前回、オープン・ドメインの質疑応答タスクに対して、BERTを全面的に採用し、End-to-Endで学習することができるORQA(Open Retrieval Question Answering)を紹介しました。

今回は、仕組みはORQAに近く、ORQAを上回る精度を達成した『REALM(REtrieval-Augmented Language Model pre-training)』を解説したいと思います。
論文はこちらです。
『REALM: Retrieval-Augmented Language Model Pre-Training』
では、早速見ていきましょう。
目次
REALMとは
REALMはREtrieval-Augmented Language Model pre-trainingの略で、文書を抽出するステップ(Retrieval)を追加し、言語モデルの事前学習を行うモデルです。
以下の図のように、関連する文書を抽出し、その情報も使ってBERTのように[MASK]部分を予測することで言語モデルの事前学習を行います。
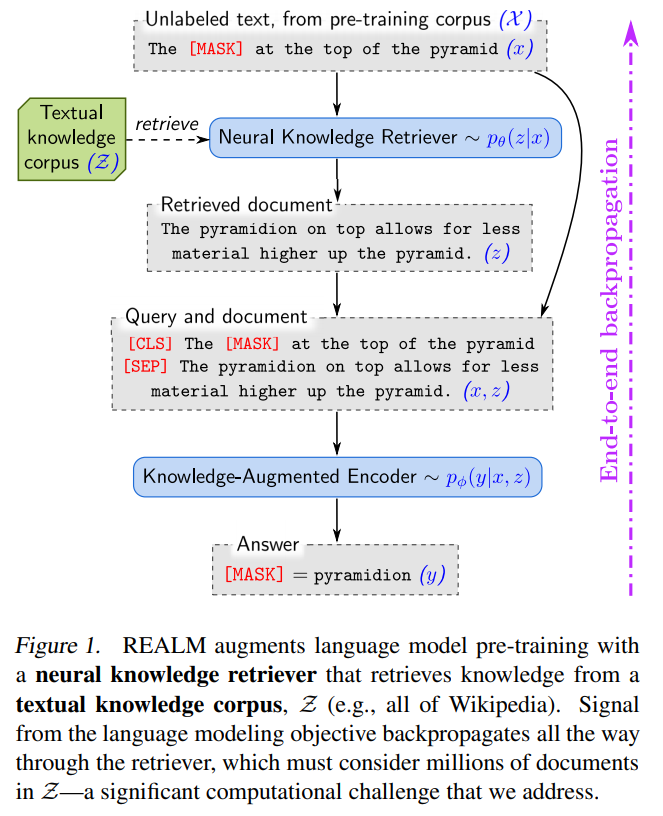
これにより内部のパラメータに知識を詰め込むのではなく、知識コーパスと呼ばれるからデータから適宜必要な情報を取り出すことで、外部情報を活用することが可能になります。
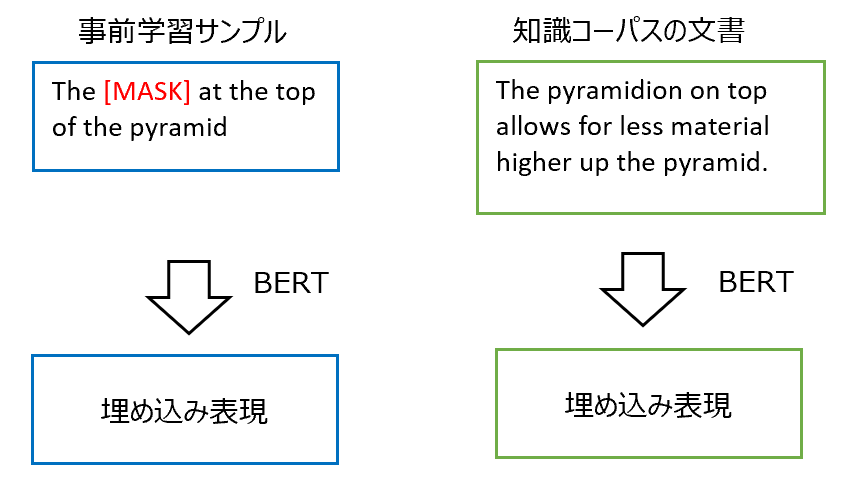
事前学習の概要は以下です。
- [MASK]に置き換えた事前学習サンプルのの埋め込み表現と知識コーパス中の(エビデンス)文書の埋め込み表現を計算する。
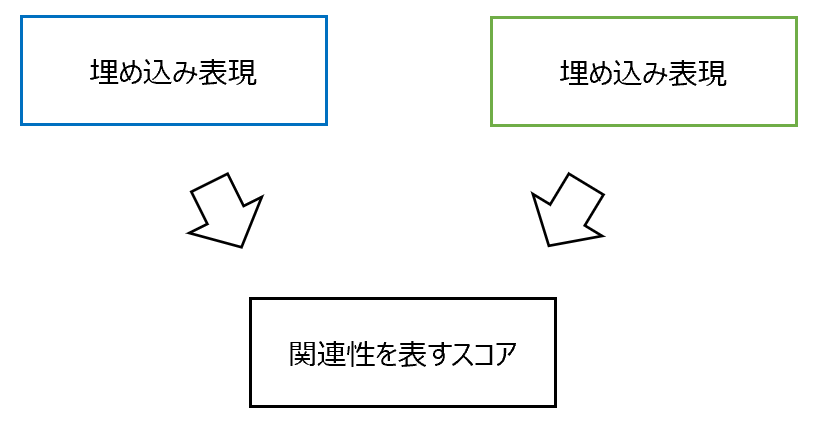
- それらの埋め込み表現の内積をスコアとして、スコアの高い\(k\)個のエビデンス文書を関連文書として抽出する。
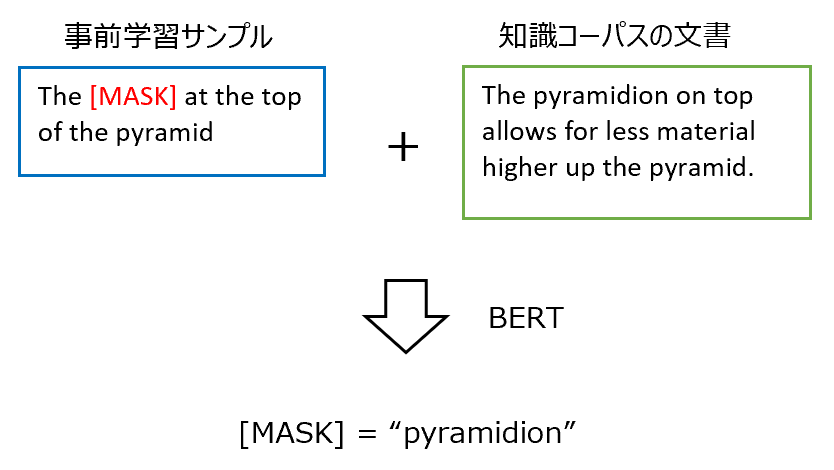
- 事前学習サンプルと抽出された文書を使って、BERTにより[MASK]の部分を予測する。
ORQAとの主な相違点は、
- [MASK]を予測することによる事前学習を行う。ORQAでは、すでに事前学習済みのBERTをそのまま使用していました。
- ORQAエビデンス文書の埋め込み表現は、Inverse Cloze Task(ICT)と呼ばれるタスクで事前学習したモデルで、あらかじめ計算しておき、それ以降は更新していなかった。
REALMでは事前学習時には、非同期で質問文とエビデンス文書の埋め込み表現を更新します。
です。
詳細については、これから解説していきたいと思います。
REALMの仕組み
REALMを使って最終的に行うことは、以下のような仕組みで質問に対する答えを予測することです(Supervised dataは不要ですので無視してください)。
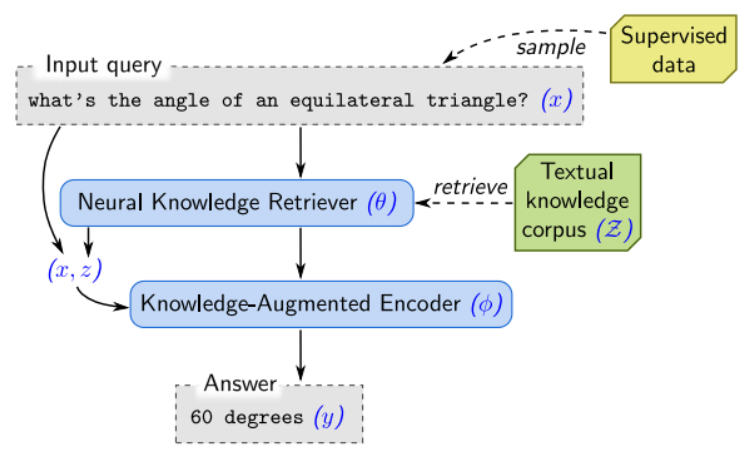
REALMのインプットは質問文\(x\)で、それをもとに答え\(y\)を出力します。
このときに、REALMでは”Retrieve-then-Predict”という仕組みを採用し、知識コーパス\(\mathcal{Z}\)から答えが載っているであろう文書\(z\)をを抽出します。
そのうえで、抽出した文書の情報を使って答え\(y\)を予測します。
ここまではORQAと同じですね。
事前学習
REALMが、ORQAと同様に、知識コーパスから関連文書を抽出し、そこから答えを探し出すということがわかりました。
REALMでは、その目的を達成するために“知識コーパスから緩れ文書を抽出し、その情報も使ったマスク付き言語モデルによる事前学習”を行います。
では、以下の図を使って説明します。
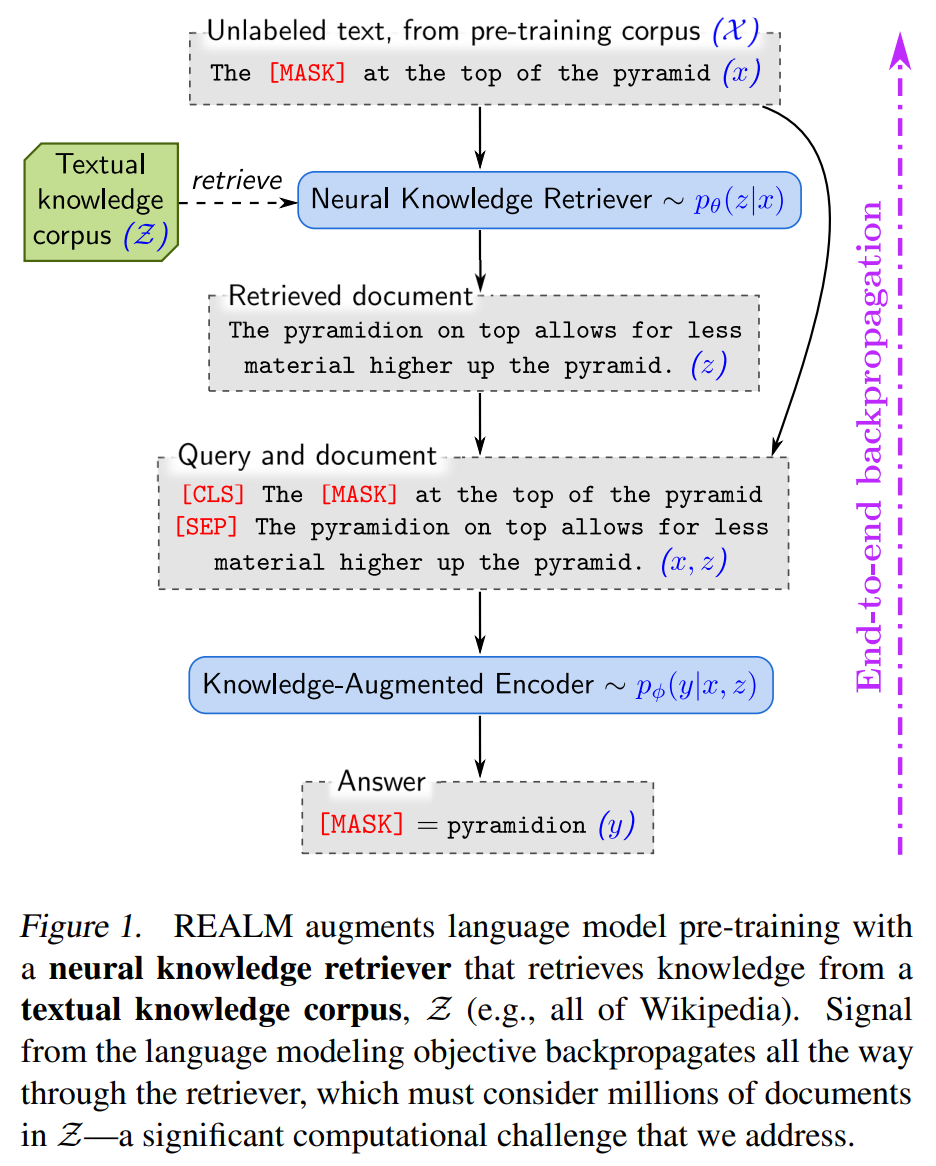
事前学習コーパス\(\mathcal{X}\)に“The pyramidion at the top of the pyramid”とあったとします。
ランダムにマスクして、“The [MASK] at the top of the pyramid”とし、その[MASK]部分を予測します。このマスクされた文章を\(x\)とします。
[MASK]部分を予測する際に、REALMではKnowledge Retrieverがまず知識コーパス\(\mathcal{Z}\)から関連する文書\(z\)を抽出します。
ここでは、“The pyramidion on top allows for less material higher up the pyramid.”という文書を抽出したとしましょう。
そして、[CLS]トークンに続けて\(x\)を並べ、[SEP]で区切って、そのあとに\(z\)を続けたものをインプットとします。
[CLS] The [MASK] at the top of the pyramid [SEP] The pyramidion on top allows for less material higher up the pyramid.
それをBERTベースのKnowledge-Augmented Encoderに入力し、[MASK]部分を予測します。
では、Knowledge RetrieverとKnowledge-Augmented Encoderについて、それぞれ詳細を見ていきます。
Knowledge Retriever
文書集合\(\mathcal{Z}\)から関連文書\(z\)を抽出してくるKnowledge Retriever部分を説明します。
Knowledge Retrieverは、まず、マスクされたインプットの文章と関連文書の埋め込み表現をそれぞれ計算します。
そして、それらの内積を計算し、類似度を表すスコアを計算します。
$$f(x, z)=\text{Embed}_\text{input}(x)^T\text{Embed}_\text{doc}(z)$$
この埋め込み表現はBERTを使って計算し、[CLS]トークンに対応する位置の隠れ層の値を使います。
$$\begin{align}
\text{Embed}_\text{input}(x)=W_\text{input}\text{BERT}_\text{CLS}(\text{join}_\text{BERT}(x))\\
\text{Embed}_\text{doc}(z)=W_\text{doc}\text{BERT}_\text{CLS}(\text{join}_\text{BERT}(z_{title}, z_{body}))
\end{align}$$
ここで、
$$\begin{align}
\text{join}_\text{BERT}(x)&=\text{[CLS]}x\text{[SEP]}\\
\text{join}_\text{BERT}(x_1, x_2)&=\text{[CLS]}x_1\text{[SEP]}x_2\text{[SEP]}
\end{align}$$
です。
式で書くと少しややこしいですが、ようは\(x\)の埋め込み表現\(\text{Embed}_\text{input}(x)\)を求める際は、\(x\)そのものをインプットとして、BERTで埋め込み表現を求めます。
関連文書の埋め込み表現\(\text{Embed}_\text{doc}(z)\)を求める際は、文書のタイトルと本文を[SEP]でつなげ、それをBERTに投入します。
そして、上記で求めたスコアに対してソフトマックス関数で確率に変換します。
$$\begin{align}
p(z|x)&=\frac{\exp f(x, z)}{\sum_{z'}\exp f(x, z')}
\end{align}$$
このKnowledge Retrieverのパラメータを\(\theta\)としています。
Knowledge-Augmented Encoder
関連する文書\(z\)の抽出をしたら、次はKnowledge-Augmented Encoderによる[MASK]部分の予測です。
基本的にはBERTと同じですが、REALMでは以下のように関連文書の情報\(z\)も使って[MASK]部分を予測します。
$$\begin{align}
p(y|z,x)&=\sum^{J_x}_{j=1}p(y_j|z,x)\\
p(y_j|z, x)&\propto \exp\left(w_j^T \text{BERT}_{\text{MASK}(j)}\left(\text{join}_\text{BERT}(x,z_\text{body})\right)\right)
\end{align}$$
\(y_j\)は[MASK]された単語を表し、\(J_x\)は[MASK]数です。
\(w_j\)は\(j\)番目の単語の埋め込み表現になります。
こちらのKnowledge-Augmented Encoderのパラメータを\(\phi\)とします。
ファインチューニング
以上が、Wikipediaなどのラベルなしコーパスを使用した事前学習方法でした。
次に、質疑応答データセットを用いたファインチューニングの方法を説明します。
ファインチューニング時は、質問文に対して、関連文書を抽出し、関連文書から答えとなる単語列を予測します。
単語列を予測するので、関連文書中の単語列の開始位置と終了位置を求める必要があります。
これには開始位置、終了位置に対応するBERTの隠れ層の値を使います。
抽出された文書\(s\)における候補となる開始位置をSTART、終了位置をENDとすると、それぞれの位置の隠れ層のベクトルを取得します。
$$\begin{align}
h_{\text{START}(s)}&=\text{BERT}_{\text{START}(s)}\left(\text{join}_\text{BERT}(x,z_\text{body})\right)\\
h_{\text{END}(s)}&=\text{BERT}_{\text{END}(s)}\left(\text{join}_\text{BERT}(x,z_\text{body})\right)\\
\end{align}$$
そして、マルチ・レイヤー・パーセプトロンを挟んで、ソフトマックス関数で評価します。
$$p(y|z,x)\propto \sum_{s\in S(z,y)}\exp\left(\text{MLP}\left(\left[h_{\text{START}(s)};h_{\text{END}(s)}\right]\right)\right)\\$$
学習
以上で、仕組みの解説は終了です。
続いて、実際に学習をどうするかを見ていきましょう。
同時分布\(p(y,z|x)\)を周辺化して、
$$p(y|x)=\sum_{z\in \mathcal{Z}}p(y|x,z)p(z|x)$$
とします。
\(p(z|x)\)は事前学習であれば事前学習サンプル\(x\)を与えた際の、関連文書\(z\)の確率を表します。
これが高いほど、\(x\)と\(z\)の関連性が高いことになります。
\(p(y|x,z)\)は、事前学習サンプルと関連文書\(z\)が与えられたとき、[MASK]の単語が\(y\)となる確率を表します。
ファインチューニング時では、事前学習サンプルを質問文と読み替え、\(y\)は答えになります。
ここで、本論文で知識コーパスとして使用するWikipediaのデータだと、1つの記事を複数のブロックに分割するため、\(\mathcal{Z}\)には1300万もの文書があります。
ですので、すべての文書で合計をするというのは現実的ではありあせん。
そこで、ORQAでもそうでしたが、関連性の高い上位\(k\)個の文書に限定します。
$$p(y|x)\simeq\sum_{z\in \text{TOP_k}(\mathcal{Z})}p(y|x,z)p(z|x)$$
また、関連性の高さはインプットの埋め込み表現\(\text{Embed}_\text{input}(x)\)と文書の埋め込み表現\(\text{Embed}_\text{input}(x)\)の内積の大きさで表しますが、その際にMaximum Inner Product Search(MIPS; 最大内積探索)というアルゴリズムを使います。
これにより、LSH(Locally Sensitive Hashing)やALSH(Asymmetric LSH)といった手法を用いて、文書数に対して劣線形(線形より少ない)で増加するるため、文書数が多くてもある程度高速に計算することが可能です。
ということで、あらかじめ\(\text{Embed}_\text{doc}(z)\)を計算しておき、MIPSにより関連性の高い上位\(k\)文書を抽出します。
モデルを学習すると、\(\text{Embed}_\text{input}(x)\)や\(\text{Embed}_\text{doc}(z)\)も変化しますが、パラメータの更新のたびにすべての文書の埋め込み表現\(\text{Embed}_\text{doc}(z)\)を更新するのは非常に計算負荷が高くなります。
ですので、ORQAではこの埋め込み表現の事前学習をInverse Cloze Taskという方法により最初にしっかりと行い、それ以降は埋め込み表現を計算するためのBERTパラメータは修正しませんでした。
REALMでは、Knowledge-Augment Retrieverの事前学習中については、数百ステップに1度だけ埋め込み表現を更新するという手法を取ります。
以下の図のように、エビデンス文書の埋め込みと関連文書の抽出を管理するIndex builderと、言語処理モデルの学習を管理するMLM trainerに分けます。
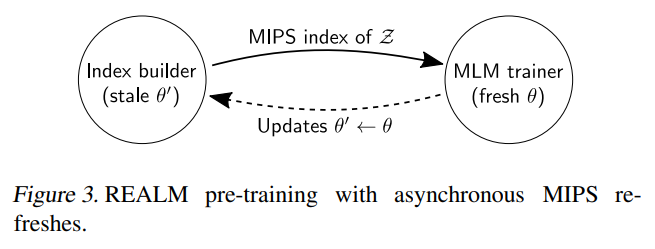
MLM trainerは学習した新しいパラメータ\(\theta'\)をIndex builderに送ります。
Index builderはその受け取った\(\theta'\)をもとに、バックグラウンドで埋め込み表現を再計算し、関連文書を抽出します。
抽出が終わったらそのインデックスをMLM trainerに返します。
この際にMLM trainerはIndex builderの処理が終わるのを待ちません。
終わるのを待たずにどんどん処理を進めていき、Index builderの処理が終わり、新しいインデックスが返ってきたらその時点で文書を更新します。
ただし、これはMLMの事前学習時のみです。
ファインチューニングでは、文書の埋め込み表現はあらかじめ計算したもので固定し、ORQAと同じように質問文の埋め込み表現のみを更新します。
その他の工夫
Salient Span Masking
REALMの事前学習は、Masked Language Modelによる事前学習に、その文章だけでなく、関連する文書をを使うという方法です。
しかしながら、その文章やせいぜいその周辺の文章だけでマスク部分の予測ができることも多いです。
ここでの事前学習の目的は関連文書を適切に使った予測を適切に行えるようにすることです。
そこで、固有名詞と日付の範囲をマスクして、そのマスク部分を予測するようにします。
これをSalient Span Maskingと呼びます。
これにより、適切な関連文書を取ってくることを効率的に学習できるようです。
固有名詞と日付の特定はBERTのCoNLL-2003による学習済みモデルを使います。
Null Document
文章を読めば[MASK]部分の予測が可能で、エビデンス文書が不要というケースが存在します。
そういった場合を適切に捉えるため、Retrieverが抽出する上位\(k\)個の文書に、\(\phi\)を選択できるようにします。
Initialization
Retrieverが関連性の高い文書を抽出する際に、\(\text{Embed}_\text{input}(x)\)と\(\text{Embed}_\text{doc}(z)\)の内積で抽出しますが、学習当初はまったく適切な文書が選ばれない可能性が高いです。
そして、まったく関連しない文書をもとにKnowledge Retrieverが答えを予測し学習しても、Knowledge Retrieverは正しく学習できません。
そこで、Inverse Cloze Taskという事前学習方法で学習した埋め込み表現を使って、それを初期値とすることでこの問題を回避します。
Inverse Cloze Taskは、文書から特定の文章を抜き出し(これをqueryとします)、残った文章をcontextとし、queryに対して対応するcontextを正例、ミニバッチ中のそれ以外のcontextを負例として、学習するものです。
詳しくはこちらのORQAの記事をご参照ください。
実験
では、REALMの仕組み学習方法について確認が終わったので、REALMの精度等について見ていきましょう。
データセット
以下の3つのデータセットを使います。
- NeuralQuestions-Open
- WebQuestions
- CuratedTrec
これらのデータセットは、SQuADなどと違い、質問を作成した人が答えを知らないという特徴があります。
知識コーパスには、Wikipediaを利用します。
事前学習用のデータセットは、以下の2パターンを試しています。
- Wikipedia
- CC-News
結果
それでは結果を見ていきましょう。
ここでは、BERTやREALMのような関連する文書を抽出して答えを予測する抽出型のモデルであるDrQAやORQAと比較します。
また、パラメータに知識を記憶させ、文章を生成するように答えを予測する生成型の巨大モデルT5とも比較をしています。
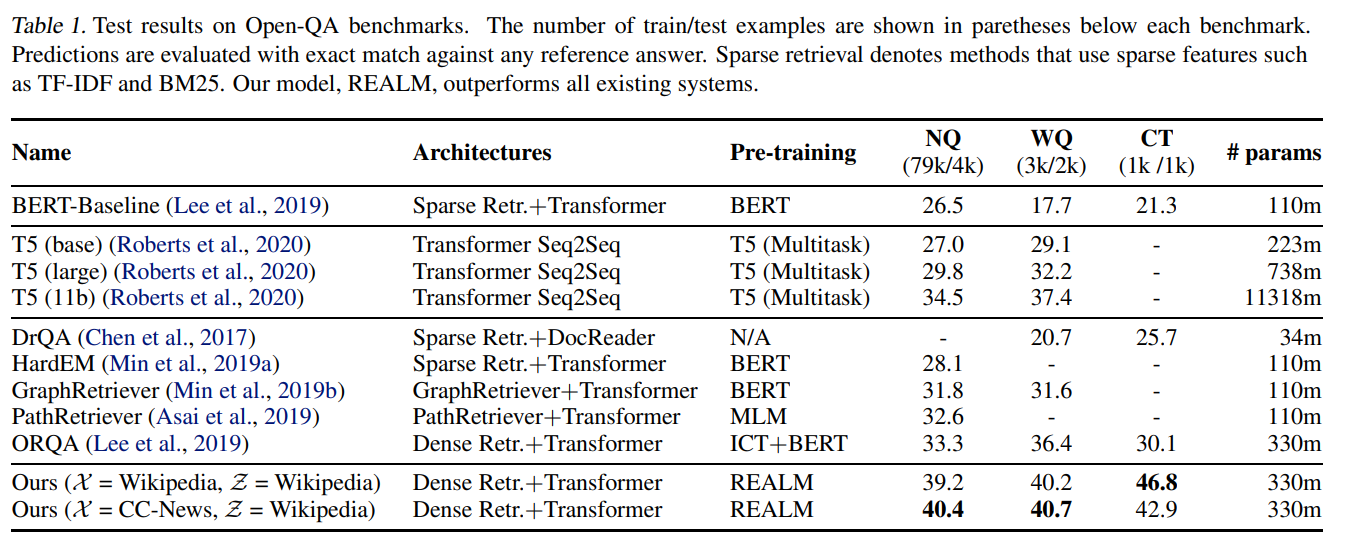
どのデータセットでも一番精度がよくなっており、2番目に精度が良いT5と比べて大きく改善しています。
関連文書を抽出しないT5の精度がORQAを上回っていますが、T5のパラメータ数はORQAやREALMの30倍も多くなっています。
次に、知識コーパスを使った場合の事前学習結果と知識コーパスを使わない場合のBERTの事前学習結果を見てみましょう。
以下の表は、インプットが“An equilateral triangle is easily constructed using a straightedge and compass, because 3 is a [MASK] prime.”(3は[MASK]数なので、正三角形は定規とコンパスを使って簡単に作成できる)の場合です。

答えは“フェルマー”ですが、難しいですね。BERTではこれはうまく答えられず“Felmat”の予測確率は1.1×10-14とほぼゼロです(a)。
一方で、REALMのRetrieverが適切な文書を取ってきた場合は、“Felmat”の確率は1.0です(a)。
また、上位8文書を使った周辺確率は0.129となっています(c)。
こういった特殊な知識を必要とするタスクではREALMの仕組みが役立つということを表していると思います。
まとめ
今回は前回のORQAに続いてOpen-DomainのQuestion Answeringに関する論文を紹介しました。
Masked Language Modelによる事前学習を拡張して、外部知識を使ったMasked Language Modelとし、また非同期で関連文書の埋め込み表現やインデックスを更新することにより精度の改善が行われています。
他にも論文には追加の分析がありますので、興味のある方は論文をご確認いただければと思います。
他ににも“What does the retriever learn?”の節も、実は裏ではゴリゴリ式展開がされていて面白いです(appendixに詳しく式展開が載っていましたが、式を追っただけで何となく満足してしまったので、解説は省略しています)。
では!