今回は「事前学習(pre-training) - ファインチューニング(fine-tuning)」を説明したいと思います。
以下の2015年の論文を参考に説明していきます。
この事前学習 - ファインチューニングという学習方法は、非常に有効な手段で、現在の主流となっているGPTやBERTなどの高精度なモデルを生み出すきっかけとなっています。
今後もこの方法は変わらないんじゃないかなぁと思う、重要な考え方ですので是非理解していただければと思います。
まず、先に結果のひとつを記載しておくと、Rotten Tomatoesというデータセットを使って、センチメント分析をした場合、LSTMをそのまま使った場合だと79.7%だった精度が、モデルは変えずにラベルのないを大量のデータセットで事前学習するだけで、83.3%と3.6%も上昇しています。
素晴らしい結果ですね。では、この論文について見ていきたいと思います。
目次
事前学習(pre-training)とは
そもそもこの論文は再帰的ニューラルネットワーク(RNN)を使ったモデルが前提とされており、RNNは学習が難しいのでテキスト分類などではあまり使われない、という問題に対応するもです。
では、どうやればRNNでテキスト分類の精度を上げるか?というのを考えていきます。
テキスト分類が難しい原因の1つは、分類するためのラベルデータが少ないというところにあります。例えば、よく使っているデータセットでもたかだか数万サンプルしかありません。
人間は自然言語処理は非常に得意ですが、人間は小さい頃から字を学び、たくさん本やニュースを読んで、文章のニュアンスなどを理解できるようになっています。一方で、機械は高々数万程度の特定のタスクに偏った文書を読んで、その狭い範囲だけで文章のセンチメントなどを理解して予測しなくてはいけません。
そこで、考えたのが事前学習で、人間のように事前に色々な文書を読んで、自然言語処理の基礎を学んでから特定のタスクを解かせようというものです。その色々な文書はWikipediaだったり本のコーパスだったりで、ここでは文書分類やセンチメント分析を行う必要はなく、ただ、文書を理解するだけです。ですので、ラベルは不要で、文書がたくさんあれば十分なのです。
ファインチューニング(fine-tuning)とは
ファインチューニングとは、ラベルなしデータを使って言語モデルを学習させたあと、解きたい特定のタスクの教師ありデータを使って、パラメータをチューニングをすることを言います。
例えば、Wkipediaなどの教師なしデータを使って言語モデルを学習させたあとに、センチメント分析用のデータセットを使って、判別モデルを学習するものです。
事前学習の効果
この論文により以下の事前学習の効果がわかります。
- 言語モデルが文章を記憶することでLSTMなどのモデルが安定する。
- 大量のラベルなしデータを追加することで精度が改善する。
二種類の事前学習
この論文では2種類の事前学習が提案されています。一つ目は、Autoencoderと呼ばれるもので、二つ目はRecurrent Language Modelと呼ばれるものです。
Autoencoder
Autoencoderは、インプットをLSTMに通して、インプットとまったく同じ結果をアウトプットするように学習します。以下の図だと、W、X、Y、Z、<eos>がインプットで、<eos>のあとにW、X、Y、Z、<eso>と予測していきます。
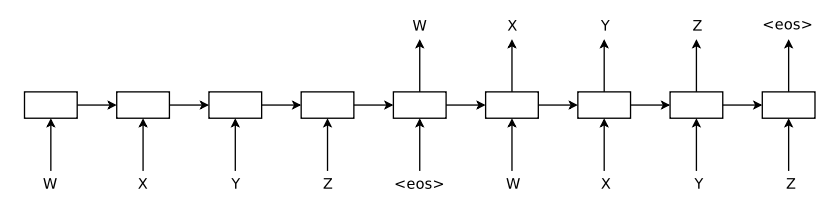
ここで、encoder(左半分)とdecoder(右半分)は同じウェイトを使用します。
そして、得られたウェイトを教師あり学習のウェイトの初期値とします。
この事前学習により学習させたLSTMを“SA(Sequence Autoencoder)-LSTM”と呼びます。
Recurrent Language Model
Recurrent Languageモデルでは、それまでの単語から次の単語を予測します。
ですので、上図の右半分がRecurrent Languageモデルに対応します。
このモデルを“LM(Language Model)-LSTM”と呼びます。
結果
ここでは、IMBDデータセット、Rotten Tomatoesデータセットなどを使って実験しています。
IMDBデータセット
まず、IMDBデータセットですが、このデータセットは、1ドキュメントの平均単語数が241単語、最大で2,526単語と 単語数は 比較的多くなっています。
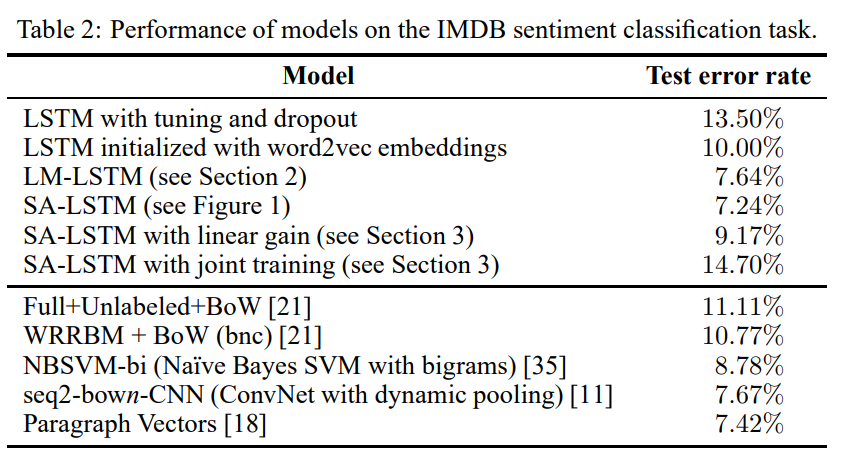
さて結果ですが、1行目がそのままLSTMを学習させた場合で、3行目、4行目がそれぞれLM-LSTM、SA-LSTMですが、事前学習することで13.50%からそれぞれ7.64%、7.24%と大幅に精度が改善しています。
2行目は、単語の埋め込み表現にWord2Vecで学習した埋め込み表現を初期値にした場合ですが、改善はしているもののそれほど精度は良くないようです。
そして、SA-LSTMはParagraph Vectors(いわゆるDoc2Vec)よりも精度は高く、SoTAを達成しています。
Rotten Tomatoesデータセット
続いてRotten Tomatoesデータセットですが、このデータセットは、1ドキュメント当たり平均22単語、最大52単語と比較的短くなっています。
こちらの結果は、1行目のそのままLSTMを学習させた場合と比較して、3行目、4行目のLM-LSTM、SA-LSTMの結果は、事前学習をしても改善していません。
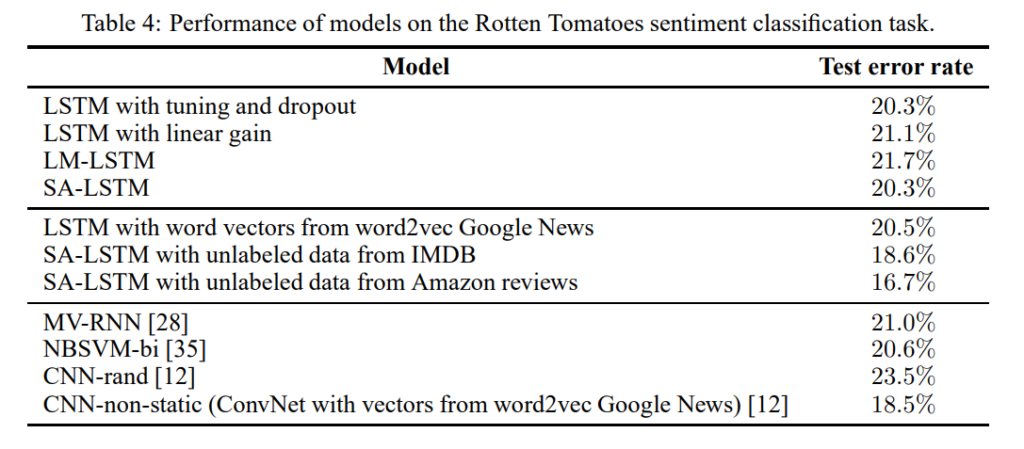
しかしながら、6行目、7行目は、IMDBデータセットやAmazon reviewsデータセットの“ラベルなしデータ”を使って、事前学習をした結果ですが、それらの場合、18.6%、16.7%と20.3%から大幅に精度が改善しています。
Amazon reviewsデータセットはIMDBデータセットよりも大きなデータセットになっています。したがって、ここからわかることは、Rotten Tomatoesデータセットは短い文章が中心なので、LSTMの学習はそれほど難しくなく、同じデータセットを使って事前学習をしても大きな精度改善には至りませんが、新たな大量のラベルなしデータで事前学習をさせ、言語モデルを学習することで、精度を改善することが可能だということです。
まとめ
今回は、いきなり教師あり学習をするのではなく、大量の教師なしデータを使った事前学習から教師ありデータで対象となるタスクにファインチューニングするというステップを踏むことで、モデルが安定し、精度が大幅に改善することがわかりました。
初めにも言いましたが、この事前学習 - ファインチューニングという学習方法は、現在の主流となっているGPTやBERTなどの高精度なモデルを生み出すきっかけとなっています。
GPTやBERTは、事前学習-ファインチューニングという考え方に、Transformerという柔軟性が高いモデルとより大きな事前学習データを組み合わせることにより自然言語処理界でブレイクスルーをもたらしたモデルです。
非常に重要な仕組みなので是非この考え方を頭に入れたうえで、GPTやBERTを学んでいただければと思います。
また、この論文では他のデータセットを使った結果も紹介されていますので、興味のある方は是非目を通してみてください。
こちらの記事では実際に、事前学習-ファインチューニングを実装し、簡単なLSTMモデルで実験しています。

では!