今回は、BERTの仕組みはそのままで、ハイパーパラメータの調整や学習用のデータ量を増やすことによって、BERTの精度を大幅に上回ることに成功したRoBERTa(Robustly optimized BERT approach)の論文を解説したいと思います。
目次
RoBERTaとは
RoBERTaのアイデアを簡単に言うと、“BERTはその持っている力を使いきっておらず、もっとうまく、 もっとたくさん学習すればもっと賢くなる”、ということです。
ということで、RoBERTaのBERTと違う設定をざっくりまとめると以下です。
- もっとたくさん学習
・事前学習用データセットを大幅に増やした
・事前学習の回数を増やした - もっとうまく学習
・バッチサイズを大きくした
・Next Sentence Prediction(NSP)を使用しない
・BERTは短い文章を多く投入していたが、RoBERTaでは長い文章を投入
・BERTは事前学習前に文章にマスクを行い、同じマスクされた文章を何度か繰り返していたが、RoBERTaでは、毎回ランダムにマスキングを行う
これにより、BERTの精度を大きく上回り、当時SoTAだったXLNetも上回っています(ただし、その後XLNetもRoBERTaを参考に同じ設定で学習したところ、RoBERTaを上回っています)。
特に、事前学習用データセットを大幅に増やす効果や手法は今後も非常に活発に研究されることになる重要なポイントです。
BERTについてよくわからない方は、先にBERTを理解しておいた方が良いと思いますので、以下の記事をご参照ください。

では、論文に沿って見ていきましょう。
論文はこちらです。
『RoBERTa: A Robustly Optimized BERT Pretraining Approach』
事前学習の設定
RoBERTaの論文では、BERTの設定を色々変えて、比較しています。
ひとつずつ見てみましょう。
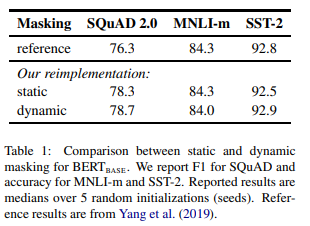
マスク - Static vs. Dynamic
BERTの実装では、最初の時点で文章にマスクをしています。
一つの文章を10個作り、それぞれ違うマスキングをすることにより、10種類のマスクされた文章を作成しています。
そして、40エポック回しているので、同じマスクは4回出てきています。
RoBERTaでは、dynamic maskingとして、学習する度にマスクをするようにします。
つまり、毎回違うマスクになるということです。
その結果、データセットにより違いますが、BERTとほぼ同等もしくは若干良い精度となっています。
Model Input Format and Next Sentence Prediction
次に、Next Sentence Predictionについてです。
BERTでは、2つのセグメントをインプットとしていました。セグメントは複数の文章のまとまりのことです。
2つ目のセグメントは、50%の確率で1つ目と同じドキュメントから持ってきたセグメントで、50%の確率で違うドキュメントから持ってきたセグメントです。
そして、2つ目のセグメントが1つ目のセグ円との続きかどうかを予測するNext Sentence Prediction(NSP)というタスクを事前学習で使うことにより、セグメント間の関連性を学習させていました。
本論文では、そのNSPの有効性について検証しています。具体的には、以下の4パターンで精度を比較しています。
- SEGMENT-PAIR + NSP
BERTの手法です。セグメントのペアをインプットとして、NSPを行います。
2つ合わせて最大512単語です。 - SENTENCE-PAIR + NSP
文章(1文)のペアをインプットとして、NSPを行います。
1文のペアなので512単語よりは短くなるため、その分バッチサイズを増やします。 - FULL-SENTENCES
一つ以上のドキュメントから連続した512単語をインプットとします。
1つのドキュメントが512単語以下の場合は、違うドキュメントの最初からサンプリングします。 - DOC-SENTENCES
FULL-SENTENCESと似ていますが、ドキュメントをまたぎません。
通常、512単語より短いので、FULL-SENTENCESと同水準の単語数になるようにバッチサイズをダイナミックに増やします。
結果は、下表です。MNLIデータセット、SST-2データセット、RACEデータセットで比較しています。
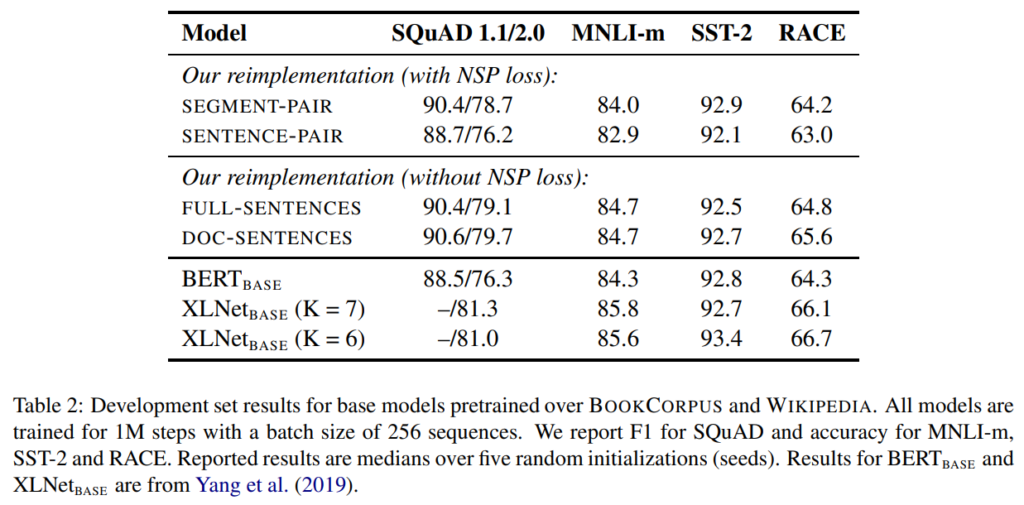
まず1行目がBERTと同じ設定ですが、2行目のSENTENCE-PAIR、つまり1文のペアをインプットにすると精度が悪化しています。
これは長期の依存関係を捉えることができなくなるからだと考えられます。
また、3、4行目はNSPを行わない場合ですが、BERTの設定である1行目のSEGMENT-PAIRとほぼ同じか、若干上昇しています。
つまり、NSPは効果がないという結論になります。
3行目のFULL-SENTENCESと4行目のDOC-SENTENCESでは、若干DOC-SENTENCESの方が良くなっています。
ただし、バッチサイズをダイナミックに変えないといけないため、比較しやすいFULL-SENTENCESを使うとのことです。
バッチサイズ
次はバッチサイズです。BERTのバッチサイズは256でしたが、非常に大きいバッチサイズで学習すると精度が向上するという結果があるので、それを試しています。
BERTでは、バッチサイズ256の100万ステップでしたが、ここでは、バッチサイズを上げた以下のパターンと比較しています(学習する文章数は揃えてあります)。
- バッチサイズ2,000で12万5000ステップ
- バッチサイズ8,000で3万1000ステップ
結果はこちらです。
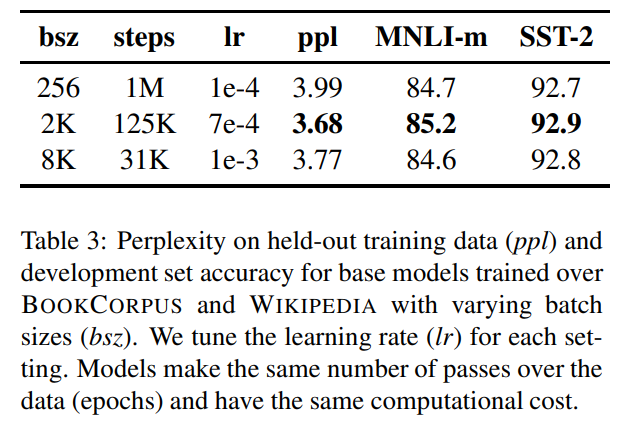
パープレキシティ、MNLIデータセット、SST-2データセットのすべてにおいて2行目のバッチサイズ2,000の12万5000ステップの場合が一番良いという結果になりました。
つまり、言語モデルそのものも、その後の下流タスクにおいても、大きなバッチサイズの方が精度が良いということがわかりました。
Text Encoding
最後にテキストのエンコーディング方法です。
BERTではByte-Pair Encoding(BPE)という手法を使って単語を作成しています。
BPEは、単語よりも区切りをもう少し細かくして、文字レベルの区切りも使います。
ざっくり言うと、まず単語に分割し、出現頻度が高いものは単語のままで、出現頻度が低いものは文字単位に置き換えることにより、未知語をなくそうというものです。
例えば、“lower”や“lowest”は、“low”と“er”に、“low”と“est”という分割を行って、ボキャブラリーとして保持するものです。
Byte-Pair Encodingとは言っても、実際はバイト単位ではなく文字(unicode)単位の分割になっています。
それをこの論文では、本当のバイト単位に分割した場合と比較を行っています。
- BERTと同じ文字単位のBPEを使ったボキャブラリー数3万語
- バイト単位のBPEを使ったボキャブラリー数5万語
結果は、バイト単位のBPEの方が若干悪化したとのことです。ただし、こちらの設定の方が幅広く使えるので、今後の実験ではバイト単位のBPEを使っているようです。
事前学習
これまで、マスキング方法、NSP、バッチサイズ、テキスト・エンコーディングについて、BERTと方法を変え、比較してきました。その結果、以下の設定を使って、今後の検証を行います。
- ダイナミック・マスキングをする
- NSPを行わない。ドキュメントをまたぐFULL-SENTENCESを使う
- ミニバッチのサイズを2,000にする
- バイト単位のBPEを使う
そして、以下の2点を検証します。
- 事前学習データを増やす
- 学習回数を増やす
なお、RoBERTaのハイパーパラメータは\(\text{BERT}_\text{LARGE}\)と同じ、Transformer block数24、隠れ層の数1,024、attention head数16の355Mパラメータとしています。
事前学習データ
BERTでは、事前学習用のデータセットとして、以下の2つ合計16GBのデータセットを使いました。
- English Wikipedia(2,500M単語)
- BooksCorpus(800M単語)
RoBERTaでは、さらに以下のデータセットを追加し、合計ではBERTの10倍の160GBを超えるデータセットを事前学習に使いました。
- CC-News(76GB)
- OpenWebText(38GB)
- Stories(31GB)
このたくさん事前学習する、というのは今後にもつながる非常に大きなポイントです。
学習回数
RoBERTaでは、ステップ数を10万ステップから30万ステップ、50万ステップに増やしています。
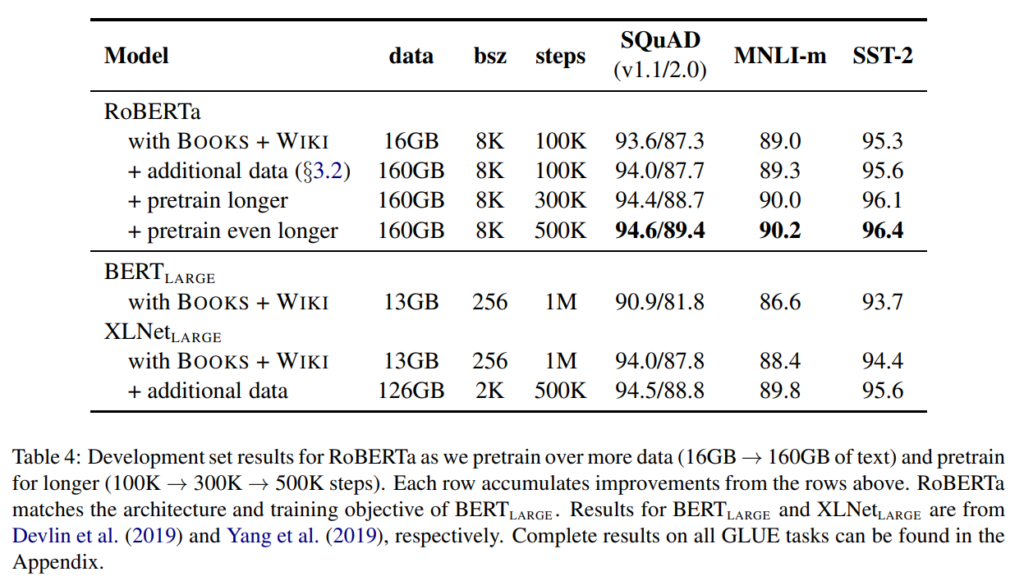
では、結果です。
まず、SQuAD、MNLI、SST-2データセットのすべてにおいて、RoBERTaのデータを増やす前の状態(1行目)で、BERTよりも精度が大きく改善しています。
そして、データを増やすことと事前学習のステップ数を増やすことで、さらに精度が向上し、XLNetの精度を超えています(その後XLNetもRoBERTを参考にして、さらにRoBERTaの結果を超えています)。
では、ここからは、RoBERTaの設定でデータ量を増やし、事前学習を長く行った場合で評価していきます。
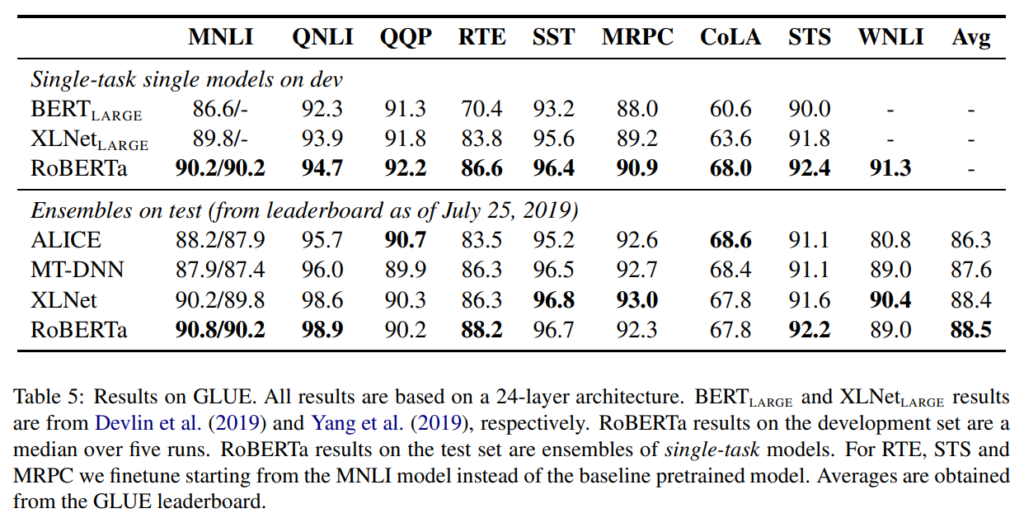
まずGLUEデータセットの結果を見てみます。
上の“Single-task on single models on dev”というのは、アンサンブルはせずに、ファインチューニング時のハイパーパラメータをdevセットを使って決め、そのdevセットの結果です。
いずれのタスクでも精度が向上しており、XLNetを上回っています。
下の“Ensembles on test”のALICEやMT-DNN等はGLUE leaderboardのテストセットの数字です。
5つのタスクでSoTAを達成しています。RoBERTaの結果は個別のタスクごとにファインチューニングしたものであり、Multi-task learningは使っていません。
ですので、うまくMulti-task learningをすることにより、さらに精度向上が見込めると思います。
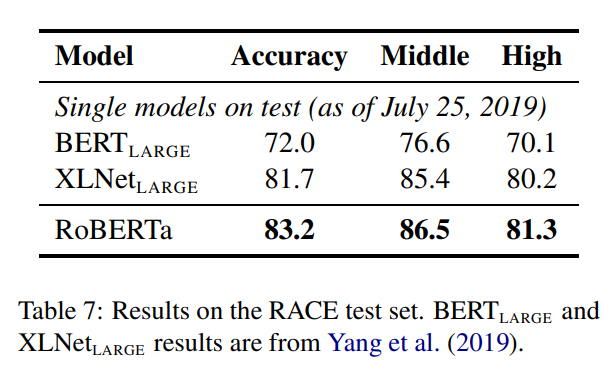
続いて、RACEの結果を見てみましょう。middle school、high schoolともにXLNetを超えています。
まとめ
今回はBERTの仕組みのまま、それ以外の設定等を調整することでSoTAを達成したRoBERTaを見てみました。事前学習のデータ量を多くする、事前学習を長くする、つまりたくさん学習することで中学生・高校生向けのテストの結果が改善したという結果はわかりやすいですね。
この“事前学習のデータ量を多くする”ことによる効果や事前学習の方法は、この後も活発に研究されていきます。