前回、事前学習-ファインチューニングに関する記事を書いたので、次はその発展形ともいえるUniversal Language Model Fine-tuning(ULMFiT)について説明していきたいと思います。
事前学習-ファインチューニングに関する記事はこちらです。
また、事前学習の有効性は以下の記事で検証していますが、非常に有効であることがわかります。今回はこれを発展させたものになります。

目次
ULMFitの概要
ULMFiTは、Universal Language Model Fine-tuningの略で、以下の論文で提案されたモデルです。
https://arxiv.org/abs/1801.06146
次のようなステップで事前学習・ファインチューニングすることによって精度を上げていくものになります。
Wikipediaなど一般的なドメインの文章を使って言語モデルの事前学習をする
↓
解きたいタスクの文章を使って言語モデルのファインチューニングする
↓
センチメント分析など解きたいタスクで分類器をファインチューニングする
さらに、以下のようなファインチューニングのためのテクニックも盛り込んで、Deep Learningの特徴を捉えたファインチューニングを提案しています。
- Discriminative fine-tuning
- Slanted triangular learning rates
- Gradual unfreezing
これにより、一種類のハイパーパラメータのセッティングで、複数のデータセットにおいてSoTAを達成しています。そういう意味で“Universal” Language Modelだとのことです。
では、次から細かく見ていきましょう。
ULMFiTの仕組み
ULMFiTの仕組みはこのようになります。
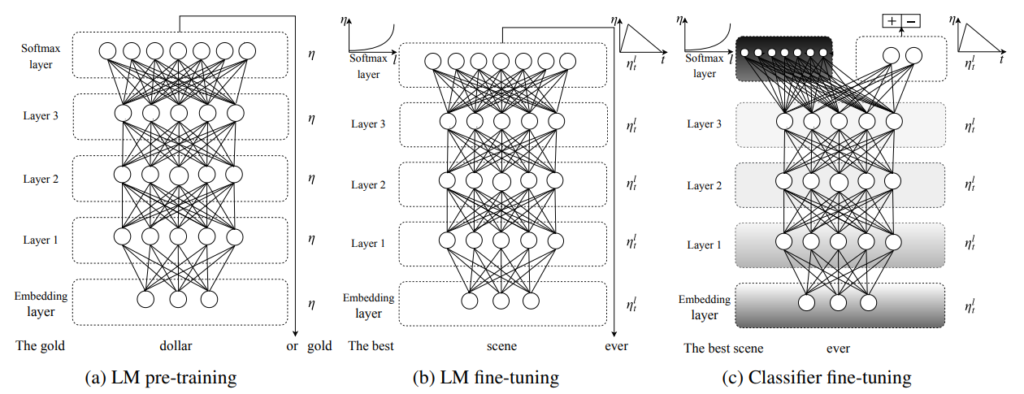
上でも説明しましたが、3つのステップを踏みます。
a) 一般的なドメインのコーパスを使って、言語モデルを学習する。 (左の図)
b) 解きたいタスクのデータを使って、言語モデルをファインチューニングする。 (真ん中の図)
c) 解きたいタスクで、分類器をファインチューニングする。 (右の図)
a) 一般的なドメインのコーパスによる言語モデルの学習
a)ですが、論文ではWikitext-103という一般的なドメインの大規模 コーパスを使って言語モデルの事前学習をしています。これはWikipedia 28,595記事で約1億単語あります。
こういった大きなコーパスで事前学習することにより、後続のタスクが少量のラベル付きデータしかなくてもうまく機能するようになります。
b) 解きたいタスクで言語モデルのファインチューニング
a)で言語モデルを学習させましたが、やはり解きたいタスクのドメインの単語や表現とは違う可能性があるので、解きたいタスクのデータを使って、事前学習をします。これは、データが少なくても、a)で言語モデルを事前学習しているので、はやく収束するとのことです。また、その際に、論文では“discriminative fine-tuning”というファインチューニングの仕方と、“slanted triangular learning rates”という学習率の設定をすることにより効率的にファインチューニングします。
Discriminative fine-tuning
Deep Learningでは、レイヤーごとに捉えている情報が違うと言います。画像認識では、初めの方のレイヤーは縦や横のエッジの情報といった粗い情報を捉えており、だんだん上位のレイヤーにいくにつれて、口や車といった細かい具体的な情報を捉えていきます。
ですので、解きたいタスクのデータでファインチューニングする際にも、各レイヤーの学習率を変えていきます。
論文では、学習率を以下のように設定しています。
$$
\theta^l_t = \theta^l_{t-1} - \eta^l\cdot \nabla_\theta J(\theta)
$$
\( \nabla_\theta J(\theta) \)が勾配で\(\eta^l\)がレイヤーごとの学習率となっています。そして、最後のレイヤーの\(\eta^L\)に対して、
$$\eta^{l-1}=\eta^l / 2.6$$
としています。つまり、レイヤーが下位になるほど、一般的なドメイン知識を優先させるために学習率を小さくして、なるべく調整しないようにします。
Slanted triangular learning rates
こちらは、学習率そのものをiterationごとに変えていく方法です。その際に以下の式で変えていきます。
$$\begin{align}
cut &= \lfloor T\cdot cut\_frac \rfloor \\
p &= \left\{ \begin{array}{ll}t/ cut ,& \text{if} t<cut\\
1- \frac{t-cut}{cut\cdot\left(1/ cut\_frac -1\right)}, & \text{otherwise} \end{array} \right. \\
\eta_t &= \eta_{max}\cdot \frac{1+p\cdot \left(ratio - 1\right)}{ratio}
\end{align}$$
\(cut\_frac\)は学習率が上昇から低下に変わるiterationの場所(割合)、\(T\)はトータルのiteration回数(epoch数×ステップ数)。つまり、\(cut\)は学習率が上昇から低下に変わるiterationの回数になります。
そして、iteration回数\(t\)が\(cut\)まで達していない場合は、\(p\)は線形に増えていきます。そして、iteration回数\(t\)が\(cut\)に達してからは、\(p\)はiteration回数が\(T\)に達するとゼロになるように線形に減少していきます。
\(p\)をそのまま学習率にしてしまうと、初めのiterationでは学習率はゼロになってしまいます。ですので、最大値と最小値を決めます。その最大値が\(\eta_{max}\)で最小値は\(ratio\)を使って制御し、 (\(p=0\)) のときの\(\eta_{max} / ratio \)になります。
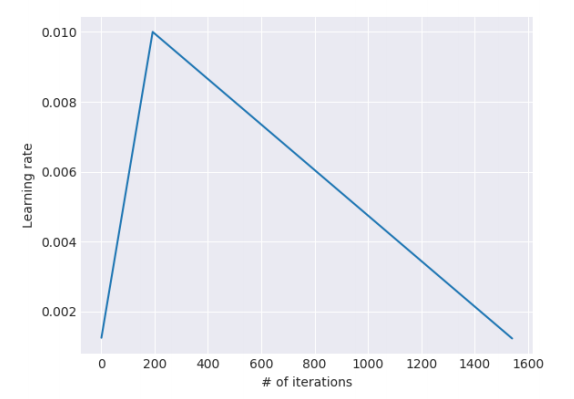
\(T=2000\)、\(cut\_frac=0.1\)、\(ratio=32\)、\(\eta_{max}=0.01\)のとき、以下の図のようになります。最初の上昇する部分がウォームアップステップで、その後少しずつ学習率を下げていきます。
解きたいタスクで分類器をファインチューニング
最後に、解きたいタスクに合わせ、分類用のレイヤーを上位レイヤーにもってきて、ファインチューニングします。一から学習するレイヤーはこのレイヤーだけです。
論文では3つのレイヤーを追加しています。1つ目のレイヤーは以下で説明するConcat poolingレイヤー、2つ目はReLUを活性化関数とした全結合レイヤー、3つ目はアウトプットレイヤーでSoftmax関数を活性化関数とした全結合レイヤーです。全結合レイヤーにはBatch NormalizationとDropoutを適用します。
Concat Poolingレイヤー
これは過去の投稿でも何度か説明していますが、LSTMでは長期の依存関係を捉えることができるとは言え、最後の時点の隠れ層の値だけだとどうしても過去の情報は曖昧になってしまいます。
そこで、すべての時点の隠れ層の値を使って、次のレイヤーに渡します。以前、CNNなどを使って同じようなことをしましたが、ここでは、Max pooling(最大値を取る)とAverage pooling(平均を取る)を使います。
そして、\(H=\{{\bf{h}}_1, \cdots, {\bf{h}}_T \}\)として、すべてを連結します。
$${\bf{h}_c}=\left[ {\bf{h}}_T, \text{maxpool}\left(H\right), \text{meanpool}\left(H\right) \right]$$
これを次のレイヤーに渡します。
Gradual unfreezing
b)のファインチューニングでも学習率を工夫していましたが、ここでのファインチューニングの方法にも工夫を加えます。それを“Gradual unfreezing”と呼んでいます。
すべてのレイヤーを同時に更新すると、今まで事前学習したことをすべて忘れて、めちゃくちゃになってしまいます場合があります。そこで、すべてのレイヤーを一気に学習するのではなく、少しずつ学習していくようにします。
先ほど上位のレイヤーほど一般的な情報が少ないと言いましたが、その理由により、解きたいタスクに合わせてファインチューニングするこのステップでは、まず一番上位のレイヤーのみ更新します(unfreeze)。そして、次のepochでは一番上のレイヤーとその一つ下のレイヤーのみを更新します。といった具合で、epochごとに順に更新するレイヤーを増やしていきます。
その他の仕組み
その他、長文に対応するために論文では“BPT3C(Back Propagation Through Time ffor Text Classification)”と呼んでいる仕組みを使っています。これは、Transformer-XLの論文を解説したときも出てきましたが、長い文章を固定長のセグメントに区切って、2つ目のセグメントは1つ目のセグメントの最後隠れ層の状態を初期値として、順番に処理する方法です。
また、前向きの処理だけでなく、後ろ向きにも文章を読ませて事前学習することでBidirectionalな言語モデルにしています。
実験
方法
タスクは、センチメント分析(IMDbデータセット)、質問の分類(TREC-6データセット)、トピック分類(AG)の3つの文書分類です。なお、TREC-6はデータセットが小さいという特徴があります。これらをひとつの共通のハイパーパラメータを使って評価します。
ハイパーパラメータの設定
ハイパーパラメータは以下のように設定しています。
- 埋め込み表現のサイズ : 400
- LSTMのレイヤー数:3
- LSTMの隠れ層の次元:1150
- ドロップアウト率:0.05 - 0.4
- 分類用のレイヤーの隠れ層の次元:50
- Adamの設定:\(\beta_1=0.7, \beta_2=0.99\)
- 学習率:言語モデルのファインチューニング時0.004、分類器のチューニング時0.01
結果
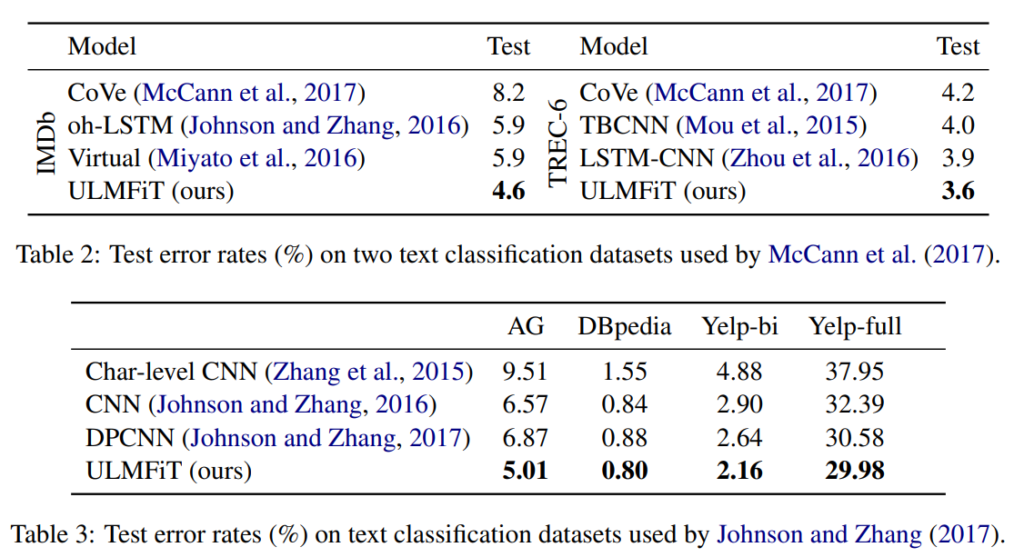
3つのデータセットで実験を行った結果、以下のようにすべてのタスクでSoTAとなっています。
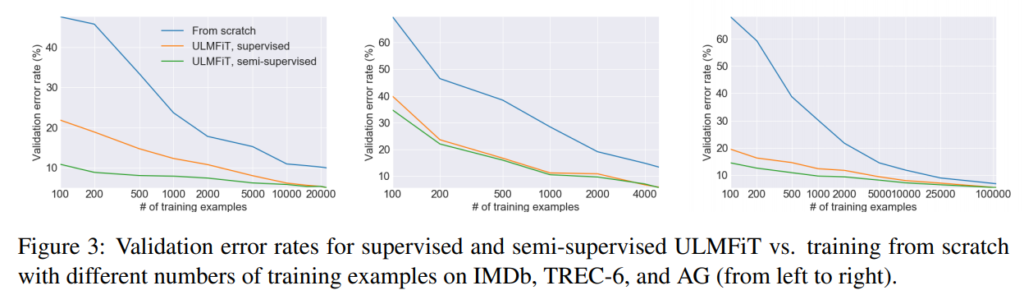
また、1. すべて一から学習する、2. b)の言語モデルの事前学習をラベルのあるデータだけで行う、3. b)の言語モデルの学習をラベルのないデータを含めてすべて使って行う、の3パターンで学習データのサンプル数を変えて、validationデータのエラー率を見ています。
例えば、 1で10,000サンプルを使って学習した場合と、3のパターンでたった100サンプルだけで学習した場合とが同じエラー率になっています!!ULMFiTのすごさがよくわかりますね。特にサンプルが少ないようなタスクだと事前学習の効果は非常に大きいようです。
そのほかにも論文では色々な分析をしていますので、いくつかご紹介したいと思います。
Impact of LM fine-tuning
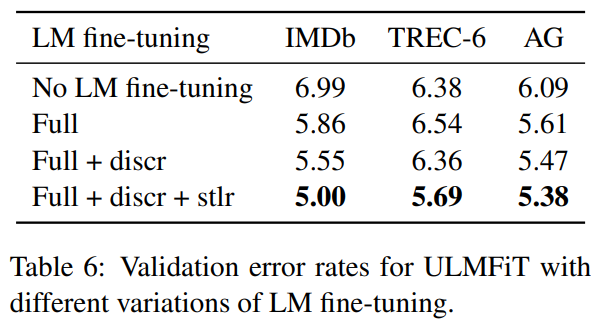
b)のステップの言語モデルのファインチューニングにおいて、2つの工夫がされていましたが、その効果を見ています。具体的には、1. ファインチューニングをしない場合、2. 単純にファインチューニングする場合、3. discriminative ファインチューニングをする場合、4. 3に加えてさらにslanted triangular learning ratesを使う場合で、比較しています。
どれも重要ですが、特徴的なのはTREC-6データセットを使った場合です。このデータセットは非常にサイズが小さいのですが、その場合、言語モデルのファインチューニング自体はあまり有効ではないようです。ただ、slanted triangular learning ratesを使うことによって大幅に精度が改善しています。
Impact of classfier fine-tuning
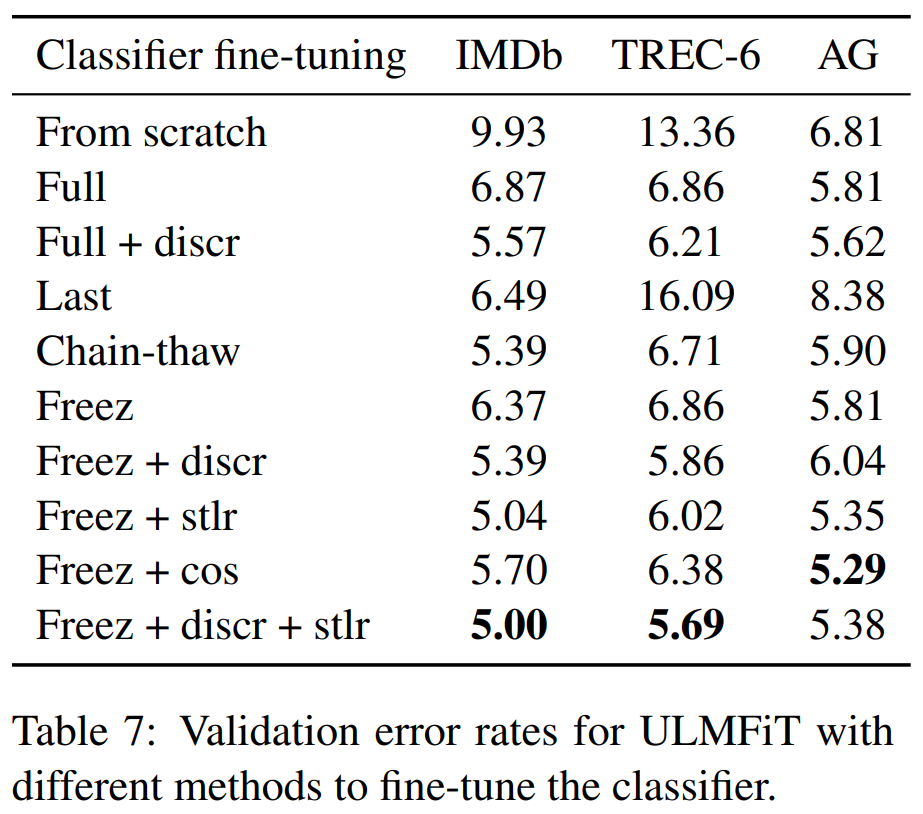
c)のステップの分類器のファインチューニングにおいて、gradual freezingを使ったり色々な方法で試した場合で比較しています。
すべてのデータセットを通してパフォーマンスが良いのは、gradual unfreezing、discriminative fine-tuning、slanted triangular learning ratesを使った場合となっています。
その他の分析
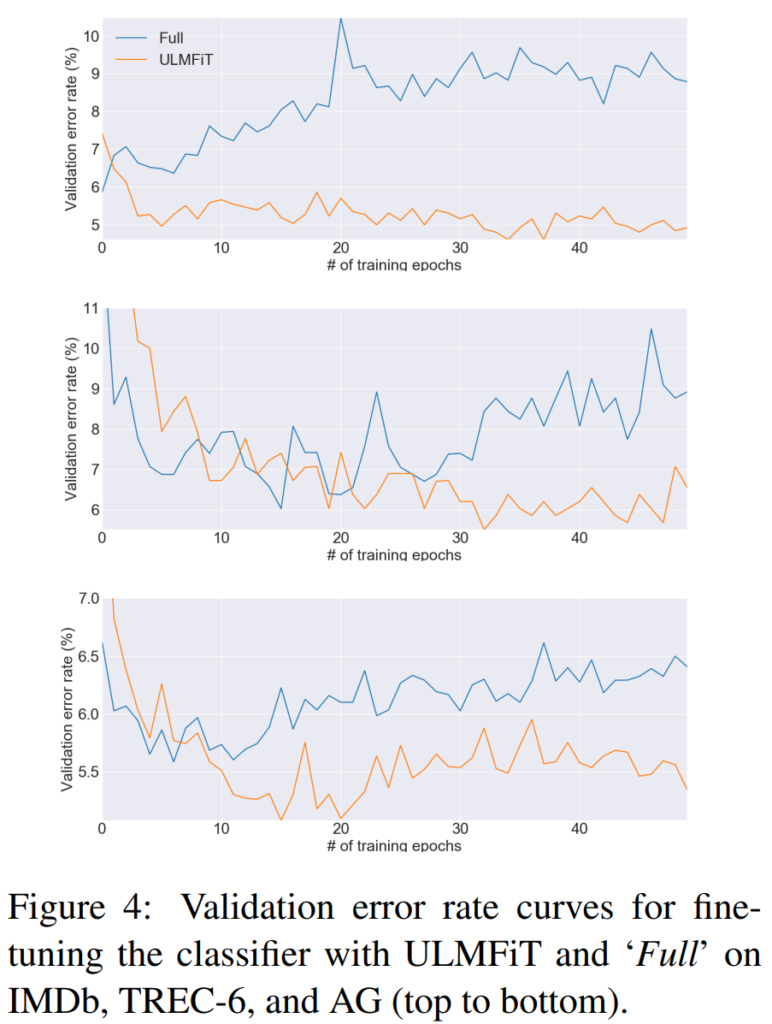
そのほかにも、分類器のファインチューニングをULMFitTで行った場合と単純に行った場合のテストエラーのエポックごとの推移比較(下図)やBidirectionalにした場合にIMDbデータセットのエラー率が5.30から4.58に下がったことなどが載っています。
ほぼ説明しましたが、他にも興味深い分析がされていますので、興味がある方は一度読むと面白いと思います。
まとめ
今回は、事前学習-ファインチューニングの発展形であるULMFiTを詳しく見てきました。あらためてこのステップの重要さがわかりました。BERTでも事前学習の方法に工夫を加えてSoTAを達成していますので、今後も事前学習-ファインチューニングの方法が自然言語処理の発展の鍵になってくるかもしれません。