今回は OpenAI が提案する OpenAI 「GPT」を解説したいと思います。
なお、現在ではGPT2、GPT3、GPT4 とどんどん発展していますので、そちらが気になる方は以下の記事をご参照ください。



ただし、GPT2、GPT3 の仕組みは、ほとんどこの「GPT」と同じですので、上記の記事ではモデルに関しては変更点しか解説していません。
ですので、仕組みを知りたいという方は、まずこの GPT の記事を読んでいただき、そのあとに上記の記事でどこが違うかを理解していただくのが良いかと思います。
では、GPT を見ていきましょう。
論文はこちらです。
『Improving Language Understanding by Generative Pre-Training』
目次
OpenAI GPTとは
GPT は OpenAI から2018年に以下の論文で提案されたモデルで、基本的には Transformer という仕組みをベースに、事前学習-ファインチューニングをすることで非常に高い精度を達成したモデルです。
特に文章生成で非常に良好な結果を残しています。
GPT はモデルに Transformer を使う
ラベルなしデータで言語モデルの事前学習、それをラベル付きデータで言語モデルのファインチューニングと教師あり学習による分類器等のファインチューニングを同時に行う
GPT の仕組みをしっかりと理解するには Transformer をしっかりと理解していた方が良いと思いますので、Transformer がよくわからないという方は以下の Transformer の記事を読んでいただければと思います。(逆に Transformer がわかっていれば GPT もあまり難しくありません)

また、事前学習 - ファインチューニングというステップについて参考になるのは以下の ULMFiT です。

ULMFiT が文書分類に特化していたのに対し、GPT では Question Answering などでも良好な結果を残しています。
GPTの仕組み
では、GPT の仕組みについて説明していきます。
繰り返しになりますが、GPTの大きな特徴は以下です。
モデルに Transformer を使う
ラベルなしデータで言語モデルの事前学習、それをラベル付きデータで言語モデルのファインチューニングと教師あり学習による分類器等のファインチューニングを同時に行う
では、これらを詳しく見ていきたいと思います。
Transformer
Transformer とは Google から提案された、文章などの時系列データを効率良く処理する仕組みです。
Transformer 以前に主流だった LSTM (Long Short-Term Memory) といったモデルは、1語1語前から順番に処理を行うため、同時計算ができず計算時間がかかってしまうという問題がありました。
そこで、Transformer はその欠点を改善すべく、すべての入力単語を同時に処理できるようにしたものになります。
具体的な仕組みですが、GPT で採用している Transformer も以下のような仕組みで、オリジナルの Transformer とそれほど変わりません。
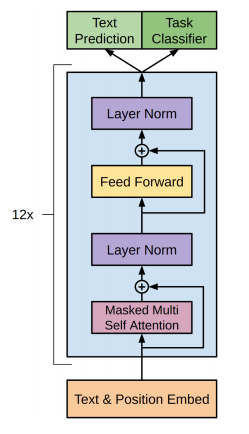
(以下は Transformer を理解している必要がありますので、まだの方はスキップしていただいても構いません)
まずは、単語の位置情報を表す Positional Encoding です。
もとの Transformer と同じで、単語の埋め込み表現に位置情報を足します。
$$\begin{align}
h_0 = UW_e + W_p
\end{align}$$
\(W_e\)が単語の埋め込み表現の行列、\(W_p\)が位置情報を埋め込む行列です。
ただし、GPTでは、\(W_p\) はオリジナルの Transformer の論文のように \(\sin\)・\(\cos\) を使った方法ではなく、\(W_p\) もデータから学習します。
次のレイヤーですが、Transformer と言っても、ここでは encoder-decoder を使った Transformer ではなく、decoder のみのいわゆるTransformer block を使います。
つまり、
$$h_l=\text{transformer_block}\left(h_{l-1}\right)$$
だけになります。
\(l=(1,\cdots, n)\)です。そして、softmaxレイヤーで求めます。
$$P(u)=\text{softmax}\left(h_nW_e^T\right)$$
Pretraining, Fine-tuning
Pretraining (事前学習)
まずは言語モデルの事前学習についてです。(事前学習の概念は非常に重要です)
言語モデルの事前学習とは、単語の意味や文法など一般的な言語の構造を理解することになります。
解きたいタスクの教師データとは違い、事前学習で必要なデータは単なる文章のかたまりですので、Web サイトなどから簡単にたくさん手に入れることができます。
具体的にどうやって言語の一般的な構造を学習するかというと、直前の \(k\) 個の単語を使って次の単語を予測できるように学習します。
数学的に言うと、以下のように対数尤度を最大化させるように次の単語を求めます。
\(\mathcal{U}\) はラベルなしデータを意味します。
$$L_1\left(\mathcal{U}\right)=\sum_i \log P\left(u_i| u_{i-k}, \cdots, u_{i-1}; \Theta\right)$$
この学習データ量を増やすことで、言語を習得していくような感じですね。
Fine-tuning (ファインチューニング)
次に言語モデルのファインチューニングと分類器のファインチューニングを行います。
ファインチューニングとは、センチメントの予測などの解きたいタスクをその教師データを使って解けるように学習することです。
ULMFiT では事前学習 - ファインチューニングを順番に行っていましたが、GPT では同時に行います。
つまり、一般的な言語の構造を理解しながら、文章のセンチメント予測などの解きたいタスクの答え方も同時に学んでいきます。
両方ともラベル付きデータを使って行います。
ラベル付きデータの入力単語を \(x_1, \cdots, x_m\) とすると、ラベル \(y\) の予測は最後の transformer block の最後の時点の出力 \(h_l^m\) のベクトルを使って softmax レイヤーにより求めます。
$$P\left(y|x^1, \cdots, x^m\right)=\text{softmax}\left(h_l^m W_y\right)$$
そして、ラベル付きデータを\(\mathcal{C}\)とすると、対数尤度
$$L_2\left(\mathcal{C}\right)=\sum_{(x, y)}\log P\left(y|x^1, \cdots, x^m\right)$$
が最大になるようにパラメータを調整します。
さらに、単純に \(L_2\) を最大化させるのではなく、同時に言語モデルのファインチューニングを行います。
その尤度を \(L_3\) とすると、
$$L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda*L_1(\mathcal{C})$$
を最大化するように、言語モデルと分類器のファインチューニングを同時に行います。
\(L_1(\mathcal{C})\) は ラベル付きコーパスを使った言語モデル( Pretraining のところの式)の学習を意味しています。
この目的関数を auxiliary objective と呼んでいます。
ちなみに、GPT-2、GPT-3 になるとファインチューニングは行わなくなります。
インプット
さて、仕組みの部分は以上で終わりです。
あとは、これらをテキスト分類や textual entailment 、question answering など色々なタスクに適用できるようにインプットを調整します。
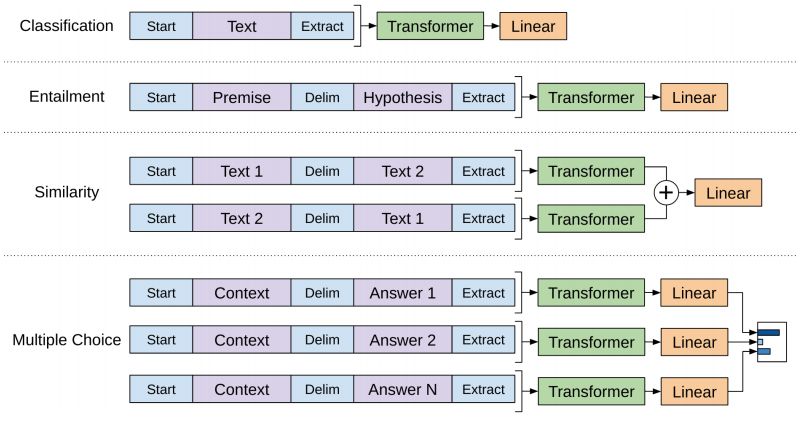
テキスト分類はシンプルです。
テキストの初めに Start トークンをテキストの終わりに Extract トークンを入れてあげます。
Extract トークンの位置にある最後の Transformer block の出力を分類に使います。
textual entailment は2つの文章の意味を読み取って、それらの関係を予測するので、Start トークン、Extract トークンに加えて、2つのテキストの間に Delimiter 用のトークンを追加します。
類似度を求めるタスクでは、1つ目のテキストと2つ目のテキストの順番は関係ありません。
ですので、1つ目のテキストの次に Delimeter 用のトークンを追加し、そのあとに2つ目のテキストをつなげたサンプルと、その逆にしたもをインプットとしたサンプルを2つ同時に作成します。
そして、2つの Transformer のアウトプットをくっつけて処理します。
question answering などのタスクで複数の答えがある場合も同様に、複数の Transformer を使って処理します。
こういった処理により、ELMo のようにタスクに特化した処理を少なくすることで、汎用性を高めています。
実験
論文では、BooksCorpu sデータセットを使って事前学習しています。
このコーパスは7,000を超える未発表の本からなっています。1B Word Benchmark というデータセットも使っています。
モデルのセッティング
12個の Transformer block をつなげていて、各 block の隠れ層の次元は768次元、multi-head attention の head 数は12個です。
position-wise feed-forward レイヤーの次元は3,072次元です。
オプティマイザーは Adam ですが、学習率の最大値を2.5e-4とし、ゼロから2,000 iteration まではその最大値まで増加し、それ以降は、cosine スケジュールにしたがって、ゼロに近づくようにします。
ミニバッチ数は64でエポック数は100、512単語をインプットとします。
単語は Bytepair Encoding というのを使っています。
ざっくり言うと、語彙数を減らすため、高頻度の単語は単語そのものを使い、低頻度の単語は文字単位などもう少し細かく分けるというものです。
Bytepair Encoding については、こちらが非常に参考になります。
https://qiita.com/taku910/items/7e52f1e58d0ea6e7859c
そして、残差結合、embedding レイヤー、attention レイヤーにドロップアウト率0.1のドロップアウトを適用し、ウェイト、バイアスにL2正則化を施しています。
活性化関数は以下の Gaussian Error Linear Unit(GELU) を使っています。
\(\Phi(\cdot)\) は標準正規分布の分布関数を表します。
$$\begin{align}
\text{GELU}(x)&=x\Phi(x)\\
&\sim0.5x\left(1+\tanh\left[\sqrt{2/\pi}\left(x+0.044715x^3\right)\right]\right)
\end{align}$$
ちなみに、ReLU が0以下の領域で傾きがゼロになるのに対して、GELU はゼロ以下でも一定の領域では傾きがゼロにならないように設計されています。
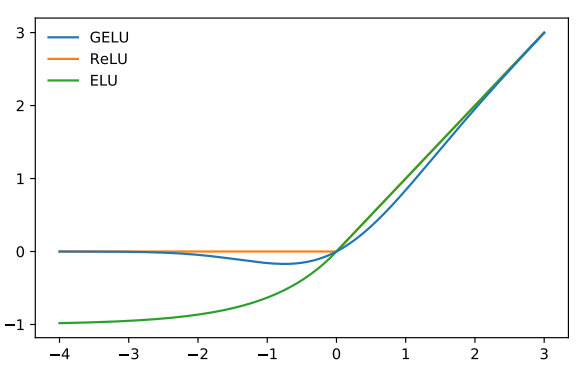
GELU については以下の投稿で少し詳しくみています。

ファインチューニングについては、ドロップアウト率0.1、学習率6.25e-5、バッチサイズ32としています。
これで3エポックぐらいで収束しているとのことです。
なお、\(\lambda\) は0.5です。
結果
では、結果をいくつか順に見てみましょう。
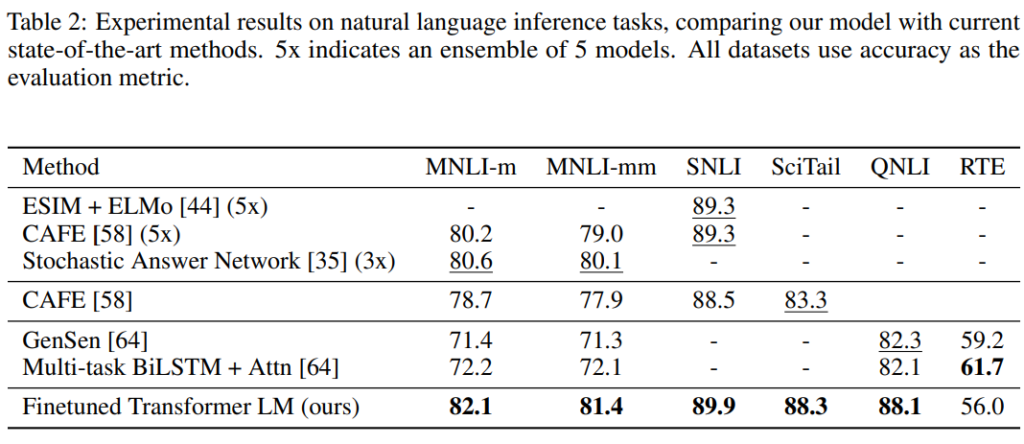
まず、textual entailment ですが、どのデータセットでも精度が上がっています。
1段目は複数モデルのアンサンブルなので単独モデルと比較すると大幅に精度が改善していることがわかります。
ただ、一番小さいRTEというデータセットは2,490サンプルしかなく、そのデータセットでは改善が見られていません。
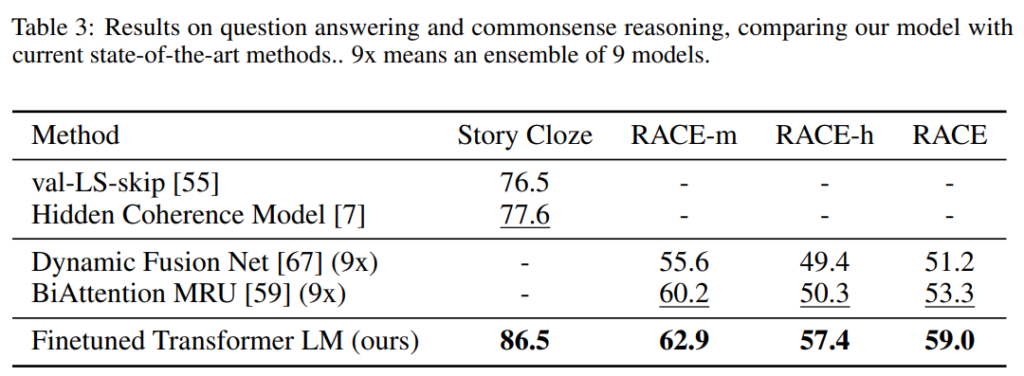
次に、Question Answering です。かなり精度が改善していますね。
RACE-m はミドル・スクール、RACE-h はハイ・スクールの英語の試験問題です。
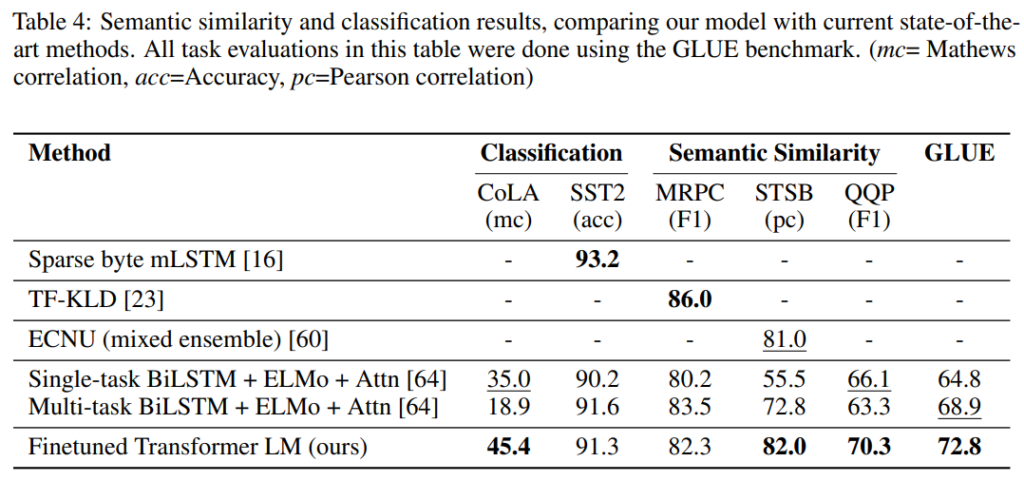
そして、 文書分類と Semantic similarity です。
Semantic similarity は、2つの文書が意味的に同じものかを判定します。このタスク3つのうち2つで SoTA を達成しています。
QQPデータセットでは ELMo の結果を大きく超えています。
まとめ
ということで、今回は OpenAI GPT の論文を読んでみました。
Transformer + ULMFiT という感じで、Transformer の扱いやすさと ULMFiT の事前学習+ファインチューニングという強力な手法の組み合わせで良好な結果を残しています。
そして、ここから GPT-2、GPT-3と改良されていくことになります。
さらにブレイクスルーとなった ChatGPT や GPT-4 では RLHF (人のフィードバックによる強化学習) という手法を使って、さらにユーザに寄り添った言語モデルへと進化しています。
GPT-2 以降はファインチューニングは念頭に置かず、ほぼ事前学習だけでタスクに対応する形になっています。
つまり、GPT からさらに巨大な(ラベルなしの)コーパスで事前学習を行うことで、各タスクにはその事前学習の知識だけでいきなり答える(Zero-shot)、もしくは数例だけを教えてもらいタスクに回答する(few-shot)ということを行います。
以下はGPT-2 の記事からの抜粋で、GPT-2 の特徴をまとめています。
特定のタスクに特化した教師あり学習は行わず、より大きな言語コーパスを使って、より大きなモデルの言語モデルを事前学習させることにより、zero-shot、もしくは few-shot のセッティングでも精度が出るような汎用的なモデルを目指しています。
- より大きなデータセット
GPT: BookCorpus データセット → GPT-2: Web をクローリングして作成した WebText (40GB)- より大きなモデル
GPT: 12レイヤーの1億17百万パラメータ → GPT-2: 48レイヤーの15億42百万パラメータ
GPT-2 が実際どのようなものかは以下の記事を読んでいただければと思います。

そして、さらにブレイクスルーとなった ChatGPT や GPT-4 では RLHF (人のフィードバックによる強化学習) という手法を使って、さらにユーザに寄り添った言語モデルへと進化しています。
GPT-4 についてはこちらの記事をご参照ください。
では、また会いましょう!!