2021年1月5日にOpenAIのサイトに「DALL·E: Creating Images from Text」という記事が公開されました。
OpenAIは最近、自然言語処理技術を使って非常に自然なニュースを生成することができるGPT-3や、画像を生成するImage GPTと非常に興味深い成果を残しています。
今回は、そのDALL-Eの記事について、解説したいと思います。
実際に見てみると、人間の想像力を超えているのではないかというクオリティの画像がたくさん出ています。
例えば、こちらの「バレリーナの衣装を着て、犬の散歩をする赤ちゃん大根」を入力した場合に、DALL・Eが作り出す画像です。

こちらは、「アボカドの形をしたアームチェア」を入力した場合の作り出された画像です。
すごいですね、これらは画像として存在する既存の椅子ではなく、DALL・Eが作り出した椅子です。

他にも自分で色々選べ、例えばこちらは椅子ではなく、「アボカドの形をしたランプ」とした場合です。
アボカド好きであれば喜びそうですね(笑)
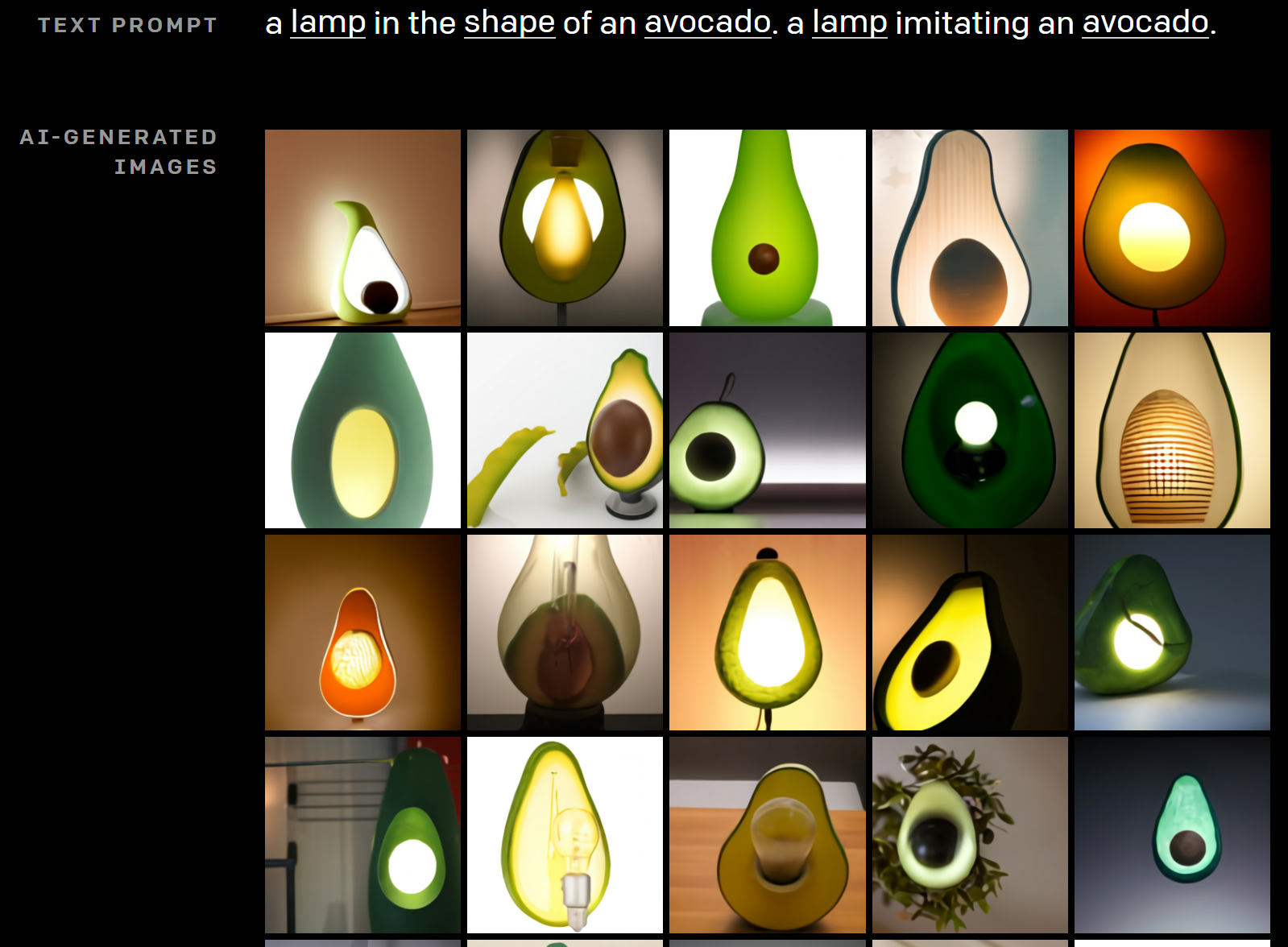
ピカチュウ・スタイルのランプとするとこのようになります。
何か違うやつもちょいちょいいます(笑)

詳細は今後発表するとのことなので、まだモデルの詳細などはわかりませんが、わかる範囲でそのブログの解説をしたいと思います。
最後の方には、関連技術や私の想像でどんなモデルかをわかる範囲で考えていますので、ご参考にどうぞ。
(既に論文の形で公表されていて、以下の記事で解説しています。技術的なところはこちらをご参照ください)

また、2022年に「DALL-E」からさらに進化した「DALL-E2」のベータ版が公開されており、そちらを使った画像生成結果を以下の記事で紹介しています。
ご興味のある方は、どんなことができるかやそのクオリティを確認していただければと思います。

「DALL-E(ダリ)」とは
名前の由来
まず、DALL-Eの由来はスペインの画家サルバドール・ダリ(Salvador Dalí )と映画『WALL・E(ウォーリー)』を組み合わせた名前だそうです。

何ができる?
DALL-Eでは何ができるのでしょうか?
全体としては、文章、もしくは文章と画像の一部を受け取って、そこから画像を生成するようです。
以下で、具体的に何ができて、何がまだうまくできないかを見てみましょう。
物体の属性情報を指定する
属性情報を指定することができます。
たとえば、こちらは“5角形の緑色の時計”です。6角形のものも見られますが、概ね正しく描かれています。

複数の物体を描く
1つだけではなく、複数の物体について、関連性を持たせた絵を描くことが可能です。
例えば以下は、“大きな緑の箱の上の小さな赤の箱”です。
概ね合っており、大きさと色、上と下の関係が正しく捉えられています。ただ、ところどころ黄色の箱だったり、緑の箱がなかったりします。

ただし、あまり複雑になるとうまくいかないようです。
以下は、”3つの積み木が重なっている。赤い四角が一番上で、緑の四角の上にある。緑の四角は真ん中で青の四角の上にある。青の四角は一番下。”という文章に対して描かれた絵です。
おしいのもありますが、数や順番などがうまくいっていないものが多く見られます。

同様に、“青い帽子をかぶり、赤い手袋をして、緑のシャツを着、黄色のズボンをはいている赤ちゃんペンギンの絵文字”です。
こちらもおしいですが、赤いリボンをしていたり、少し違うものがほとんどです。
このように、指定された属性数が多いとDALL-Eは混乱してしまうとのことです。

視点を調整する
どこから見た物体かを指定することができます。
例えば、これは“山にいるカピバラの超アップ”(訳が下手ですみません)です。
自分で遊んでもらうといいと思いますが、“下からのアングル”などを指定すると、指定した画像がうまく生成されています。

様々なスタイルで描く
単なる写真や絵だけではなく、“3D”風、“X線写真”風、“粘土人形”風などを選ぶことができます。
こちらは、“森に住むカピバラのX線写真”です。
見事ですね。これは簡単に作れませんね。

アングルを設定する
これもまたすごいです。
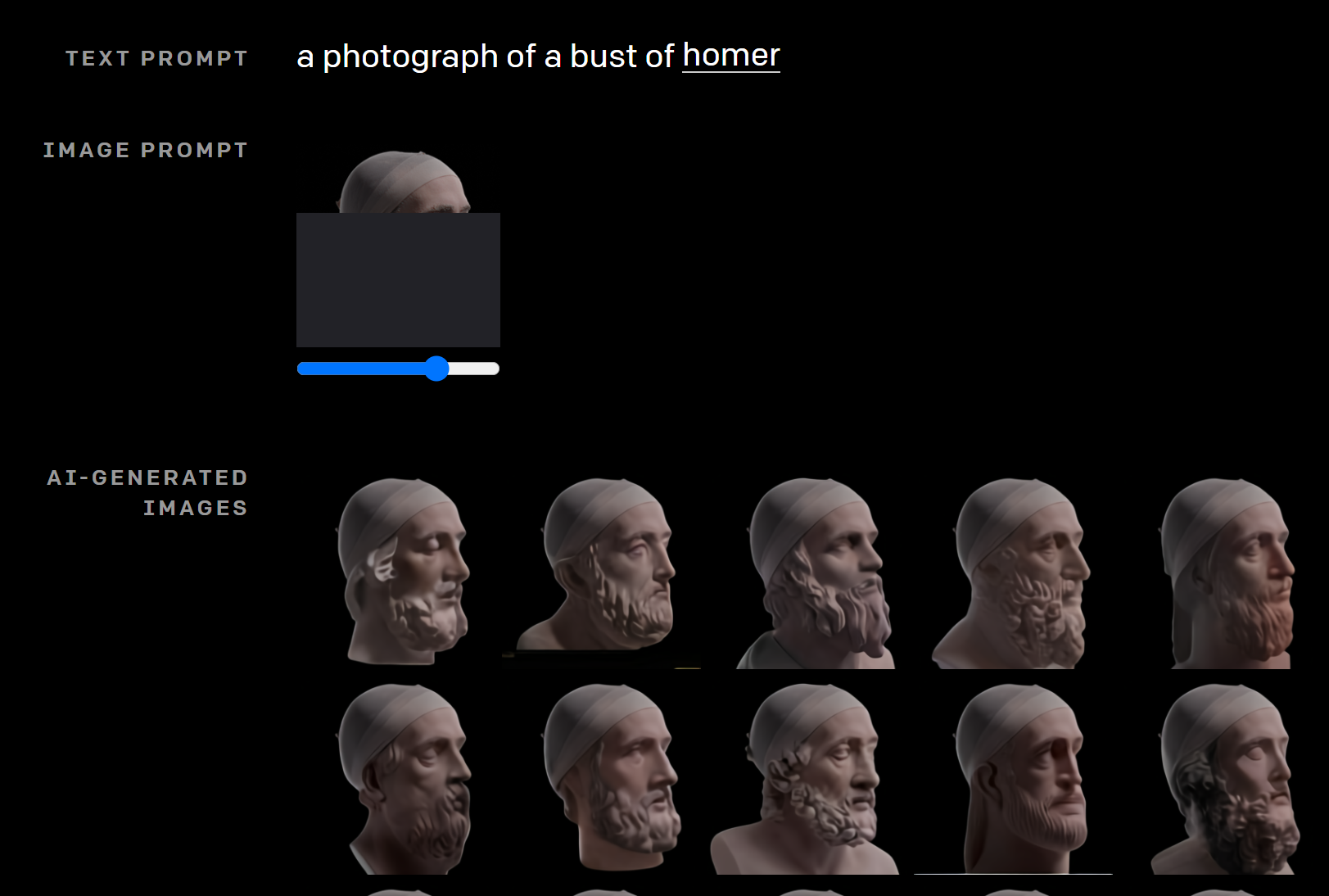
以下は”ホメーロスの銅像の写真”です。
テキスト情報だけでなく、Image promptに画像の一部もインプットします。これはホメーロスの前からみた画像の一部です。

次に少し横を向かせた写真をImage promptに指定します(少しずつアングルを変えられます)。
その角度のホメーロスの画像が生成されます。
断面を描画する
X線写真などを描画することができましたが、物体の断面も描画できます。
こちらは、“火山の断面”です。

接写画像を描画する
Extreme close-upをさらに拡大することが可能です。
こちらは、“エスプレッソの接写写真”です。

詳細を推測して描画する
一言に物体と言っても色々な表現の仕方があります。
可愛い猫といってもたくさんの種類があり、どういう状況かなど様々存在します。
DALL-Eでは、そういったものも推測して生成することが可能です。
こちらは、“青いパイナップルの画像を使ったiPhoneのアイコン”です。もちろんこれは世の中に存在するアイコンではありません。

続いて“openaiと書かれた店頭”です。もちろんこんな店はありません。色々なタイプの店があります。
従来のように細かく指定することなく、非常に漠然とした文章をインプットすることで、その行間を読んで生成することが可能です。

ファッション、インテリアを描画する
こちらは“青のネルシャツに黒のジーンズをはいた男性のマネキン”です。
イメージ通りですね。

続いてインテリアです。
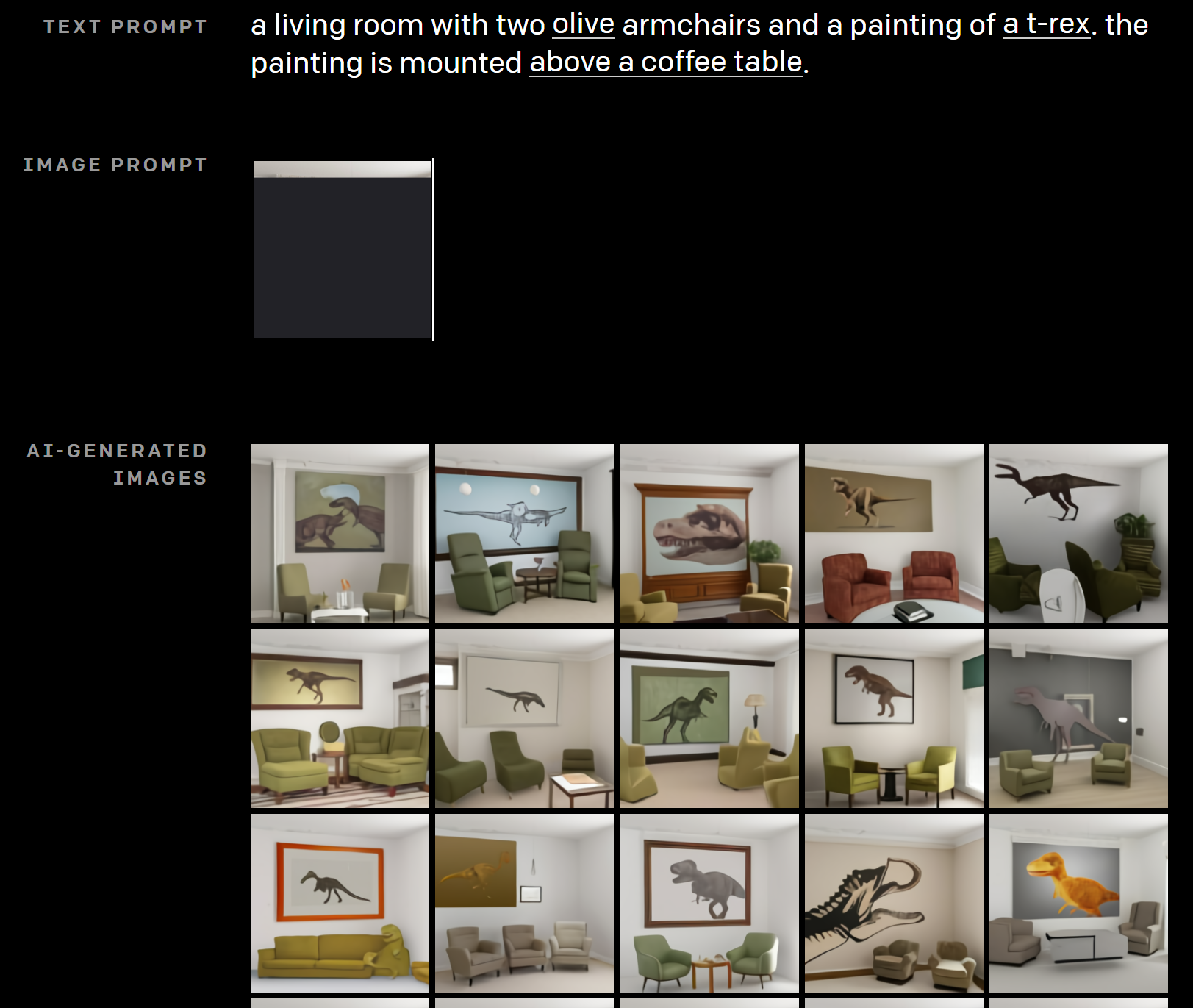
こちらは“2つのオリーブ色のチェアとティラノサウルスの絵があるリビング。絵はコーヒーテーブルの上にある。”です。
チェアの個数や色、ティラノサウルスの絵、コーヒーテーブルの上とどれもほぼ正確に描かれています。
2つの物体を融合する
2つの全く違う物体を融合させて一つの想像上の物体を生成することができます。
これはかなり創造性に富んだ画像が生成されます。
例えば、“ハープから作られたカタツムリ”です。

他にも設定を変えて、“バナナから作られたクジャク”です。

こちらは“アボカドの形をしたチェア”です。

動物や野菜のイラストを描画する
架空の物体を作りだすことができましたが、それを使ってイラストを描くことができます。
こちらは、“サングラスをしてギターを弾く赤ちゃん大根”です。葉っぱの部分がモヒカンになっています。

絵文字を生成することも可能です。
こちらは”アルパカ・ライオンの絵文字”です。アルパカとライオンが混ざったユニークな絵文字ができています。

Zero-shot visual reasoning
GPTの一連の研究やCLIPなどはzero-shotの設定で分析が行われてきました。
zero-shotとは、タスクとなる特定のデータセットで学習せずに、一般的な学習をしただけで、そのタスクを解くことです。
そして、GPT-3では、その能力が非常に高いことが証明されました。
例えば、“here is the sentence ‘a person walking his dog in the park’ translated into French:”とインプットすると、GPT
-3はフランス語で“un homme qui promène son chien dans le parc.”と返します。
文章の続きを返すように翻訳されます。
ここでGPT-3は翻訳用のデータセット(英語とフランス語のペア)を使って翻訳を学習したわけではありません。
あくまでWebから集められた巨大なラベルのない文章データを使って、言語を学習しただけです。
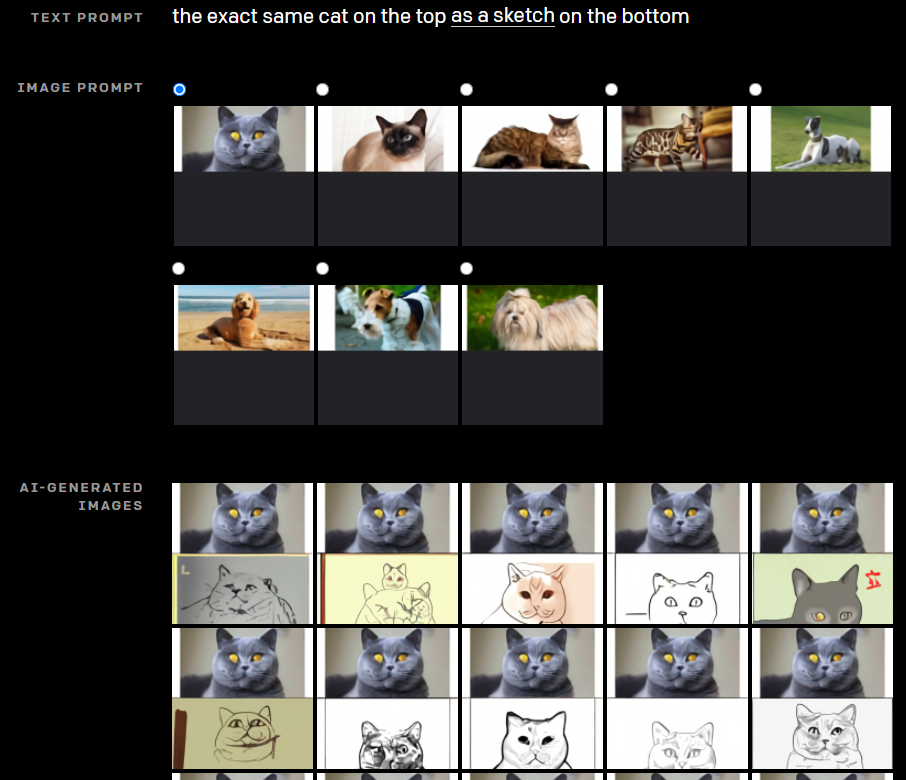
DALL-Eでも同じような形で、画像の翻訳を試みています。
Text promptに“上段の猫と同じスケッチを下段に描く”というようなもので、Image promptには猫の画像を与えます。
すると、その通り、上段には猫の画像、下段にはそのスケッチ風の画像が生成されます。スケッチの手法もそれぞれですね。
他にも、“同じティーポットで、上段には写真を下段には笑顔を書いたティーポット”とすると、下段にはちゃんと笑った顔が描かれた同じティーポットが生成されています(ときどき違うものもできていますが)。
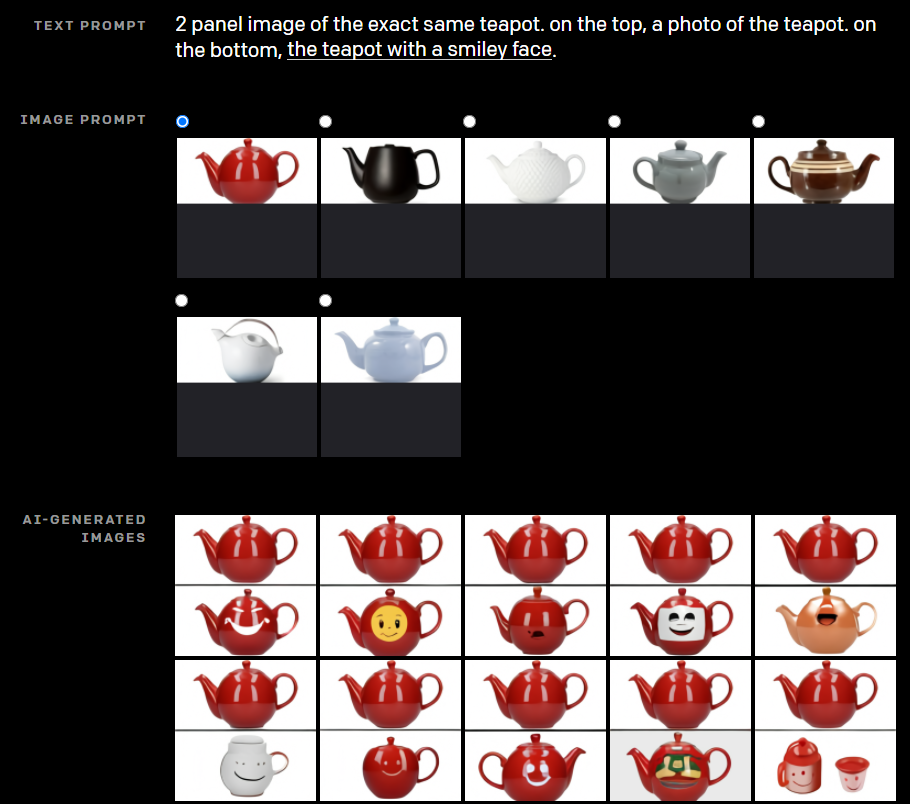
OpenAIの著者らも「こんなことができるようになるとは思わなかった」そうです。
地理的な知識を利用する
日本、中国、アメリカといった国に関する画像を生成することができます。
例えば“日本の食べ物の写真”です。

“ブータンの町の通りの写真”です。かなりそれっぽいですが、これは実在するのでしょうか。

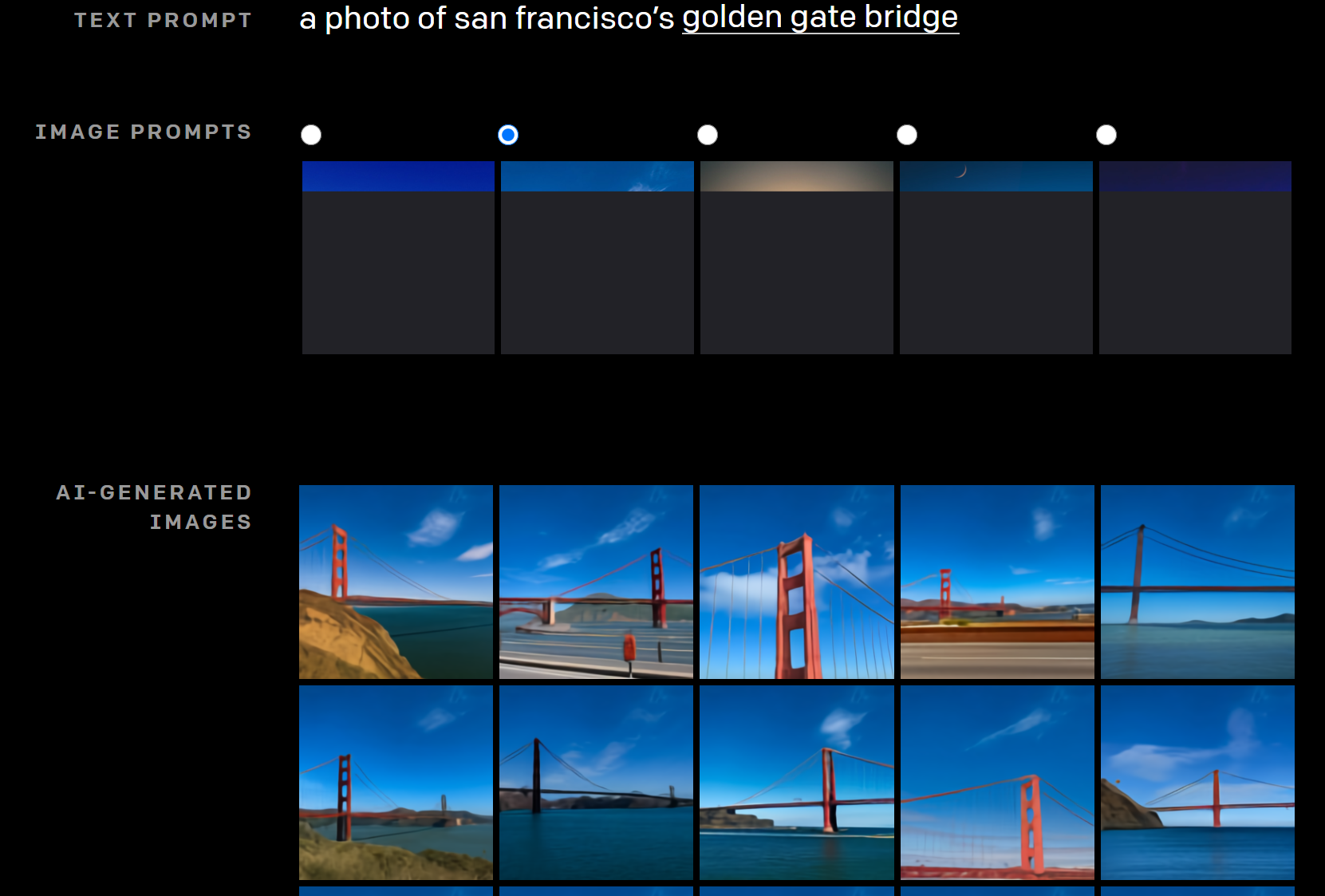
“ゴールデンゲート・ブリッジの写真”ですが、Image promptに画像の一部を設定することができます。
それにより、その画像に従って、昼の写真や夕方の写真を生成することができます。
決められたルールに基づいて色を設定しているのではなく、あくまで文章と画像の一部を使って画像を生成しているところが驚きです。
時代の知識を利用する
いつの時代ではどうだったか、という情報を考慮した画像を生成することができるようです。
こちらは、“1900年代から将来までの電話”です。
text promptに“a photo of a phone from the ...”と入力すれば良いのでしょうか。
このあたりの詳細はまだわかりません。
ついでに画像の一部をimage promptで設定することにより、雰囲気を変えた画像が生成されます。

遠い将来の電話は先祖返りしていますね。
人間でもそうですが、AIでもデータにないような将来予測は難しいと考えられます。
と色々なパターンを見てきましたが、驚くような結果がたくさんあります。
DALL-Eの仕組み(わかる範囲で)
関連技術
では、詳細はまだわかりませんが、わかる範囲で使われていそうな技術について説明したいと思います。
まず、DALL-Eは今までの研究成果を組み合わせたものと言えそうです。
記事に出てくる関係しそうなモデルはこちらです。
GPT-3
OpenAIが開発した巨大な自然言語処理モデルです。
大量のデータを使って言語を学習することで、人間でも見破れない精度のニュース記事を生成したりすることが可能です。
Image GPTも含めて、アイデアとしてはGPT-3が起点になっていると考えられます。
また、モデルの構造もTransformerベースであり、GPTと同じような構造になっていると考えられます。

Image GPT
OpenAIが開発した画像生成モデルで、上記のGPTが原点になっています。
画像の一部を与えるとその続きを生成することが可能です。
こちらは一番左の画像のように、元の画像に黒い影でマスクし、その部分をImage GPTで生成したものです。
非常にうまく予測されていますね。

DALL-Eでも、画像の一部を与え、その設定を変えることにより、昼の様子や夜の様子を変えて描画することが可能でした。

VQ-VAE
VQ-VAE(Vector Quantized Variational Auto-Encoder)は、名前にAuto-encoderとある通り、画像を圧縮・生成する技術です。
VQ-VAEは、潜在変数を連続的なベクトルではなく、離散的なベクトルで表現します。
発想としては、テキストでも画像も離散的だということです。
例えば「犬」と「猫」の間に何かが存在するわけではありません。
そのように、ベクトルの補間に意味をなさないような離散的なものなので、離散的なベクトルで表現します。
DALL-Eでは、256×256ピクセルの画像を32×32ピクセルに圧縮して、画像のインプットとしており、その圧縮する手法にVQ-VAEのような手法を使っているようです。
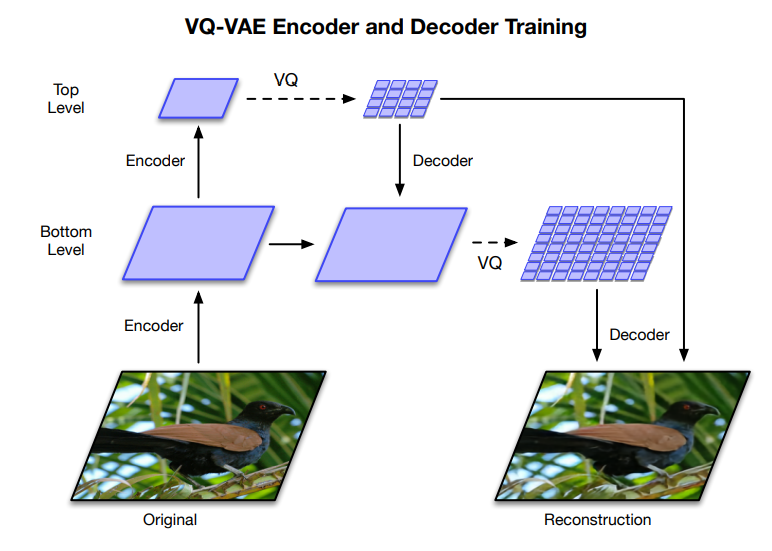
with VQ-VAE-2』
CLIP
CLIP(Contrastive Language-Image Pretraining)は、テキストと画像を組み合わせたモデルです。
従来のImageNetにあるような画像-ラベルのペアのデータセットを使うのではなく、Webから集められた画像とその画像につけられている説明文などのキャプションをペアとしたデータを使って学習します。
ImageNetデータセットなどのように「猫」「犬」といった決まったラベルではなく、「うちの猫」とか「ふてくされる犬」というような自由なラベルになっています。
ですので、通常の損失関数ではなく、正解ラベルは類似度を高くし、それ以外とは類似度を低くするといったcontrastive lossを使った学習を行います。
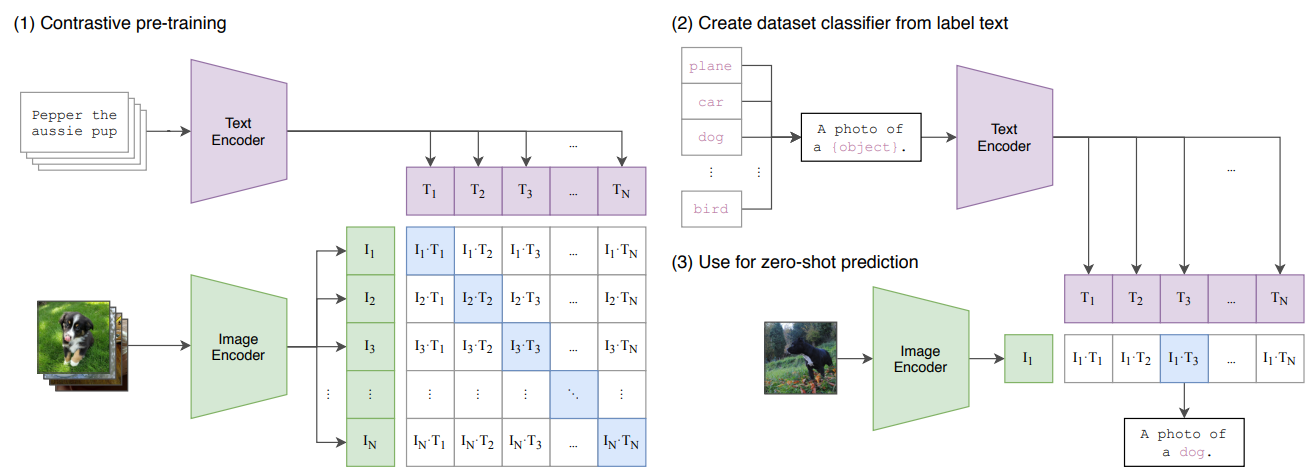
DALL-Eでは512個の生成された画像から32個をランキングし、表示しているとあります。
ですので恐らく、生成された512個のテキスト・画像のペアについて、CLIPを使ってそれぞれの類似度を計算し、抽出していると考えられます。

Sparse Transformer
Transformerで長い系列を処理するためにattentionを効率化したものです。
すべての位置にattentionを向けるのではなく、一部のみにattentionを向けることでメモリの使用量を減らします。
右の2つがSparse Transformerで提案されているattentionのパターンであるstrided patternとfixed patternです。一番左の通常のTransformerよりも網掛けの部分が少なくスパースになっています。
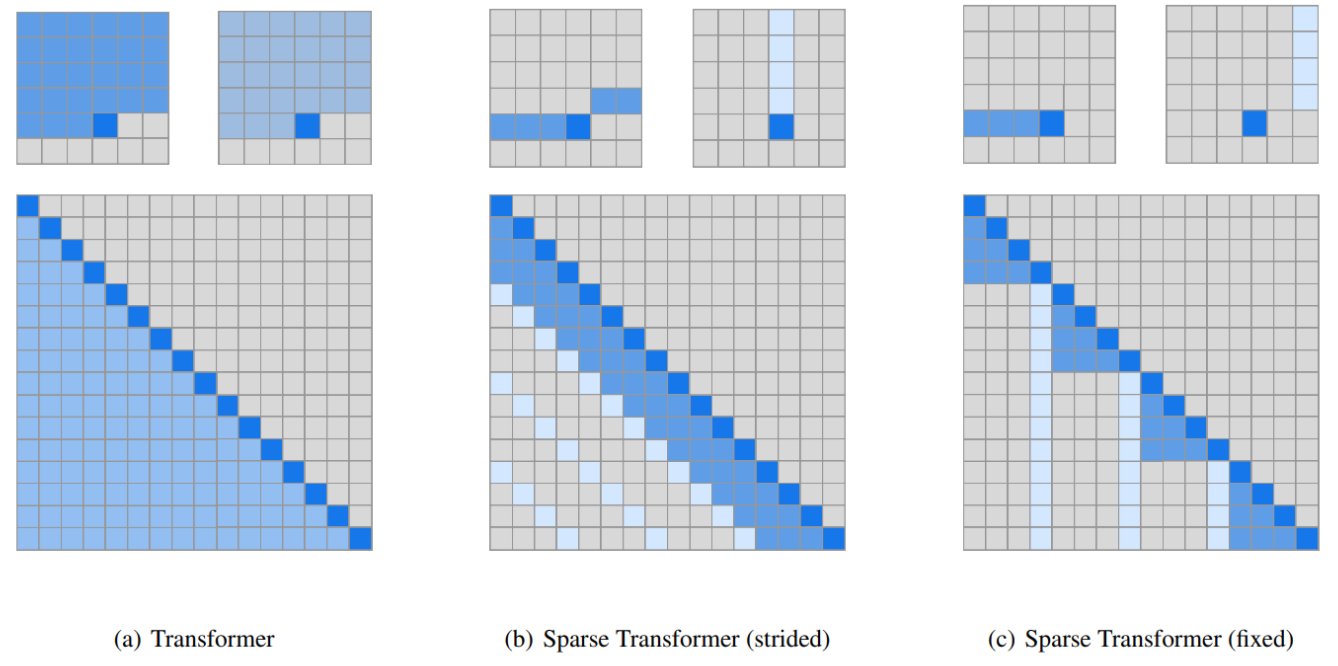
テキストと画像の1280トークンをインプットとする、とあり、インプット系列が長いのでSparse Transformerのattentionにより計算効率の向上を図っているものと思われます。

DALL-Eの仕組みをわかる範囲で想像しながら解説
(既に論文が出ていますので、正確な解説は以下の記事をご参照ください。)
上記の技術を使って、何をやっているかを見ていきましょう。
まず、OpenAIは2020年に巨大自然言語モデル「GPT-3」や「GPT-3」を画像生成に応用した「Image GPT」を発表しており、これらがベースになっていると考えられます。
実際に、DALL-Eは、“テキスト-画像のペアを使って学習し、テキストによる説明文から画像を作り出す120億個のパラメータのGPT-3”とあります。
ちなみに、自然言語処理のGPT-3は1750億個のパラメータを持つので、サイズとしてはそれよりは小さくなっています。
インプット
“Transformerのモデルで、1280個のトークン列をインプットとして、尤度の最大化を行って順番にトークンを生成するように学習する”とあります。
そして、ブログの最後には以下のように書かれています。
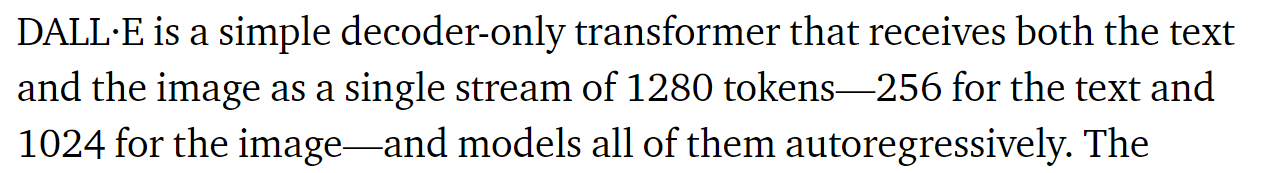
つまり、1280トークンのうち256トークンはテキスト情報で残りの1024(32×32)トークンは画像情報です。
テキストと画像情報を一つの列に並べ、それをインプットとして、次のトークン(テキストもしくは画像のピクセル情報)を順番に予測するように学習します。
まさに、GPTと同じような仕組みです。
細かいところだと、テキスト部分については、BPE(Byte-Pair Encoding)により分割し、それが256トークンになります。
そして、そのテキストのボキャブラリーは16,384語です。
画像部分は横一列に並び替え、テキストと同じように考えて、1ピクセルに8192種類(ボキャブラリーのようなもの)を持たせます。
元の画像は解像度が256×256ですが、256×256だと65,536トークンと以上に大きくなるため、VQ-VAEに似たような方法で使ってこれを32×32に圧縮します。
つまり、画像の特徴を表す離散的な潜在変数を使って次元を削減します。
これが後半の1024トークン(32×32ピクセル)に対応します。
処理全体
そして、GPT-3のようなモデルでauto-regressiveな形で処理をします。
以下がイメージ図です(もう論文が出たので、少し修正しました)。
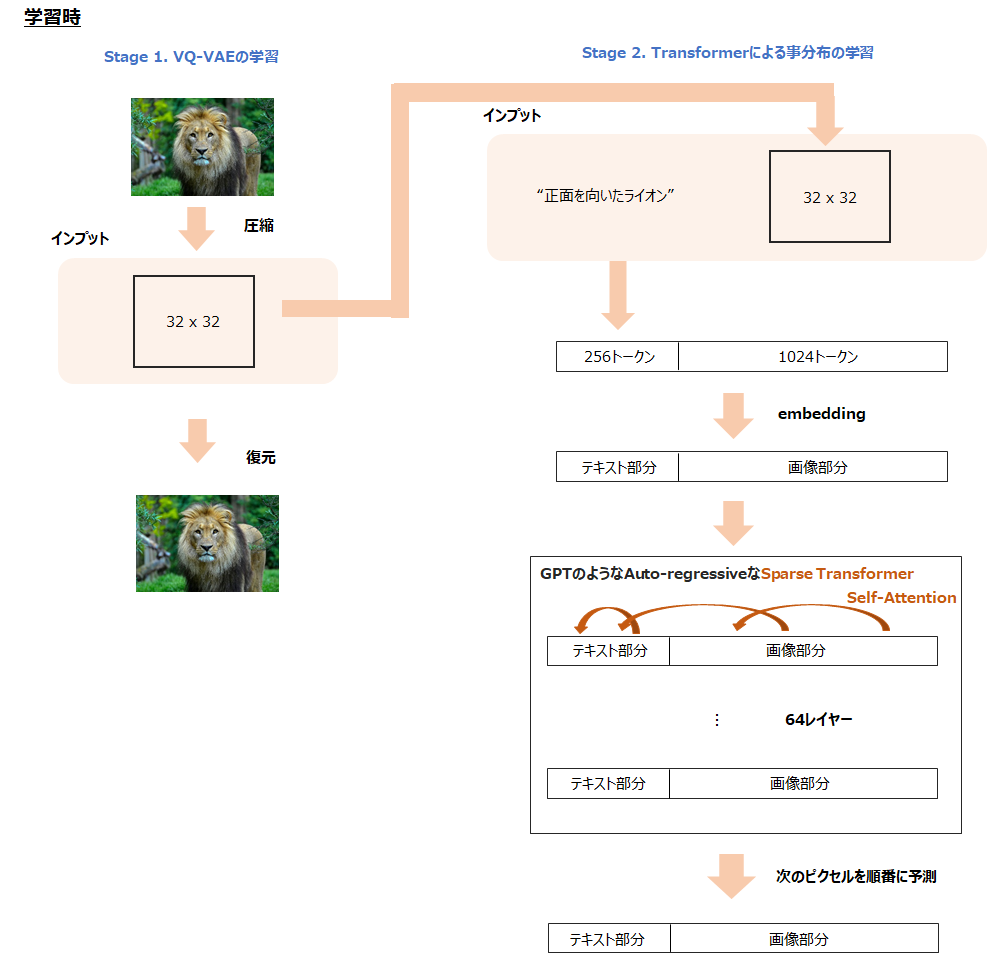
前半はテキスト情報、後半は画像情報を64層のself-attention層を持つTransformerにインプットします。
attentionはSparse Transformerの仕組みを使ってすべてにattentionを向けるのではなく、決められた場所に限定してattentionを向けます。
ただし、後半部分である画像の系列はすべてのテキストにattentionを向けるとの記載があります。
これにより、テキストと画像の学習を同時に行うことが可能です。
データセット
CLIPで使用したようなWTI(WebText Image)データ背とのような画像とテキストのペアからなる恐らくかなり巨大なコーパスを使ってこのモデルを学習します。
そうすると、前半のテキスト部分だけをインプットとして、auto-regressiveな処理で画像を生成することができるというものだと考えられます。
画像生成
実際に画像を生成するときは、前半のテキスト部分をインプットとします。
もしくは、必要に応じて前半のテキスト部分と、後半の画像部分の一部をインプットとすることで、その続きを生成することが可能になります。
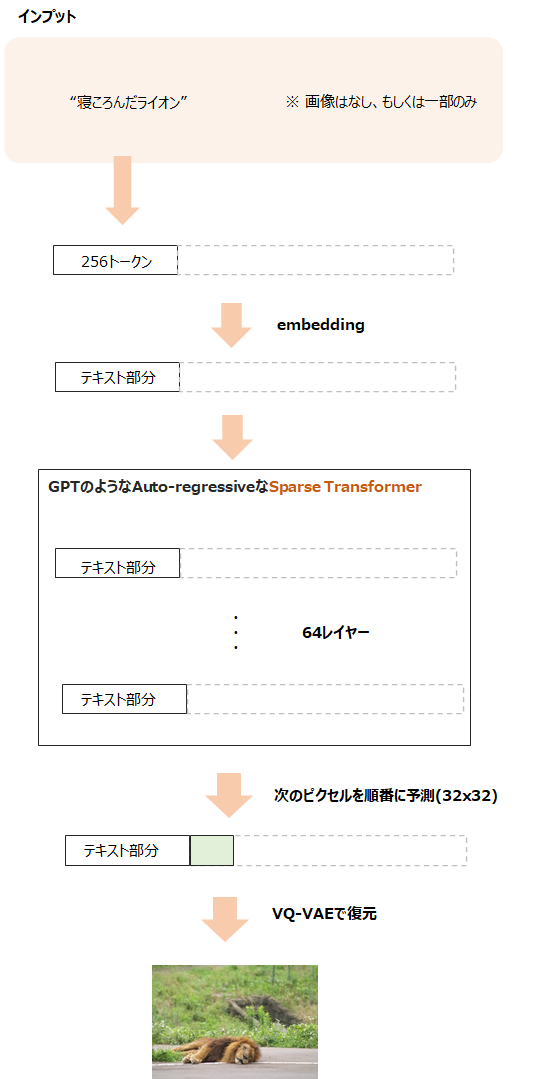
CLIPを使ったランキング
これで一つの画像が生成されました。
この方法で512枚の画像を生成します。
そして、テキスト情報と生成された画像のペアについて、最後にCLIPを使って類似度を計算してランク付けを行い、上位32枚を抽出します。

以上が、私のわかる範囲での解釈です。
そこは論文が出るのを待ちたいと思います。
まとめ
今回は非常に興味深いブログであったOpenAIのDALL-Eを見てきました。
ちょっとフライング気味ですが、せっかくなのでわかる範囲で想像も交えながらモデルを解説しました。
皆さんもどういったモデルかを考えてみてはいかがでしょうか?
では!