さて、今回は以前ご紹介したOpenAI GPTの進化版OpenAI GPT2を解説したいと思います。
現時点ではすでにOpenAI GPT-3が開発されていますが、まずはOpenAI GPT-2を理解していきたいと思います。
『Language Models are Unsupervised Multitask Learners』
先にGPT-3を知りたい方はこちらの記事をご覧ください。

まず、GPT-2論文の背景を説明しておきます。
2018年以降、ULMFiT、ELMo、OpenAI GPT、BERTと大規模な言語コーパスを使って教師なし学習で事前学習を行い、そのあとに特定のタスクについて教師あり学習でファインチューニングする手法により、目覚ましい成果があげられています。
しかしながら、これらのモデルもまだ数千や数万といった教師ありデータでファインチューニングしなければなりません。
人間については、そんなに大量のデータで学習しなくても、少しの追加の学習や手引きがあればタスクを解くことができます。
そこでGPT-2では、より人間に近い、汎用的に使えるモデルを構築することが目的としています。
簡単にまとめてしまうと、OpenAI GPT-2の特徴は以下です。
モデルの仕組みはGPTとほぼ同じで、特定のタスクに特化した教師あり学習は行わず、より大きな言語コーパスを使って、より大きなモデルの言語モデルを事前学習させることにより、zero-shot、もしくはfew-shotのセッティングでも精度が出るような汎用的なモデルを目指しています。
- より大きなデータセット
GPT: BookCorpusデータセット → GPT-2: Webをクローリングして作成したWebText(40GB) - より大きなモデル
GPT: 12レイヤーの1億17百万パラメータ → GPT-2: 48レイヤーの15億42百万パラメータ
つまりタイトル通り、「言語モデルというのは教師なし学習で様々なタスクを学習するモデルである」という考えがもとになっています。
そういう意味では、BERTやその後に続く、大規模なコーパスで事前学習をし、その後ファインチューニングをさらに工夫して精度をさらに高めていく、といった路線とは一線を画していると言えます。
しかしながら、データセットによっては、教師ありデータを使った事前学習-ファインチューニングの手法と比べて、精度はまだまだというものも多数あります。
ただ、この考え方をさらに発展させて、次のGPT-3へとつながっていきますので今後に期待される研究だと思います。
では、論文の詳細を見ていきたいと思います。
オリジナルのOpenAI GPTの詳細については、こちらの記事をご参照ください。
またこちらの記事『13億パラメータ日本語GPT-2を使ってみる』では、日本語GPT-2のモデルを使って文章生成をしていますので、ご参考にしてみてください。
目次
OpenAI GPT-2とは
GPT-2の論文には文章を自動生成した例が載っていますが、この文章生成能力はフェイクニュースの生成など悪用の危険性が極めて高いレベルということで、当初はリリースされないという話になるぐらいのモデルです。
そして、OpenAI GPT-2で目指すところは、特定のタスクに特化するのではなく、色々なタスクに応用できるできるだけ汎用的なモデルを構築することにあります。
なぜ汎用的なモデルが必要かというと、現在の機械学習モデルは、大きなモデルを大量のデータを使って教師あり学習をすることにより、非常に高い精度を達成していますが、一方で、そういったモデルは、特定のタスクについて高精度ではありますが、データの分布が変わってしまうと、意外にもろく、精度が大きく悪化するという現象が見られています。
つまり、現状では、まだ人間のように少ない学習だけでタスクを解けるような汎用的なモデルは出来ていません。
特定のタスクに特化してしまう理由としては、特定のデータセットでファインチューニングしているというのが大きいです。
そこで、OpenAI GPT-2ではファインチューニングではなく言語モデルを中心に考えます。
言語モデルは、以下のように表され、それまでの単語列をもとに次の単語、次の単語と予測していくものです。
$$\begin{align}
p(x)=\prod^n_{i=1} p(s_n|s_1, \cdots, s_{n-1})
\end{align}$$
そして、1つのタスクを解くということはインプットに対して、\(p(output|input)\)を求めることになります。
GPT-2では、これをより一般化し、複数のタスクを一つのモデルで解けるようにしようというのです。
これは、\(p(output|input, task)\)と表し、タスクを学習させるのではなく、インプットを渡し、さらにタスクで条件付けして「こういうタスクを解きなさい」と命令することで、そのタスクを解くものです。
そしてGPT-2ではモデルをより大きくして、より多くのデータで学習することにより、より一般的に転移学習を可能にし、さらに見たこともないデータセットに対しても(zero-shot setting)良い結果が得られるように改良したのです。
翻訳の例だと、今では翻訳用の学習データセットを学習させることが一般的ですが、multi-task settingでは、言語モデルだけを学習したあとに、(translate to french, english text, french text)を学習させます。
OpenAI GPT-2の詳細
OpenAI GPT-2はGPTから特にモデル面での大きな変化はありません。
むしろ、学習の仕方、学習データを工夫したと言えます。
まずは、学習データを見ていきましょう。
学習データセット
学習データセットに、Webをクローリングしたデータを使っています。
Webをクローリングしたデータだと、文章の質が悪いことが想定されますし、文章の質が高いものを抽出するのは時間がかかりすぎますので、ここでは、特定のWebページに関連するデータだけを取得します。
具体的には、Redditというソーシャル・メディア(掲示板のようなもの)からリンクされているページをスクレイピングしてきます。
そして、そこの投稿の中でも3 karma(ポイントのようなもの)以上獲得している投稿に絞ることで、一定の重要性を考慮しています。
それにより、集まった4500万リンク(これをWebTextと呼びます)のうち、2017年12月以降に作成されたリンクを除いたり、重複するページを除くなどをしたあとの、800万文書をデータセットしています。
容量としては40GBです。
Wikipediaについては、他のデータセットと重複してしまい、汎化できたことで精度が改善しているのか、単にWikipediaデータセットの内容がテストデータセットの答えにもなっていることが原因なのかわからなくなるため、使われていません。
以下はWebTextデータセットの例ですが、英語-フランス語で翻訳した文章が入っています。これを使って(教師あり学習をせずに)自然に翻訳を学習しようというものです。

では、次にインプットをどうするか、という問題を見ていきましょう。
インプットの表現
インプットには、単語単位ではなく、Byte Pair Encoding(BPE)というものを使います。
BPEは簡単に言うと、よく出てくる単語は単語のまま辞書に登録し、あまり出てこない単語は文字単位に分割するイメージです。
例を挙げると、よく出てくる“beautiful”は辞書に登録し、あまり出てこない“beautifully”は、“beautiful”と“ly”に分割します。“ly”もあまり出てこなければ、“l”と“y”に分割されます。
しかしながら、Byte Pairと言っても、実際は上記のように“Byte”単位ではなく、“文字”単位になっています。
GPT-2では、真の意味でByte Pair Encodingを行います。つまり、本当にByte単位で分割しています。
ただし、英語で良く出てくる形として、“dog.”や“dog!”、"dog?"などがあるので、こう言った種類の違う文字列はくっつけないなどの工夫を行っているようです。
モデル
モデルはTransformerベースですが、一部以下のような微修正があります。
- Layer Normalization層を各サブ・ブロックの入力の位置に移動。
オリジナルのTransformerでは、以下のように、例えばMulti-Head Attention層の後に残差結合層(Add)が来て、その後にLayer Normalization層が来ていました。
これを、Normalization層をMulti-Head Attention層の前(赤線の位置)にもって来たということです。
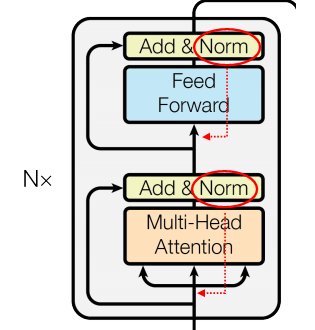
- Layer Normalization層最後のself-attentionブロックの後にも追加。
- ボキャブラリーを50,257に増やす。
- 文章の長さを512単語から1024単語に増やす。
- バッチサイズを64から512に増やす。
モデルに関してはこれぐらいの修正で、GPT-3でも特に変わっていません。
実験
では、実際にGPT-2でタスクを解いた結果を見ていきましょう。
論文では以下の4つのモデルサイズを試しています。
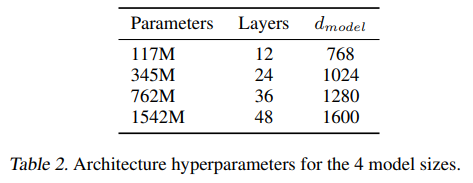
一番大きなサイズのものは48レイヤーで約15億個(!)のパラメータを持ちます(GPT-3になるとさらに増えます)。
1つ目がもともとのGPTと同じサイズ、2つ目がBERT(Large)と同じサイズです。
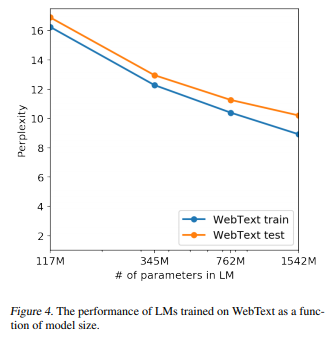
非常に大きなモデルサイズですが、データサイズも非常に大きいため、以下の図の通り一番大きなモデルでもまだアンダーフィットしていそうです。(横軸がパラメータ数で、縦軸がperplexityです。モデルを大きくしていっても、まだperplexityが減少しています)
Language Modeling
では、上記のモデルでWebTextデータセットを使って、言語モデルを事前学習します。
そして、新しいデータセットに対して、追加の事前学習やファインチューニングをせず完全にzero-shotセッティングで、Perplexityや予測精度を計算します。
結果は以下の通りです。
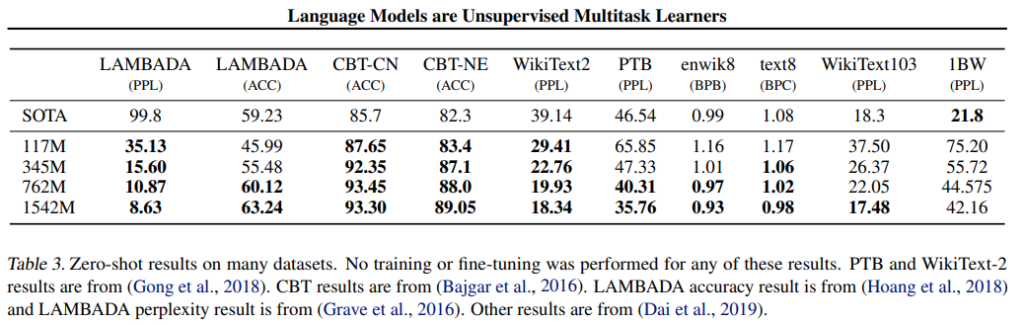
これまでのSoTAに対し、ほとんどのデータセットでperplexity、精度で上回っています。
しかも、これはzero-shotなので、完全に初めて見るデータセットでこれだけの精度が出ているということで、素晴らしい結果です。
また、モデルを大きくすればするほど精度が改善しているのがわかります。
1BWデータセットではperplexityが大幅に悪化していますが、1BWデータセットは文章をシャッフルしているので、長期の依存関係がなくなってしまっていることが原因とのことです。
なお、LAMBADAというのは、以下のようなターゲットとなる単語を予測するタスクで、その予測精度がGPT-2の一番大きいモデルで63.24%ということです。

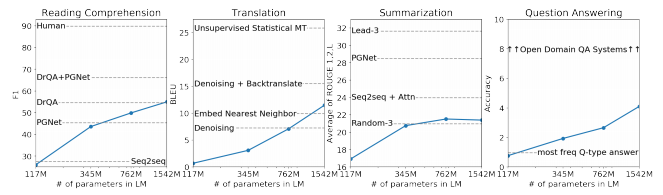
以下は、Reading Comprehension、Translation、Summarization、Question Answeringの結果です。
まだ、SoTAには及びませんが、モデルを大きくしていくことで、精度が改善しています。
Children’s Book Test
ではまず、Children's Book Testデータセットについて、簡単に説明しておきます。
Children's Book Testは、子供向けの本の一部を抜粋したもので、以下の論文で提案されました。
『THE GOLDILOCKS PRINCIPLE: READING CHILDREN’S BOOKS WITH EXPLICIT MEMORY REPRESENTATIONS(2015)』
まず、20個の連続した文章を以下のように抜き出し、これをSとします。

次に、その次に続く文章のうちの一部をマスクします。これをqとします。
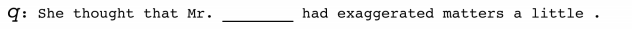
そして、qのマスクした部分に入る単語の候補が10個あります。これをCとします。
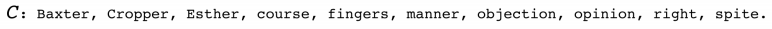
この10個の候補Cから答えaを選ぶ、というタスクです。
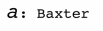
20個の文章ですので、それなりに長く、長期の依存関係を捉える必要があります。
そして、10個からそれぞれを選んで、残りの文章も含めて、言語モデルとしての確率を計算します。
その中で一番確率の高い単語を選びます。
では、名詞、固有名詞の結果は以下です。
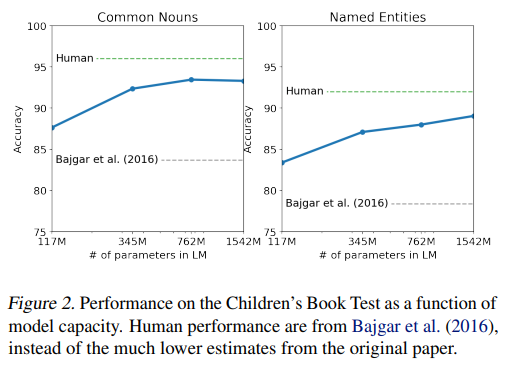
横軸がモデルサイズになりますが、どれもそれまでのSoTAを上回っており、それぞれ93.3%と89.1%の精度になっています。
人間レベルまではもう少しといったところでしょうか。
LAMBADA
LAMBADA(LAnguage Modeling Broadened to Account for Discourse Aspects)データセットは、以下のようにcontextとtarget sentenceが与えられ、target sentenceの最後の単語を予測するタスクになります。
こちらも、文章はそれなりに長いので、長期の依存関係を捉える必要があります。

このデータセットについても、perplexityは99.8から8.63に改善しています。
また、テストデータの精度も19%から52.66%と大幅に改善したとのことです。
Winograd Schema Challenge
Winograd Schema Challengeデータセットは、commonsense reasoning(常識的推論)の能力を測るためのデータセットです。
例えば、以下のような問題です。
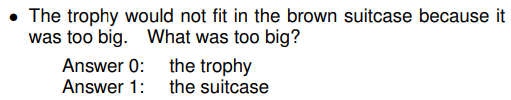
「大きすぎてトロフィーが茶色のスーツケースに収まりませんでした」という文章に対して、「何が大きすぎたのでしょう?」という質問があり、答えをトロフィーかスーツケースを選ぶものです。
自然言語処理で言う、いわゆる「照応解析」の問題です。
このデータセットでも、2番目に大きいもモデルでSoTAを更新しています(Partial ScoringとFull Scoringについては、細かいテクニックですので興味のある方はこちらの論文をご参照ください。)。
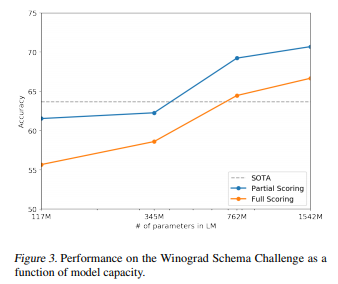
1番大きいモデルではSoTAから7%改善し70%程度になっています。
Translation
英語とフランス語の翻訳タスクです。
翻訳も、教師あり学習だと非常に大きな2つの言語のパラレル・コーパスが必要になりますので、日本語などのメジャーではない言語に対応するため教師なし学習の需要が大きな分野です。
したがって、このタスクではzero-shotなので教師データを使って学習するのではなく、あくまで言語モデルを学習するだけです。
ただし、入力sのフォーマットは、英語からフランス語に翻訳するタスクだと、“英語の文章 = フランス語の文章”という形でインプットしてやり、実際にフランス語に翻訳する場合には、“英語の文章 = ”をインプットして、その後に続く文章を生成する形で翻訳します。
WMT-14データセットの英語からフランス語への翻訳の精度はBLEUスコアで5BLEUとなり、こちらは単語から単語に翻訳する教師なし学習の結果よりも若干悪い精度となっています。
フランス語から英語への翻訳の場合は、11.5BLEUと若干改善しています。
これは、GPT-2が基本的に英語のWebサイトで学習しているため、英語の文章生成の方がうまくできることによるものと考えられます。
この結果は他の教師なし学習による翻訳精度よりも良い結果になっていますが、現在最高の33.5BLEUにはまだまだ及びません。
しかしながら、ここで使ったWebTextデータセットには、10MBしかフランス語の文章がなく、これは他の研究で使われているフランス語データセットの500倍小さいとのことです。
文章生成
論文のappendixには、GPT-2による文章生成の例がいくつか記載されています。
例えば以下のような文章ですが、上段が実際の文章、下段の左が一番小さいモデルで続きを生成した場合、下段の右が一番大きいモデルで続きを生成した例です(服装に関する話題)。
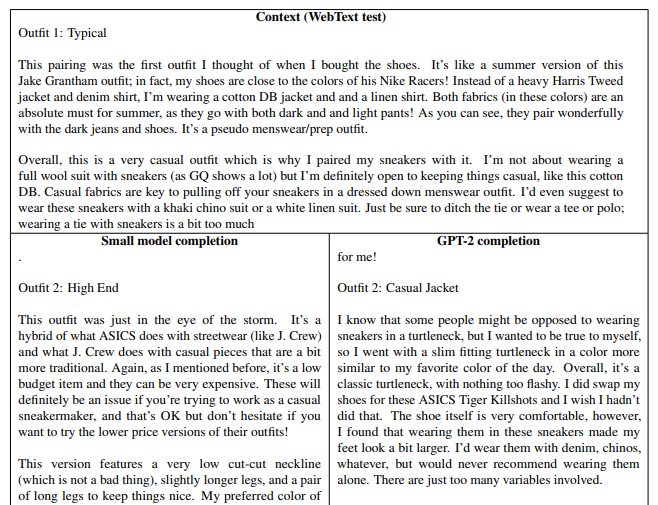
私の英語スキルではどこまで自然かは正しく判断できないかもしれませんが、少なくとも右側はまったく違和感を感じられず、機械が生成したとは思えない文章となっています。
論文には他にも例がありますので、興味がある方は読んでいただければと思います。
まとめ
今回はOpenAIによるGPT-2を見てきました。
ここでのポイントはより大きな言語コーパスを使って、より大きなモデルを学習することにより、zero-shotセッティングでの精度を高めるということです。
この流れはGPT-3でも続き、GPT-3ではさらに大きなモデルになっていきます。
論文では、もっと色んな結果が載っていますので、興味がある方は是非オリジナルの論文を読んでいただければと思います。