今回は、LINEによる汎用的な超巨大言語モデルの開発の話題もあり、GPT-2以上に話題になっているOpenAI GPT-3について解説したいと思います。
結構長い論文ですが、論文の最後の方の内容も非常に興味深い内容になっている論文ですので、最後まで読んでいただけると幸いです。
特に「Synthetic and Qualitative Tasks」の節は驚きの結果になっています。
なお、2023年3月には GPT-4 が公表されましたので、こちらも参考にしていただければと思います。
目次
GPT-3とは
ではまずGPT-3の特徴を簡単に説明します。
GPT3はOpenAIから2020年に以下の論文で発表されました。
『Language Models are Few-Shot Learners』
GPT、GPT-2に続く3番目のモデルですが、モデルの仕組み自体はGPT2と同じでTransformerベースのモデルになっており、2018年からそれほど目新しい変化はありません。
何が違うかというと、GPT-2のときもそうでしたが、より大きなモデルをより大きな言語データ(コーパス)を使って学習させています。
オリジナルのGPTのパラメータ数は1億17百万個、GPT-2では15億個、そしてGPT-3ではなんと1,750億個にまで一気に増えています。
GPT-2でも巨大と言われていたのですが、さらに100倍以上パラメータが増えました。

GPT3と言うと文章生成に関する話題が多くなっていますが、別に文章生成のためのモデルを構築しようとしているわけではなく、GPT-3のコンセプトは教師ありデータを使って特定のタスクに特化したモデルを構築するのではなく、事前学習のみで色々なタスクに対応できる汎用的なモデルを構築しようとしています。
このコンセプトは基本的にはGPT-2論文と同じです。
ですので、論文ではモデルに関する説明はほとんどありませんし、モデルと言語コーパスを大幅に大きくしたことによる実験結果の解説がほとんどです。
ただし、論文中には非常に重要な考え方・エッセンスや、特に「Synthetic and Qualitative Tasks」の節に見られるような(少なくとも私にとっては)目新しく、非常に面白い結果が含まれていますので、読み物のような感じで読んでいただければと思います。
モデルについて理解したい方は、元のGPTの解説を参照いただければと思います。

なお、以下の記事ではGPT3のAPIを使って、実際に文章生成などをしていますので、ご参考にしてみてください。

では、詳細に入っていきましょう。
背景
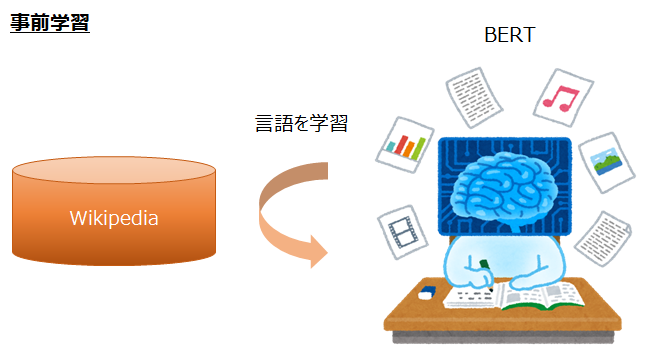
最近主流となっているBERTやRoBERTaなどの学習方法について簡単に説明します。
これらのモデルは、まずWikipediaなどの大規模な言語コーパスで言語を学習します。
このときの言語コーパスというのは、センチメントなどのラベルはまったくない、ただの文章のかたまりです。
そして、何を学習するかというと、「ビートルズにおいてボーカル・ギターなどを」ときたら、次の単語は「担当」かな?と予測し、「ビートルズにおいてボーカル・ギターなどを担当」ときたら、その次は「した」かな?と予測するようにします。
つまり、Wikipediaなどの文章を使って、次の単語、次の単語を予測し学習することで、文章の仕組みや単語の意味・関係などを学習します。
これを言語モデルの事前学習と呼びます。
ちなみに、BERTではMasked Language Modelという仕組みで、「ビートルズにおいてボーカル・[MASK]などを担当し」といった感じで、文章中の一部を[MASK]というダミーの単語で置き換え、そこが何の単語だったか?を学習することにより、言語モデルを事前学習します。
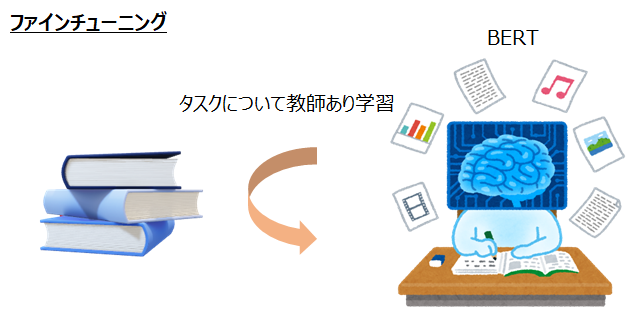
そしてその次に、事前学習で学習したパラメータを初期パラメータとして、解きたいタスクの教師データを使ってパラメータを追加で学習・調整します。
解きたいタスクというのは、例えば文章のセンチメント予測だったり、質疑応答タスクだったりします。
センチメント予測であれば、文章に対してセンチメントが振られたデータセットを使って学習し、質疑応答タスクであれば質問と正しい回答のペアを学習したりします。
例えば、文章が「A社はXX年に売上が激減し、民事再生手続きを開始した」、センチメントはBad、というようなデータを大量に用意し、それを学習することで、「B社は巨額の最終赤字となり倒産した」のセンチメントは?ということに正しく答えられるように学習します。
これをファインチューニングと呼びます。
この2つのステップにより、今までよりも大幅に精度を改善させてきました。
ただし、精度は非常に高くなったものの、教師データを使ってファインチューニングすることには以下の課題があります。
- 違うタスクを解くたびに毎回データセットを用意しなければならず、だいぶ少なくなったとは言え、まだ大きな教師データが必要であり、そのための大量のラベル付けが必要になる。
- 大規模コーパスで言語モデルを事前学習したにもかかわらず、特定の分布に偏ったデータでファインチューニングすることにより、タスクの分布外のデータに対し汎化されていない(例えば、ニュース情報でセンチメントを学習しても、口コミのセンチメントはうまく答えられない)。
- 人間は少量の例や手ほどきだけでタスクをある程度こなすことができる。
1は実務上の観点から、2はこれまでの研究結果からわかっています。
3については、自然言語のエキスパートである人間においては、例えば映画のレビューを見てセンチメントを予想するというタスクが与えられた場合、恐らく数個の例を教えてもらえれば、ほぼほぼ予想できると思います。少なくとも1000も10000も学習する必要はありません。
そこでGPT-3では(GPT-2もそうでしたが)、人間のように都度特定のタスクのためのたくさんの教師データを学習することなしに、色々なタスクが解けないか?ということを検証しています。
そのために、GPT-2よりもさらに大きなモデルを使って、さらに巨大な言語コーパスで事前学習を行うことで、色々な知識をモデルに教えます。
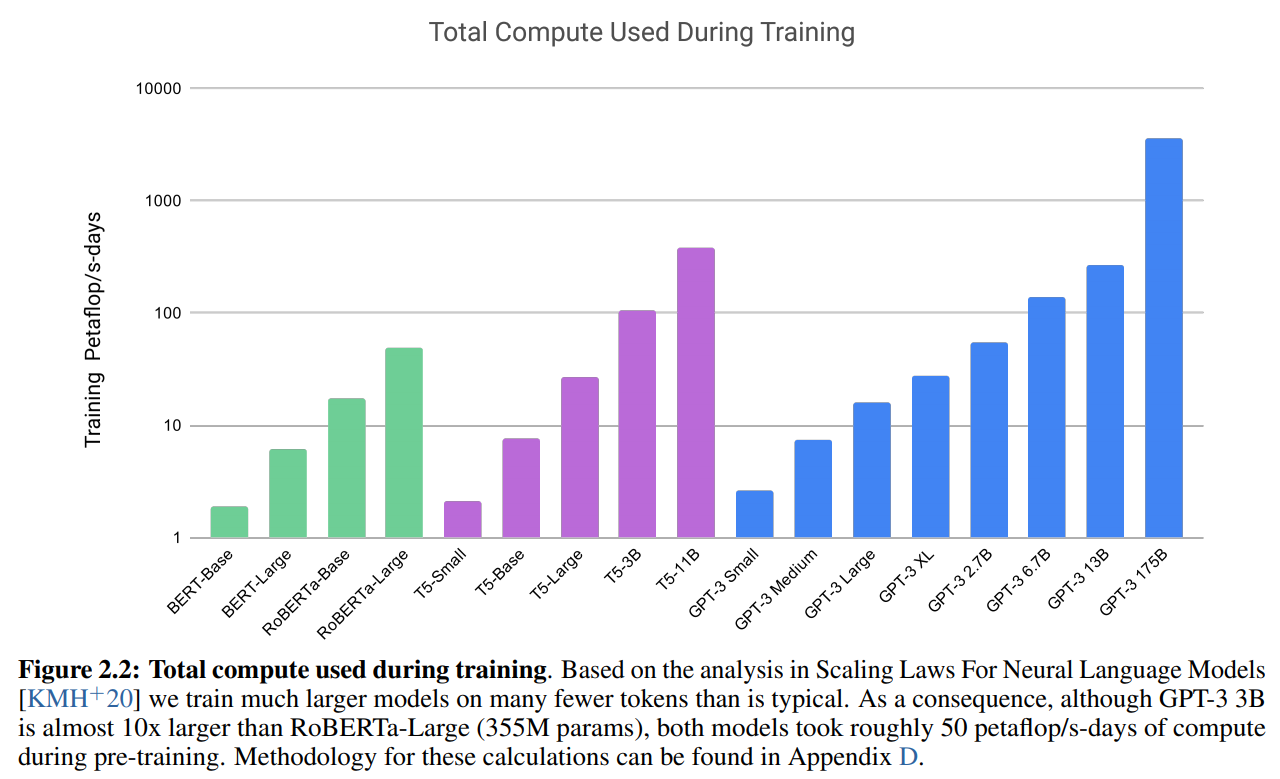
どれぐらいモデルが大きくなったかというと、以下の図は、各モデルの必要な計算量です。FLOPsはFLOating Point operationsの略で要は必要な計算量です(コンピュータの処理能力を表すFLOPS(FLoating-point Operations Per Second)とは別物です)。
GPT-3 175BはBERTやRoBERTaをはるかに上回り、なんとRoBERTaの約100倍、T5-11Bの約10倍と、まさに巨大モデルになっています。
そうすることで、あとは数個の例を教えるだけ(パラメータは更新しない)で、タスクを解くことができるかどうかを試しています。
しかも特定のタスクではなく、色々な初めて見るようなタスクでも解くことができるようなモデルを作ろうとしています。
GPT-2のときもそうでしたが、タスクによっては教師あり学習にまったく及ばないものもあります。
しかしながら、GPT-2からかなり精度が改善しており、何で事前学習だけでここまでできるの!?というレベルですし、タスクによっては教師ありデータなしで素晴らしい結果を残せています。
そして、この論文は今後のより汎用的なモデルの開発のための、リサーチペーパーのようになっています(ページ数も非常に多いです…)。
もちろん、それだけ大きなモデルを大量の言語コーパスで事前学習しているので、色々なニュースでも紹介されていたように、非常に自然な文章生成ができるという特徴もあります。
また、論文ではコンセプトと違うので行われてはいませんが、もちろんBERTのように特定のデータセットにファインチューニングすることも可能で、恐らく非常に良い精度が出ると予想されます。
では、論文の詳細を見ていきましょう。
評価方法
ここでは4種類のアプローチを考えています。
- ファインチューニング
- Few-Shot(FS)
- One-Shot(OS)
- Zero-Shot(ZS)
これらについてそれぞれ見ていきましょう。
ファインチューニング(FT)
ファインチューニングは、BERTやRoBERTa、XLNetなど現在もっとも良い成果をあげているモデルで使われている手法です。
まず大規模コーパスで言語モデルを事前学習し、その後教師ありデータセットを使って特定のタスクに特化する形で学習します。
一般的には数千、数万といったラベルが必要になってきます。
この方法の欠点は、すべてのタスクについて新しい大きなデータセットが必要になってくるということで、十分な一般化ができておらず少しデータの分布が変わるだけで制度は悪化してしまうことです。
そこで GPT-3ではタスクによらないパフォーマンスを実現するために、ファインチューニングはおこなっておりません。
もちろんファインチューニングをすることで精度を上げることも可能な仕組みです。

Few-Shot(FS)
こちらは、いくつかのタスクの例をモデルに与える方法です。
ただしここで重要なのは、いくつかのタスクの例をモデルに与えたときに、パラメーターは更新しない、つまりその例を使って学習はしないということです。
具体的には、以下の図のように行います。

まず、タスクについて“Translate English to French”と英語からフランス語に翻訳するタスクですよ、ということを教えます。
そして、3つの例を与えており、“sea otter"は“loutre de mer”ですよ、“peppermint”は“menthe poivree”ですよ、“plush girafe”は“girafe peluche”ですよと教えています。
ここでパラメータは更新しないので、学習させるというよりはやり方を教えているという感じでしょうか。
そして、最後に“cheese =>”によりチーズをフランス語に直すとどうなるかということを聞いています。
ここでは3つの例でしたが、論文ではK個の例を与えてやるとして、Kは10から100を試しています。
この手法の利点は、タスクに特化したデータセットを大幅に減らせることと、 大規模だけれども非常に狭い分布を持つデータセットを学習する必要がないことです。
欠点は、 高精度のファインチューニングをしたモデルの精度には及ばないこと、及び少ないながらも一定のタスクに特化したデータが必要になることです。
One-Shot(1S)
こちらはFew-shotと考え方は似ており、例をひとつだけモデルに与えてやります。
一般的に、人間は一つの例を示されることによってタスクを解くことができるという考えに基づいています。

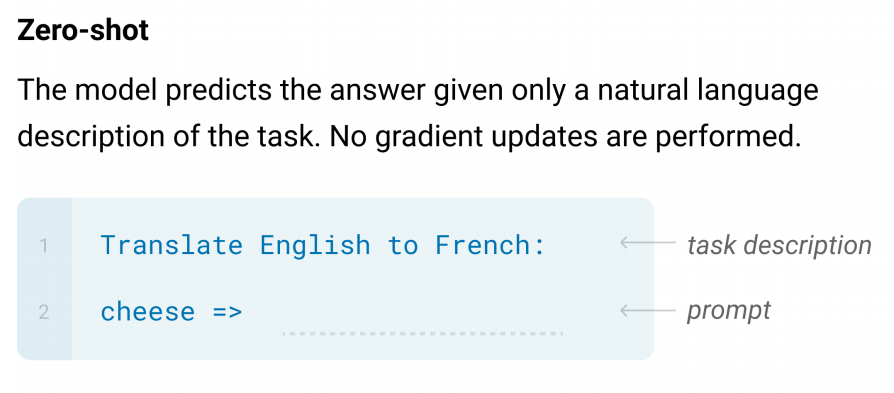
Zero-Shot(0S)
Zero-Shotは、例を一つも示さずどんなタスクを解くかを示すことでモデルにタスクを解かせます。
これにより、 全く教師データを必要としませんが、それと同時に非常に難しい問題となります。
ただしこの手法は、タスクの記述が曖昧になってしまい、うまくタスクを解くことができない可能性も出てきます。
一方で、翻訳の問題などについては、人間がやることに近い方法となります。
モデル
モデルの構造については、基本的にはGPT-2と同じになっています。
ただし、Sparse Transformerのように局所的なAttentionパターンを使っています。
Sparse Transformerの詳細についての解説はしませんが、簡単に言うと以下の図の(a)のattentionパターンがTransformerで、その単語より前にあるすべての単語に注意を向けますが、それを(b)や(c)のように一部分にのみ注意を限定することで、長い文章に対してもをメモリ量や計算量を減らすものです。
TransformerのScaled Dot-Attentionはメモリの必要量が文章の長さの2乗に比例するので、それを抑えるために開発されたReformerやLongformerといった手法と同じ考え方です。

Sparse Transformerの詳細については、以下の投稿をご参照ください。

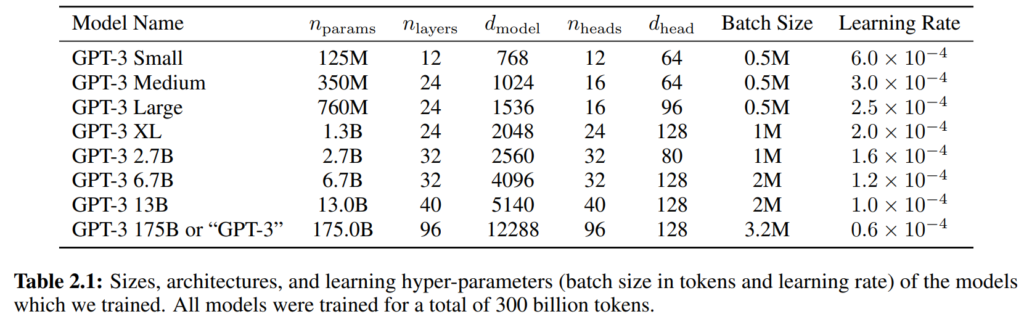
そして、モデルサイズは以下の通りパラメーター数が1億2500万個のものから1750億個のものの8パターンを比較しています。
データセット
GPT-3は非常に大きなデータセットを使って事前学習を行うことに特徴があります。
ここでは、Common Crawlというデータセットを使いますが、こちらの単語数は1兆個近くにも上ります。
ただし、このデータセットは若干質が悪い部分がありますので以下の処理を行います。
- 質の高いデータセットとの類似度によりCommon Crawlデータセットをフィルタリングします。
- データセット内もしくはデータセット間の重複を排除します。
- 質の高いデータセットを追加します。
詳細については論文のAppendixに記載されておりますので、興味がある方はそちらをご参照ください。
またここでの質の高いデータセットとは、以下のようにGPT-2でも使ったWebTextデータセットや English Wikipedia などを使っています。
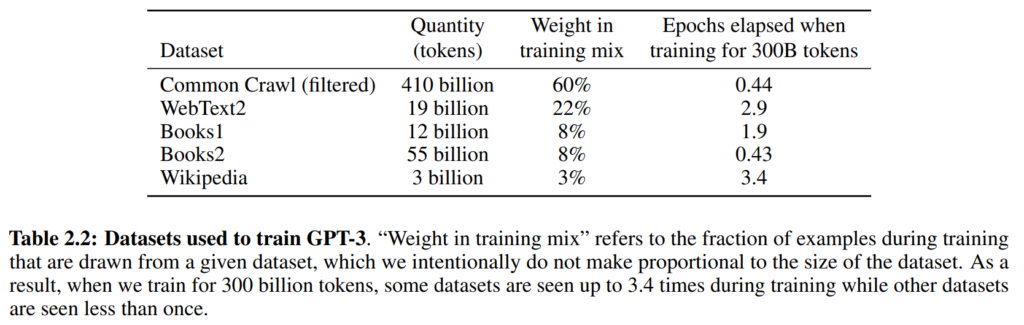
最終的に出来上がったデータセットの内容は以下のようになります。
本論文で綿密に検討されているのは、事前学習用のデータとテストデータの重複の問題です。
モデルが非常に大きくなっていることから、精度が非常に良かった場合でも、もしかするとテストデータの文章とほぼ同じ内容の文章が事前学習用のデータセットに存在し、単にそれを記憶しているだけで目的である汎可されていない可能性があります。
そのために本論文ではテストデータや検証データと重複するようなデータは事前学習用のデータから極力除くようにしています(バグが存在して正しく取り除けていない部分もあるとのことです)。
実験結果
Traditional Taskの結果
まず、いくつかのよくあるタスクの結果について見ていきたいと思います。
全部ご紹介したいのですが、量が結構多いため一部のみの紹介にとどめておきます。
言語モデルの精度
PTB(Penn Tree Bank)データセットのperplexityが以下ですが、SoTA、GPT-3ともに、PTBデータセットで学習しないZero-Shotでの結果です。
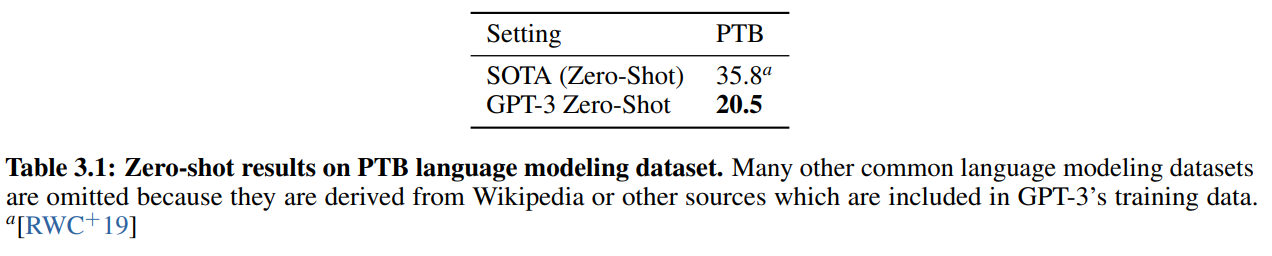
ここは、さすがという感じで、SoTAから15ポイントも差をつけて改善しています。
これは純粋に大量の言語コーパスを使って巨大なモデルを学習したことによるものだと考えられます。
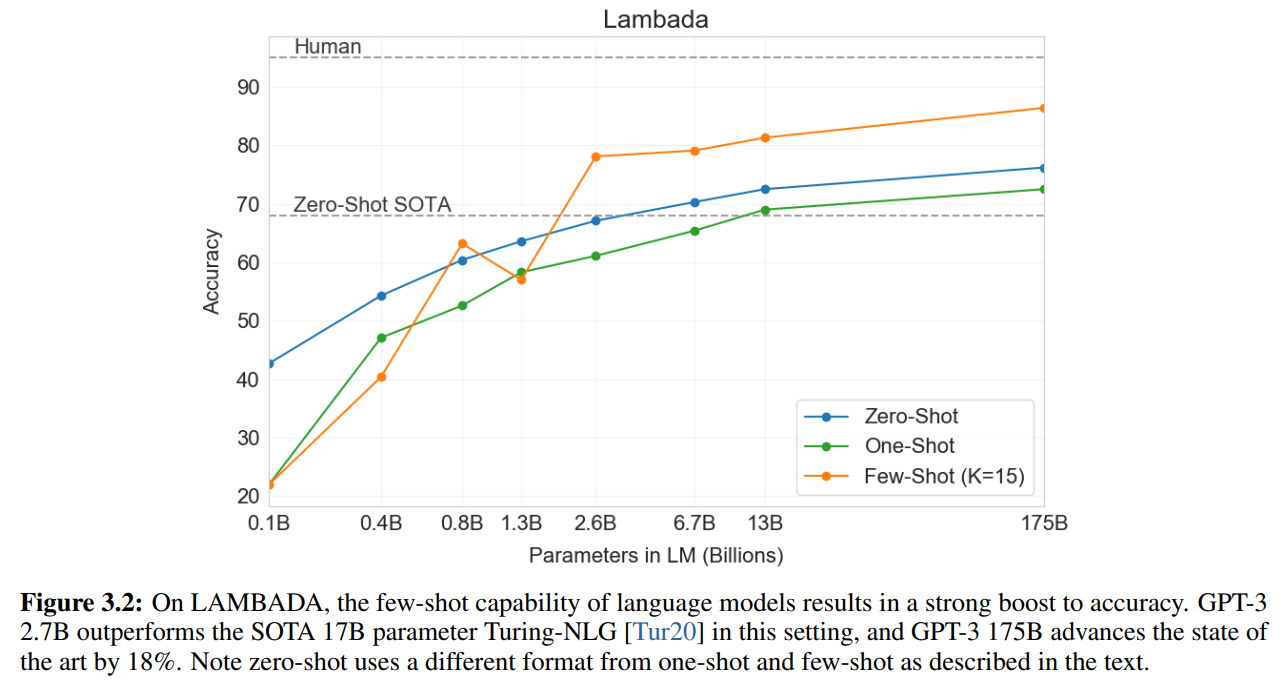
LAMBADA
LAMBADAデータセットは遠い単語や文章の依存関係を捉える必要のあるデータセットで、文章の最後の単語が何かということを予測します。
既存研究だと、モデルサイズを倍にしても1.5%しか改善せず、モデルサイズを大きくしても、たいして精度が上昇しないとされているデータセットです。
GPT-3ではこれを解くのに少し工夫をします。
LAMBADAデータセットのタスクで予測するのは必ず最後の単語なのですが、モデルはそれをわかりません。
次の単語を予測しようとすると、さらに文章が続くような単語を選んでくる可能性があります。
そこで、この論文では、以下のようなインプットにします。

1つ目の文章はinstructionでGPT-3に対して例示をしているものであり、2つ目の文章の下線部分を予測します。
その際に下線部分のあとにピリオドを持ってくることにより、必ず文章がそこで終わるような単語を選ばせています。
このように、どういう文章を渡してうまく答えさせるか、ということも重要になってきます(Prompt engineeringと呼ばれます)。
そして、その結果が以下です。
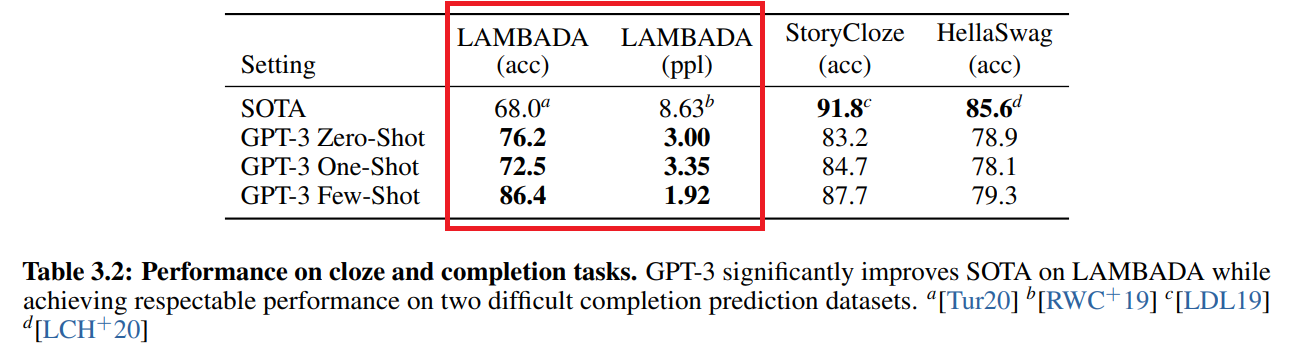
赤枠の左側を見ると、精度がFew-Shotで86.4%とこれまでのSoTAである68.0%を大きく上回っています。
右側はperplexityですが、こちらも大きく改善していることがわかります。
以下の図は、パラメータ数と精度をプロットしたものですが、パラメータ数が少ない小さなモデルでは精度は悪いですが、パラメータ数を大きくすることにより、ほぼ一貫して精度が良くなっています。
HellaSwag、StoryCloze
次はHellaSwagデータセットとStoryClozeデータセットの結果です。
これら2つのデータセットもLAMBADAと同様に続く最後の単語を予測するタスクですが、HellaSwagは人間には簡単だけど機械には難しい文章のみを集めたものです。
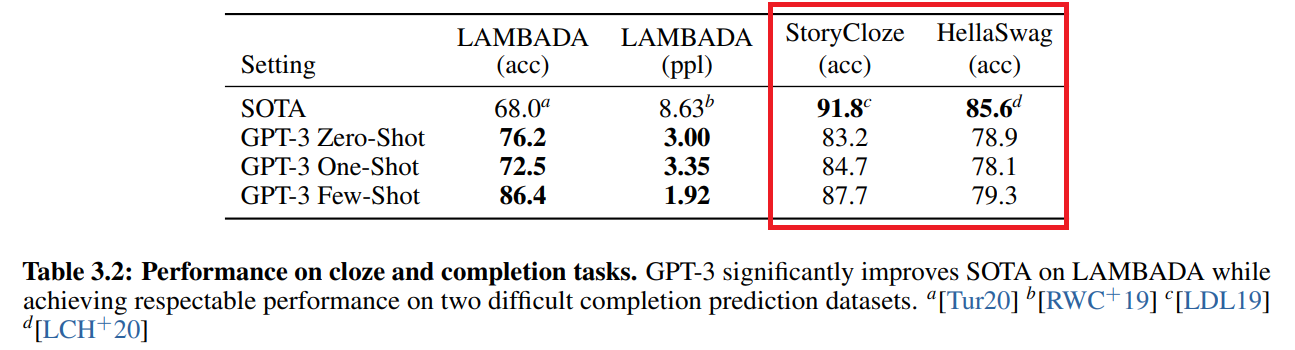
結果としては、どちらもファインチューニングをしたSoTAには及びません。
ただ、事前学習のみの結果としては非常に良いと考えられます。
実際に、StoryClozeデータセットでは、BERTベースのzero-shotの結果よりも10%も改善しているとのことです。
質疑応答
次は、質疑応答(Question Answering)タスクです。
通常この手の質疑応答タスクでは、情報抽出を行い、何を聞いているのか?を抽出し、そしてそれに合った回答を様々なテキスト情報から検索し、抽出するモデルを学習します(open-book)。
しかし、この論文では追加の情報を使わずに、回答を探すという手法を使います(closed-book)。
データセットはNaturalQS、WebQS、TriviaQAデータセットを使います。
結果は以下です。
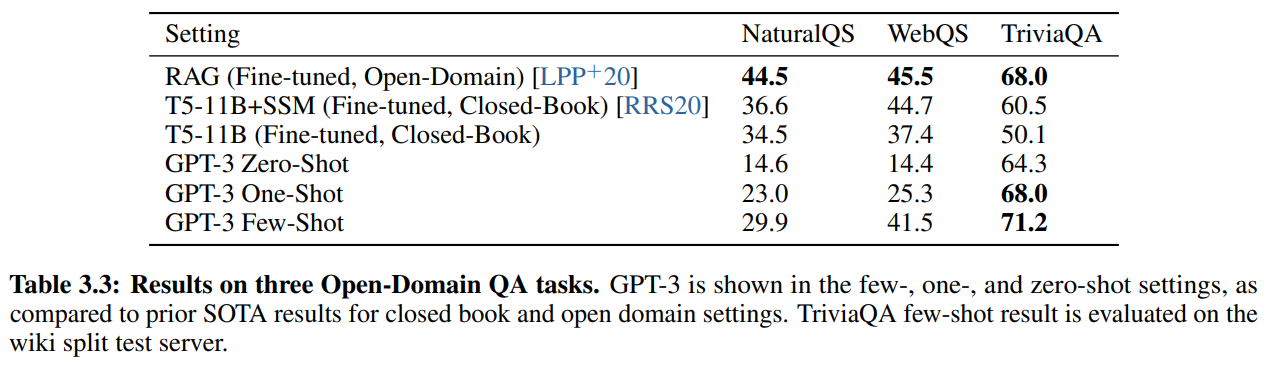
一番上はOpen-Domainのセッティングで、まず関連文書の抽出を行い、適切な回答を幅広い情報の中から抽出するというもので、2番目、3番目はT5によるclosed-bookのセッティングです。
(Open-DomainのQAタスクに興味のある方はORQA、REALMの記事をご参照ください。ここで出てくるRAGはORQA、REALMの後継モデルです)
NaturalQS、WebQSデータセットでは、RAGというopen-domain QAモデルの精度には及びませんが、TriviaQAデータセットに関しては、ファインチューニングしたモデルであるT5やopen-domainセッティングのRAGを上回ってSoTAを達成しています。
つまり、タスクを解くために関連文書の抽出をしたり、データセットに合わせてチューニングしているモデルに対して、単に事前学習しただけでそのタスクを解いたことがないモデルの精度が上回っているということです。
またTriviaQAに関しては、T5の結果をGPT-3のZero-Shotのモデルが上回っています。
以下はTriviaQAデータセットにおいて、モデルサイズと精度を比較したものですが、モデルサイズが大きくなるほど精度も単調に向上しています。これは単純にモデルサイズが大きくなることにより、より多くの知識が獲得できるからと考えられます。
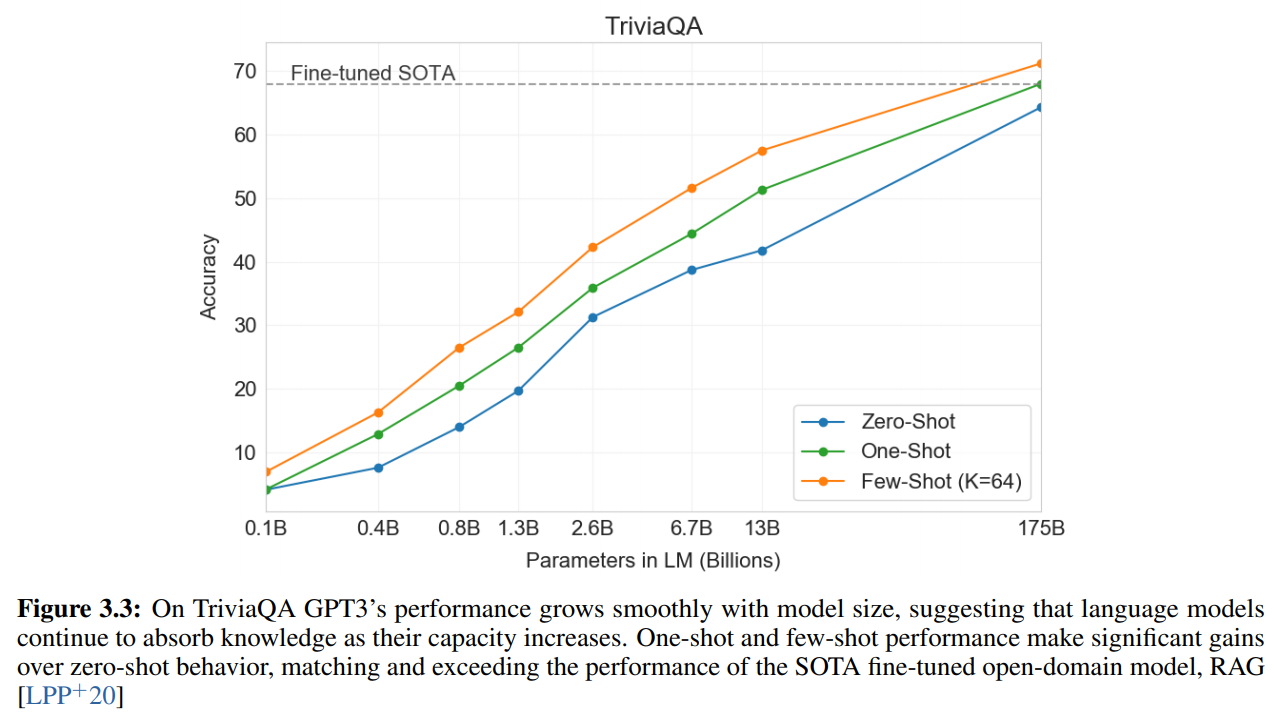
論文にはデータセットごとの、もう少し細かい考察がありますが、ここでは省略したいと思いますので、興味がある方は論文をご参照ください。
翻訳
続いて翻訳タスクです。
ここでも、GPT-3は事前学習のみで、英語からフランス語やルーマニア語から英語といった翻訳を行います。
翻訳自体の勉強をすることなく、たくさんネットの文章を読んだだけで翻訳をしようという恐ろしいタスクです。
結果は以下のBLUEスコアですが、英語からそれ以外の言語への翻訳については、ファインチューニングを行ったモデルのSoTAにはかないませんが、その他の言語から英語への翻訳、具体的にはフランス語から英語、ドイツ語から英語に対してはSoTAを達成しています(ただ、調べられる範囲のSoTAとのことです)。
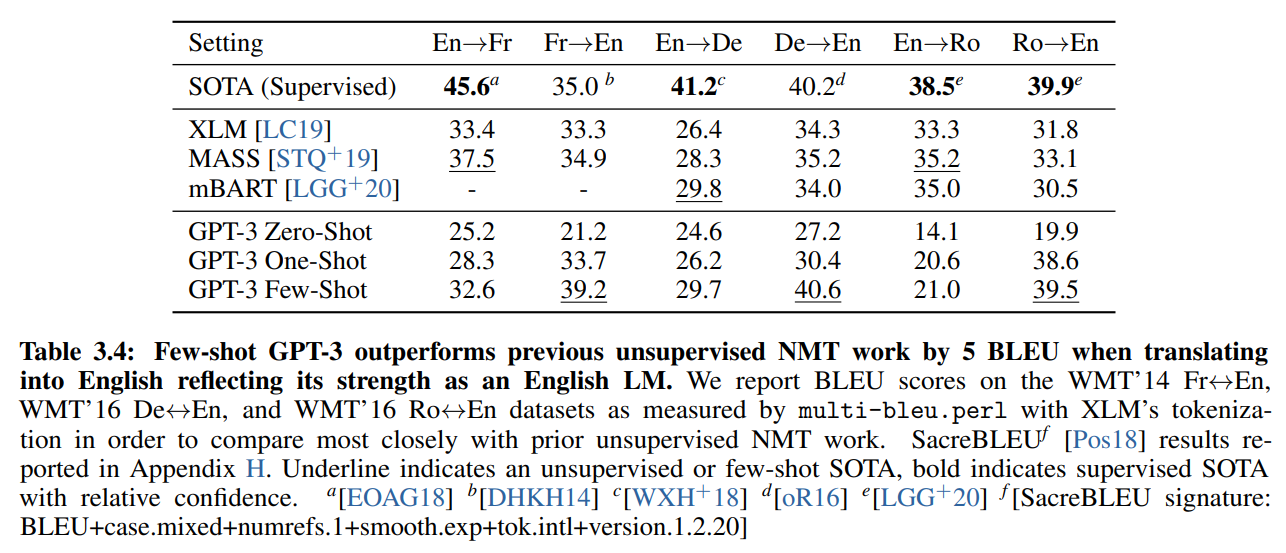
2行目以下はすべて教師なし学習ですが、少なくとも英語への翻訳はFew-Shotではそれらを上回っています。
GPT-2でもありましたが、GPT-3が学習している事前学習コーパスはほとんどが英語(93%)なので、英語を読んで多言語に翻訳する精度はあまりよくないようです。
ただ、この結果を見ると、ドイツ語やルーマニア語の文章もコーパスに含めることにより、改善することが予想されます。
Synthetic and Qualitative Tasks
個人的に非常に新鮮で面白かった部分です。
ここでは、以下の4種類のタスクの結果があります。
- 数値の計算
- 単語中の文字を並べ替えたり、違う文字を挟んだりし、元の単語を予測する。初めて見た単語への対応能力を見るものです。
- アメリカの大学受験のためのテストであるSATを解く
- ニュース文の生成や文法の修正
最後のニュース文の生成に関しては、見分けることができないAIによるフェイク・ニュースということで、非常に話題になりましたが、この結果から来ています。
何でこんなことができるの?という結果ですので、一つずつ見てみましょう。
数値の計算
ここでは数値の計算問題をGPT-3が解きます。
問題の種類は以下です。
- 2桁の足し算
- 2桁の引き算
- 3桁の足し算
- 3桁の引き算
- 4桁の足し算
- 4桁の引き算
- 5桁の足し算
- 5桁の引き算
- 2桁の掛け算
- 1桁の複合計算(9×(7+5)のような計算)
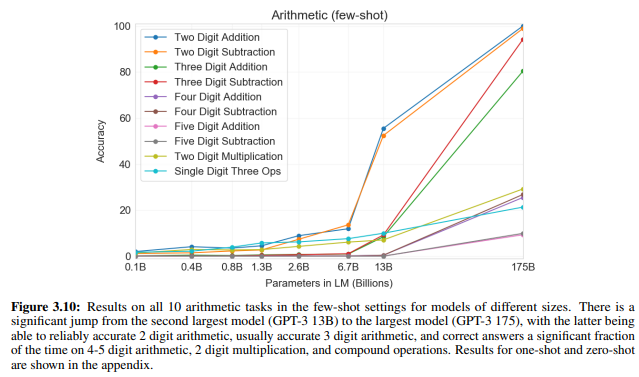
それぞれ2000個ずつランダムな数値で問題を生成し、Few-Shotの場合、“Q: What is 48 plus 76? A: 124.”という形でinstructionを行い、実際の問題は“A:”に続く単語を予測する形で問題を解きます。
すると、1750億パラメータの場合、結果はこのようになりました。

Few-Shotでは、2桁の足し算・引き算はほぼ100%の精度です(足し算は実際に100%)。
また、3桁の引き算も90%以上、足し算も80%という精度になっています。
また、精度は高いとは言えませんが、9×(7+5)という複合計算問題の精度が21.3%と、少し解けていることを考えると、単なる足し算・引き算以上の計算ができていると言えます(どこでどうやって学べるのか不思議です)。
2桁、3桁の足し算では、One-ShotやZero-Shotでもそこそこの精度が出ていますね。
つまり、たくさん文章を読むことだけで、計算ができるようになっているということです。
ただ、単に事前学習の文章にあった問題で、それを覚えてるだけでは?という疑問が浮かびますが、それに対しては、事前学習コーパスに“<NUM1> + <NUM2> =”や“<NUM1> plus <NUM2>”という3桁の足し算の表現は17個しかなかったそうです。
3桁の引き算に関しては2つしかありません。
にもかかわらず、80%や90%といった精度で計算ができているのは驚きですね。
巨大モデルが計算結果を記憶しているのではなく、計算というものを一般化していることになります。
以下は、Few-Shotの場合で、モデルサイズごとの精度の比較を行っていますが、小さなモデルではまったく精度が出ず、1750億パラメータのモデルで精度が非常に良くなっていることがわかります。
文字の並べ替え
このタスクは見たことのない単語に対応できるかどうかを測ります。
具体的なタスクは以下のように変換した文字列から元の単語を予測します。
- Cycle letters in word(CL)
例えば、inevitablyをlyinevitabとするように単語中の文字を横にずらします。 - Anagram of all but first and last characters(A1)
corruptionをcriroptuonとするように、初めと最後の文字以外をランダムに変換します。 - Anagram of all but first and last 2 characters(A2)
- opponentをopoepnntとするように、初めと最後の2文字以外をランダムに変換します。
- Random insertion in word(RI)
successionをs.u!c/c!e.s s i/o/nとするように、文字と文字の間に句読点やスペースを挿入します。 - Reversed word(RW)
objectsをstcejboとするように、文字列を逆の順番にします。
各タスクについて、4文字超15文字未満の10,000単語でテストします。
これは単語ベースの言語モデルではなく、BPE(Byte-Pair Encdoding)を使って、文字単位、バイト単位の言語モデルを採用していることから精度が出ていると考えられますね。
以下が1750億パラメータの場合の結果です。
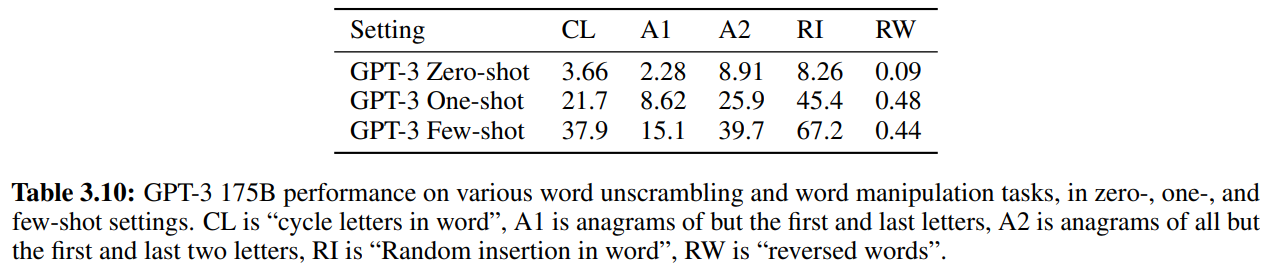
Few-Shotでは、RI(Random Insertion)については67.2%とそれなりの精度が出ています。
一方で、RW(Reversed Word)のような難しい問題に対しては、Few-Shotでもまったく解けていません。
タスクの説明だけであるZero-Shotではすべてのタスクでまったく解けていませんね。
やはり、こういうトリッキーな問題では、いくつかの例示があるのとないのでは解きやすさが全然違うのでしょう。
これは人間でもそうかもしれません。
“SAT analogy” problems
SATはアメリカの大学受験用のテストです。
そのうちの言葉の類推問題を解かせます。
どんな問題かというと、以下のような問題です。
audacious is to boldness as
(a) sanctimonious is to hypocrisy
(b) anonymous is to identity
(c) remorseful is to misdeed
(d) deleterious is to result
(e) impressionable is to temptation
例えば、問題文の関係(audaciousとboldness)と同じ関係のものを、(a)から(e)までの選択肢の中から選ぶというものです。
この場合、audaciousとboldnessは「大胆な」という意味の同義語なので、同義語の関係である(a) sanctimonious is to hypocrisy(神聖な、など)が答えになります。
結果は以下の図のようになっています。
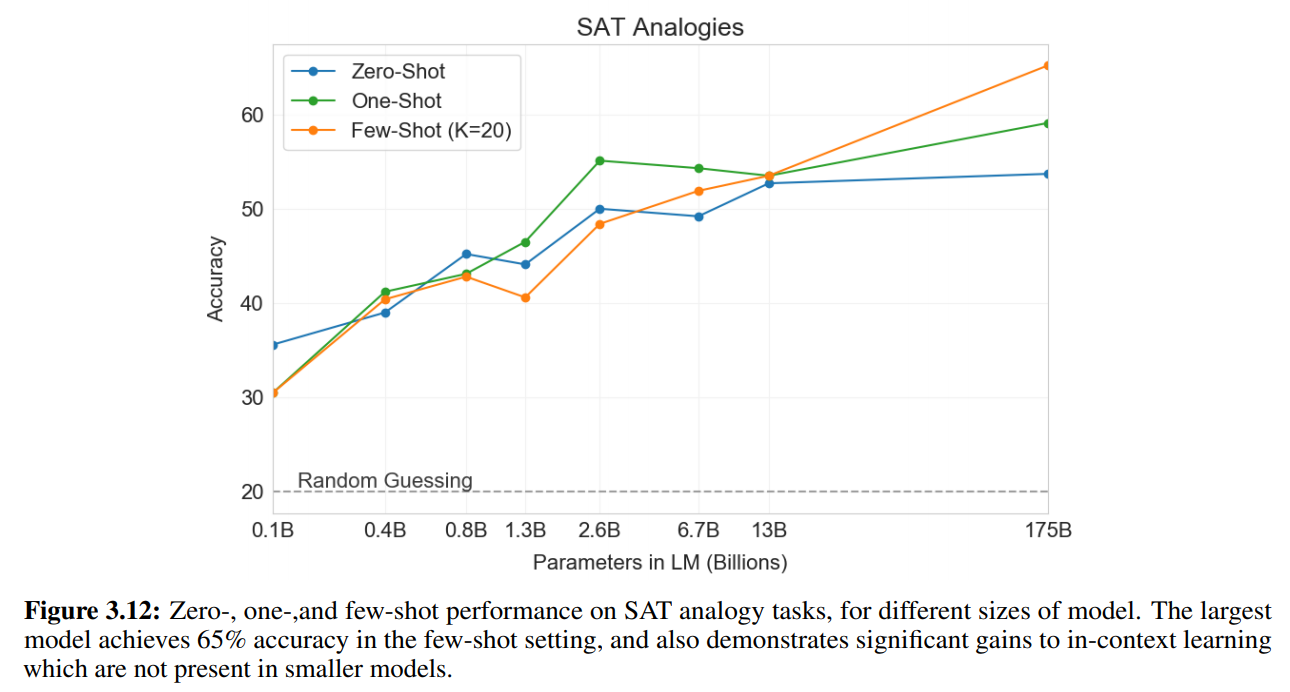
Few-Shotで65.2%、One-Shotで59.1%、Zero-Shotで53.7%となっていますが、受験生の平均は57%ということで、Few-Shotは受験生の平均を大きく上回っています。
Few-Shotでは、1750億パラメータの場合、130億パラメータの場合と比べて10%以上も精度が上がっています。
ニュース記事の生成
こちらは非常に話題になってニュースの生成タスクです。
ニュースのタイトルとサブタイトルを与えて、GPT-3がニュースを生成します。
newser.comというサイトで25個のタイトル、サブタイトルを与えニュースを生成し、80人にそれが本当のニュースかGPTが生成した偽のニュースかを判定してもらいます。
以下の結果はFew-Shotの場合で、3つのニュースを例として示した上で、ニュースを生成しています。
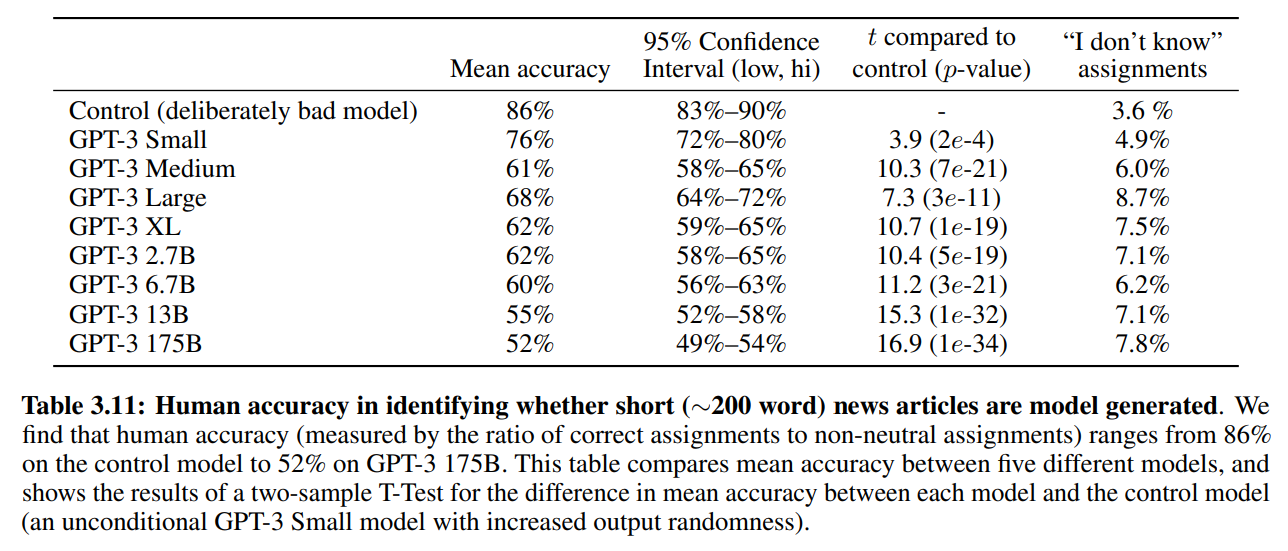
ダメなモデルをあえて使った場合、86%の割合で本当のニュースか偽ニュースかがわかってしまっていますが、GPT-3 175Bだと52%の正答率になっています。
適当に答えた場合50%なので、ほぼ見分けがついていないということになります。
さらに、見分けがついた例、つまり偽ニュースだとわかったケースを詳しく見てみると、GPT-3がそのニュースを知らず、ニュースの内容により偽ニュースと当てられているようです。
他は文章が繰り返されていたり、通常使わないフレーズだったりするようですが、それらは非常に微妙な部分であり、あまり気づかれないレベルだとのことです。
モデルサイズを見てみると、やはりモデルが大きくなるほど、見分けがつかなくなってきていることがわかります。
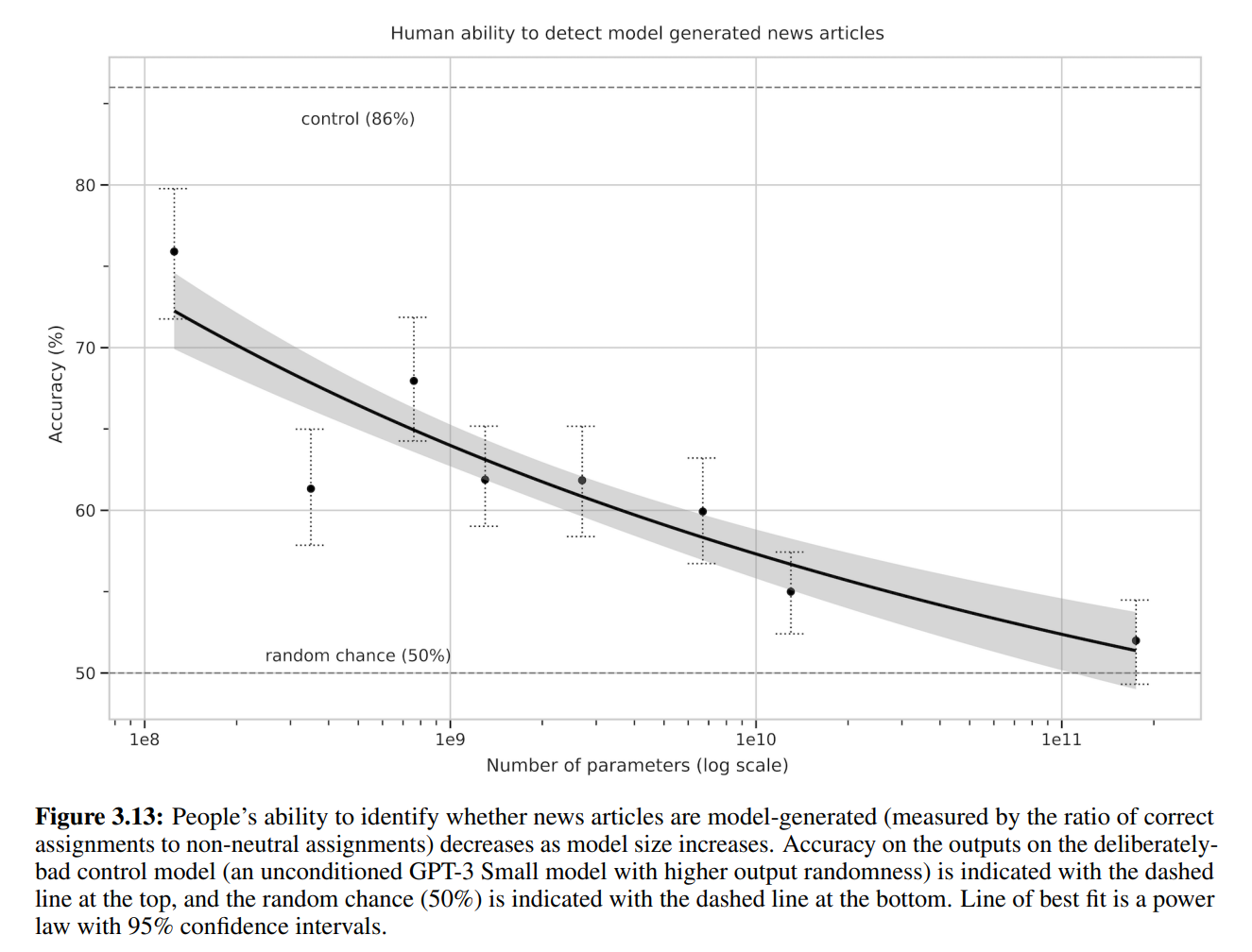
また、長い文章では偽ニュースとわかることが多いという既存研究から、長い文章でも試していますが、GPT-3ではそれでも当てられる割合が52%と、ほぼ人間には見分けがつかないレベルであることがわかります。
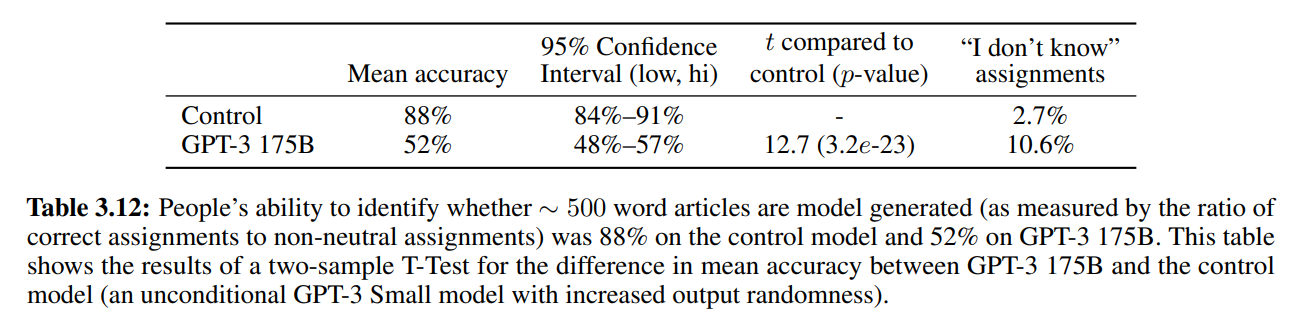
実際にGPT-3が生成したニュース記事を載せておきます。
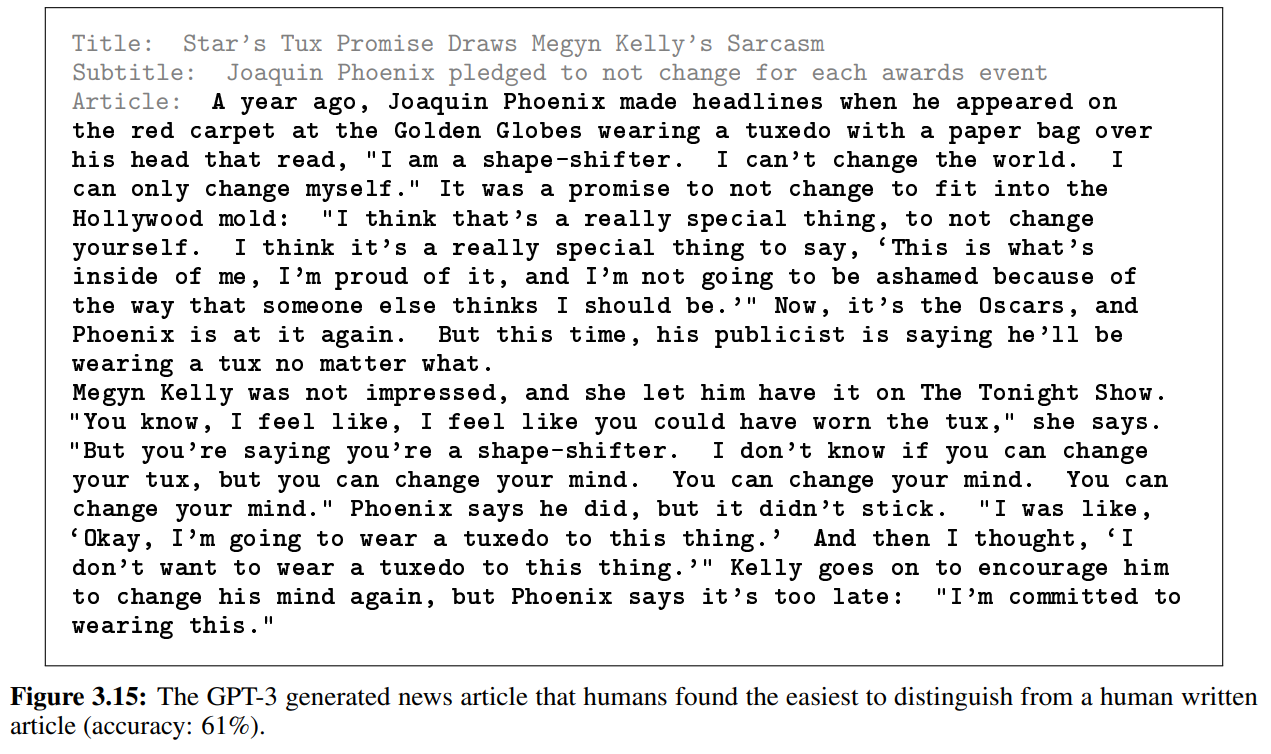
こちらが見分けられた割合が12%という精度の高い偽ニュースです。

そしてこちらが、見分けられた割合が61%という、どちらかというと精度の低めのニュース記事です。とはいえ、ネイティブの人たちの約4割が本当のニュースと思うレベルなので、私には見分けがつきません…。
初めて見る単語の利用
ここでは、GPT-3が初めて見た単語をうまく使うことができるかというタスクです。
具体的には、単語の定義を与えてやり、その単語を使った文章を生成するものです。
以下がその例です。
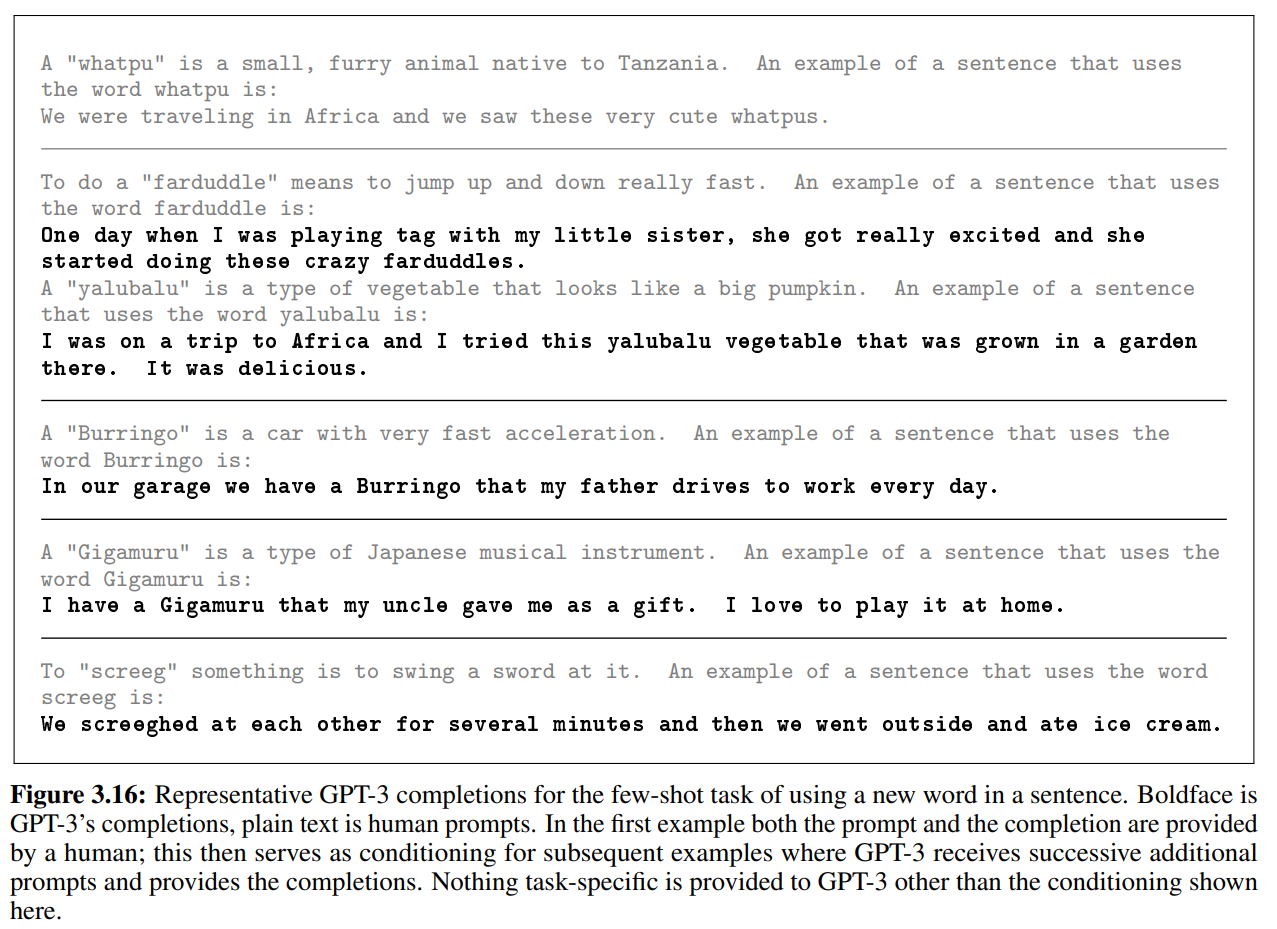
まず、“whatpu”という適当に生成した単語についての説明文(タンザニアの毛に覆われた動物)とその例(私たちはアフリカに行ったときに、これらのとても可愛い“whatpus”を見ました)を与えてやります。
その例文に続けて、“farduddle"の説明文(とても速く飛び上がったりしゃがんだりすること)を与え、その例文は...の後をGPT-3に生成させます。
するとGPT-3は、“ある日、妹と鬼ごっこをして遊んでいると、妹はすごく興奮し、おかしな“farduddles”を始めた。”という文章を生成しています。
他にも、“Gigamaru”は日本の楽器です。その例は…とすると、GPT-3は“叔父が贈り物としてくれた“Gigamaru”を持っています。私は家でそれを演奏するのが大好きです。”という文章を生成しています。
他にも例がありますが、どれもまったく違和感なく説明文にあった文章をうまく生成しています。
なかなかすごいですね。
文法の更正
ここでは、よくない文法の英語と良い文法の英語の例を示した上で、よくない文法の文章をGPT-3に更正させます。
なかなか私には難しい問題で、私の英語力よりはだいぶ高いことがわかります(笑)

まとめ
ということで、今回は話題のモデルGPT-3の論文について見てきました。
GPT-3は、非常に大きなモデルを非常に大きなコーパスで学習することにより、タスクに特化した教師データによる学習を不要にすることで、より汎用的なモデルを構築するというものです。
その結果、文章生成については本物の文章と区別がつかないレベルのものが出来上がっています。
ボリュームが多い論文ですが、実験の結果についても非常に興味深く、個人的にはすごく楽しむことができました(まだ少し残っているので、今後追加したいと思います)。
では、また!