今回は、RoBERTaを使って、さらなる事前学習することによる効果を分析している“Don't Stop Pretraining: Adapt Language Models to Domain and Tasks”という論文を解説したいと思います。
丁寧に分析されており、非常に実践的な内容になっておりますので、BERTなどを使って自然言語処理を使っている人は必見です。
目次
概要
この論文の概要は以下になります。
- ドメインのデータセットを使って追加で事前学習を行うことによる効果を検証
- タスクのデータセットを使って追加で事前学習を行うことによる効果を検証
- タスクと同じ分布を持つデータの収集方法を提案
簡潔に言うと、すでに一般的なコーパスで言語モデルを事前学習しているモデルに対して、さらに対象となるドメインやタスクのデータセットで事前学習を行うことによる効果を検証するというものです。
モデルについては、この研究はモデルを新しく提案するものではないため、ベースラインモデルとしてをRoBERTa使っています(RoBERTaの解説はこちら)。
RoBERTaはBERTよりも大きなコーパスを使って事前学習をすることにより、BERTの精度を超えたモデルです。
BERTでは、English Wikipedia(2,500M単語)とBooksCorpus(800M単語)の合計16GBのデータセットを使って事前学習しましたが、RoBERTaではさらにCC-News(76GB)、OpenWebText(38GB)、Stories(31GB)を加えて160GBを超えるデータセットを使って事前学習しています。
それ以外にも色々な工夫をほどこしていますが、データを増やしたことは非常に重要で、それによりBERTの精度を上回っています。
そして、この論文では、色々なデータを使って事前学習をしたけれど、タスクの属する各ドメインに対してさらに事前学習することで精度は向上するのか?ということを丁寧に分析しています。
ドメインの関係図
ここで、少しドメインとタスク・データに関する説明をしておきます。
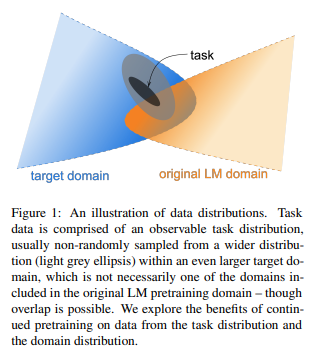
上図で、青がターゲットとなるタスクが属するドメイン、オレンジがRoBERTaで事前学習に使ったドメインになります。
青とオレンジは一部オーバーラップしています。
そして、黒の部分がタスクのデータになります。
薄いグレーの部分はタスクデータではないものの、タスクと同じ分布をもつデータになります。
このように、それぞれのデータは一部オーバーラップしながら存在しています。
追加で行う事前学習の方法
本論文では、オレンジで事前学習(original LM) → 青で事前学習(Domain-Adaptive Pretraining) → 黒で事前学習(Task-Adaptive Pretraining)、というステップを踏んだり、それぞれで事前学習をしたりして、その効果を検証しています。
具体的には
RoBERTaの事前学習に、さらに2つの事前学習を加えることで、さらに精度が向上するかどうかを分析しています。
- Domain-Adaptive Pretraining(DAPT)
タスクと同じドメインのデータセットを使って事前学習を行う(上図の青色の部分)。 - Task-Adaptive Pretraining(TAPT)
タスクのデータセットにあるラベルなしデータを使って事前学習を行う(上図の黒やグレーの部分)。
そして、この論文では以下の4つのドメインについて、各ドメインに2つずつ、合計8個の分類問題を解いています。
- 生物医学(biomedical)
- コンピュータ・サイエンス
- ニュース
- 口コミ
ちょっと前置きが長くなりましたが、実際の分析に進んでいきたいと思います。
Domain-Adaptive Pretraining(DAPT)
“Domain-Adaptive Pretraining(DAPT)”は、ターゲットのタスクの属するドメインのデータで事前学習をするものです。
ターゲットのタスクの属するドメインは、上の図で言う青色の網掛け部分です。
例えば、口コミの分類がタスクであれば、Amazonの口コミや映画の口コミといったものがドメインのデータになります。
今回は上記の4つのドメインを使うので、それぞれ以下のデータセットをドメイン・データセットとして使います。
- 生物医学の論文(BIOMED)
- コンピュータ・サイエンスの論文(CS)
- RealNewsのニュースデータ(NEWS)
- Amazonのレビュー(REVIEWS)
以下の図は、各データセットのデータ量になります。
RoBERTaは160GBのデータセットで事前学習したものになりますが、ここではさらに11GB~48GBのデータセットを使って、追加で事前学習をしていきます。

Analyzing Domain Similiarity
では、まず、ドメイン間の内容がどの程度似ているかについて、類似度を計算して確認します。
ドメイン間の類似度の計算方法は、まずドキュメントをランダムに選び、そこからトップ1万単語を選び、各ドメインで重複している単語の割合を計算します。
文書数はAmazon Reviews以外は、5万文書、Amazon Reviewsは15万文書をランダムで選んでいます。
RoBERTaについても、近似的に、BookCorpus、Stories、English Wikipedia、RealNewsデータセットから50万文書を選んで、同様に類似度を計算します。
その結果が以下の図です。
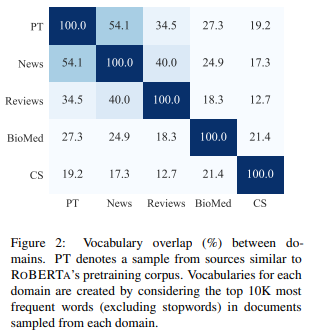
一番上が、RoBERTa(の近似)で、類似度の高い順に、News → Reviews → BioMed → CSになっています。
NewsはそもそもRoBERTaにも入っているのでこのような結果になっています。
では、この類似度によりどのぐらいDAPTの結果が違ってくるのでしょうか。
以下で見ていきたいと思います。
実験
上記のデータセットを使って、RoBERTaで追加で事前学習を行います。
その結果、こちらは先ほどの表ですが、右から2列を見ていただくと、ニュース以外ドメインにおいてmasked LMの損失(\(\mathcal{L}_{\text{ROB}}\)、\(\mathcal{L}_{\text{DAPT}}\))が減少していることがわかります。
改善幅は、RoBERTaの事前学習データとのオーバーラップが小さかったBioMedやCSが大きくなっています。
ニュースデータで追加の事前学習をしても効果が見られないのは、RoBERTaの事前学習で既に使われているからと考えられます。
分類問題
次に、分類問題を解いていきます。
各ドメインに対して、データが多いもの・少ないもの2つずつデータセットを用意します。
そして、各データセットに対して、教師あり学習を行い分類します。
結果は以下です。
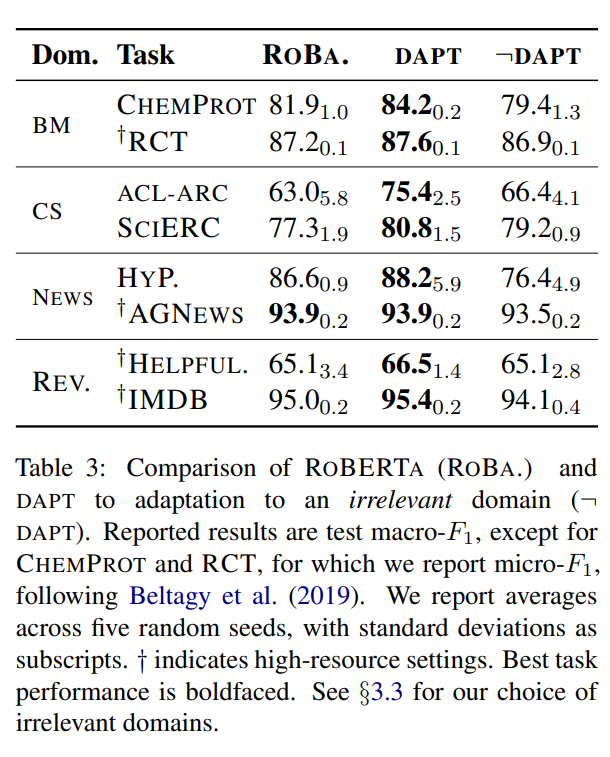
“DAPT”の列(左から4列目)がDAPTを行って分類問題を解いた結果ですが、ニュースドメインのAGNEWS以外のデータセットでRoBERTaを上回っています。
つまり、RoBERTaの事前学習のコーパスと関連性が低いと、ドメインに合わせた事前学習を行うことが効果的であることが示唆されています。
ただし、ニュースドメインでも、HyperPartisanデータセットでは、精度が改善していますので、同じドメインでも一定の効果は得られることがわかります。
DAPTの対象となるドメイン
次に、ターゲットとなるタスクのドメイン以外のデータセットを使ってDAPTを行った場合、どのような結果になるかを見ていきます。
NewsドメインにはCSデータ、BioMedデータを、CSドメインにはNewsデータを、BioMedドメインにはReviewデータを事前学習用データとして利用します。
上記のTable 3の一番右の列がその結果となっています。
どのデータセットもターゲットとなるタスクのドメインのデータセットを使ってDAPTを行った場合よりも、精度が悪化していることがわかります。
そして、ACL-ARC、SciErc以外の場合を除いては、ベースラインであるRoBERTaよりも精度が悪化しています。
ここからわかることは、単に事前学習のデータを増やせばよいのではなく、ターゲットとなるタスクのドメイン(適切なドメイン)のデータセットでDAPTを行わないといけない、ということです。
Task-Adaptive Pretraining(TAPT)
“Task-Adaptive Pretraining(TAPT)”は、ターゲットとなるタスクのデータで、タスクを解く前に一度事前学習を行うものです。
TAPTで使用するデータセットは、基本的に事前学習のデータセットよりも小さく、タスクの分布に非常に近いので、小さな計算負荷で大きな効果が見込まれます。
実験
まず、TAPTを行った場合とベースラインのRoBERTaの結果を比較してみましょう。
結果は以下の表で、どれもRoBERTaの精度を上回っています。
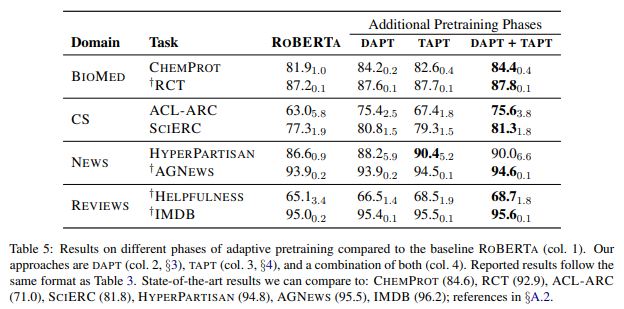
これは、何GBというような大量のデータを使って学習したのではなく、少量のデータでこの結果となっていますので、コストパフォーマンスは非常に高いと思われます。
さらに、DAPTとTAPTを比較すると、RCT、HyperPartisan、AGNews、Helpfulness、IMDBでTAPTの精度がDAPTの精度を上回っています。
繰り返しになりますが、DAPTほどの大量のデータを使わず、比較的少ないデータセットでDAPTの精度を超えており、非常に効率が良いと考えられますので、実務では基本的にはやった方が良いと思われます。
DAPT+TAPT
次に、DAPTとTAPTを組み合わせた場合を見てみましょう。
RoBERTaをターゲットとなるタスクのドメインでDAPTを行い、さらにターゲットとなるタスクのデータでTAPTを行っています。
Table 5の一番右の列ですが、HyperPartisanを除いて、DAPT+TAPTが最も精度が高くなっています(HyperPartisanは若干精度が低下していますが、標準誤差の範囲です)。
この結果を見ると、計算負荷を許容すれば、ターゲット・タスクのドメインで事前学習し、ターゲット・タスクのラベルなしデータでさらに事前学習する方法が最良ということになります。
タスク間の転移学習
今度は、同じドメインですが、別のタスクでTAPTを行います。
例えば、BioMedドメインの場合、RCTデータセットでTAPTを行い、ChemProtデータセットでファインチューニングを行い分類するというものです。
結果は、以下のようになり、ターゲット・タスクで事前学習する場合よりも、精度は悪化しています。

つまり、同じドメインでもタスクによってデータの分布は違うため、DAPTだけでは十分ではなく、DAPTのあとにTAPTを行うことが効果的であることを示唆しています。
ちなみに、これはULMFiTでも使われていた方法です。
以下の記事では、事前学習モデルではありませんが、LSTMを使って、タスクのデータを使って事前学習をすることの効果を検証しています。

TAPT用データを増やす方法
ここでは以下の2つの方法によりTAPT用のデータを増やす方法を検討しています。
- Human Curated-TAPT
- 自動でデータを選択する
では、以下でこれら2つの手法について詳しく見ていきます。
Human Curated-TAPT
これは、ラベル付けされていないデータを利用するものです。
実際によくあるケースとして、例えば、50,000件の文章データがあり、文書分類のためにラベル付けをしますが、すべてのデータにラベル付けをするのは作業負荷が高いため、そのうち2,000データだけラベルを付けるということがあります。
この場合、ラベル付けされていない48,000データもTAPTの対象とすることで、大幅にデータ数を増やすことができます。
データ
RCTデータセットを使って実験してみます。
RCTデータセットの本来の学習サンプルは約180,000件ですが、このうち500件だけ学習用のラベル付きサンプルとします。
そして、それ以外をラベルがないデータとして、TAPTを行います。
同様に、ニュースドメインであるHyperPartisanデータセットでも5000ドキュメントをTAPT用のラベルなしデータとして使い、500ドキュメントを学習用データとして使います。
IMDBデータセットとも同様です(IMDBにはもともとラベルなしデータがあります)。
結果
1行目のTAPTと3行目のCurated-TAPTを比べると、RCT-500データセットで大きく精度が改善しています。
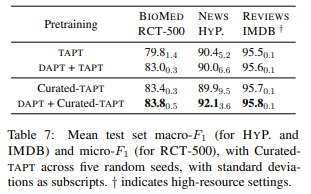
また、DAPT+Curated-TAPTでは、3つのデータセットにおいてDAPT+TAPTの場合よりも精度が改善しています。
RCTデータセットでは、Curated-TAPTが83.4%、Table 5にあるすべてのデータをフルに使った場合のDAPT + TAPTが87.8%となっていますが、Curated-TAPTで使用したラベル付きデータは、もとの学習データ180,000件のうちたったの500件のみです。
つまり、Curated-TAPTは0.3%だけのデータを使って、フルに使った95%の精度を達成しています。
非常に強力ですね。
まとめると、タスクと同じ分布を持つラベルなしデータを大量に集めてTAPTを行うことは非常に効果があると考えられます。
Automated Data Selection for TAPT
では次に、そもそもラベルなしのデータすらない場合を考えていきます。
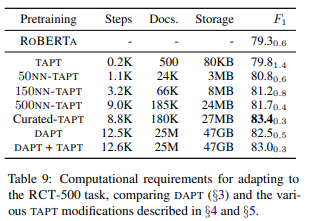
また、同じドメインのラベルなしデータは大量にありますが、DAPTはデータが多く計算リソースを非常に使用するので、限られたリソースでできるTAPTをしたいと思います。
以下の表に、RCT-500データセットでの各事前学習フェーズのドキュメント数や容量がまとめられています。
TAPTに比べてDAPTはドキュメント数が多く、非常に負荷が高いことがわかります。
ではここで、TAPT用のデータを同じドメインのデータから選択する方法を考えます。
簡単に言うと、ドメインのデータからタスクと同じ分布を抜き出します。
まず、ここでは、VAMPIRE(VAriational Methods for Pretraining In Resource-limited Environments)というBag-of-Wordsベースの軽量モデルを使います。
そして、VAMPIREでドメイン・サンプルとタスク・サンプルの文章を埋め込みます。
その埋め込み空間の中で、タスクと近いサンプルを以下の方法で選択します。
- k-近傍法(k-nearest neighbors) : kNN-TAPT
- ランダム: RAND-TAPT
図では以下のようになります。
Biomedical Sentences(ドメイン・サンプル)100万とChemProtデータ(タスク・サンプル)をVAMPIREで埋め込み、それをk-NNでk個のサンプルを選択しています。

ここでは割愛しますが、Appendixにはk-NNで選択したサンプルの例なども記載されています。
結果
以下が結果です。
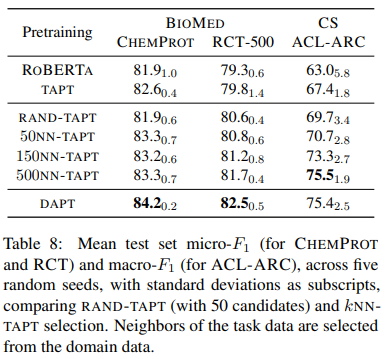
まず1点目は、どのデータセットでもkNN-TAPTは普通のTAPTを上回っています。
つまり、50サンプルずつ選ぶだけでも、TAPTよりも精度が改善するということです。
2点目は、RAND-TAPTはkNN-TAPTよりも精度が悪いということです。
やはりドメインからランダムにデータを選択するのではなく、タスクのサンプルに近いデータを選択することが重要になります。
3点目は、kを増やすほど精度は改善し、最終的にはDAPTに近づきます。
これは、ドメイン・サンプルの中でTAPTに使うサンプルが増えるので、DAPTに近づくのは当然ですね。
以上をまとめると、ドメイン・サンプルからできるだけタスク・サンプルに近いサンプルを抽出することが重要で、それができれば少ないサンプルでも高い精度の改善が見込まれる、ということになります。
まとめ
今回の論文では、十分大きなデータセットで学習したRoBERTaに対して、さらにドメインやタスクのデータセットで事前学習を行うことによる効果を見てきました。
DAPT、TAPTを使うことにより、精度が大きく改善していましたので、まずこれを検討しても良いと思います。
DAPTは負荷が高いという人は、TAPTだけでも良いかもしれませんね。
非常に実践的であり、明日からでも使えそうな話です。
あとは自分たちのデータセットで実際に試してみて、結果を考察してみましょう。