今回は、ドメインが指定されていない質疑応答タスクであるOpen Domain Question AnsweringをEnd-to-Endで学習するモデル「ORQA(Open-Retrieval Question Answering)」を解説したいと思います。
オープン・ドメインの場合、近年では一般的に、まず知識用のコーパスから関連する文書を抽出し、その抽出された文書から質問に対する答えを探しだすという2ステップを使います。
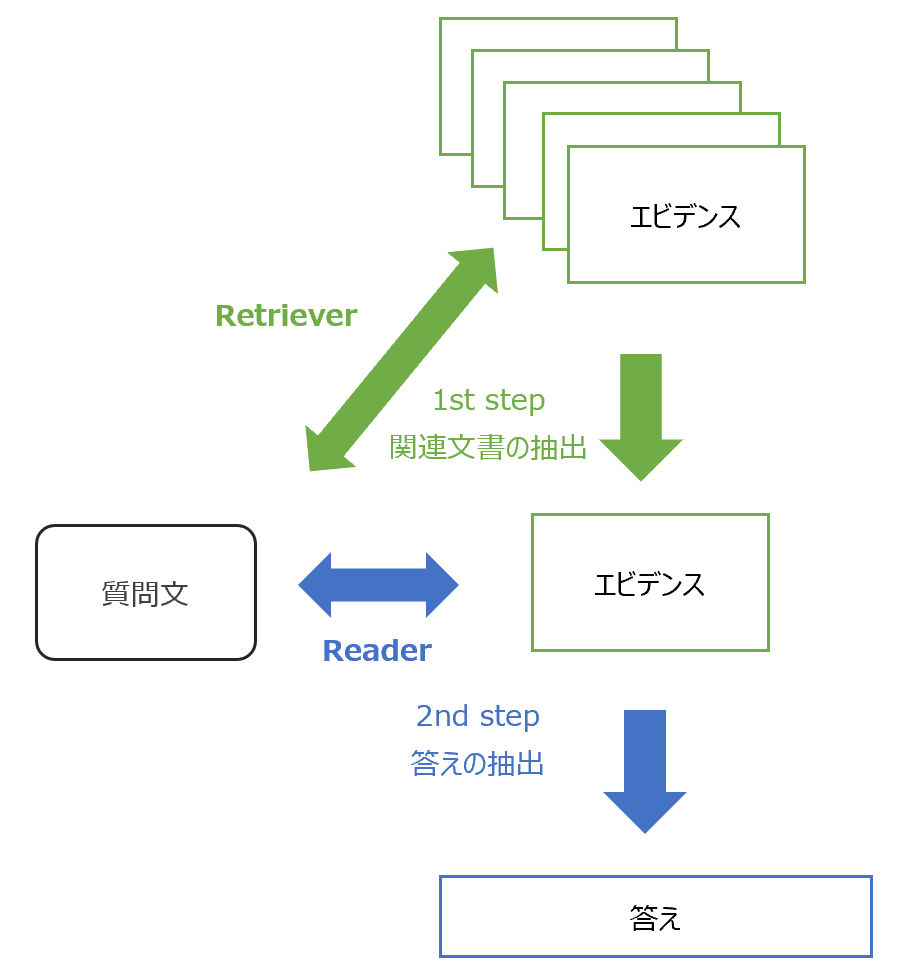
従来のモデルでは、この2つのステップは完全に分かれていて、Retieverによる関連文書の抽出、正しい文書からReaderによる答えの抽出を別々に学習していました。
ORQAではそれをEnd-to-Endで学習で、一気通貫で学習きるうようにしています。
また、文書の抽出にはDrQAのようにTF-IDFではなくBERTを使っています。
これにより、単語の出現回数だけでなく文脈に応じた文書の抽出が可能になります。
ReaderにもBERTを使用しており、現在の自然言語処理の発展に合わせています。
では、論文の詳細を見ていきましょう。
『Latent Retrieval for Weakly Supervised Open Domain Question Answering』
目次
タスクの特徴
まず、タスクの特徴を簡単に見ていきます。
質疑応答タスクは「Reading Comprehension」と「Open-domain QA」に分かれます。
「Reading Comprehension」は、質問文に対して、あらかじめ答えが載っている文書が特定されており、そこから答えを探すというものです。
SQuADというデータセットが有名です。
一方で、「Open-domain QA」は答えが載っている文書(エビデンス)は与えられておらず、自分で探してこないといけません。
エビデンスにはWikipediaなどを使います。
特に今回のOpen Retrieval QAでは、Wikipediaから該当する記事を抽出するところ、そこから答えを探すところを一気通貫で学習します。
まとめると以下のようになっています。
ORQAの仕組み
全体の仕組みは以下のようになっていますので、ときどき見返しながら読んでいただけるとわかりやすいと思います。
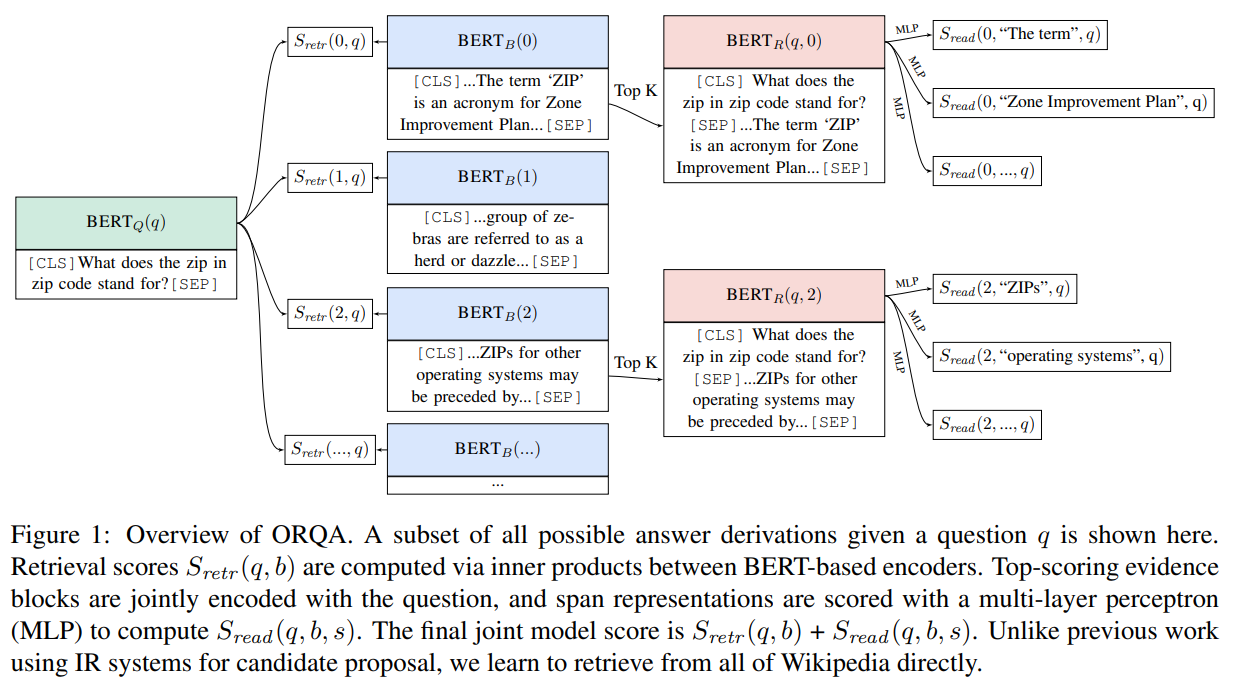
まず、質問文を\(x\)とし、知識コーパス\(\mathcal{Z}\)として、各文書\(z\in\mathcal{Z}\)と表します。
ORQAの1ステップ目は\(\mathcal{Z}\)から関連する文書を抽出することです。
Retriever
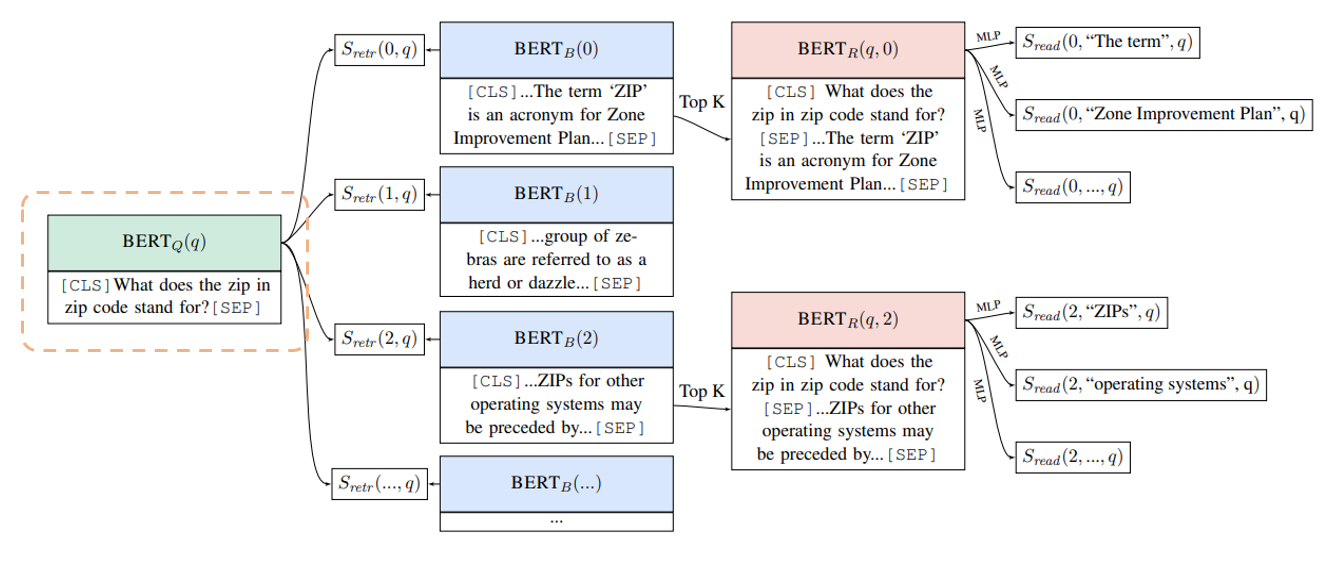
まず、質問文をBERTにより埋め込み表現に変換します。
この際に、文章の先頭につけるダミートークンである[CLS]の部分の隠れ層のベクトルを使います(特に何層目かということに関しては記載がありません)。
また、埋め込み表現に\(W_q\)を掛けてBERTの768次元の埋め込み表現を128次元のベクトルに変換します。
$$h_q=W_q\text{BERT}_Q(q)[\text{CLS}]$$
これは、上図で言うと以下のオレンジの点線部分です。
同様に知識コーパスにある文書についてもBERTで埋め込みます。
ただ、知識コーパス\(\mathcal{Z}\)はWikipediaなどを使いますが、これらの記事は非常に長文で、通常のBERTでは処理できません。
そこで、各文書をエビデンス・ブロックと呼ばれるB個の細かい文章に分割します。
そして、各エビデンス・ブロック\(b\)について、埋め込み表現を計算し、\(W_b\)を掛けます。
$$h_b=W_b\text{BERT}_B(b)[\text{CLS}]$$
そして、質問文とevidence blockの関連性を表すスコア\(S_{retr}(b, q)\)を埋め込み表現同士の内積
$$S_{retr}(b, q)=h_q^Th_b$$
で表します。
図で言うと以下のオレンジの枠線で囲んだ部分です。
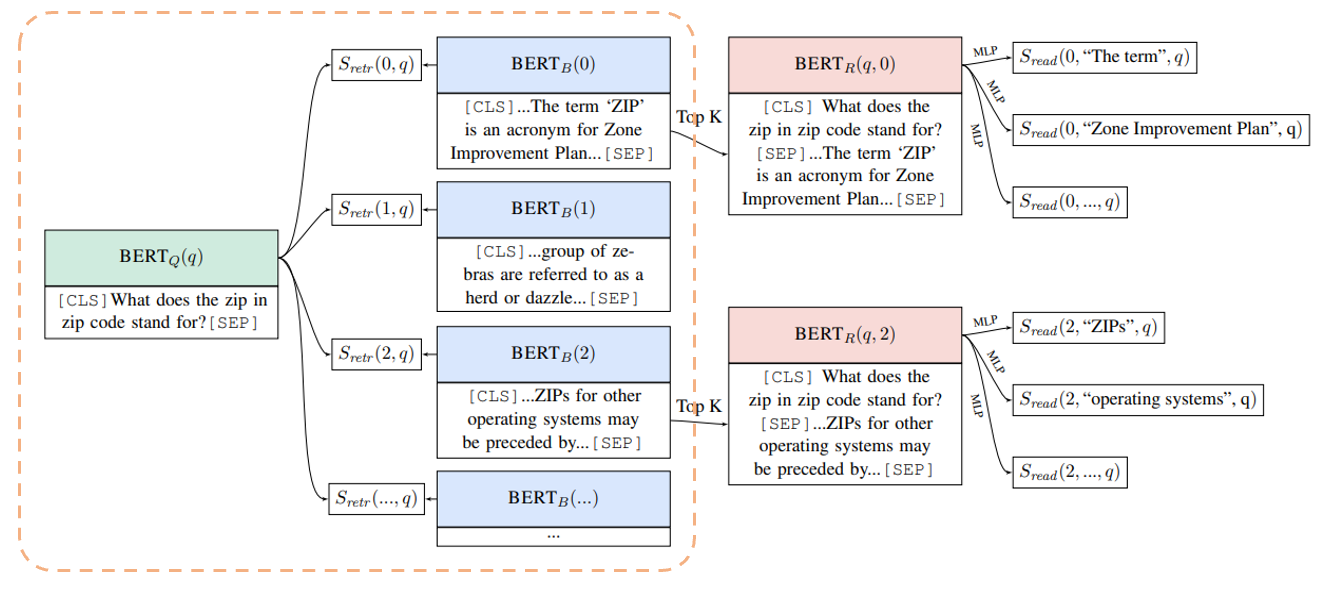
これで、質問文とエビデンスの関連性の大きさを表すことができました。
Reader
続いて抽出したエビデンス・ブロックから、答えとなる範囲を求めるReader部分です。
ReaderもRetrieverと同様にBERTを使います。
BERTへのインプットは質問文とエビデンス・ブロックを[SEP]で並べたものになり、通常のQuestion-Answeringのように答えの範囲を求めます。
Reader用のBERTRによる、開始位置の候補となる位置(START(s))の隠れ層のベクトルと終了位置の候補となる位置(START(s))の隠れ層のベクトルを取り出します。
$$\begin{align}
h_{start}&=\text{BERT}_R(q, b)[\text{START}(s)]\\
h_{end}&=\text{BERT}_R(q, b)[\text{END}(s)]
\end{align}$$
それらを縦に連結して、マルチ・レイヤー・パーセプトロンによりスコアを計算します。
$$S_{read}(b,s,q)=\text{MLP}([h_{start}, h_{end}])$$
以下のオレンジの枠線部分です。
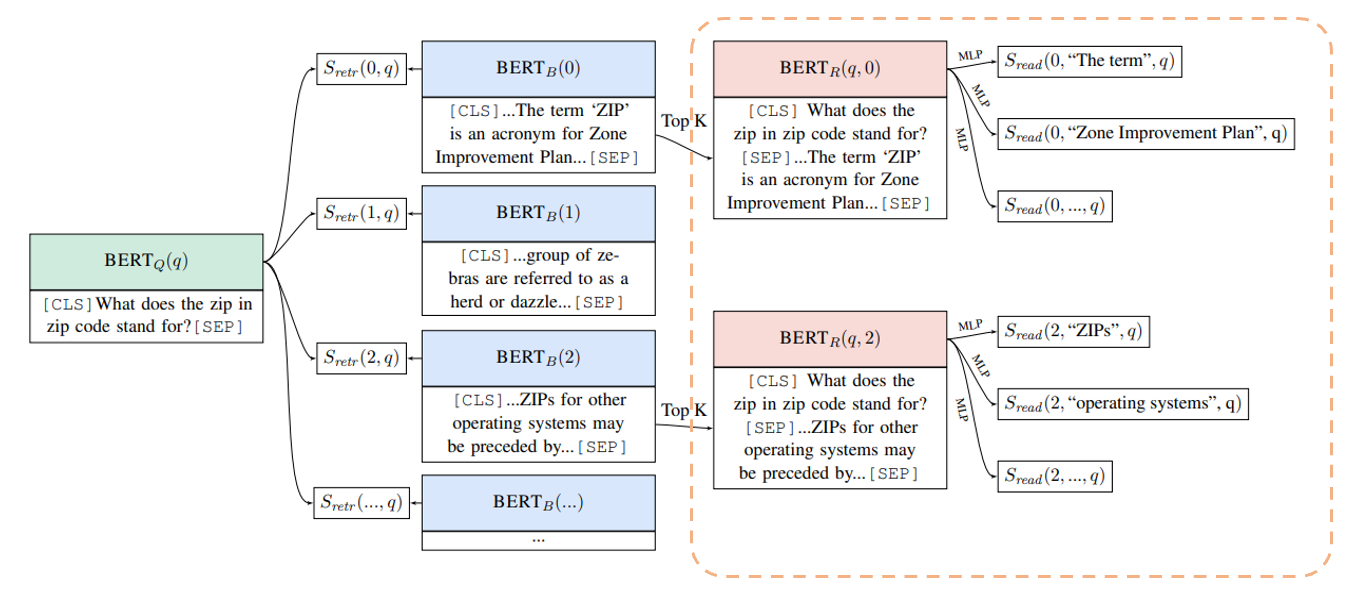
Top Kという部分はあとでも説明しますが、答えを探すための文書を関連性の大きいK個のエビデンス・ブロックに限定するということです。
学習と推論
仕組みは比較的単純でしたね。
しかしながら、実際に学習しようとすると、知識コーパスのブロック数が1300万もあるため、1300万文書の埋め込み表現を求めて、質問文と関連する文書を選ぶ、そして正しくなければパラメータを修正して、また1300万文書の埋め込み表現を求めて、というのは相当計算負荷が高いです。
また、抽出された文書は潜在変数であるため、教師ラベルに合わせて、正しくない文書を選んでいる可能性があります。
例えば以下の表の下段のように、「アラバマ州にはいくつの地区がありますか?」という質問に対して、答えは“7”ですが、関連する文書には「アラバマ州は、食料品にも他の商品と同じ税率をとしている7つの州のうちの1つであり...」という文章を抽出し、その答えを7と正しい予測することもあります。
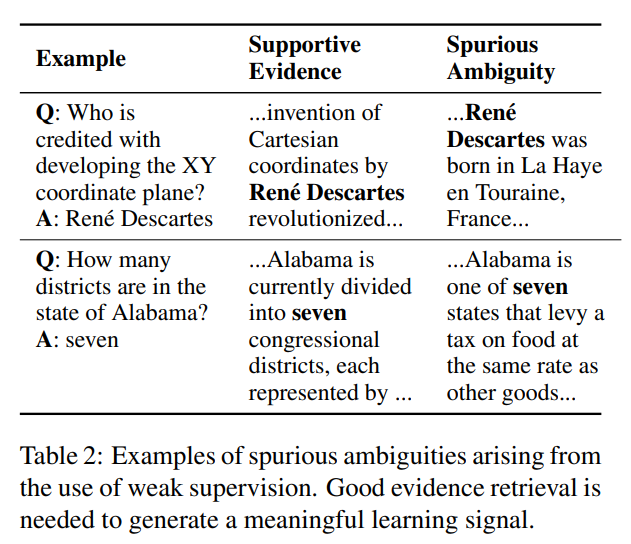
ですので、関連性を適切にとらえることができるようなエビデンス・ブロックを抽出することが非常に重要になり、そのための適切な埋め込み表現を求めることが重要です。
そこで、ORQAでは“Inverse Cloze Task”という教師なしの事前学習で、文書の適切な埋め込み方法を学習します。
そして、ファインチューニング時には、エビデンス・ブロックの埋め込み表現をあらかじめ計算し、それは更新しません。
ただし、質問文の埋め込み表現はファインチューニングされるので、抽出されるエビデンス・ブロックはそれに伴い修正されます。
Inverse Cloze Task(ICT)によるBERTBの事前学習
上述の通り、やりたいことは1300万ブロックの中から質問文の答えが載っている文書を適切に抽出することです。
質問文の答えが載っている文書は、質問文にある固有名詞やイベントや関連性について言及している文書であることが多いです。
そして同時に、質問文にない情報、つまり質問の答えを含んでいなければなりません。
Inverse Cloze Taskでは文章が与えられ、そのコンテキストがどれか予測します。
これではよくわからないので、具体的な例で説明します。
まず、ある文書の中から1つの文章を抜き出します。
その抜き出した文章が質問文に該当し、残った部分がコンテキストに該当します。
以下の例を見てみましょう。
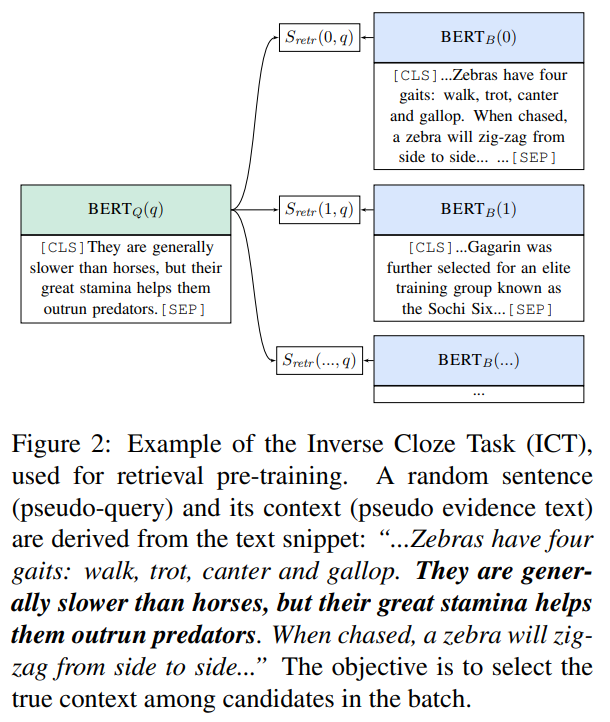
文書は、“…Zebras have four gaits: walk, trot, canter and gallop. They are generally slower than horses, but their great stamina helps
them outrun predators. When chased, a zebra will zigzag from side to side..”です。
そして、太字の部分(“They are generally slower than horses, but their great stamina helps them outrun predators.”)を抜き出して、それをインプットとします。
残った部分(“…Zebras have four gaits: walk, trot, canter and gallop. When chased, a zebra will zigzag from side to side..”がコンテキストになり、これが正例となります。
負例はミニバッチに含まれる正例以外のサンプルになります。
そして、スコアをソフトマックス関数で計算します。
$$P_\text{ICT}(b|q)=\frac{\exp\left(S_{retr}(b, q)\right)}{\sum_{b'\in \text{BATCH}}\exp\left(S_{retr}(b',q)\right)}$$
\(S_{retr}(b,q)\)は前にも出てきましたが、エビデンス・ブロック\(b\)と質問文\(q\)の埋め込み表現を128次元にしたベクトルの内積です。
このようにすることで、質問文にはZebrasという単語が入っていませんが、文脈を考慮してZebrasに関する文書を抽出できるようにします。
これは、従来のような単語のマッチングよりも優れている部分になります。
しかしながら、単語のマッチングも非常に重要であり、それを学習する必要があることから、90%のサンプルについては、コンテキストからその文章を除きますが、残りの10%については、コンテキストにもその文章をそのまま残します。
これにより、文脈によるマッチングだけでなく、単語のマッチングについても学習することを狙います。
関連するエビデンス・ブロックの抽出
上記のICTによる事前学習で、エビデンス・ブロック\(b\)の埋め込み表現を適切に計算できるようになりました。
前述しましたが、ORQAではエビデンス・ブロックのエンコーダー\(\text{BERT}_B(b)\)の学習はこれで終了で、ファインチューニングはしません。
これは1300万文書を使ってファインチューニングするとなると計算負荷が非常に高いからです。
したがって、エビデンス・ブロックの埋め込み表現はあらかじめすべて計算しておき、学習時もそれを変えず、質問文のエンコーダー\(\text{BERT}_Q(q)\)についてのみ、ファインチューニングを行います。
これにより、ICTによる事前学習では捉えられなかった関連性をファインチューニングで対応します。
質問文の埋め込み表現とエビデンス・ブロックの埋め込み表現の類似度が高いもの、つまり内積が大きいものを選びますが、その際にはLocally Sensitive Hashing(LSH)などの手法を用います。
これにより、上位k個のエビデンス・ブロックを抽出し、それらの中から質問文の回答を探します。
ファインチューニング
事前学習後の学習方法をまとめておきます。
まず、すべてのエビデンス・ブロックの埋め込み表現を\(\text{BERT}_B\)を使ってあらかじめ求めておきます。
そこからファインチューニングです。
\(\text{BERT}_Q\)により質問文の埋め込み表現を計算して、関連性の高いエビデンス・ブロックをLSHにより\(k\)個抽出します。
次に、その\(k\)個のエビデンス・ブロックに対して、\(\text{BERT}_R\)を使って、質問文の答えとなる範囲を予測します。
そして、そのスコアからソフトマックス関数を使って確率を計算します。
$$P(b, s|q)=\frac{\exp(S(b,s,q))}{\sum_{b'\in\text{TOP}(k)}\sum_{s'\in b'}\exp(S(b',s',q))}$$
本論文では\(k=5\)としています。
この\(\text{BERT}_Q\)、\(\text{BERT}_R\)のパラメータや\(W_q\)を更新していきます。
損失関数
損失関数は、負の周辺対数尤度として、これを最小化します(周辺対数尤度の最大化)。
$$L_\text{full}(q,a)=-\log\sum_{b\in\text{TOP}(k), s\in b}\sum_{a=\text{TEXT}(s)}P'(b,s|q) $$
となります。
ここで、\(a=\text{TEXT}(s)\)は\(a\)が範囲\(s\)のテキストと一致する場合を意味します。
あともう一つ、答えの予測を完全一致させるという条件を緩めた損失を考えます。
上位\(k\)個よりも多い上位\(c\)個(論文では5000)のエビデンス・ブロックを抽出します。
$$P_\text{early}(b|q)=\frac{\exp\left(S_{retr}(b,q)\right)}{\sum_{b'\in\text{TOP}(c)}\exp\left(S_{retr}(b',q)\right)}$$
そして、そのエビデンス・ブロックの中に、答えとなる単語列が含まれているかどうかを基準とした損失を計算します。
$$L_\text{early}(q,a)=-\log \sum_{b\in\text{TOP}(c),a\in\text{TEXT}(b)}P_\text{early}(b|q)$$
\(a\in\text{TEXT}(b)\)は\(b\)の中に答えである\(a\)という単語列が含まれていることを意味します。
そして、\(L_{full}\)と\(L_{early}\)の合計を損失とします。
$$L(q,a)=L_{early}(q,a)+L_{full}(q,a)$$
以上が、ORQAの仕組みになります。
ポイントの一つは、Inverse Cloze Test(ICT)という事前学習により、ファインチューニングなしで適切なエビデンス・ブロックの埋め込み表現を求めるというところです。
また、エビデンス・ブロックの埋め込み表現はファインチューニングしませんが、質問文はファインチューニングを行うため、質問文の埋め込み表現を変化させることにより、タスクに合った適切なエビデンス・ブロックを抽出することができます。
実験
以下のデータセットを使います。
- Neural Questions
- WebQuestions
- CuratedTrec
- TriviaQA
- SQuAD
それぞれの詳細は以下のようになります。

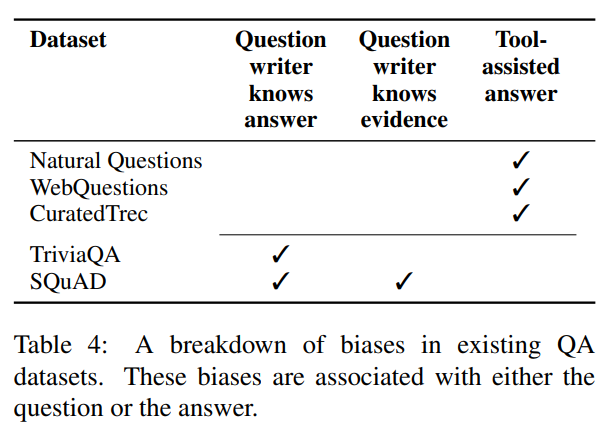
ポイントは、初めの3つのデータセット(Natural Questions、WebQuestions、CuratedTrec)については、質問者が答えを知らないということです。
よりリアルなデータセットになっているということですね。
TriviaQAとSQuADはあらかじめ答えがわかっているものを質疑応答の形にしています。
ですので、TriviaQAとSQuADの質問文には答えの手がかりになる単語が含まれていることが多くなっています。
特にSQuADでは顕著なようです。
結果
では、各データセットの結果です。
左の3つはReaderはBERTですが、RetrieverをBM25(TF-IDFベース)で抽出する(BM25+BERT)、通常のニューラルネットワークの事前学習済みモデルで埋め込み表現を計算する(NNLM)、ELMoの事前学習済みモデルで埋め込み表現を計算するものです。
一番右が今回のORQAです。
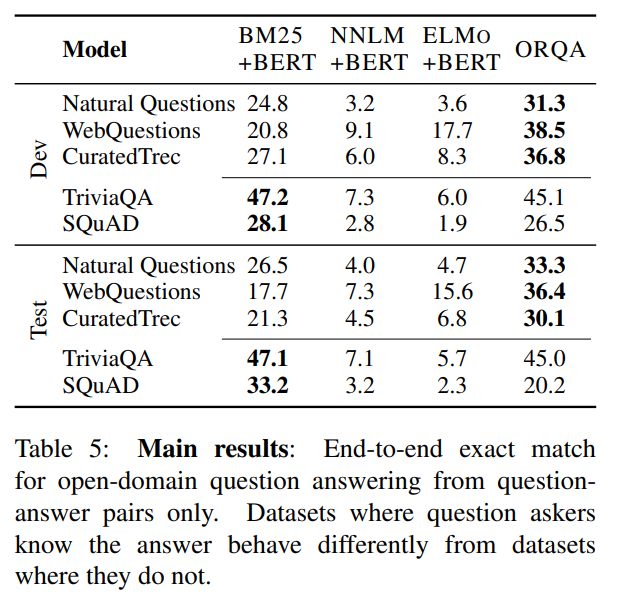
まず、NNLM+BERT、ELMo+BERTに比べて、BM25+BERTの精度は非常に良いことがわかります。
続いて、ORQAに関しては、Natural Questions、WebQuestions、CuratedTrecデータセットでは、BM25+BERTを大きく上回る精度が出ています。
一方でTriviaQAとSQuADに関してはBM25+BERTの方が精度が良くなっています。
これは、データセットの特性で、例えばSQuADではWikipediaの記事に対して、その記事を見ながら質問者が質問を作成していますが、そのときに質問文には記事に存在する単語が含まれていることが多いことが考えられます。
それにより、BM25を使ったRetrieverの方が精度が良いと考えられます。
追加分析
Masking Rate
Inverse Cloze Taskで埋め込み表現の事前学習を行う際に、単語同士のマッチングもうまくできるように、サンプルの10%については、質問文がエビデンスから除かずに残しました。
つまり、サンプルの90%については、エビデンスから質問文を削除しています。
ここでは、何%をエビデンスから削除し、何%を残すと効果的か?について検証しています。
BM25+BERTと比較した結果は以下のようになります。
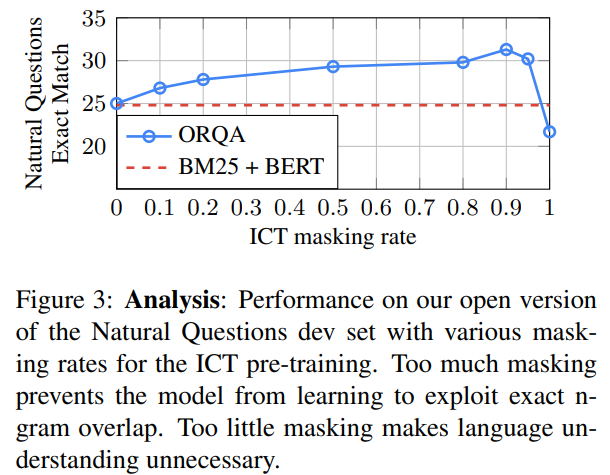
マスクをまったくしない、つまりエビデンスから質問文を削除しない場合だと、BM25+BERTと同水準、その後マスクをしていくことによって、文脈も意識した学習になるため、精度が改善していきます。
しかしながら、すべてのサンプルにおいてマスクしてしまうと、単語のマッチングをうまく学習できないため逆にBM25+BERTよりも悪化してしまいます。
一番良いのは0.9、つまり90%となっています。
予測例
最後に、ORQA、BM25+BERTの予測例を見てみます。
上の3つはBM25+BERTが間違っていてORQAが正しく予測しているケース、一番下はORQAが間違っていて、BM25+BERTが正しく予測しているケースです。

上の3つは、BM25+BERTでは単語のマッチングのみを使っていることから、うまく意味を捉えられておらず、正しいエビデンス・ブロックが抽出できていません。
一方でORQAではうまく抽出できており、例えば最初の例だと「ニュー・オーリンズ」などの単語が含まれていないが、意味的には関連性の高いエビデンス・ブロックが抽出されています。
一番下の例については、エビデンス・ブロックを128次元のベクトルに落とし込んでいることから、表現力が足りていない可能性が指摘されています(この例だけではなかなか判断できませんが)。
まとめ
今回は、ORQAを見てきました。
ORQAは、エビデンス文書の抽出とエビデンスから答えを抽出する部分を分けずに、End-to-Endで学習できるモデルです。
また、最近の自然言語処理の発展している技術を取り入れ、BERTを全面的に採用し、さらにInverse Cloze Taskという事前学習を取り入れることで、従来のモデルよりも高い精度を達成することができました。
では、次回は同じようにEnd-to-EndでOpen Domain Question Answeringのタスクを行うRealmについて見ていきたいと思います。
では!