0.1とすると上位10%の単語から選んでいるので、選ばれる文章のバリエーションが少なくなります。 - num_return_sequences
生成する文章の数です。
今回は5として5つ生成しています。 - その他
pad_token_id、bos_token_idなどで特殊な単語のIDを指定しています(あまり意識しなくても大丈夫かもしれません)
他にも、色々設定・チューニングできるので、うまく設定すると目的にあったより良い文章ができるかもしれません。
生成結果
プロンプトはこちらでした。
prompt = "人生を楽しくポジティブに生きていくための3つのこと。1."
では、生成結果を見てみましょう。
こんな感じの文章が生成されます。5つの文章のうちの1つ目だけを記載しています。
人生を楽しくポジティブに生きていくための3つのこと。1.楽しく行動する 2.自分の魅力を出し惜しみしない 3.感謝する まず、一番重要なことは「楽しく行動して人を喜ばせる」ことです。なぜか。これは、自分の脳を100%使ったアクションだからです。好きなことをしていたら、必ずその行動は、「楽しんでいるかどうか」をチェックされるようになります。好きなことをしていない人は、常に時間に追われていて、いつもせわしない表情をしています。一方、好きなことをしている人は、楽しんでいる表情をしています。
太字がプロンプトに設定した文章で、そのあとが生成された文章になります。
ちゃんと3つのポイントが生成されていますね!!
2つ目は以下です。ちょっと長いので途中までにしています。
人生を楽しくポジティブに生きていくための3つのこと。1.自分の価値観を押し付けるのではなく、相手の価値観も認めること2.我慢をすることが良いことではないこと3.ポジティブに人と向き合うことが大切。…
こちらも3つちゃんと生成されていました。
というように、色々な文章が生成されます。
次は以下のように、プロンプトを設定してみます。
prompt = "筋トレするメリット 1. 健康になる。 2. "
この場合は3つでなくてもよいですね。
文章生成のコードは同じなので省略しますが、以下のような文章がされました。
筋トレするメリット 1. 健康になる。 2. 美容・健康効果。2. 代謝アップ。3. 血流が良くなる。4. 基礎体力アップ。5. 筋力低下予防。6. ストレス解消に。7. 普段の生活でも役に立つ。8. 若返る。9. 糖尿病や認知症予防。 11. 病気予防。12. 病気進行予防。13. 病気予防。15. 筋力の衰えを防ぐ。 13. 強弱がある体になる。
11と13は同じ病気予防だったり、同じ意味の項目があったりしますが、全体的にうまくいっていそうです。
筋トレのメリットをブログやYouTubeなどで発信している人は、アイデアを出す上で参考になるかもしれませんね。
それ以外にも、もちろん普通の文章も生成できます。
成功している人が必ずやっていることは、絶対に勉強する・あらゆる事にチャレンジする・感謝を忘れない・笑顔でいるという事など多数あります。それがたとえどんな些細なことでも、毎日それを継続する事は、とてつもなく大変な事ですので、自分次第で小さな成功を積み重ねて下さい。そうすればいずれ自分本来の力は大きく花開いていきます。絶対諦めないでください。諦めない気持ちがあれば必ず夢はかなう。これが僕のメッセージです。私達が応援いたします。共に頑張りましょう!共に夢を叶えましょう!
何か既にありそうな文章ですが、基本的にランダム性を入れているので、まったく同じ文章というのは見つかりません(見つかりにくいだけかもしれませんが)。
センチメント分析
では、次に簡単なセンチメント分析をしてみましょう。
以下の入力にして、センチメントを予測します。
上方修正はポジティブ。下方修正はネガティブ。営業増益はポジティブ。営業減益はネガティブ。売上増加は
コードはこちらです。
prompt = "上方修正はポジティブ。下方修正はネガティブ。営業増益はポジティブ。営業減益はネガティブ。売上増加は"
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to(device)
with torch.no_grad():
output = model.generate(
input_ids,
max_length=30,
min_length=10,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=1
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
print(decoded)
ここでは、生成される文章が毎回違っては困るので、do_sample=Falseとしてランダムに文章を生成しないようにします。
以下のように、ちゃんと売上増加はポジティブと判定されています。
上方修正はポジティブ。下方修正はネガティブ。営業増益はポジティブ。営業減益はネガティブ。売上増加はポジティブ。
他にプロンプトを変えて、「粉飾決算」のセンチメントを予測した場合でもうまくいっています。
上方修正はポジティブ。下方修正はネガティブ。営業増益はポジティブ。営業減益はネガティブ。粉飾決算はネガティブ。
「営業赤字」として場合もうまくいっています。
上方修正はポジティブ。下方修正はネガティブ。営業増益はポジティブ。営業減益はネガティブ。営業赤字はネガティブ。
以下は、間違っている例です。
上方修正はポジティブ。下方修正はネガティブ。営業増益はポジティブ。営業減益はネガティブ。特別利益はネガティブ。
「特別利益」はポジティブなイメージですが、ネガティブと判定されています(ちなみに、特別損失はネガティブと判定されます)。
当然と言えば当然ですが、必ずしも思い通りに生成するとは限りません。
プロンプトをうまく設定すれば良いかもしれませんので、工夫が必要ですね。
足し算
では、GPT-3の論文で実験されていた足し算について見てみましょう。
GPT-3では2桁ぐらいの足し算について、ある程度できていました。
promptを"1+2="とます。
3が返ってくればいいですね。
prompt = "1+2="
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to(device)
with torch.no_grad():
output = model.generate(
input_ids,
max_length=5,
min_length=4,
do_sample=False,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=1
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
print(decoded)
ここでも、do_sample=Falseとして、ランダムに生成しないようにしています。
1+2=3
答えは"1+2=3"と正しく答えられました。
なかなかいけるんじゃないか、と思いましたが、"1+8="とすると
1+8=2
2という答えが返ってきました。
何とかならないものかと、プロンプトを"1+3=4。1+8="とすると、
1+3=4。1+8=9
無事9という答えが返ってきました。
とはいえ、他に色々な計算を試しても、やはり計算というのはなかなか難しいようです。
1300億強のパラメータを持つGPT-3と比較するのは酷ですね。
他にも色々できると思いますので皆さんでも試して遊んでみてください。
ファインチューニング
では、自分が生成したいドメインの文章を生成するために、ファインチューニングをしてみましょう。
(センチメント分析などのタスクのデータを使っているわけではないので、ファインチューニングというより“ドメインに合わせた追加の事前学習というべきなのかな?”と思いますが、ここではファインチューニングという言葉を使います)
で、やってみたのですが、Google Colab Proだとメモリが足りず、ファインチューニングが出来ませんでした。
ですので、とりあえず今回は3億パラメータのgpt2-mediumを使ってファインチューニングしたいと思います。
データセット

個人的に収集したキャンプサイトの口コミのデータセットを使用します。
サービスや設備などの6項目について、評価とコメントがあります。
項目:サービス
評価:5
コメント:店員さんの対応が素晴らしく良く満足ですね 気さくにいろいろな話してもらいました 平日でほぼ貸切だったちめ少し早く着いても柔軟に対応していただけました。…
上記のような文章が各項目について1万強ずつぐらいあります。
評価は1から5で5が一番良くて、1が一番悪くなっています。
このデータセットを使って、色々遊んでみたいと思います。
ファインチューニングのやり方
まず、ソースからtransformersをインストールします(でないと動かない場合があります)。
!pip install git+https://github.com/huggingface/transformers
続いて、SentencePieceとdatasetsをインストールします。
!pip install sentencepiece !pip install datasets
あと、以下のリポジトリにあるスクリプトををするのでリポジトリをクローンします。
!git clone https://github.com/huggingface/transformers
Google Colabを使っている場合、データを取得するためにドライブをマウントする必要があります。
from google.colab import drive
drive.mount('/content/data')
データのある場所に移動します。
%cd '/content/data/My Drive/data/'
requirements.txtを使ってインストールしろ、というエラーが出た場合は、以下でインストールしてください。
pip install -r ./transformers/examples/pytorch/language-modeling/requirements.txt
あとは、以下のようにrun_clm.pyを使ってファインチューニングすることができます。
!python ./transformers/examples/pytorch/language-modeling/run_clm.py \ --model_name_or_path=rinna/japanese-gpt2-medium \ --train_file=train.txt \ --do_train \ --num_train_epochs=3 \ --save_steps=10000 \ --block_size 512 \ --save_total_limit=3 \ --per_device_train_batch_size=1 \ --output_dir=output/ \ --overwrite_output_dir \ --use_fast_tokenizer=False
実際に実行してlossをプロットすると、以下のように減少していることがわかります。
RNNでスクラッチで学習した文章生成
GPTで文章を生成して見る前に、かなり前にこちらの記事『【データ分析実践】RNNを使って文章生成を実装してみる』で同じデータセットを使って学習した結果をみておきましょう。
こちらではRNNをスクラッチで学習しました。
以下のような文章が生成されています。
キャンプ場は ない と 勘違い し まし た が すぐ 見え まし た 。 川 は 高台 に
ある ので 腰 が 痛く なり そう です 。
山 の 斜面 を 登る ので 展望 隣 の フリー サイト は 直前 の ため 事前 確認
さ れ て いる 方 が 良い と 思い ます 。 カフェ → 写真 と 比べ て き て 少し 迷い まし た が 追加 か な ? )
夜 、 天の川 も 見え まし た 。 岩場 で 泳ぎ た 魚 を 焚い て い ない ほう
が 爽やか な だけ で 大 に する か です 。
設備 当方 は 木 が 多く 夏のこ 、 快適 に 過ごせ ます 。
早朝 の 時期 は 木 の 上 の 部屋 ( キャビン 内 の マット 可 ) も ある よう です
いちおう文章にはなっているような、なっていないようなという感じですね。
GPT2で生成した結果
では、同じ元データセットを使って、GPT-2(medium)を学習した結果を見ていきます。
タイトルからコメントを生成する
以下のようなタイトルとコメントをつなげた文章(原文を少し修正しています)を持つデータセットを作成しています。
リピートしたくなる快適なキャンプ場!: 注意事項等丁寧に説明してもらい、売店の品揃えも豊富で、大抵のキャンプギアなら忘れ物してもレンタルで対応できそうでした。
太字がタイトルで、そのあとがコメントです。
では、このデータセットで学習したモデル読み込みます。
from transformers import T5Tokenizer, AutoModelForCausalLM
import torch
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForCausalLM.from_pretrained("output/")
model.to(device)
model.eval()
そして、タイトルをプロンプトに設定して文章を生成します。
良い評価のサンプル
プロンプトは「最高の3日間でした!」にしてみます。
タイトルに合った文章が生成されるでしょうか?
num_return_sequences = 5
prompt = "最高の3日間でした!:"
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to(device)
with torch.no_grad():
output = model.generate(
input_ids,
max_length=100,
min_length=100,
do_sample=True,
top_k=500,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=5
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
for i in range(num_return_sequences):
print(decoded[i])
生成された文章を見てみましょう。
最高の3日間でした!: 今回初の家族キャンプでしたが、私たち夫婦はバギー体験を楽しみにしていました。実際は10分の1くらいしか乗っていませんが、ママ友とパパと子供3人、スタッフはみんな仲良しでした。(受付時にはバギーの説明を丁寧にしてくださり、安心できました。)気さくなスタッフさんがたくさんいて、いろいろ相談もしやすかったです
タイトルにあった文章が生成されていることがわかります。
他にも以下のような文章が生成されます。
最高の3日間でした!: スタッフの方々もとても親切で丁寧な対応をして下さいました。 4人で伺ったので、個室も使わせて頂き、他のお客さんとも合わず、ゆっくり過ごせました。 夜中にもスタッフの方が声がけに回って来てくださり、危ない事をしているグループがないか見回っていただいたり、声を掛けやすくとても良かったです。
しつこいですが、3つ目の文章です。
最高の3日間でした!: オーナーも大変親切でサイトの説明も大変分かりやすく良かったです。また、ゴミの分別などもとても分かりやすかったです。受付のおじさんは愛想が良く、お洒落なカフェバーのマスター?と思われます。 チェックイン、チェックアウトにも非常に丁寧で親切でした。10分程早く着いてしまいましたが、チェックインできるまで一緒に過ごして頂きました。
どれもうまく文章が生成されていますね。
さすがにRNNで生成した文章よりも遥かに精度が高いですね。
悪い評価のサンプル
では、続いてプロンプトを「最悪の3日間でした」にしたいと思います。
悪い文章が生成されることを期待します。
1つ目に生成された文章はこちらです。
最悪の3日間でした: スタッフの方々がとても感じがよかったので満足ですが、それと同時に過剰なサービスに戸惑いました。説明を聞かずに勝手に施設を利用されてしまい、追加料金をとられるという悲しい現実が待っていました。このようなトラブルが起こらないようにルールを厳しくするべきだと思いました。 とにかくスタッフの方々がすごいです!家族的な対応です。
「追加料金を取られるという悲しい現実が待っていました」という悪い出来事がしっかりと出てきていますね。
最後の1文はちょっと合っていませんが、それ以外はうまくいっているようです。
2番目の文章はこちらです。
最悪の3日間でした: チェックインの時間帯が早すぎます。チェックイン前にキャンプ場内のお風呂を案内された上に、管理棟の住所も聞かれ、困惑しました。スタッフからは、チェックイン時の注意事項の説明はきちんとしていただけましたが、チェックアウト後のお風呂の説明がなかったので、翌朝風呂に入ったらドライヤーが故障し、受付で事情を話すと、ドライヤーが故障したので新しいのを貸してほしいと申し訳なさ
ちょっと謎な文章もありますが、基本的に不満がある文章になっていますね。
項目と評価からコメントを生成する
では、次は項目(サービス、設備、自然、環境など)とセンチメントを付与したデータセットを作成して、学習させます。
次のような形で、「項目 + センチメント -> コメント」という形で整形します。
サービス + 非常に良い -> 店員さんの対応が素晴らしく良く満足ですね 気さくにいろいろな話してもらいました。
サービス + 悪い -> スタッフの対応は、普通でした。 しかし、大学生らしき集団が水鉄砲や水風船であそびだし、周りのお客さんにお構い無しの行動で目に余る状態。
項目と評価を指定して文章生成
では項目を“サービス”、評価を”非常に良い”として文章を生成します。
サービス + 非常に良い -> グランピングの方は、食材を用意してくれていたり、タープを用意してくれていたり、花火を分けてくれたり、かなりサービスがよかったです。シャンパンをくれました! 子供は夜も走り回っていたので、なかなか寝付けませんでしたが、スタッフの方が気にかけてくれ、寝る時も声をかけてくれるので、よかったです。 温泉のシャワーを夜10時から朝8時まで出してくれるので助かりました。
生成された文章は、ちゃんとサービスに関する内容になっており、しかも良いコメントですね。
続いて、“悪いサービス”の文章を生成してみましょう。
サービス + 悪い -> 従業員の接客に不満がありました。 特にハロウィンの時期にお菓子を配るのですが、受付時に渡される袋には、電話番号が書かれているだけではお菓子もらえないんです。それも30分くらい待ちました。駐車場も従業員が負担している感じ。ごみや分別などの説明も最低限でした。またサイトは管理されておらず、ゴミの処分には有料3000円を取られました。これは利用者が負担すべきです。
ごみの処分に3000円とは確かに不満ですね(笑)
項目を変えてみる
項目を「設備」にして文章を生成してみましょう。
ちゃんと設備に関する文章になっているでしょうか。
設備 + 良い -> 風呂つきのロッジを利用しました。 コテージとの距離は近く良かったです。 炊事場は、お湯が出るので助かりました。 トイレも清潔感があり良かったです。 バンガローにもハンモックなどもあり子供たちはとても喜んでました。 22時には消灯してくださいと注意書きがありましたが22時30分に何度も見回りの係の人達も回っていました。
お風呂や炊事場、トイレという設備に関するコメントになっていて、ちゃんとセンチメントも考慮されていますね。
では、「悪い設備」です。
設備 + 悪い -> 設備は必要な物がそろっておりサイトの広さも十分ありましたが、洗い場や場でお湯が出ず、立ち会いが必要になります。キャンプ場の広さから、お風呂なども作れないのではないかと思います。キャンプ場内には洗い場やトイレはありますが、サイト間が遠くシャワーなどは使いにくいです。
ちゃんと設備に関する内容になっており、悪いコメントになっていますね。
項目、評価と“話題”を指定する
では、続いて項目、評価を指定しつつ、開始の文章を指定してみましょう。
ここでは、「環境 + 非常に良い -> 夜景」として、夜景に関して良いコメントを生成してみましょう。
環境 + 非常に良い -> 夜景がよく見えたり海も近く、景観は最高です。 生鮮品も買い出しが出来るので便利でした。 周辺は住宅地ではありますが、静かで車の音も気にならないです。
環境に関する話題で夜景についてもちゃんとコメントされています。
悪い場合は次のようになりました。
環境 + 悪い -> 夜景を見るなら灯台まで行かなきゃダメなんですが駐車場が小さいので車で行くのは大変です。車で行くことをお勧めします。温泉は近くにあります。歩いて行くには山を登らないといけないので歩いて行くには少し面倒です。車で行くことをお勧めします。 夜景を見たいなら、その手前の山登り坂を登るしかないです。階段が急なので子供だけでは無理だと思います。
夜景で悪い文章はどうやって書くのだろうと思いましたが、「夜景を見るのに遠くまで行かない」という感じで、うまく文章が生成されています。
では、環境をサービスに変えてみましょう。
サービス + 良い -> 夜景を眺めながらくつろぐことができるバーがあり、スタッフの方も非常に親切でした。また、フロントにも本がたくさんあり、自由に使っていいそうです。アウトドア好きならたまらないと思います。売店にはなんでも売っているので忘れても安心です。薪は1束700円と格安で買うことができます。ストーブもありました。電源サイトもあるようでしたが、今回は利用しませんで
うまくできていますねぇ。
サービスと夜景をうまく絡めた文章が出来ています。
まとめ
ということで、今回は13億パラメータを持つ日本語版GPT-2の使い方などを見てきました。
かなりのケースでうまくいっていますが、うまくいかないケースも見られています。
しかしながら、個人的にはすごく可能性を感じさせてくれるモデルだと感じました。
今後もこういった日本語モデルが作られて、日本語のNLPが発展していくことを期待しています(上から目線)。
では!!