今回は、BERTをDistillation(蒸留)という手法を使って軽量化したDistilBERTについて、こちらの原論文をもとに解説したいと思います。
https://arxiv.org/abs/1910.01108
目次
DistilBERTとは
DistilBERT(a Distilled version of BERT)は、0か1かというような教師ラベルではなく、BERTの出力を教師データのように使うことで、精度はBERTの97%を維持しながらもパラメータを40%も削減した、より軽量のモデルです。
つまり、蒸留するという単語にもあるように、重要なコアの部分だけを凝縮するイメージです。
どうして軽量化する必要があるか?という点ですが、最近のNLPにおいて主流となっている手法は、非常に大きなモデルを使って、より多くの教師なしデータで事前学習をすることにより、精度の高い言語モデルを作るという流れなのですが、問題点として、BERTやRoBERT、やOpenAIのGPT、GPT2、GPT3など、モデルがどんどん巨大化し、1つのサンプルの計算も非常に時間がかかってしまい、普通の環境で使いたいユーザーには計算負荷が高すぎるということが背景にあります。
以下の図は、最近の事前学習モデルのパラメータ数です。
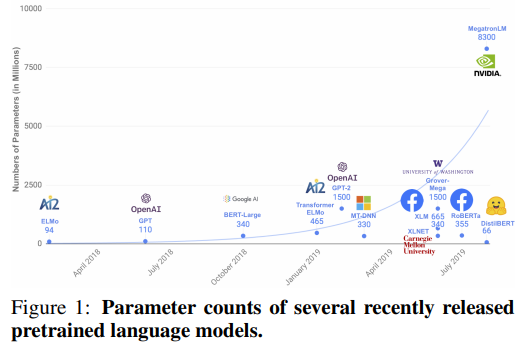
そこで、本論文では、BERTをもとにより小さな軽量モデルを作ることを考えます。
この際に、小さくして精度が劣化するのではなく、精度はなるべく維持し、モデルを小さくしていきます。
DistilBERTは、Knowledge Distillationという手法を用いて、BERTを教師(teacher)、DistilBERTを生徒(student)として、生徒が教師の考え方を学ぶように学習します。
最終的には、DistilBERTはBERTの97%の精度を維持したまま、パラメータ数を40%削減し、計算速度を60%にまで速くしました。
これにより、数%の精度が問題になるユーザーはBERTを使い、数%程度の精度の差は許容範囲内で、それよりも計算スピードを速くしたいというユーザーはDistilBERTを使う、ということが可能です。
では、DistilBERTの詳細について見ていきましょう。
Knowledge Distillation

先生がBERT、生徒がDistilBERT
まず、簡単に“knowledge distillation”という概念について説明します。
knowledge distillationは、Geoffrey Hintonらにより、2015年に“Distilling the Knowledge in a Neural Network”という論文で提案されたもので、studentがteacherの回答を見習うように学習する手法です。
この際のteacherがBERTで、studentがDistilBERTになり、studentはteacherの答えを真似をするように学習します。
ただし、studentはteacherほど大きな記憶容量(パラメータ数)はありませんので、その少ない記憶容量でできるだけteacherに近づけるようにします。
DistilBERTにおけるknowledge distillationの仕組みは、以下の損失関数により達成することができます。
学習用の損失関数
DistilBERTの損失関数は、以下のように、3つの損失関数\(L_{\text{CE}}\)、\(L_{\text{mlm}}\)、\(L_{\text{cos}}\)の和で表します。
$$L=L_{\text{CE}} + L_{\text{mlm}} + L_{\text{cos}}$$
では、個別に見ていきましょう。
distillation loss(\(L_{\text{CE}}\))
1つめは、studentがteacherを模倣するようにする損失関数で、以下のように表されます。
$$L_{\text{CE}}=-\sum_i t_i\times\log\left(s_i\right)$$
ここで、\(t_i\)はteacher(BERT)による\(i\)番目の単語の予測確率です。そして、\(s_i\)はstudent(DistilBERT)による\(i\)番目の単語の予測確率です。
これにより、studentであるDistilBERTは、teacherであるBERTが出力する分布を学習することができます。
例えば、teacherがこのラベルが正しい!と予測し、1に近い予測をしていた場合は、それを学習することができます。
さらに、一番予測確率が高い単語だけでなく、その次に予測確率が高い単語の予測確率なども真似することができ、teacherの予測する分布全体を学習することができます。
ここが0-1の正解ラベルを学習するのと違う部分です。
例えば、以下のような文章を考えましょう。
私は昨日[mask]を観ました。
そして、teacherであるBERTの予測確率がもっとも高い単語が“映画”だったとします。
その場合、studentも“映画”の予測確率を高くするように学習します。
次にBERTの予測確率が高い単語は、例えば”テレビ”で、少し低めですが予測確率がゼロでない単語には“野球”、”サッカー”があったとします。
その場合も、studentは“テレビ”や“野球”、“サッカー”の予測確率もteacherであるBERTに近づけるように学習することができます。
ただし、ここでは予測確率を“softmax-temperature”という関数を使って、
$$p_i = \frac{\exp\left(z_i/T\right)}{\sum_j \exp\left(z_j/T\right)}$$
とします。
これは、\(T\)を1とすれば普通のsoftmax関数になりますが、\(T\)を1よりも大きくすると、普通のsoftmaxと比べて、予測確率が低い単語を予測する確率が上がります(これは文章生成時にランダムさを強くするために使われたりします)。
なぜこのような関数にするかというと、先ほどの例で、“映画”、“テレビ”の予測確率が圧倒的に高く、“野球”や“サッカー”はそれらに比べてかなり低いけれども、ゼロではなかったとします。
その場合、“野球”や“サッカーも”ゼロではないということは考慮したいのですが、普通のsoftmaxだと予測確率が小さすぎて、studentがこれらの単語を考慮するインセンティブがありません。
そこで、予測確率の小さい単語の予測確率を上げることにより、予測確率の小さい単語の予測確率も学習するように仕向けています。
masked language model loss(\(L_{\text{mlm}}\))
こちらはBERTと同じmasked language modelによる損失関数です。
詳細は必要に応じてBERTの記事を参照ください。
cosine embedding loss(\(L_{cos}\))
teacher(BERT)とstudent(DistilBERT)の隠れ層のベクトルのコサイン類似度(cosine similarity)を損失関数とします。
cosine embedding lossにより、studentの文章の埋め込み表現をteacherの埋め込み表現に近づける効果があります。
DistilBERT: a distilled version of BERT
DistilBERTの構造
ここまでは、DistilBERTの学習方法を見てきましたが、ここからはDistilBERTの構造の説明です。
DistilBERTはBERTよりもパラメータ数を減らしたいので、パラメータ削減方法を検討します。
そこで、まず、以下のNext Sentence Prediction(NSP)に絡んだ層を除きます。
- token-type embedding層
例えば2つの文をインプットとした場合、どこまでが1つ目の文章でどこが2つ目の文章かを指定するものです。 - pooler
最後のTransformerブロックの後の分類用の層です。
そして、レイヤー数をBERTの半分にします。
論文ではBERT_BASEのレイヤー数が12だったのに対し、DistilBERTでは6にしています。
これにより、パラメータ数が40%減少することになります。
初期値の設定
のちほど分析されていますが、studentであるDistilBERTの初期値の設定が重要になります。
ここでは、teacherであるBERTのパラメータを初期値として設定します。
ただし、レイヤー数が半分なので、対応する2つのレイヤーのうちの1つを初期値としています。
Distillation
RoBERTaを参考に学習方法を以下のように設定しています。詳細はRoBERTaの記事をご覧ください。
- バッチサイズ4,000と大きくする。
- ダイナミックにマスキングを行う。
- Next Sentence Predictionは行わない。
データ
データはBERTと同じEnglish WikipediaとBookCorpusの2つを使っています。
Experiments
では、実際にDistilBERTの精度がどのようになるか見ていきましょう。
General Language Understanding
まずは、GLUEベンチマークを使って、ELMo、BERT-baseと比較しています。
結果は以下の通りで、それぞれmulti-task learningやアンサンブルなどは行わず、1つのモデルで評価した場合です。
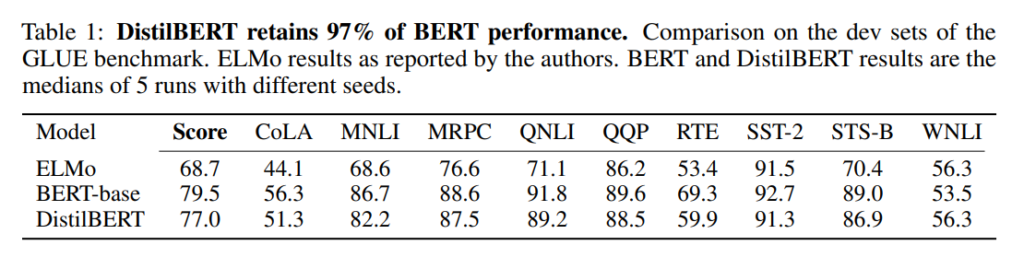
タスクにもよりますが、DistilBERTの精度はELMoよりかなり良くなっています。
また、BERT-baseと比べると、平均で97%程度の精度を維持しています。
つまり、パラメータ数をBERTから40%減らして精度は3%しか低下していないということになります。
下流タスクの精度
続いて、分類タスクであるIMDBデータセットと質疑応答データセットのSQuADでBERT-baseと比較しています。
BERT-baseとDistilBERTを比べると、IMDBでは0.6%程度の悪化にとどまり、SQuADでは3.9%の悪化となっています。
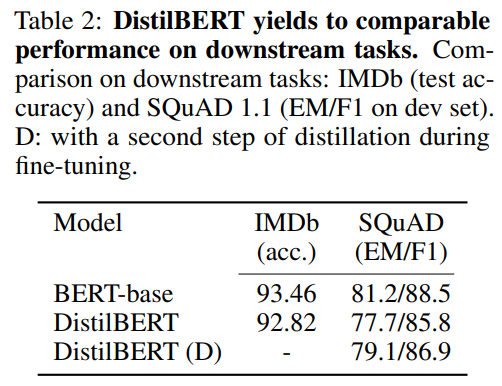
さらにTable 2の1番下の行は、ファインチューニング時にもteacherをBERTにして、distillationを行った場合です。
つまり、ファインチューニングを行うときに、既にSQuADデータで学習したBERTの予測確率も真似するように学習を行っています。
この場合、通常のDistilBERTよりも精度が改善しています。
ここから言えることは、実際の運用において、BERTでは計算負荷が大きすぎる場合DistilBERTを選択できますが、その際にはまず、BERTでターゲットとなるタスクの予測モデルを構築し、さらに事前学習済みのDistilBERTのファインチューニング時に構築済みのBERTを使ってdistillationを行うと良い、ということです。
サイズと推論にかかる時間
以下の表では、ELMo、BERT_BASE、DistilBERTのパラメータ数と、1サンプルを推論した場合の時間を比較しています。

BERT_BASEはELMoよりもパラメータ数が少なく、DistilBERTはBERT-baseよりもさらに40%少なくなっています。
また、推論時間についてもDistilBERTはELMoの半分以下、BERT-baseの60%程度になっています。
追加分析
最後に、triple lossの効果および初期化の方法の影響を分析しています。
Table 4の上から3列がそれぞれ、\(L_{\text{CE}}\)を使わない場合、\(L_{\text{cos}}\)を使わない場合、\(L_{\text{mlm}}\)を使わない場合のGLUEスコアの変化です。
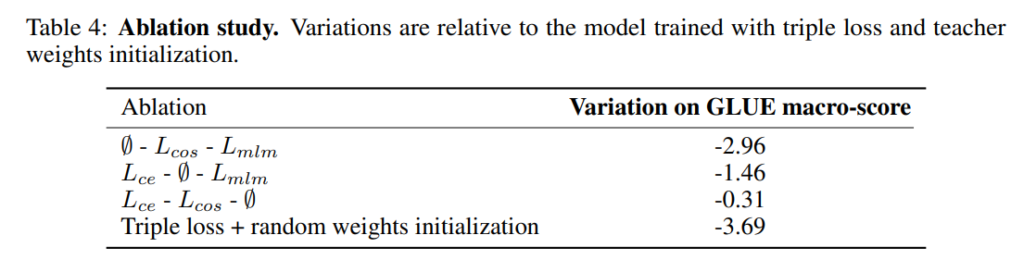
\(L_{\text{CE}}\)を使わない場合、2.96%も精度が悪化しています。
一方で、\(L_{\text{mlm}}\)を使わない場合は0.31%の悪化と、それほど影響は大きくありません。
teacherであるBERTから学習すれば、特に独学で言語モデルを学習する必要性はそれほど大きくないと解釈できます。
最後に、1番下の行ですが、これはstudentであるDistilBERTの初期値設定をteacherであるBERTの初期値にするのではなく、ランダムに初期化した場合の結果です。
GLUEスコアは平均で3.69%も悪化しており、BERTの初期値を利用すべきであることが示唆されています。
まとめ
今回はBERTをknowledge distillationという手法を使って軽量化モデルを構築したDistilBERTを解説しました。
BERT(もしくはRoBERTa)を使うか、DistilBERTを使うかは、数%でも精度を重視する場合はBERTやRoBERTaを、速く推論しないといけない場合はDistilBERTを使う、などといった選択が必要になると思います。
最近のモデルがどんどん巨大化していることに対する対応であり、今後も活発に研究されていくのかな、と思います。