今回はOpenAIの『CLIP(Contrastive Language-Image Pre-training)』を解説したいと思います。
CLIPは画像の分類に利用されるモデルですが、今までのモデルと何が違うかというと、自然言語処理の技術を応用する点です。
一般的な画像分類では、たくさんの画像を用意して、それぞれ対して犬、猫、リンゴ、などのラベルをつけます。
それを教師データとして学習します。
しかしながら、その方法には以下のような問題点があります。
- ラベル付けに非常にコストがかかる。
- ラベルの種類が限定的で、学習対象の種類についてはうまく分類できるが、初めて見る対象(例えば、犬と猫を学習して、果物を分類するなど)については分類精度が低い。
CLIPでは、こういった問題に取り組んでいきます。
ちなみに、CLIPはモデルの仕組みではなく事前学習方法ですので、モデル自体はResNetやVision Transformerを使います。
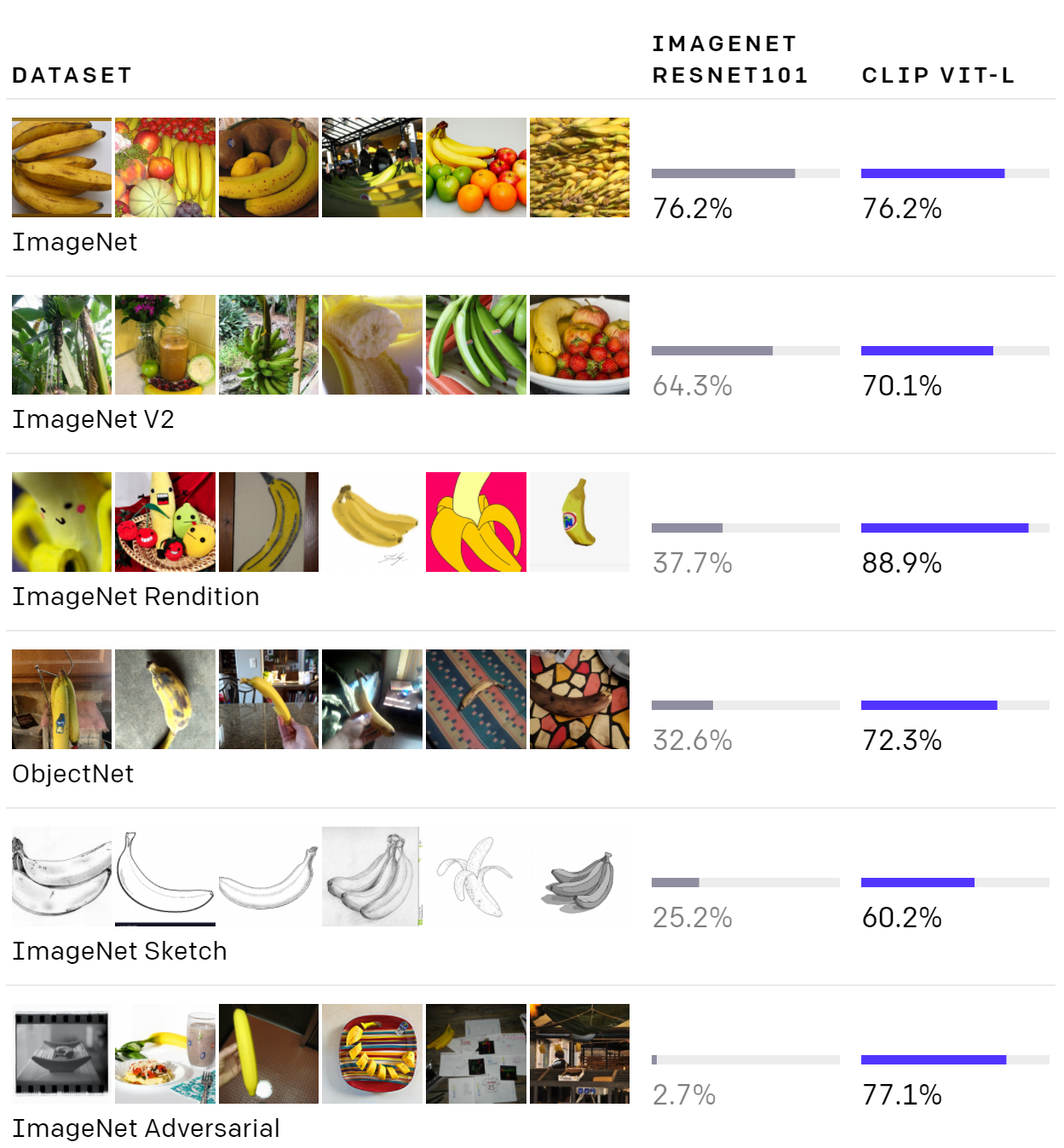
以下は、ImageNetで学習ているResNet-101の精度と、Vision Transformerを使ったのCLIPの精度の比較です。
ImageNetの精度はほぼ同じですが、その他のデータセットでは、通常のResNet-101では精度が大きく悪化しています。
これは、その他のデータセットは見たことがなく、zero-shot(ここでのzero-shotとは学習していないデータセットを予測すること)になるからです。
一方で、CLIPのViT(Vision Transformer)では精度が悪化してらず、zero-shotでもロバストなモデルであると考えられます。
自然言語処理の「GPT-3」にも共通しますが、OpenAIは汎用的なAIの開発に取り組んでおり、今回も特定のタスクの精度を向上させるよりも、初めて見るデータセットに対して精度を向上させることを目的としています。
また、CLIPは同じくOpenAIの自然言語から画像を生成するモデル「DALL-E」でも一部用いられています。
興味のある方はこちらの記事をご覧ください。

『CLIP』の論文はこちらになります。
Learning Transferable Visual Models From Natural Language Supervision
この論文では「GPT-3」の論文と同様に、さまざまな分析がされており、非常にボリュームが多くなっています。
それぞれ非常に興味深いのですが、今回は分析結果についてはすべては解説せずにいくつかの結果だけ紹介するにとどめておきます。
第二回として、続きやより詳細な結果をご紹介できればと考えています。
また、CLIP APIを使って、ドラクエ画像で遊んでみた結果がこちらの記事にありますので、ご参考にしてください。

では、見ていきましょう。
目次
CLIPとは
まず、CLIPの考え方として、zero-shot(初めてみるデータセット)でもうまく画像を分類できるようにする、というのが目的です。
しかしながら、前述のとおり、今までのように画像とラベルのペアを集めて、それを教師データとして学習することには以下の問題があります。
- ラベル付けに非常にコストがかかる。
- ラベルの種類が限定的で、学習対象の種類についてはうまく分類できるが、初めて見る対象については分類精度が低い。
そこで、CLIPではWebから大量の画像とテキスト(画像のタイトルや説明)のペアを取得します。
これにより、まずラベル付けのコストはなくなります。
さらに、Webから集めてくることで、学習用の画像が非常に多くなり、ImageNetの1400万画像よりももっともっと多くすることが可能です。
実際、CLIPの学習データは4億ペアとなっています。
しかも、画像の種類は多岐にわたります。
これにより、特定のデータセットに過度にフィッティングしない汎用的なモデルの構築を試みます。
自然言語処理のGPT-2、GPT-3ではWebから集めた巨大な自然言語データを学習させることで、zero-shotでもタスクを解くことができる非常に汎用的なモデルができていますが、この考え方を画像に適用しています。
ただし、工夫が必要な点は、ImageNetなどでは、ラベルは「犬」、「猫」の1000種類などと決まっていますが、Webから取得したデータはラベルが決まっていないところです。
同じ犬の写真でも「うちの犬」だったり「犬の写真」だったり、「すねる犬」だったりします。
そうすると、さすがに画像から「うちの犬」なのか「犬の写真」なのかを正確に予測するのは非常に難しいタスクになります。
人間でもそれを間違いなく当てるのは無理ですね。
そこで、Contrastive pre-trainingという考え方を導入します。
CLIPは「Contrastive Language-Image Pre-training」の略で、まさに自然言語と画像を使ってContrastive objectiveを目的関数にした事前学習モデルです。
- これまでの画像分類の問題点
- ラベル付けに非常にコストがかかる
- ラベルの種類が限定的で、学習対象の種類についてはうまく分類できるが、初めて見る対象については分類精度が低い
- CLIPでは、
- インターネットから画像・テキストのペアを収集することにより、幅広いラベルを学習する
- 自然言語処理による教師あり学習を組み合わせる
- それにより、初めて見る画像についても、うまく分類できるようにする
- Contrastive objectiveを目的関数にした事前学習を行う
CLIPの仕組み
データセット
CLIPのインプットは、画像とテキストのペアです。
インターネットから集められた4億ペア(画像-テキスト)のデータセットを使います。
Wikipediaで100回以上出現する単語をベースとします。そして、それらの単語で検索し出てきた画像-テキストのペアを抽出します。
この検索は50万個の単語を利用し、各検索結果につき、20,000ペアを上限としています。
このデータセットをWebImage Textということで、WITと呼びます。
事前学習方法
まず、1つの実験を行っています。
画像についてはCNNを、そしてテキストの処理にはTransformerを使い、画像からそのキャプションを予測するという手法を試しています。
しかしこの方法は、ImageNetデータセットを使って精度を確認すると非常に効率が悪いことがわかりました。
以下の図の通り、TransformerではなくBag-of-Wordsを使ったモデルよりも3倍も計算効率が悪くなっています(青がTransformer、オレンジがBag-of-Words)。
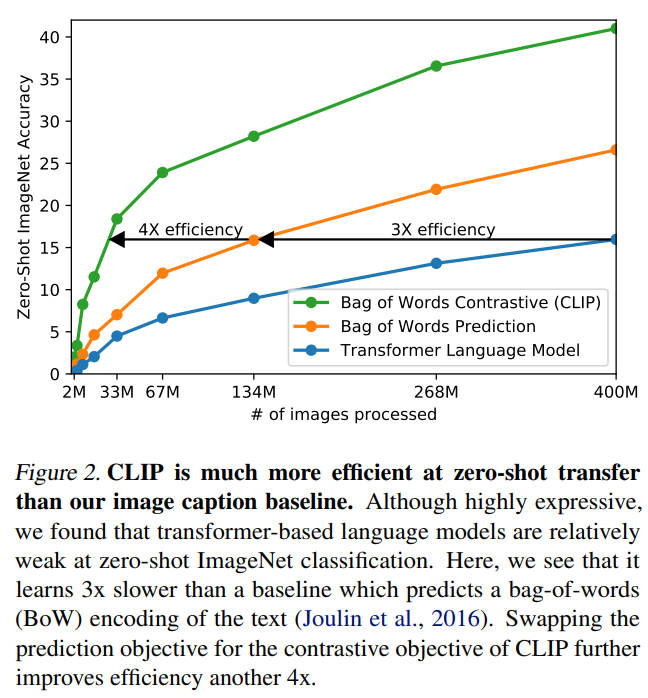
この理由の一つとして、ImageNetやCIFARなどといったデータセットであれば、決まった数のラベルがありますが、インターネットから集めた画像・テキストのペアのテキストラベルは自由なフォーマットを取ることが考えられます。
「犬」、「猫」を予測するのは簡単ですが、「犬の写真」だったり、「可愛い猫」などを予測するのは人間にとっても非常に難しいタスクです。
Contrastive Pre-Trainingの導入
そこで、CLIPでは“Contrastive ojective”を使います。
“Contrastive objective”は、このインプットのラベルが何か?を予測するのではなく、このインプットラベルは複数の候補のうちどれか?を予測します。
そうすることにより、ラベル候補が「犬の写真」、「可愛い猫」、「可愛い犬」、「ソファーで寝る犬」があって、写真が「猫」であれば答えは「可愛い猫」であるということがわかります。
このContrastive objectiveを使って学習した結果が上図の緑の線です。
モデルはBag-of-Wordsを使ったものですが、Contrasitve objectiveを使わない場合と比べて同じ精度に達するまでの計算量が1/4に減っています。
Contrastive Pre-Training
contrastive pre-trainingのもう少し具体的な方法を解説します。
ミニバッチ数を\(N\)とすると、そのミニバッチの中には\(N\)個の画像とテキストのペアがあります。
そして、Contrastive objectiveでは、\(i\)番目の画像であれば\(i\)番目のテキストがペアとして対応するので、正例は\(i\)番目のテキストになり、負例はそれ以外のすべてのテキストとします。
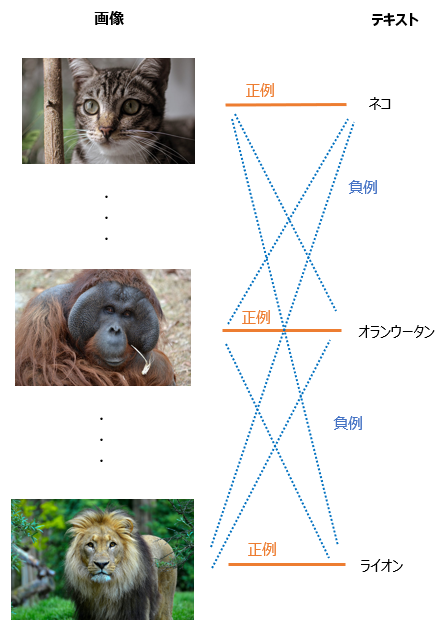
つまり、各サンプルごとに1つの正例と\(N-1\)個の負例を設定するので、バッチ全体では\(N\)個の正例と\(N^2-N\)個の負例ができます。
そして、正例については類似度を高くし、負例については類似度を低くするように学習します。
疑似コードは以下のようになっています。

順を追って見ていきましょう。
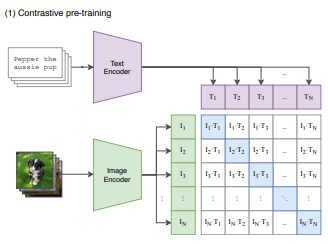
まず、最初の2行で、画像のエンコーダー、テキストのエンコーダーを使い、それぞれをエンコードします。

エンコードされた各埋め込み表現にを行列を掛けてサイズを\(d_e\)にします。

画像・テキストの埋め込み表現をこの2つのベクトルの内積を計算し、それをlogitとします。

そして、損失を計算します。ここではSymmetric lossと呼んでいます。
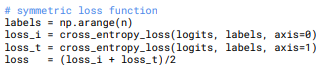
少々追加で解説します。
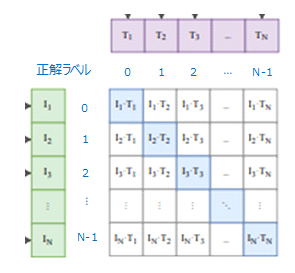
ラベルは0からn-1までの数字を並べたものを設定し、loss_iは画像の損失でloss_tはテキストの損失です。
loss_iは行方向(横方向)にクロス・エントロピー誤差を計算し、loss_tは列方向(縦方向)に損失を計算します。
つまり、以下の図の青の部分の対角成分が正しい組合せ(正例)になっているので、例えば1番目の画像であれば、正解ラベルは0であり、それを正解ラベルとして行方向にクロス・エントロピー誤差を計算します。
同様に、2番目のテキストであれば2番目の行、つまりラベル”1”が正しいので、それを正解ラベルとして列方向にクロス・エントロピー誤差を計算します。
そして、loss_iとloss_tの平均を取っています。
事前学習の全体像はこちらです。
推論
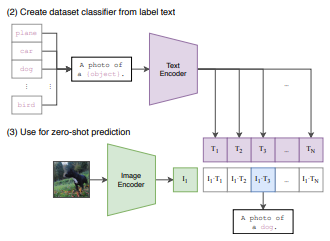
あとの実験のときにも見ますが、推論をする際は、そのデータセットのすべてのラベル候補の中から類似度がもっとも高いラベルを選びます。
予測の際に正解ラベルをそのまま「plane」、「car」とするのではなく、「A photo of plane」や「A photo of car」という形で、A photo of ~とします。
これにより、事前学習と推論時のラベルが近くなり、精度の改善が見られたそうです。
これを“Prompt Engineering”と読んでいます。
そして、それを画像とラベル(テキスト)をそれぞれエンコーディングし、類似度がもっとも高い画像を選びます。
モデル
画像、テキストのそれぞれについてエンコードするモデルを決めます。
まず、画像ですが、1つめはResNet-50を少し改良したモデルをベンチマークとして使います。
2つめの画像のモデルはVision Transformer(ViT)です。
Vision Transformerについては、以下の記事が参考になります。
https://qiita.com/omiita/items/0049ade809c4817670d7
そして、テキストのエンコーダーはTransformerを使います。
レイヤー数12、隠れ層の次元512、アテンション・ヘッドを8とした6300万パラメータとします。
最大長は76を上限とします。
画像のモデルは、以下の5つのResNetと3つのVision Transformerを使います。
- ResNet-50
- ResNet-101
- ResNet-50x4
- ResNet-50x16
- ResNet-50x64
- ViT-B/32
- ViT-B/16
- ViT-L/14
すべて32エポック学習します。
実験
Zero-shot Transfer
Zero-short Transfer
ここでのゼロ・ショットとは、学習していないカテゴリを分類するのではなく、初めてのデータセットに対して分類することを指します。
画像のインプットはそのまま画像です。
テキストのインプットは、データセット中のすべてのラベル候補をインプットとします。
例えば、CIFAR-10データセットであれば10個のラベルがそれぞれインプットとなります。
そして、各エンコーダーで画像とテキストの埋め込み表現を計算し、各埋め込み表現のコサイン類似度を計算して、softmax関数でどのペアの確率が高いかを予測します。
こちらは少し古いモデルですがVisual N-Gramsとの比較です。
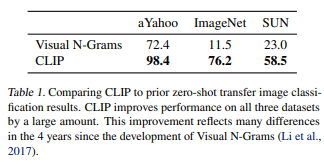
Visual N-Gramsと比較すると大幅に精度が改善していることがわかります。
特にImageNetデータセットでは11.5%から76.2%に精度が改善しています。
76.2%というのは、ImageNetの約1300万のラベル付きデータで学習せずに、あくまでゼロ・ショットでの精度になります(もちろんVisual N-GramsもImageNetでは学習していません)。
そして、CLIPのゼロ・ショットの精度はほぼImageNetで学習したResNet-50と同水準になっています。
また、トップ5の結果は95%にも及ぶとのことです。
Prompt Engineering
インターネットから収集された画像・テキストのペアのテキスト情報は、一つの名称になっているわけではなく、文章になっていることが多いです。
そこで、例えばImageNetのラベルを予測する場合に、ラベルを「猫」として予測するのではなく、「猫の写真」とした方がうまくいくという結果になっています。
一応、論文の沿って説明すると“A photo of a {label}”としています。
{label}にcatなりflowerなりのラベル名が入ります。
これにより、ResNet-50ベースでImageNetデータセットのゼロ・ショット設定で精度が+1.3%改善したそうです。
これをprompt engineeringと呼びます。
他にも、Oxford-IIIT Petsデータセット(ペットを分類するデータセット)の場合、“A photo of a {label}, a type of pet”とし、Food101データセット(食べ物を分類するデータセット)の場合“A photo of a {label}, a type of food”と、説明文を付加します。
あと、複数のprompt engineeringをアンサンブルするという工夫もします。
例えば、一つのラベルに対して“A photo of a big {label}”、“A photo of a small {label}”などの複数のプロンプトで予測し、その平均を取ります。
ただし、予測確率の平均を取るのではなく、テキストをエンコーディングした埋め込み表現の平均を取り、その埋め込み表現に対し分類をします。
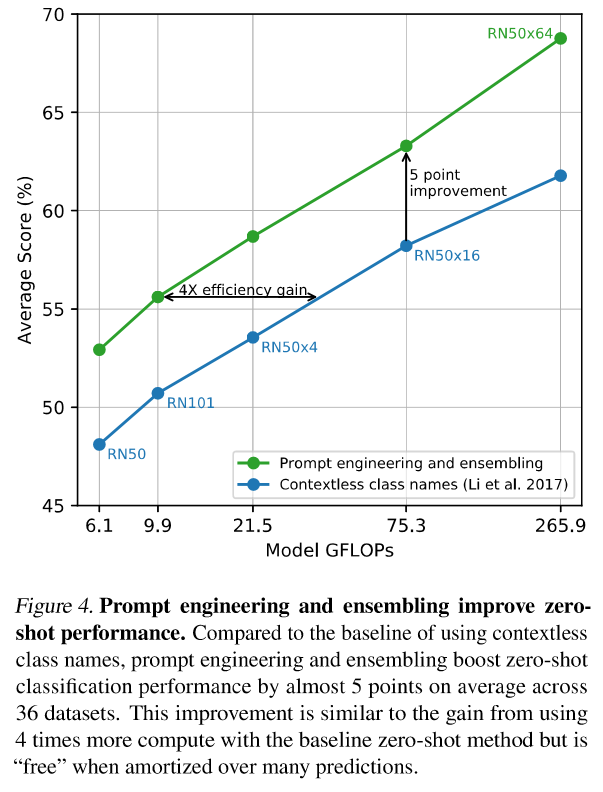
80種類のpromptによるアンサンブルで、ImageNetデータセットで+3.5%改善します。
prompt engineeringによる効果と合わせて約5%の改善です。
パフォーマンス分析
次に、CLIPと各データセットで学習されたResNet-50のパフォーマンスを比較分析します。
CLIPはzero-shot設定です。
ResNet-50はImageNetで学習されており、各データセットの画像の特徴量を求め、その特徴量に対してロジスティック回帰モデルにより教師ラベルを使ってファインチューニングします。
いわゆるLinear Probeですね。
ですので、特徴量はResNet-50により計算される特徴量を使い、ロジスティック回帰のパラメータのみを学習します。
比較結果は以下です。
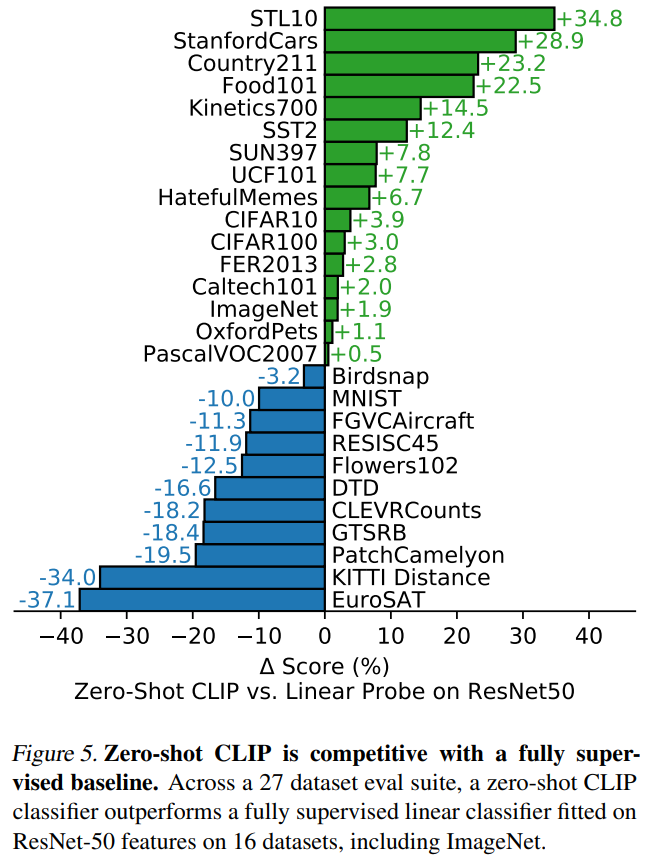
これは、CLIPの精度からResNet-50のLinear probeの精度を引いた数値が載っています。
緑はCLIPの精度の方が良いデータセット、青はResNet-50の精度の方が良いデータセットです。
全体としては25データセット中16データセットでCLIPの方が精度が良くなっていますが、一貫してどちらかの方が良いというわけではなく、データセットにより結果は大きく違います。
STL-10は学習サンプルが13000と比較的少なくなっていますが、このデータセットではCLIPの精度は99.3%とSoTAを達成しています。
このように結果が大きく違う理由について、事前学習データとタスクデータの違いが挙げられています。
ImageNet、CIFAR-10、CIFAR-100といった割と一般的なデータセットについては、ともに事前学習で見たことのある画像なので、お互いあまり差はありません。
Kinetics700やUCF101データセットではCLIPが大きく上回っていますが、これらのデータセット動画から切り取った画像データセットで、ラベルが動詞などになっています。
ですので、自然言語によるラベルデータを使ったCLIPの方が、名詞ベースのラベルデータを使ったImageNetよりも精度が良くなっていると考えられます。


一方で、CLIPの精度が大きく下回っているデータセットは抽象度が高く、複雑な画像サンプルになっています。
EuroSATやRESISC45は衛星画像で、PatchCamelyonはリンパにある腫瘍を見つけるデータセットです。
これらをzero-shotの設定で解くというのは確かに難しいと考えられます(人間でも簡単にはできないですね)。
他にも、CLEVRCountsは物体の数を数えるタスク、GTSRBは自動運転の画像、KITTI Distanceは一番近い自動車間の距離を予測するタスクになっており、これらのデータセットでは、教師あり学習の方が良くなっています。
これらのタスクは人間にとっては、それほど難しいタスクではないため、今後の課題と言えるでしょう。
Few-shotとの比較
続いて、few-shot(いくつかのサンプルだけ学習する)との比較をしています。
こちらはCLIP、BiT-M、SimCLR、ResNet50で、各クラスに16サンプル以上ある20データセットを評価した場合の精度の平均です。
横軸は各データセットで学習した1クラス当たりのサンプル数です。
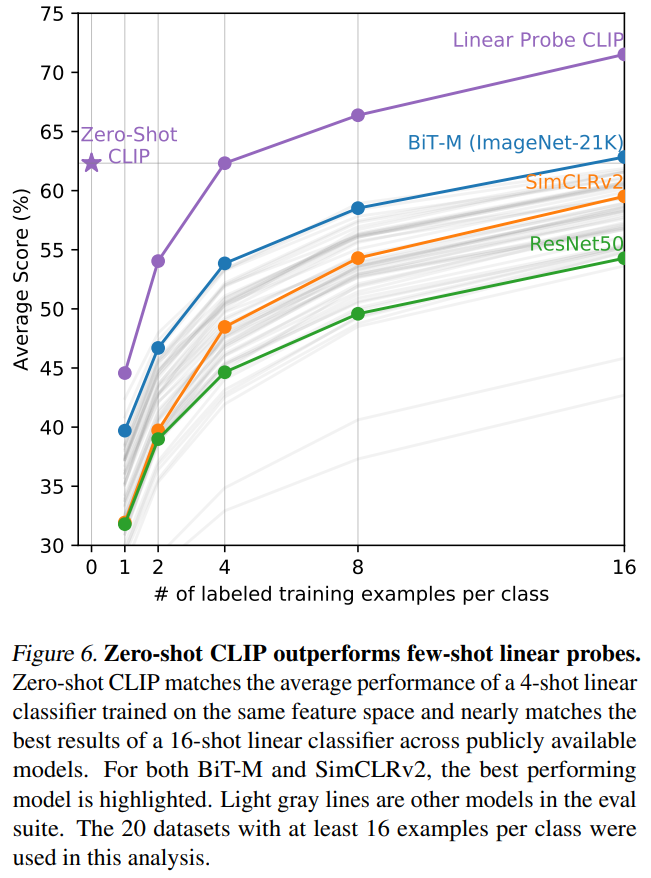
紫色の線がCLIPで、同じく紫の星マークがCLIPのzero-shotになります。
普通に考えると、zero-shotはfew-shotよりも悪くなると考えられますが、そうではないようです。
zero-shotと同じになるのは4-shotとなっています。
これは画像には複数のものが映っていますが、教師あり学習でサンプル1件だとそれをうまく捉えられないからと考えられます。
そして、CLIPのzero-shotとその他のモデルのfew-shotを比較すると、一番良いBiT-Mの16-shotと同等の精度になっています。
Zero-shotとFew-shotの精度が同じになる教師データ数
CLIPのzero-shotとfew-shotの精度が同じになる教師データ数をデータセットごとに見ていきましょう。
ここでは厳密に精度を比較して必要なサンプル数を求めるのではなく、1、2、4、8、16、全データ、で精度を計算し、それを対数線形補間することで求めています。
では、結果は以下のようになっています。
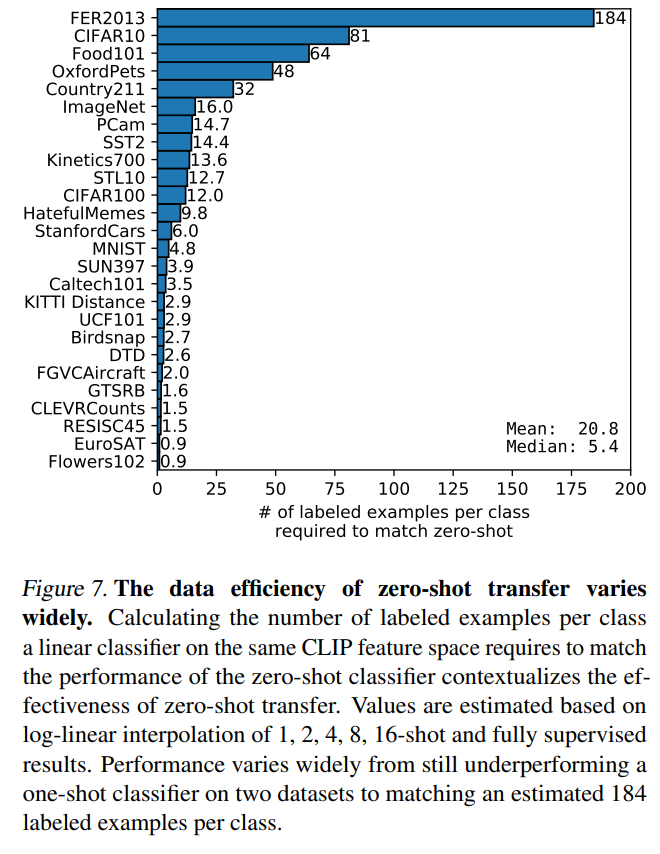
データによって差が非常に大きいことがわかります。
FER2013データセットでは184サンプル必要なのに対し、EuroSAT、Flowers102データセットで1サンプルの場合でもzero-shotよりも良くなっています。
1つのクラスあたり必要なサンプル数の中央値は5.4で、平均では20.8です。
続いて全教師データを使った場合とzero-shotの比較です。
モデルが同じなので全教師データを使った場合が最大になりますが、こちらもデータセットによってばらつきがあります。
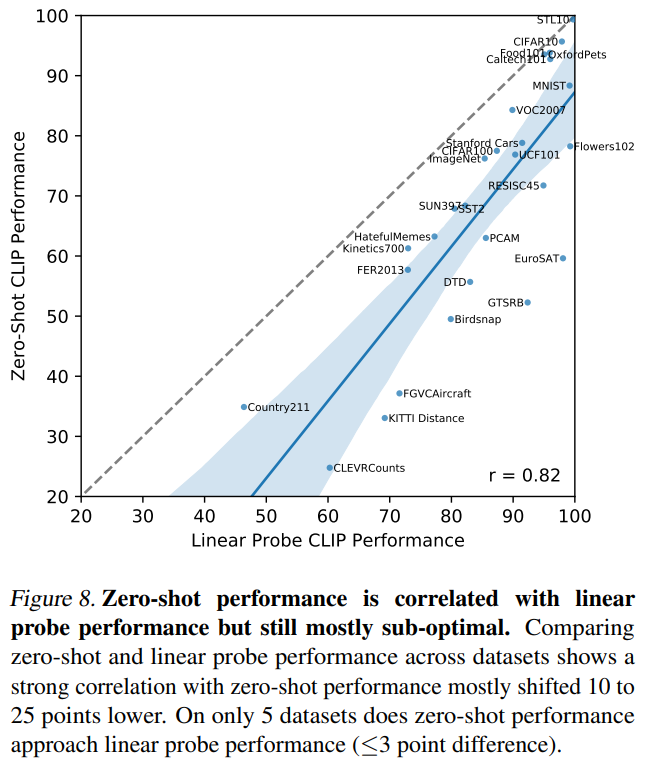
STL10やCIFAR10、Food101などはzero-shotでも全教師データを使った場合の精度に近く、全教師データを使った場合の90%以上の精度になっています。
そして、全教師データを使った場合の精度が高いほど、zero-shotの精度も高いということも、点が右上がりであることからわかります。
相関係数は0.82でp値は10-6以下とのことです。
このデータセットによる違いは、データの質に依っているとのことです。
表現学習
続いて、表現学習の観点です。
ここでは、事前学習により得られたモデルで、各サンプルの埋め込み表現を計算します。
そして、その埋め込み表現は変えず、線形分類器をその上につけて分類を行います。
これで精度が高いモデルほど、画像の良い表現、つまり特徴を捉えていると考えられます。
66個のモデル、27データセットについて、比較しています。
まず、以下の図の左側が12個のデータセットの結果です。
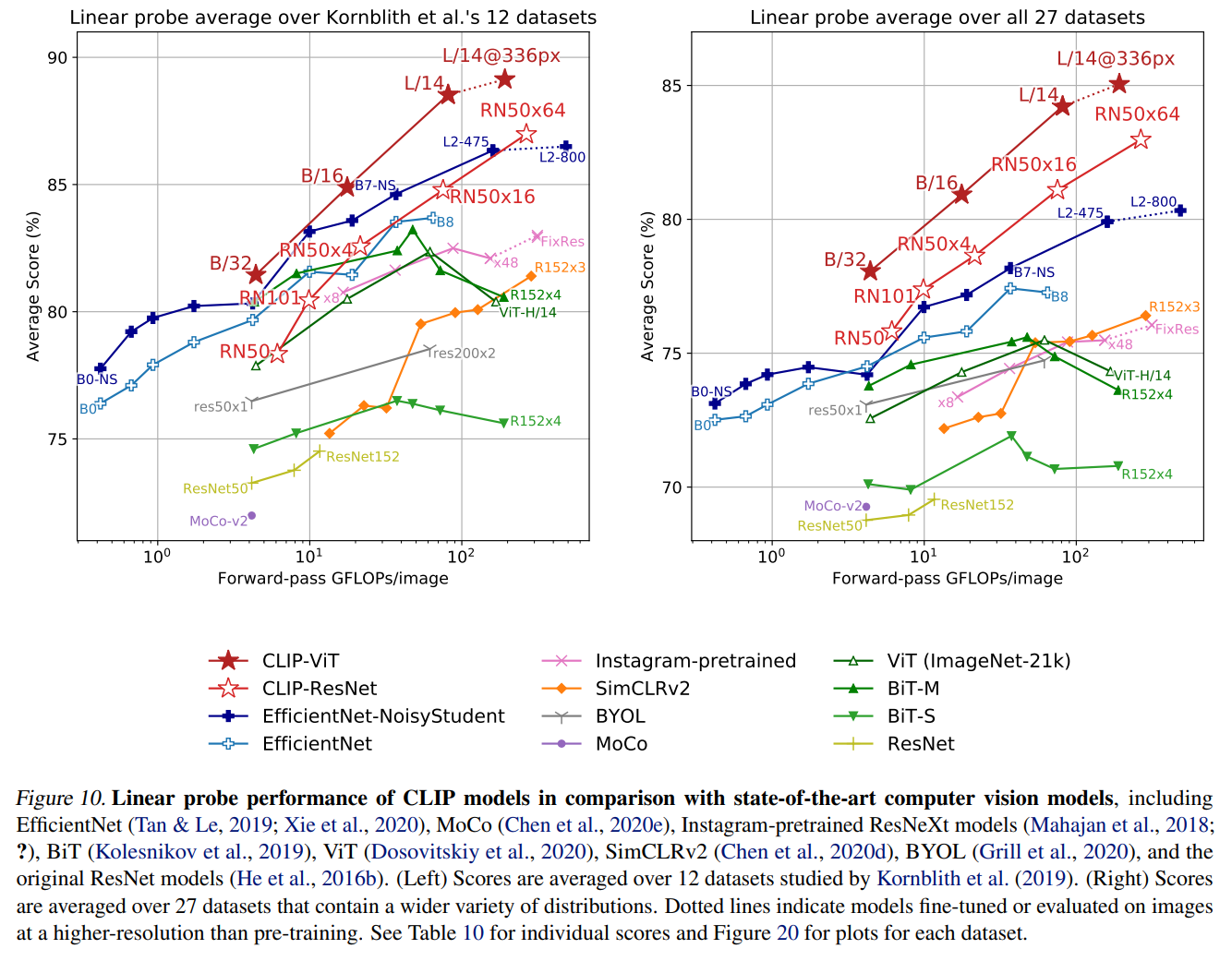
まず、色が塗られていない☆がResNetをCLIPで学習させたモデルです。
オリジナルのResNet(黄色)やBiT-S(緑の下向き▼)よりも上回っています。
しかしながら、BiT-M(緑の上向き▲)と比べるとImageNetは精度が若干下回っています。
一方、赤の★のCLIP-ViTでは、非常に精度が高くなっています。
これは、学習データが多くなるとTransformerの優位性が特に発揮されるということかと思います。
分布のシフトに対するロバスト性
ディープラーニングのモデルは教師データに過度にフィットしてしまうという分析が多数あります。
CLIPはzero-shotなのでそのデータセットを見たことがなく、過度にフィットするということはありません。
では、CLIPがどの程度、分布のシフトに対いてロバストなのかを見てみましょう。
以下の左図は、CLIP以外はImageNetで学習したモデルを12個のデータセットで評価した結果です。
横軸がImageNetの精度で、縦軸が12データセットの精度の平均です。
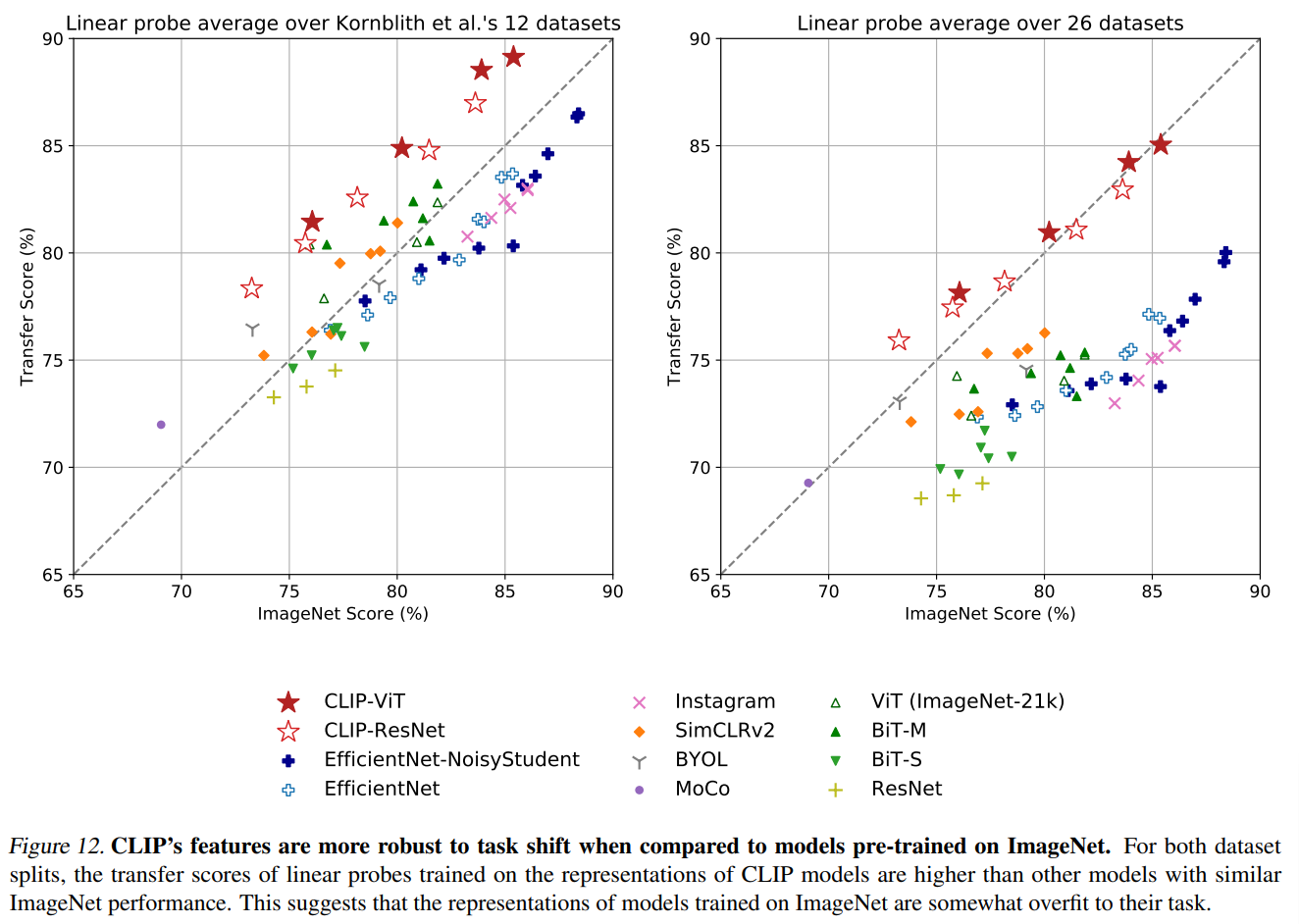
星ではない他のモデルは、ImageNetの精度に比べて、12データセットの精度は低くなっています。
一方で、星マークのCLIPよる精度はImageNetよりも精度が高く、他のモデルと比較しても転移した場合の精度は上回っています。
右図はすべてのデータセットで試した場合ですが、同じような結果になっています。
CLIPの方が転移した場合の精度が良く、他のモデルはImageNetよりも精度が下がっています。
ここから、ImageNetで学習したモデルはImageNetにオーバーフィットしており、CLIPはよりロバストであるということがはっきりとわかります。
素晴らしい結果ですね。
まとめ
今回はOpenAIの画像と自然言語処理を組み合わせたモデルである『CLIP』を見てきました。
GPTの研究と同じ流れで、大量のデータを事前学習させることにより、zero-shotでも精度が非常に高くなっており、ロバスト性も非常に高いことがわかります。
かなり汎用的な画像分類ができているように思えますね。
まだ、論文には続きがありますので、それらについての解説はまた今度にさせていただきます。
では!!