今回から、何回かにわたって情報抽出(Information Extraction)について解説していきたいと思います。
主に、『情報抽出・固有表現抽出のための基礎知識 実践・自然言語処理シリーズ』を参考にしています。
情報抽出とは
現在の世の中には、ニュース、SNSの投稿、ブログ記事、株価や金融政策関にするレポート、企業がPDFで開示する開示情報などたくさんのテキスト情報で溢れており、さらに年々増加しています。
そして、そういったテキスト情報は機械が簡単に処理できない非構造化データとなっています。
今までは、このような非構造化データを集め、必要な情報を手で抜きだすことで、機械が処理しやすい情報に変換していました。
このように機械が処理しやすい情報を構造化データと呼び、非構造化情報を構造化情報に変換することを構造化と呼びます。
例えば、「外国人によるインバウンド需要の増加の影響で、〇〇社の売上がXX%増加した。」というニュースがあったとします。
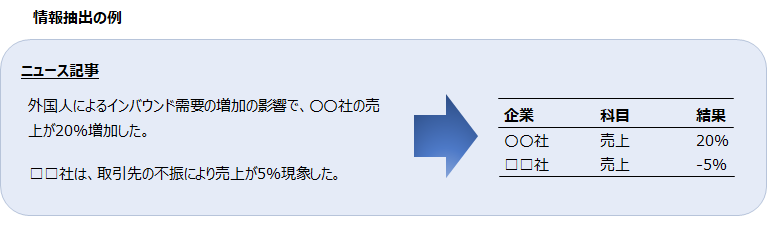
株式を扱うトレーダーであれば、誰(〇〇社)の何(売上)がどうなった(XX%)、という情報を抽出し、過去の決算情報やトレンドを用いて分析し、株式を売買する必要があるかもしれません。
自然言語処理技術を使って、このように必要な情報を自動で抽出、もしくは半自動で抽出することを情報抽出と呼び、文章や文書から特定の欲しい情報を特定し、機械が処理しやすいような形で抽出(構造化)することを言います。
情報抽出の種類
情報抽出には以下のようなタスクがあります。
- 固有表現抽出(Named Entity Recognition; NER)
文章の中の人物名や地名、組織名、日付、金額・数値情報などを特定するタスクです。
上記の例では、〇〇社やXX%という表現が、組織名や数値情報に当たります。
- 照応解析(Anaphora Resolution)
「それ」などの代名詞が何を指しているかを特定したり、同じ企業名でも違う呼び方がされていた場合に(例えば、トヨタ自動車とトヨタ、トヨタ自など)、同じ企業であると特定するタスクです。
特に、日本語では主語が省略されることが多いので、主語が何か?を特定する必要がある場合が多いです。
- 関係抽出(Relation Extraction)
単語間の関係を抽出します。
例えば、「〇〇社の代表取締役社長の△△氏が記者会見を開いた。」という文章であれば、「△△」は「〇〇社」の社長である、もしくは、「岩手県の県庁所在地である盛岡市で~」という文章から、「岩手県」の県庁所在地は「盛岡」である、というような関係を抽出します。
- イベント情報抽出(Event Extraction)
どのようなイベントが起こったか、を抽出します。
「トヨタ自動車がソフトバンクと技術提携した。」であれば、誰(トヨタ自動車)と誰(ソフトバンク)が何をした(技術提携した)か?を抽出します。
情報抽出の手法
情報抽出の手法には大きく以下の2つの手法があります。
- 辞書・ルールベース
- 機械学習ベース
辞書・ルールベースの手法は、一定の規則を人間が考え、その規則に当てはまっているかどうかで、情報を抽出するものです。
機械学習ベースの手法は、大量のデータと正解ラベルを用意し、それをうまく設計された機械学習モデルに投入することで機械に情報を抽出させるものです。
現在では、テキスト情報が非常に増えていることと機械学習の手法がどんどん発展していることから、今取り組むのであれば機械学習ベースの方が主流になっていると思います。
しかしながら、情報抽出は、抽出したい情報によって設計しなければならないので、一つ作れば色んなタスクにも汎用的に使えるというわけではありません。
固有表現抽出であれば、どの固有表現が必要か、関係抽出であれば、どのような関係が必要かということを定義し、モデルを構築していく必要があります。
まとめ
今回は、情報抽出の種類など基本的なところを解説しました。
次回からは、少しずつ詳細に踏み込んでいきたいと思います。