今回は、固有表現抽出などの系列ラベリングを行う上で、重要なアルゴリズムである“ビタビアルゴリズム(Viterbi Algorithm)”を解説したいと思います。
まず、各単語について固有表現かどうかをどのように予測するか、については今回は説明しません。
次回、それについては説明しますので、次の記事まで読んでいただくことで、固有表現抽出の手法について一通り理解できると思います。
BIOモデルによる表記方法など、固有表現抽出の基礎については、すぐに読めると思いますので以下の記事をご参照ください。

今回は主に以下の本を参考にしています。非常に分かりやすいのでビタビアルゴリズムはもちろん、固有表現抽出や情報抽出を基礎から理解したい方にオススメです。
なぜビタビアルゴリズムが必要なのか?
BERTなど自然言語処理のモデルが発展してきているので、何となく固有表現抽出というと、どの単語が固有表現に当たるかという正解ラベルを作成して、BERTを使って予測させればいいんじゃない?と思う方もいるかもしれません。
確かにそれでも可能です。
しかしながら、こちらの記事『【入門者向け】固有表現抽出の概要を理解する』にも書きましたが、固有表現のラベルには規則があります。
例えば、BIO表現の一例ですが、このようになります。
簡単にするために人物だけを特定します。
| 〇〇 | △△ | 社長 | が | 退任 | した | 。 |
| B-PER | I-PER | O | O | O | O | O |
人物の開始位置にはB-PERを、人物の続きにはI-PER、固有表現以外にはOをラベリングします。
そして、これをもとに学習したとします。
しかしながら、予測結果には、例えば、一番初めの単語にI-PERなどが来てしまったり、もしくは、B-PERの後にまたI-ORGが来たりしてしまう可能性があります。
特に、人物だけではなく、組織名や地名なども特定するのであれば、そういった間違いが増えてきます。
そこで、一番初めに"B-"は来ないなど、あらかじめ規則を定めておき、その規則を満たしているラベルの列を求め、さらにその中で最適なラベル列を求めるためにビタビアルゴリズムが使われます。
ビタビアルゴリズムにより、明らかにおかしな順番のラベル列を排除することにより、精度を上げることができます。
ビタビアルゴリズムは、系列としてのラベルの満たすべき規則を考慮し、その中で系列として最適なラベル列を求めるために使われる。
ビタビアルゴリズムは固有表現抽出だけでなく、日本語の形態素解析や英語の品詞のタグ付けなど、系列の解析に広く利用されている方法です。
品詞タグ付けにおけるビタビアルゴリズムはこちらの記事をご参照ください。本質的にはこちらの記事と同じです。

ビタビアルゴリズムの仕組み
アルゴリズム自体は非常にシンプルなのですが、何をやっているかを自分で細かく理解しようとすると、なかなかややこしいものです。
しかしながら、本質的な部分を理解しておけば、何をやっているかがわかりやすいと思いますので、まずざっくりと何をやろうとしているかを説明します。
まず、LSTMやBERTなどのモデルを使って、文章の各単語に対して予測したラベルの確率(スコア)があるとします。
先ほどの文章であれば、以下のような感じです。
| 〇〇 | △△ | 社長 | が | 退任 | した | 。 | |
| B-PER | 0.3 | 0.5 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| I-PER | 0.4 | 0.3 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| O | 0.3 | 0.2 | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 |
B-PERの行は、モデルが出力したB-PERとなる確率、I-PERの行はモデルが出力したB-PERとなる確率という感じです。
一番確率が高いラベルを選ぶと、“〇〇”がI-PERと予測され、I-PERから始まってしまうことになります。
これは許容できないので、以下のようなルールを作成します。
| P/L | B-PER | I-PER | O | EOS |
| BOS | 1 | 0 | 1 | 1 |
| O | 1 | 0 | 1 | 1 |
| B-PER | 1 | 1 | 1 | 1 |
| I-PER | 1 | 1 | 1 | 1 |
Pは前の単語でLが現在の単語を表し、前の単語Pと現在の単語Lの組み合わせで、連接可能(許容できる組み合わせ)であれば1、そうでなければ0としています。
BOSは文章の初めを表し、EOSは文章の最後を表します。
本来であれば、B-PERのあとにI-LOCはダメとか、そういったもう少し大きな表になります。
これを使って、連接可能性を考慮しながら、つまり、あり得るラベル列の中で、系列として最適なラベリングを決定していきます。
アルゴリズム詳細
では、ビタビアルゴリズムを説明していきたいと思いますが、まず変数を定義したいと思います。
- \(\widehat{path\_score}_{j, y_j}\)
\(j\)番目の単語のBIOラベルを\(y_j\)とした場合の、それまでの経路全体の最大スコア。 - \(\widehat{path}_{j, y_j}\)
\(j\)番目の単語のBIOラベルを\(y_j\)とした場合の、それまでの経路全体のスコアが最大となる一つ前のラベル。
つまり、\(\widehat{path\_score}_{j, y_j}\)を取る場合の一つ前のラベル。 - \(score_{j, y_j}\)
\(j\)番目の単語のBIOラベルが\(y_j\)となる場合のスコア - \(C(y_{j-1}\rightarrow y_{j})\)
\(j\)番目のBIOラベルと一つ前の\(j-1\)番目のBIOラベルの連接可能性。連接可能であれば1、連接可能でなければ0を取る。
例えば\(\widehat{path\_score}_{j, y_j}\)と\(\widehat{path}_{j, y_j}\)は\(j=3\)の場合は以下の図のようになります。
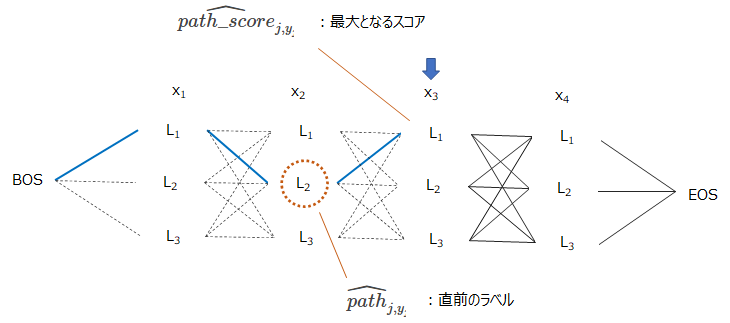
\(x_3\)のBIOラベルを\(L_1\)とした場合に、その最適な経路が青い線で、そのときの経路全体のスコアが\(\widehat{path\_score}_{3, y_3}=\widehat{path\_score}_{3, L_1}\)、その場合の一つ前のラベルが\(\widehat{path}_{j, y_j}=\widehat{path}_{3, L_1}=L_2\)となります。
では、アルゴリズムについて見ていきます。
for \(j = 1\) to \(J+1\)
for all \(y_j\),
\(\widehat{path\_score}_{j, y_j}=\max_{y_{j-1}} \left[\widehat{path\_score}_{j-1, y_{j-1}} +score_{j, y_j} \times C(y_{j-1}\rightarrow y_{j})\right]\)
\(\widehat{path}_{j, y_j}=\arg \max_{y_{j-1}} \left[\widehat{path\_score}_{j-1, y_{j-1}} +score_{j, y_j} \times C(y_{j-1}\rightarrow y_{j})\right]\)
end for
end for
ここで、\(C(y_{j-1}\rightarrow y_{j})\)は\(j\)番目のラベルと一つ前の\(j-1\)番目のラベルの連接可能性を表し、連接可能であれば1、連接可能でなければ0になります。
ですので、B-PERの後ろにまたI-ORGなどが来ている場合はスコアが0になり、選択されません。
このアルゴリズムで何をやっているかというと、まず\(j-1\)番目の各ラベルについて、それまでの最適な経路がわかっているとします。
そして、\(j\)番目において、各BIOラベルを取る場合それぞれについて、経路のスコアを計算し、スコアが最大となる経路を求めます。
例えば、\(j\)番目を\(L_1\)とした場合のスコアは、その前のラベルが①\(L_1\)、②\(L_2\)、③\(L_3\)のどの場合が最大になるか?、そしてその最大となるスコアを求めます。
それと同時に、スコアが最大となる場合の一つ前のラベル①-③のどれかを保存します。
これを\(j\)番目が\(L_1\)の場合だけでなく、\(L_2\)、\(L_3\)の場合も同様にします。
そして、次のステップに進んでいきます。
これで、最後のEOSまで行くのが前半の前向きのパートになります。
これによりEOSに行った時点で、EOSの前の最適なラベルが求まっています。
次に後半のアルゴリズムです。
\(\widehat{y}_J = \arg\max_{y} \widehat{path\_score}_{J+1, EOS}\)
for \(j=J\) to 1
\(\widehat{y}_j = \widehat{path}_{j, \widehat{y_j}}\)
end for
EOSの前の時点(\(J\))での最適なラベルが求まりました。
次は、その場合の\(J-1\)番目の最適なラベルも\(\widehat{path}_{J, \widehat{y_J}}\)に保存されていますので、それが\(J-1\)番目のラベルになります。
さらに同様に\(J-2\)番目も求まり、これを\(j=1\)まで順番に繰り返すと、連接可能性を考慮した最適なBIOラベルの系列が求まります。
まとめ
今回は、固有表現抽出におけるビタビアルゴリズムの適用方法を紹介しました。
あとは、各ラベルのスコアをLSTMやBERTなどを使って求めれば、ビタビアルゴリズムにより最適なラベル列を求めることが可能です。
今度実際に固有表現抽出を実装してみたいと思います。
参考文献
より詳しく知りたい方向けに、今回参考にした2つの書籍を挙げておきます。
1つめに関してはビタビアルゴリズムや固有表現抽出についてより詳しく説明されており、しっかりと理解できると思います。
2つめは、ビタビアルゴリズムについて例を使った説明しています。固有表現抽出以外にも形態素解析や自然言語処理の歴史などの話もありますので、自然言語処理の初学者が全体感をつかむのに最適だと思います。