Attentionメカニズムを使ったセンチメント分析
今回はLong Short-Term Memory(LSTM)にAttentionメカニズムを加えたモデルを作成したいと思います。
Attentionメカニズムについては、こちらをご参照ください。

なぜAttention?
Attentionメカニズムとは、どこに注意を向けるかを学習することで長期の依存関係を捉えることのできる方法です。
これは、以前CNNを取り扱ったときにも説明しましたが、一般的にRNNでセンチメント分析をする場合、時点0から順番に単語を処理していき、一番最後の時点\(T\) での出力結果\(y^{<T>}\)をもとに分類されます。
つまりこのような形で処理をします。
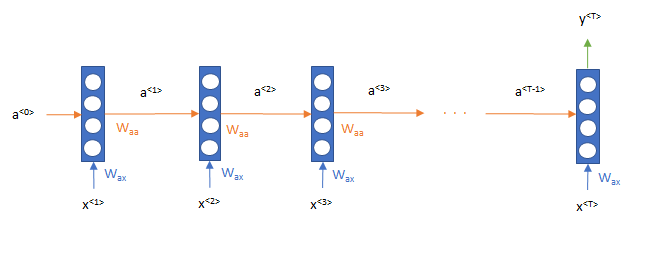
しかし、この場合、RNNは\(T\)より遠い過去の情報の記憶は曖昧になってしまうという欠点があります。
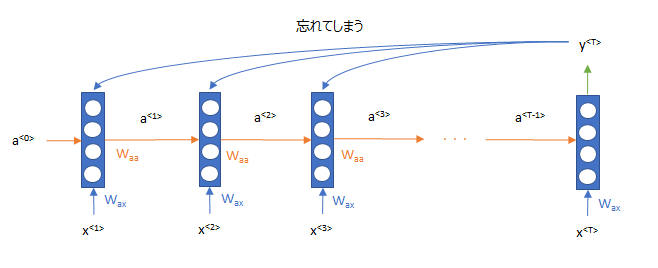
そこで、その欠点を克服するために、RNNの出力を全部使って、初めの方の単語の列の記憶も使おうというものです。
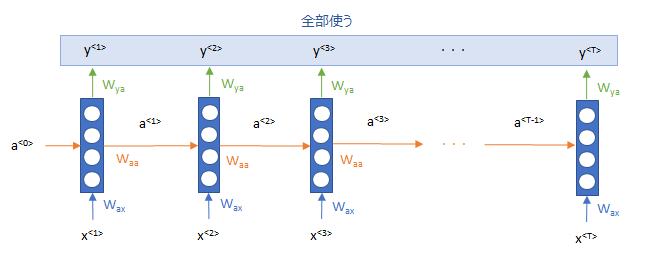
どうやって?というところですが、そこでAttentionメカニズムを使おうというのが以下の論文です。
今回はこちらの論文を参考に、モデルを構築したいと思います。
https://arxiv.org/abs/1703.03130
参考書籍
こちらの本では、TensorflowやPyTorchなどを使わず、PythonによりスクラッチでAttentionメカニズムを実装していますので、参考になると思います。
ニューラル・ネットワークの基礎やRNNからしっかり説明されており、非常にわかりやすいのでオススメです。
時間のない人もすらすら読めると思いますので、一度目を通すだけでも良いと思います。
Attentionの仕組み
Attentionメカニズムの詳細については、こちらの投稿で説明していますので、ここでは今回の論文を非常に簡単に説明します。
まず、各単語の埋め込み表現を以下のようにBidirectional LSTMで処理します。右向きの矢印が順方向の処理、左向きの矢印が逆方向の処理になります。
$$\overrightarrow{h}_t = \overrightarrow{\text{LSTM}}(x_t, \overrightarrow{h}_{t-1})\\
\overleftarrow{h}_t = \overleftarrow{\text{LSTM}}(x_t, \overleftarrow{h}_{t+1})
$$
そして、2つの隠れ層の状態を結合します。
$$h_t=\left[ \overrightarrow{h}_t ; \overleftarrow{h}_t \right] $$
論文の図を引用するとこのような図になります。
\(w_t\)がインプットとなる単語の埋め込み表現で、それを双方向LSTMに投入します。
そして、LSTMのアウトプットである\(h_t\)からattentionを計算して、\(M\)という文書の埋め込み表現を計算します。そこから、softmax関数を通して分類します。
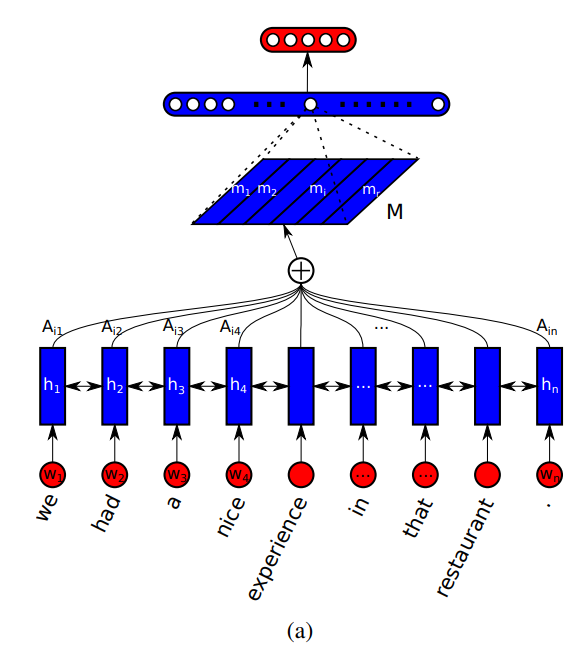
ここで、attentionを使うポイントは、\(h_t\)すべてを直接使うことにより、初めの方の単語を忘れないようにしています。
では、attentionはどのように計算するのでしょうか?
それが論文中の以下の図です。
以下の通り、 隠れ層のアウトプット列\({\bf h}=(h_1, h_2, \cdots, h_T)\)をインプットとする小さなニューラルネットワークで表現します。
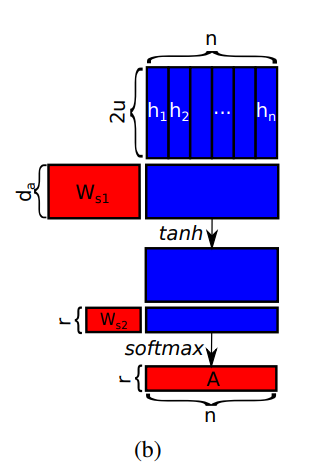
翻訳では、インプットとなる文章とアウトプットとなる文章とのattentionだったのですが、このような分類問題では、インプットとなる文章(正確にはインプットとなる文章の隠れ層のアウトプット)自身にattentionを向けるので、Self-Attention(自己注意)と呼ばれています。
式で書くと以下のようになります。
$$\text{attention}=\text{softmax}\left(W_{s2} \tanh \left( W_{s1} {\bf h}\right) \right)$$
実装
では、今まで見てきたとおりにattentionを使ったセンチメント分析のプログラムを書いてみたいと思います。
プログラムの作成は、こちらのTensorflowのチュートリアルを参考にしております。
https://www.tensorflow.org/tutorials/text/nmt_with_attention
ただし、このチュートリアルは翻訳用のプログラムなので、ここではセンチメント分析用に修正しています。
では、まず、attention部分を作成してみましょう。
式と仕組みがわかっていれば、あとは次元の操作に注意していくだけです。
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import GRU, Embedding, Bidirectional, Dense, Dropout, Flatten
class Attention(tf.keras.layers.Layer):
def __init__(self, da, hop, dropout=0.0):
super(Attention, self).__init__()
self.W1 = Dense(da, use_bias=False)
self.W2 = Dense(hop, use_bias=False)
self.dropout = Dropout(dropout)
def call(self, hidden, mask, training):
"""
hidden: (バッチサイズ, 文章の長さ, 隠れ層の次元)
mask: (バッチサイズ, 文章の長さ)
"""
score = self.W2(tf.nn.tanh(self.W1(hidden))) # attentionスコア
mask = tf.cast(mask, 'float')
score -= tf.expand_dims(mask, -1) * 1e6 # マスクされている部分のattentionがゼロとなるようにスコアを負の大きな値に設定する
attention_weights = tf.nn.softmax(score, axis=1) # softmaxでattentionを計算
attention_weights = self.dropout(attention_weights, training=training)
output = tf.matmul(tf.transpose(attention_weights, perm=[0, 2, 1]), hidden) # attenionをインプットにかけてcontextベクトルを計算する
return output, attention_weights
次にattentionを使って、全体を実装していきます。
一応、論文の通り、multi-hopに対応していますが、ここではhop=1を想定しています。
class SelfAttentionRNN(tf.keras.Model):
def __init__(self, vocab_size, emb_dim, hidden_units, batch_size, da, hops, emb_dropout=0.0, dropout=0.0, output_dropout=0.0, l2=0.0):
super(SelfAttentionGRU, self).__init__()
self.batch_size = batch_size
self.vocab_size = vocab_size
self.emb_dim = emb_dim
self.hidden_units = hidden_units
self.emb_layer = Embedding(input_dim=vocab_size, output_dim=emb_dim, mask_zero=True) # embeddingレイヤー
self.emb_dropout = Dropout(emb_dropout) # ドロップアウトレイヤー
self.bigru_layer = Bidirectional(LSTM(self.hidden_units,
return_sequences=True,
return_state=True,
dropout=dropout,
kernel_regularizer=regularizers.l2(l2))
, merge_mode='concat') # bidirectional GRUレイヤー
self.attention_layer = Attention(da, hops) # attentionレイヤー
self.flatten = Flatten() # すべてを1列にする
self.output_dropout = Dropout(output_dropout)
self.dense = Dense(1, activation='sigmoid', kernel_regularizer=regularizers.l2(l2))
def call(self, x, mask, training):
x = self.emb_layer(x) # embedding
x = self.emb_dropout(x, training=training) # dropout
hidden, state1, state2 = self.bigru_layer(x) # bidirectional gru
attn_output, attention_weights = self.attention_layer(hidden, mask, training) # attention
output = self.flatten(attn_output) # flatten
output = self.output_dropout(output, training=training) # dropout
prediction = self.dense(output) # dense
return prediction, attention_weights
モデル部分はこれだけです。非常にシンプルですね。
重要だと思うのは、行列の次元をひとつひとつ確認しながら書いていくことかなと思います。
これ以下は、attentionに限定されず、他のモデルでも共通して使える部分になります。
まずは、損失関数の定義です。2値分類なので、binary_crossentropyとします。
from tensorflow.keras.optimizers import Adam
optimizer = tf.keras.optimizers.Adam()
def loss_function(label, predict):
loss_ = tf.keras.losses.binary_crossentropy(label, predict)
return tf.reduce_mean(loss_)
論文のようにmulti-hopとするのであれば、ここに以下の論文中のペナルティ関数を入れる必要があります。
今回はそれはしていないので、hop=1に限定したいと思います。multi-hopでも特に難しくありません。
$$P=||\left(AA^T-I\right)||^2_F$$
次に、学習用の関数を定義します。
@tf.function
def train_step(x, y_label):
loss = 0
with tf.GradientTape() as tape:
mask = tf.math.equal(x, 0)
output, attention_weights = model(x, mask)
loss += loss_function(y_label, output)
batch_loss = (loss / len(y_label))
variables = model.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
# accuracyの計算用
predict_label = tf.math.greater(output, 0.5)
correct = tf.equal(y_label, tf.cast(predict_label, y_label.dtype))
correct = tf.reduce_sum(tf.cast(correct, 'int32'))
return batch_loss, correct, len(y_label)
では、次にデータを作成する部分です。
tf.Dataを使って、学習用データセットとテスト用データセットを作成します。
テスト用データセットはわざわざ作らなくてもいいですが、ローカル端末のスペック上、一回のバッチで計算できないので、このようにしています。
BUFFER_SIZE = 64 BATCH_SIZE = 64 train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train.reshape(len(y_train), ))).shuffle(BUFFER_SIZE) train_dataset = train_dataset.batch(BATCH_SIZE, drop_remainder=True) steps_per_epoch = len(x_train) // BATCH_SIZE # 何個に分けるか test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test.reshape(len(y_test), 1))) test_dataset = test_dataset.batch(BATCH_SIZE, drop_remainder=False) steps_per_epoch_test = len(x_test) // BATCH_SIZE
では、モデルをインスタンス化します。 HOP=1としています。
EMB_DIM = 200
HIDDEN_UNITS = 100
DA = 100
HOPS = 1
model = SelfAttentionGRU(vocab_size=MAX_WORD+1,
emb_dim=EMB_DIM,
hidden_units=HIDDEN_UNITS,
batch_size=BATCH_SIZE,
da=DA,
hops=HOPS,
emb_dropout=0.5,
dropout=0.5,
output_dropout=0.5)
精度を計算するための関数を作成しておきます。
def calc_accuracy(dataset, model, steps_per_epoch):
correct_num = 0
total_num = 0
for x_input, y_label in dataset.take(steps_per_epoch):
mask = tf.math.equal(x_input, 0) # マスク
predict, _ = model(x_input, mask, training=False) # 予測
predict_label = tf.math.greater(predict, 0.5) # 0.5以上なら1, 0.5以下なら0
correct = tf.equal(y_label, tf.cast(predict_label, y_label.dtype)) # 正解かどうかを判定
correct_num += tf.reduce_sum(tf.cast(correct, 'int32')) # 正解数を集計
total_num += len(y_label) # 全データ件数
return correct_num / total_num
最後に実際に学習するコードを書いて終了です。
EPOCHS = 1
import time
for epoch in range(EPOCHS):
start = time.time()
#enc_hidden = encoder.initialize_hidden_state()
total_loss = 0; correct_num = 0; total_num = 0; test_correct_num = 0; total_num_test = 0
for (batch, (x_input, y_label)) in enumerate(train_dataset.take(steps_per_epoch)):
batch_loss, correct, total = train_step(x_input, y_label)
correct_num += correct
total_num += total
total_loss += batch_loss
if batch % 10 == 0:
print('Epoch {} Batch {} Loss {:.4f} Acc {:.1f}%'.format(epoch + 1,
batch,
batch_loss.numpy(),
correct_num / total_num * 100))
# テストセットの計算
test_acc = calc_accuracy(dataset, model, steps_per_epoch)
print('Epoch {:02} Train Loss {:.4f} Train Acc {:.1f}%'.format(epoch,
total_loss / steps_per_epoch,
correct_num / total_num * 100))
print(' Test Acc {:.1f}%'.format(test_acc * 100))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
モデル構築結果
では、何とかモデルが出来上がったので、モデルを回して結果を見てみましょう。
結果は、
- 学習データ:84.2%
- テストデータ:83.2%
とLSTM単体の82.5%は上回りましたが、前回のLSTM+CNNの83.9%を若干下回りました。惜しいですね。
ちなみに、こういった面白い論文があります。LSTMはどれぐらいの単語を見ているか?を検証しており、平均的には200個ぐらいの単語を見ていて、きちんと単語の順番まで考慮できているのは50個程度とのことです。
https://www.aclweb.org/anthology/P18-1027/
Attentionを見てみる
最後にattentionがどのようになっているか見てみましょう。 attentionを可視化するためのコードはこちらです。
from IPython.display import HTML
def highlight(word, attn):
"Attentionの値が大きいと文字の背景が濃い赤になるhtmlを出力させる関数"
html_color = '#%02X%02X%02X' % (
255, int(255*(1 - attn)), int(255*(1 - attn)))
return '<span style="background-color: {}"> {}</span>'.format(html_color, word)
def mk_html(tokenizer, sentence, preds, attention_weights):
"HTMLデータを作成する"
# indexのAttentionを抽出と規格化
attention_weights = sample_attention[sample_attention!=0]
attention_weights = (attention_weights - min(attention_weights)) / (max(attention_weights) - min(attention_weights))
# ラベルと予測結果を文字に置き換え
if preds < 0.5:
pred_str = "星3個以下"
pred_prob = 1 - preds
else:
pred_str = "星5個"
pred_prob = preds
# 表示用のHTMLを作成する
html = '<br>確率{:0.0f}%で"{}"です。<br><br>'.format(pred_prob * 100, pred_str)
# 1段目のAttention
for index, attn in zip(sentence, attention_weights):
if index==0:
break
html += highlight(tokenizer.index_word[index], attn)
html += "<br><br>"
return html
上記のコードは、以下の本を参考にさせていただきました。
ちなみに、この本はPytorchで実装する本ですがすごくいいです。
そして、sample_text_seqに分かち書きをして、数値の列に変換し、パディングしたものを以下のように処理をすればattentionの大きさでハイライトされます。
sample_mask = tf.math.equal(sample_text_seq, 0) # マスクを計算 sample_predict, sample_attention = model(sample_text_seq, sample_mask, training=False) # 推定 HTML(mk_html(tokenizer, sample_text_seq[0], sample_predict.numpy()[0, 0], sample_attention.numpy()[0])) # attentionを可視化
では、適当に文章を作成して、結果を見てみましょう。
まず、こちらの文章(元の文章を少し修正しています。)
何度もリピートして利用させて頂いています。 何と言っても、管理人さんの人柄が大好き
です。 貸してくださるキャンプ道具も全て手作りで、設営も手伝ってくれたり、
一緒に子供たちとアケビを取りに行ってくれたり、管理人さんと話がしたいために
ここを選ぶ感じです。 夜は星空がキレイで、フクロウの鳴き声がまた幻想的です。
本当にオススメで大好きなキャンプ場です!
結果は、“星5個”です。attentionの位置もそれっぽいですね。
multi-hopにすると、hopごとにもう少しattentionが分散するかもしれません。

では、次は悪い文章です(別のサイトからとってきました)。
駐車料金高すぎ。下の方の駐車場に車を駐車した人は行きも帰りも地獄。あれで
1000円はありえない。入場料についても高すぎる。
三連休のど真ん中なので仕方ないにしろ、待ち時間長すぎる。アスレチック90分、
幼児用室内カート40ー50分。その他長すぎるために乗っていない。
確率94%で“星3個以下”と推定されました。そうですね、うまく捉えられていそうです。

次は、間違えそうなレビューを適当に作りました。
スタッフの方はすごく親切で説明も丁寧でした。ただ、トイレが汚いのは嫌でした。
二度と行きたくなくなりました。
結果は、“星5個”ですね。どちらかというと星3個以下なのですが、まあわかりにくいですね。
確率も53%と迷っている感があります。
どんなレビューやねん!!という感じなので、恐らく学習データにはこういう文章はないのでしょう...。

まとめ
ということで、今回はLSTMにattentionメカニズムを加えたものを試してみました 。
attentionがどこに当たっているかを見るのは楽しいですね。
以下の本は、Pythonを使ってスクラッチでattentionメカニズムを使ったモデルを構築しています。
スクラッチから作っているので、細かいところも理解することができ、非常にオススメです。
ただ、こんな論文もあります。attentionは説明にはならない!とのことです。まだ読んでいませんので、いつか読みたいと思います。
https://arxiv.org/abs/1902.10186
さらに、こんな論文もあります。attentionは説明にならないわけではない!とのことです…。
https://arxiv.org/abs/1908.04626
では、次はTransformerを実装していこうと思っています。