さて、今回は2015年に提案されたDCGAN(Deep Convolutinoal Generative Adversarial Networks)について解説していきたいと思います。
DCGANは学習が難しいとされていた畳み込み層を積み重ねたGANに、細かな工夫をすることで、幅広いデータセットでうまく学習ができるようにしたものです。
論文は以下になります。
『Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks』
実際に実装したり、実装を見た方がわかりやすいので、はじめにDCGANの仕組みをざっと解説して、PyTorchで実装していきたいと思います。
GANの概要
GANはもともと2014年にIan Goodfellowらによって論文「Generative Adversarial Networks」で提案された画像の生成モデルです。
一般的な仕組みは、ノイズ・ベクトルを与え、そのノイズ・ベクトルからGeneratorが画像を生成し、Discriminatorが本物か生成された画像かを判定することで学習します。
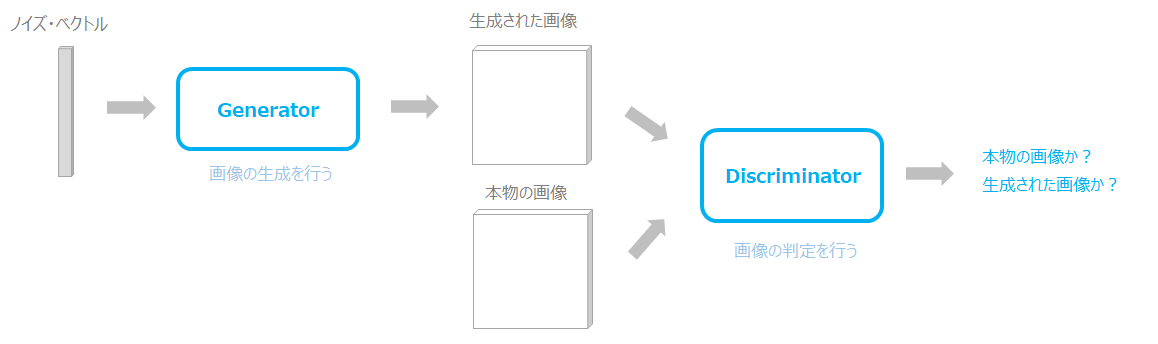
DiscriminatorがGeneratorが生成した画像と本物の画像を見分けられればDiscriminatorは優秀ということになりますし、見分けられなければGeneratorが優秀ということになります。
これをGeneratorとDiscriminatorが同じように学習していくことで、Generatorは良い画像の生成器に、Discriminatorは良い分類器になると考えられます。
DCGANの概要
より複雑な画像をきれいに生成するために、層を積み重ねたCNN(Convolutional Neural Network)を使いたいと考えます。
しかしながら、そこには学習が難しく安定しないという問題がありました。
そこでDCGANでは様々なパターンの設定を試し、幅広いデータセットで安定して学習する方法を見つけたというものです。
DCGANの仕組みで工夫を特徴的な仕組みは論文にもある通り以下の5点です。
- プーリング層を使わず、代わりにストライドを利用した畳み込みを行う。
- generator、discriminatorの両方に(2015年に提案された)バッチ正規化を使用する。
- 全結合層を使わない。
- generatorの活性化関数にReLUを使用する。ただし、最後のアウトプット層はTanhを使用する。
- discriminatorの活性化関数にLeakyReLUを使用する。
バッチ正規化は今では当たり前のように使われていますが、当時はまだ世に出たばかりという状況でしたので、このような細かい技術の積み重ねによって発展していることがわかりますね。
詳細は実装のところで見ていきたいと思います。
Generatorの構造
DCGANのgeneratorの構造は以下の通りです。
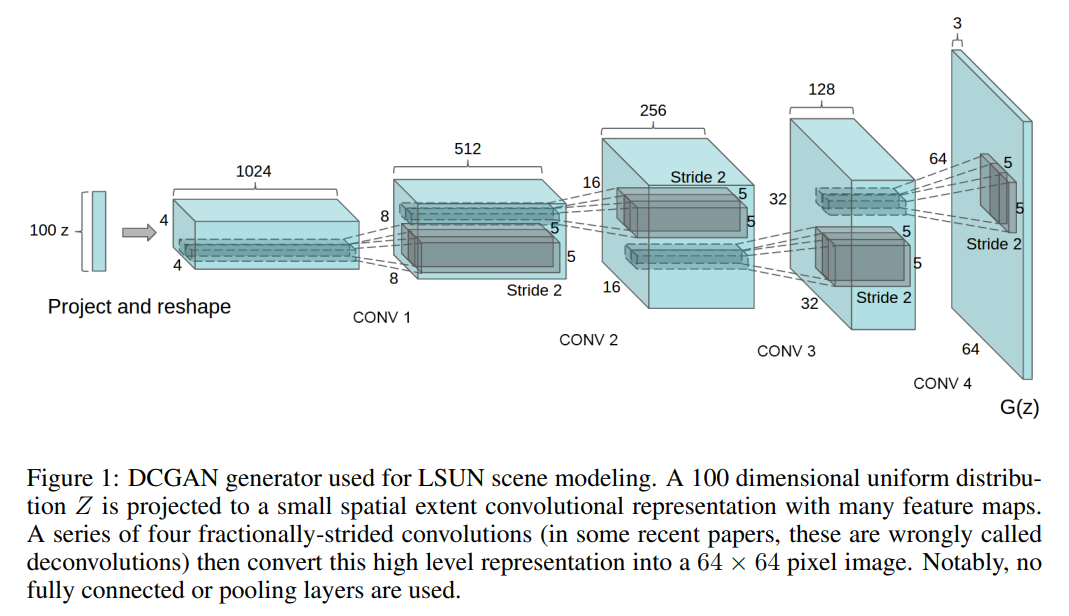
画像を生成するためのノイズが100x1のベクトルで与えられ、それを転置畳み込み層(Transposed Convolutinoal layer)を使って4x4x1024にします。
転置畳み込み層は画像を大きくしていくための畳み込み処理になります。
転置畳み込み演算についてはこちらの記事をご参照ください。

そして、転置畳み込みを続けてチャネル数を1024から3へとだんだん小さくし、画像のサイズを4x4から64x64へと大きくしていきます。
最終的にできた64x64x3が生成された画像になります。
Dsicriminatorについては通常の畳み込み層(Convolutional layer)を使って処理をします。
実装の前に
実装する前に、本記事作成に参考にしたものを紹介しておきます。
『Cousera - Generative Adversarial Networks(GANs)講座』
簡単ではありませんが、非常に分かりやすく専門的です。
英語ですが、手っ取り早く、しかもしっかりと学びたい方にはオススメです。

『つくりながら学ぶ!PyTorchによる発展ディープラーニング』
PyTorchを使って色々なモデルを実装していきます。説明もかなりわかりやすいです。
GAN以外にも画像認識やTransformer、BERTなどの自然言語処理分野もありますので非常にオススメです。
『PyTorch実践入門 (Compass Booksシリーズ)』
こちらはGANというよりはPyTorchの解説本です。
細かいところから説明してくれているので、非常に参考になります。
実装
では、ここからは実際に手書き数字の画像データセットであるMNISTを使用し、実際に実装をすることでDCGANがどのようなものか見ていきたいと思います。
実装では論文の設定よりも少し小さいサイズにして実装します。
まずは、使用するパッケージをインポートします。
import torch from torch import nn from tqdm.auto import tqdm from torchvision import transforms from torchvision.datasets import MNIST from torchvision.utils import make_grid from torch.utils.data import DataLoader import matplotlib.pyplot as plt
あと、表示用の関数を作成しておきます。横を5列にして表示する単純な関数です。
def show_tensor_images(image_flattened, num_images=25, size=(1, 28, 28)): image = image_flattened.detach().cpu().view(-1, *size) # 画像のサイズ1x28x28に戻す image_grid = make_grid(image[:num_images], nrow=5) # 画像を並べる plt.imshow(image_grid.permute(1, 2, 0).squeeze()) # 画像の表示 plt.show()
Generator
まず、画像を生成するGeneratorを作成していきます。
今回実装するGeneratorの全体像はこちらです。
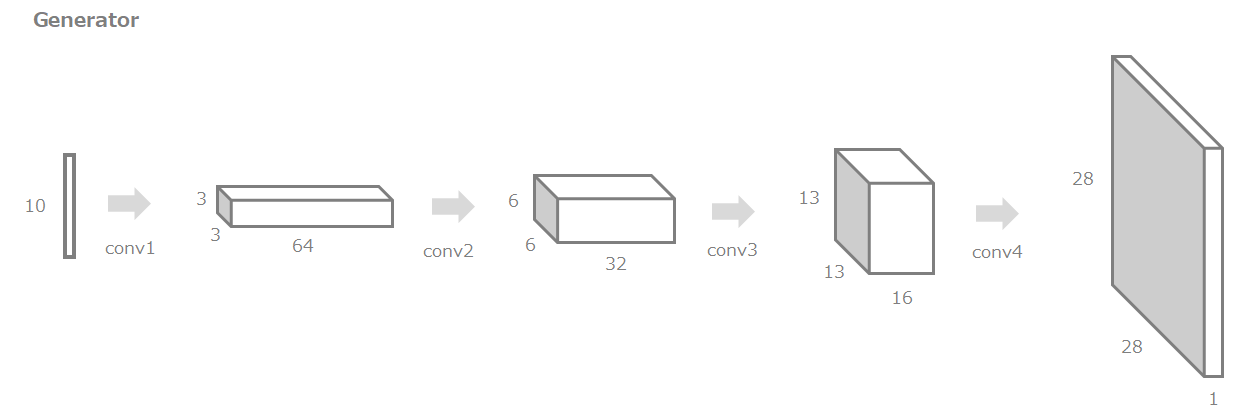
10次元のノイズベクトルから最終的に28x28x1の数字画像を生成します。
Generatorは4つのGeneratorブロック(conv1~conv4)から構成されるものとし、まずはGeneratorブロックを作成していきます。
Generatorブロックは基本的に“転置畳み込み→バッチ正規化→ReLU”で構成されます。
ただし、最後のブロックについてはバッチ正規化は使わず、“転置畳み込み→Tanh関数”で構成されます。
- バッチ正規化を使用。
- プーリング処理は使わず、ストライドを使った畳み込みを利用する。
- 活性化関数にReLUを使う。最後の層はTanhを使う。
class GeneratorBlock(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size=3, stride=2,
final_layer=False):
super(GeneratorBlock, self).__init__()
if not final_layer:
self.generator_block = nn.Sequential(
nn.ConvTranspose2d(input_channels, output_channels, kernel_size, stride),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True))
else:
self.generator_block = nn.Sequential(
nn.ConvTranspose2d(input_channels, output_channels,
kernel_size, stride),
nn.Tanh())
def forward(self, x):
return self.generator_block(x)
続いて、Generator本体を作成します。
前述の通りGeneratorは4つのGeneratorブロックから構成されます。
最初にチャネル数を設定した値に増やし、そこから半分、半分として、最後に画像のチャネル数(RGBであれば3、白黒であれば1)に合わせます。
class Generator(nn.Module):
def __init__(self, z_dim=10, image_dim=1, hidden_dim=128):
super(Generator, self).__init__()
self.z_dim = z_dim
self.generator = nn.Sequential(GeneratorBlock(z_dim, hidden_dim * 4),
GeneratorBlock(hidden_dim * 4, hidden_dim * 2,
kernel_size=4, stride=1),
GeneratorBlock(hidden_dim * 2, hidden_dim),
GeneratorBlock(hidden_dim, image_dim,
kernel_size=4, final_layer=True))
def forward(self, noise):
noise_reshaped = noise.view(len(noise), self.z_dim, 1, 1)
return self.generator(noise_reshaped)
def get_generator(self):
return self.generator
ハイライトしている12行目はN(バッチ数)×z_dimをN×z_dim×1×1に変換しています。
あと入力用にノイズを生成する関数を作っておきます。
def get_noise(n_samples, z_dim, device='cuda'): return torch.randn(n_samples, z_dim, device=device)
Discriminator
続いてDiscriminatorです。
今回実装するDiscriminatorの全体像は以下です。
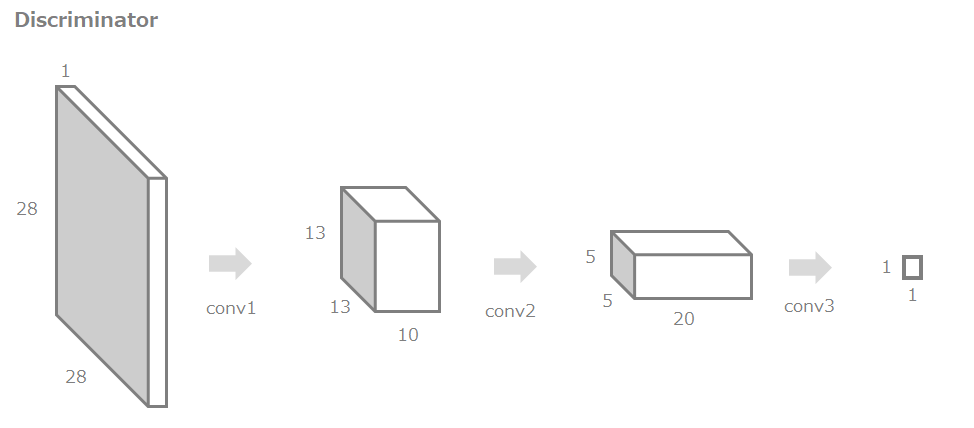
28x28x1の画像をインプットとして、通常の畳み込み処理で1x1にし、これを本物か生成された画像かの判定に使用します。
DiscriminatorもGeneratorと同様に、複数のDiscriminatorブロックから構成されるものとします。
各Discriminatorブロックは、畳み込み→バッチ正規化→LeakyReLUで構成されます。
LeakyReLUを使うところがDCGANのポイントですね。
(ちなみに、DCGAN以外ではあまり使われておらず、ReLUや自然言語処理ではGeLUなどが多い印象です)
最後のレイヤは、バッチ正規化は使わず、また全結合層も使わず畳み込み層のみで、1×1のアウトプットにします。
- バッチ正規化を使用。
- プーリング処理は使わず、ストライドを使った畳み込みを利用する。
- 活性化関数にLeakyReLUを使う。
- 全結合層を使用しない。
class DiscriminatorBlock(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size=4, stride=2, final_layer=False):
super(DiscriminatorBlock, self).__init__()
if not final_layer:
self.discriminator_block = nn.Sequential(nn.Conv2d(input_channels, output_channels,
kernel_size, stride),
nn.BatchNorm2d(output_channels),
nn.LeakyReLU(negative_slope=0.2,
inplace=True))
else:
self.discriminator_block = nn.Sequential(nn.Conv2d(input_channels, output_channels,
kernel_size, stride))
def forward(self, x):
return self.discriminator_block(x)
続いて、Discriminator本体を作成します。
class Discriminator(nn.Module):
def __init__(self, image_channels, hidden_channels):
super(Discriminator, self).__init__()
self.discriminator = nn.Sequential(DiscriminatorBlock(image_channels, hidden_channels),
DiscriminatorBlock(hidden_channles, hidden_channels * 2),
DiscriminatorBlock(hidden_channels * 2, 1,
final_layer=True))
def forward(self, input_images):
prediction = self.discriminator(input_images)
return prediction.view(len(prediction), -1)
Training
では、学習部分を実装していきましょう。
ハイパーパラメータの設定
各種ハイパーパラメータの設定をしておきます。
z_dim = 64 batch_size = 128 learning_rate = 0.0002 beta_1 = 0.5 beta_2 = 0.999 num_of_epochs = 25 device = 'cuda'
データの作成
データを読み込んで、データローダーを作成します。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))])
dataloader = DataLoader(
MNIST('.', download=True, transform=transform),
batch_size=batch_size,
shuffle=True
)
transforms.Normalize()では、元の値が0から1までの範囲を取るので、平均を0.5、標準偏差を0.5として
$$\frac{x - 0.5}{0.5}$$
という式で、値の範囲を-1から+1までに変換しています。
モデルの設定
続いて、Generator、Discriminatorのインスタンス化、オプティマイザの設定をします。
image_channels = 1 hidden_channles = 16 # インスタンス化 generator = Generator(z_dim).to(device) discriminator = Discriminator(image_channels=image_channels, hidden_channels=hidden_channles).to(device) # オプティマイザ gen_opt = torch.optim.Adam(generator.parameters(), lr=learning_rate, betas=(beta_1, beta_2)) disc_opt = torch.optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(beta_1, beta_2))
そして、ウェイトの初期化を行います。
# ウェイトの初期化
def weights_init(m):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
torch.nn.init.constant_(m.bias, 0)
generator = generator.apply(weights_init)
discriminator = discriminator.apply(weights_init)
損失関数
損失関数はDCGANに限らずGANの一般的な話になりますが、少し詳しく説明します。
ここでは本物の画像のラベルを1、偽物の画像のラベルを0とします。
まず、DiscriminatorはGeneratorが生成した画像と本物の画像の2つを判定し学習します。
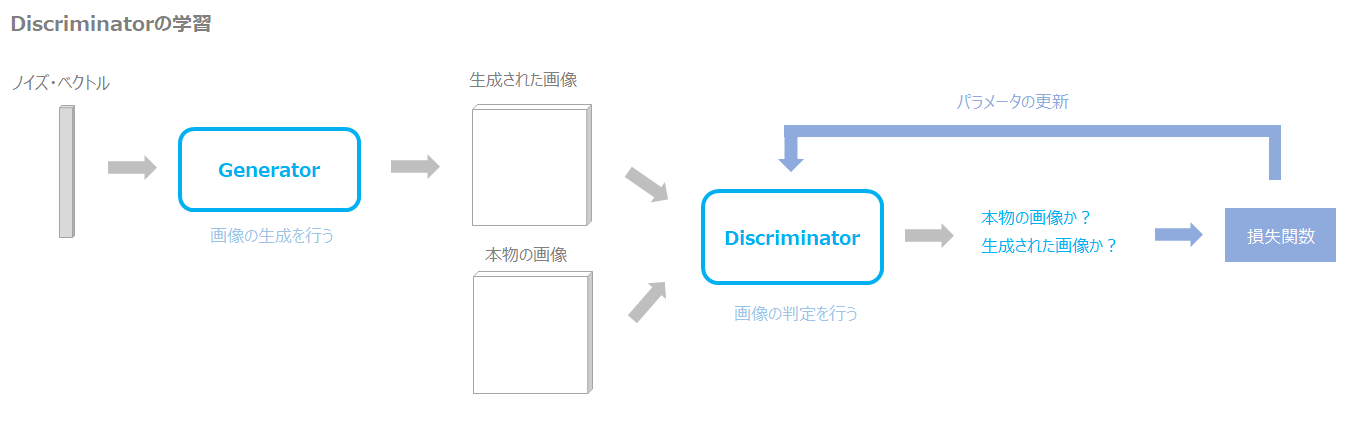
Generatorが生成した画像には偽物の画像と判定し(ラベル0)、本物の画像には本物の画像と判定する(ラベル1)ようにします。
その分類を間違えると損失が大きくなるようにします。
通常のCross-entropy誤差を使い、生成された画像に対する損失と本物の画像に対する損失の平均をDiscriminatorの損失とします。
続いてGeneratorの学習です。
Generatorについては本物の画像は使用しません。
あくまでGeneratorが生成した画像についてDiscriminatorがどう判定するか、だけを考えます。

Discriminatorが本物の画像と判定すれば損失が小さく、偽物の画像と判定すれば損失が大きくなるようにします。
これはつまり、Discriminatorの損失の逆になるとも考えられます。
ですので、GeneratorもDiscriminatorの予測結果にBinary Cross-entropy誤差を使用しますが、与える正解ラベルは本物のラベルである1を与えます(つまり、Discriminatorが間違えて本物と判定すると損失が小さくなります)。
そして、DiscriminatorとGeneratorの損失の平均をGAN全体の損失とします。
では、いったん損失関数にBinary Cross-entropy誤差を設定します。
criterion = nn.BCEWithLogitsLoss()
学習
では、実際に学習していきましょう。
for epoch in range(num_of_epochs):
mean_generator_loss = 0
mean_discriminator_loss = 0
for real_images, _ in tqdm(dataloader):
real_images = real_images.to(device)
# discriminator
disc_opt.zero_grad() # 勾配の初期化
# 偽画像
noise = get_noise(len(real_images), z_dim, device=device) # ノイズの生成
fake_images = generator(noise) # 偽画像を生成
disc_fake_prediction = discriminator(fake_images.detach()) # Discriminatorで予測
correct_labels = torch.zeros_like(disc_fake_prediction) # 偽画像の正解ラベルは0
disc_fake_loss = criterion(disc_fake_prediction, correct_labels) # 偽画像に対する損失を計算
# 本物の画像
disc_real_prediction = discriminator(real_images) # Discriminatorで予測
correct_labels = torch.ones_like(disc_real_prediction) # 本物の画像の正解ラベルは1
disc_real_loss = criterion(disc_real_prediction, correct_labels) # 本物の画像に対する損失を計算
# 最終的な損失
disc_loss = (disc_fake_loss + disc_real_loss) / 2
disc_loss.backward()
disc_opt.step()
# エポックごとの損失
mean_discriminator_loss += disc_loss / len(real_images)
# generator
gen_opt.zero_grad() # 勾配の初期化
fake_noise = get_noise(len(real_images), z_dim, device=device) # ノイズの生成
fake_images = generator(fake_noise) # 偽画像の生成
disc_fake_prediction = discriminator(fake_images) # Discriminatorで予測
correct_labels = torch.ones_like(disc_fake_prediction) # 本物の正解ラベルは1
gen_loss = criterion(disc_fake_prediction, correct_labels) # 損失を計算
gen_loss.backward()
gen_opt.step()
# エポックごとの損失
mean_generator_loss += gen_loss / len(real_images)
print(f'Generator loss: {mean_generator_loss}')
print(f'Discriminator loss: {mean_discriminator_loss}')
# 生成される画像を表示
noise = get_noise(len(real_images), z_dim, device=device)
show_tensor_images(generator(noise))
ポイントはGeneratorの誤差を計算する際に、
correct_labels = torch.ones_like(disc_fake_prediction) gen_loss = criterion(disc_fake_prediction, correct_labels)
としているところです。
Generatorの生成した画像に対する正解ラベルは、Discriminatorにとっては偽物を表す0ですが、Discriminatorにとっては本物を表す1になります。
では、結果を見てみましょう。
最初はGenerator以下のような数字に見えない画像が生成されています。

これが次のエポックでは少し数字に見えてきていますね。

最終的に25エポック目では以下のような画像になります。
左が生成された画像で右が本物の画像です。

まだある程度見分けがつきそうですが、画像によっては見分けがつかないものもありますね。
まとめ
今回はGANの基礎となるDCGANを見てきました。
DCGANは非常に成功しましたが、それでもGANにはGeneratorがDiscriminatorをだますために同じような画像ばかりを生成するmode collapse(モード崩壊)などが見られます。
その後、損失関数を工夫したりすることでそういった現象を克服していき、今では非常に高精度の画像が生成されるようになっています。
今後は、より新しいモデルについてもご紹介していきたいと思います。
上でも紹介しましたが、以下の書籍はPyTorch、Deep Learningの基礎を学ぶ上で非常にオススメです。
では!