今回から数回かにわたって、実際の決算書を使ったデータ分析をしていきたいと思います。
まずは決算データの取得や可視化、分析といったところから始めたいと思いますが、本サイトは自然言語処理をメインにしていますので、最終的には自然言語処理を使った分析をしていきたいと思います。
目次
EDINETとは
EDINETとは、“Electronic Disclosure for Investor's NETwork(金融商品取引法に基づく有価証券報告書等の回次書類に関する電子開示システム)"のことで、投資家などが企業の有価証券報告書、半期報告書、四半期報告書、大量保有報告書といった投資家にとって重要な開示書類を自由に見るためのシステムです。
以下のような画面で、提出企業や書類の種類等を指定することが可能です。
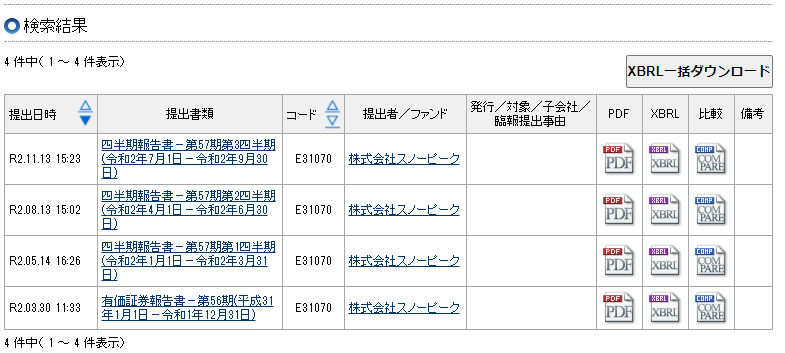
そして、検索すると、以下のように指定した条件にマッチする書類の一覧が表示されます。PDFやXBRL形式(後述)で取得することができますので、普通に閲覧する分にはPDFをクリックすることにより、有価証券報告書等を見ることが可能です。
今回はこの EDINET からEDINET API を使ってデータの取得をします。
ただし、 PDF でデータを取得すると表形式のデータの取り扱いが以上に難しくなります。
そこで取り扱いやすいXBRLという形式のデータを利用したいと思います。
XBRLとは
XBRL(eXtensible Business Reporting Language)とは、財務情報や投資情報といった事業報告用の情報作成・流通・利用できるように標準化された xml ベースの言語になります。
これを使えば 、例えば売上高を取ってきたい場合、 PDF を解析する必要がなく、売上高に対応するタグを検索することで数値を取ってくることが可能になります。
例えば、トヨタ自動車の2020年3月期の有価証券報告では、以下のような5期間の経営指標の推移が記載されています。
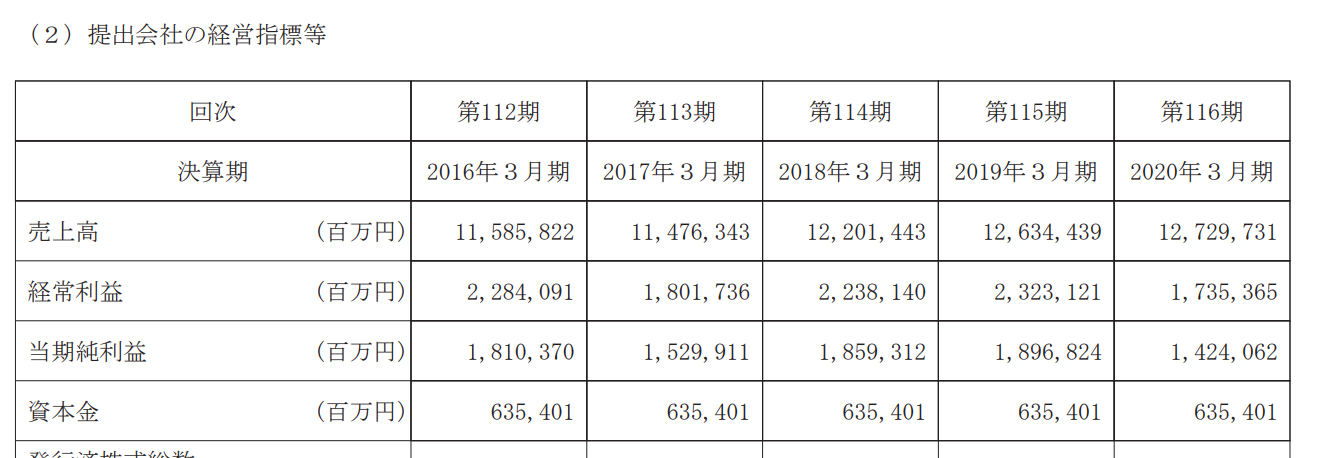
これは特に表形式のデータなのでPDFから取得するのは非常に困難です。
XBRLだとそれほど難しくはありません(うまく取れないときも多いですが)。
例えば、このうちの経常利益部分はXBRLだと以下のように記載されています。
<jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults contextRef="Prior4YearDuration_NonConsolidatedMember" unitRef="JPY" decimals="-6">2284091000000</jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults>
<jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults contextRef="Prior3YearDuration_NonConsolidatedMember" unitRef="JPY" decimals="-6">1801736000000</jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults>
<jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults contextRef="Prior2YearDuration_NonConsolidatedMember" unitRef="JPY" decimals="-6">2238140000000</jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults>
<jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults contextRef="Prior1YearDuration_NonConsolidatedMember" unitRef="JPY" decimals="-6">2323121000000</jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults>
<jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults contextRef="CurrentYearDuration_NonConsolidatedMember" unitRef="JPY" decimals="-6">1735365000000</jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults>
ぱっと見では非常にわかりにくいですが、1行目の“jpcrp_cor:OrdinaryIncomeLossSummaryOfBusinessResults”という部分がkeyになっていて、"Prior4YearDuration_NonConsolidatedMember"がcontextRefと呼ばれるものです。
Prior4Yearというのは4期前を意味しており、NonConsolidatedMemberは単体を意味しています。
そして、その数値(この場合2284091000000円)やunitRef(単位)等の情報が記載されています。
基本的には、このkeyとcontextRefを指定することにより、数値を引っ張ってくることが可能です。
では、XBRLの取得、XBRLパーサーによるデータの取得をやっていきましょう。
EDINET APIによるデータ取得
API の細かい仕様はここでは割愛しますので、以下のページをご参照ください。
https://disclosure.edinet-fsa.go.jp/EKW0EZ0015.html
EDINET APIには大きく二つの種類があり、一つは書類の一覧を取得するAPI、もう一つは書類 ID を指定して書類の内容を取得するAPIです。
書類一覧API
まず一つ目の書類一覧APIを使って、書類の一覧を取得したいと思います。
こちらが仕様書に記載されている書類一覧 API のサンプルになります。

エンドポイントに対して、日付と必要に応じて種類を指定します 。
書類一覧が欲しい場合は、種類に2を指定します。
では Python を使って実際に取得してみましょう。
まず、今後必要になってくるライブラリも含めてimportしておきます。
import requests import os import zipfile import numpy as np import pandas as pd from pandas import DataFrame import matplotlib.pyplot as plt import seaborn as sns; sns.set(); %matplotlib inline
一覧の取得関数を作成します。
EDINET_API_URL = "https://disclosure.edinet-fsa.go.jp/api/v1"
def get_submitted_summary(params):
url = EDINET_API_URL + '/documents.json'
response = requests.get(url, params=params)
# responseが200でなければエラーを出力
assert response.status_code==200
return response.json()
これだけです。
あとは、以下のように作成した関数を呼び出して一覧を取得し、pandasのDataFrameに変換することで利用することができます。
date = '2020-03-30'
SUMMARY_TYPE = 2
params = {'date': date, 'type': SUMMARY_TYPE}
doc_summary = get_submitted_summary(params)
df_doc_summary = pd.DataFrame(doc_summary['results'])
df_doc_summary
では、取得した一覧を見てみましょう。

書類取得API
続いて、書類一覧ではなく、書類取得APIを使って書類自体を取得したいと思います。
こちらも特段難しいことはなく、書類IDと書類の種類を指定することでzip形式で書類を取得することが可能です。

typeは1が本文書、2がPDFですので、1の本文書を取得します。
def get_document(doc_id, params):
url = EDINET_API_URL + '/documents/' + doc_id
response = requests.get(url, params)
return response
ついでに、zip形式でダウンロードする関数も作っておきます。
def download_document(doc_id, save_path):
params = {'type': 1}
doc = get_document(doc_id, params)
if doc.status_code == 200:
with open(save_path + doc_id + '.zip', 'wb') as f:
for chunk in doc.iter_content(chunk_size=1024):
f.write(chunk)
そして、例えば、スノーピークの決算を見たいとします。
この場合は、先ほどの一覧を取得したDataFrameを使って、
df_doc_summary.query('edinetCode=="E31070"')
で検索することが可能です(EDINETコードで取得しましたが、証券コードでももちろん指定可能です)。
そして、そこから2019年12月期の有価証券報告書はS100IC1Bという文書IDであることがわかりました。
では、download_document関数を使って、有価証券報告書をダウンロードしましょう。
download_document(doc_id='S100IC1B', save_path='./')
これで、指定したフォルダににzip形式で保存できます。
あとは、zipを解凍すれば、PublicDocの下にHTMLやXBRLファイルが保存されています。
データをまとめて取得
では、書類を一つ一つダウンロードするのは大変なので、まとめて取得する関数を以下に作成します。
doc_type_codesは、文書の種類で120が有価証券報告書、130が訂正有価証券報告書という具合で、他にも半期報告書や四半期報告書も取得します。
SUMMARY_TYPE = 2
def download_all_documents(date, save_path,
doc_type_codes=['120', '130', '140', '150', '160', '170']):
params = {'date': date, 'type': SUMMARY_TYPE}
doc_summary = get_submitted_summary(params)
df_doc_summary = pd.DataFrame(doc_summary['results'])
df_meta = pd.DataFrame(doc_summary['metadata'])
# 対象とする報告書のみ抽出
if len(df_doc_summary) >= 1:
df_doc_summary = df_doc_summary.loc[df_doc_summary['docTypeCode'].isin(doc_type_codes)]
# 一覧を保存
if not os.path.exists(save_path + date):
os.makedirs(save_path + date)
df_doc_summary.to_csv(save_path + date + '/doc_summary.csv')
# 書類をを保存
for _, doc in df_doc_summary.iterrows():
download_document(doc['docID'], save_path + date + '/')
open_zip_file(doc['docID'], save_path + date + '/')
return df_doc_summary
return df_doc_summary
続いて、zipファイルを解凍する関数も作っておきます。
def open_zip_file(doc_id, save_path):
if not os.path.exists(save_path):
os.makedirs(save_path + doc_id)
with zipfile.ZipFile(save_path + doc_id + '.zip') as zip_f:
zip_f.extractall(save_path + doc_id)
日付でループするので、そのための設定をし、とりあえず2020年3月1日から2020年6月30日までに提出された報告書を取得します。
from datetime import datetime, timedelta
def date_range(start_date: datetime, end_date: datetime):
diff = (end_date - start_date).days + 1
return (start_date + timedelta(i) for i in range(diff))
start_date = datetime(2020, 3, 1)
end_date = datetime(2020, 6, 30)
では、取得しましょう。今回は有価証券報告書のみに限定したいと思います。
doc_type_code=['120']
save_path = 'original_data/'
for i, date in enumerate(date_range(start_date, end_date)):
date_str = str(date)[:10]
df_doc_summary = download_all_documents(date_str, save_path)
if i == 0:
df_doc_summary_all = df_doc_summary.copy()
else:
df_doc_summary_all = pd.concat([df_doc_summary_all, df_doc_summary])
これで、指定したフォルダに4か月間に提出された有価証券報告書が保存されました。
次はこのデータを使って取得したいデータを抽出する方法を説明します。
EDINET XBRLを使ったデータ取得
今回はこちらのXBRLパーサーを使わせていただきたいと思います。
https://github.com/BuffetCode/edinet_xbrl
普通にpipでインストールして使えます。
以下の関数で、keyとcontext_refを指定し、pathで指定したファイルからデータを取得します。
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
def get_one_xbrl_data(path, key, context_ref):
parser = EdinetXbrlParser()
## 指定したxbrlファイルをパースする
xbrl_file_path = path
edinet_xbrl_object = parser.parse_file(xbrl_file_path)
## データの取得
data = edinet_xbrl_object.get_data_by_context_ref(key, context_ref)
if data is not None:
return data.get_value()
例えば今期の売上を取りたい場合は、keyがjpcrp_cor:NetSalesSummaryOfBusinessResultsで、contextRefがCurrentYearDurationなので、以下のように指定します。
import glob
seccode = 7816
# 文書IDと提出日を取得
doc_id = df_doc_summary_all.query(f'secCode=="{seccode}0"').docID.values[0]
date = df_doc_summary_all.query(f'secCode=="{seccode}0"').submitDateTime.values[0]
# XBRLを取得
file_path = save_path + date[:10] + '/' + doc_id + '/XBRL/PublicDoc/*.xbrl'
file_path = glob.glob(file_path)[0]
# データを取得
get_one_xbrl_data(file_path,
key='jpcrp_cor:NetSalesSummaryOfBusinessResults',
context_ref='CurrentYearDuration')
結果は以下のように文字列で返ってきます。
'14260803000'
テキスト情報も取得可能で、例えば「事業等のリスク」欄を取得したい場合には、以下のようにkeyとcontext_refを取得します。
get_one_xbrl_data(file_path,
key='jpcrp_cor:BusinessRisksTextBlock',
context_ref='FilingDateInstant')
それ以外にも取れますので、タクソノミを見たり(結構大変ですが)、XBRLファイルを見たりしながら自分の欲しい情報を取得します。
欲しいデータをまとめて取得
一つ一つ指定していては面倒ですので、まとめて取得しようと思います。
私の場合は、account_listというものを作成していて、それを読み込む形にしています。
account_df = pd.read_csv('account_list.csv').fillna('')
中身は単純に名前や何期前かという情報や、keyとcontext_refの一覧です。
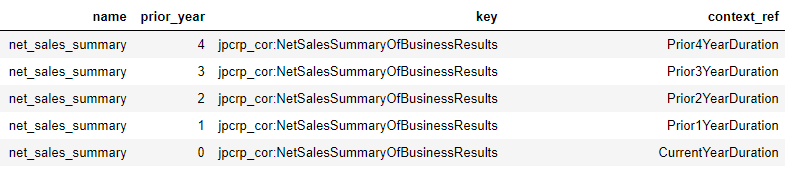
そして以下の関数で必要な情報をまとめて取ってきます。
def get_xbrl_data(path, account_df):
parser = EdinetXbrlParser()
## parse xbrl file and get data container
xbrl_file_path = path
edinet_xbrl_object = parser.parse_file(xbrl_file_path)
## データの取得
account_df['value'] = ''
for idx, account in account_df.iterrows():
key = account['key']
context_ref = account['context_ref']
data = edinet_xbrl_object.get_data_by_context_ref(key,
context_ref)
if data is not None:
account_df.loc[idx, 'value'] = data.get_value()
return account_df
するとvalueの列に数値が設定されて返ってきます。

また次回深堀りしたいと思いますが、今回は簡単なグラフだけ作成しようと思います。
とりあえず、基準日と何期前かという情報から、1期前から5期前の年月を計算する関数を作っておきます。
def calc_fiscal_year(prior_year, asof):
return datetime.date(int(asof.year - prior_year),
asof.month, asof.day)
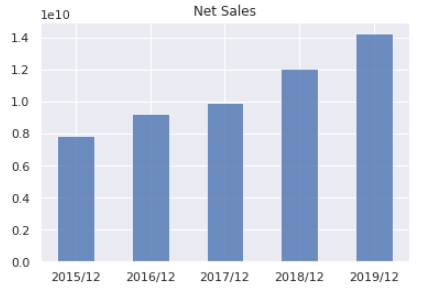
そして、それを使って、売上高の棒グラフを作成してみます(雑ですみません)。
# 売上を取得
net_sales_summary = account_df.query('name=="net_sales_summary"').copy()
# 数値データに変換
net_sales_summary['value'] = net_sales_summary['value'].astype('float')
# x軸用に調整
years = [calc_fiscal_year(prior_year, asof=datetime.datetime(2019,12,31))
for prior_year in net_sales_summary.prior_year]
net_sales_summary['fiscal_year'] = [str(year.year)+'/'+str(year.month)
for year in years]
# 棒グラフを作成
plt.bar(net_sales_summary['fiscal_year'], net_sales_summary['value'],
color='b', alpha=0.8, width=0.5)
plt.title('Net Sales')
するとこのような感じで売上高の5期間の推移を見ることができます。もちろん、売上高だけでなく、経常利益や自己資本、配当の推移も簡単に見ることができます。
それについては次回Plotlyというツールを使って行いたいと思います。
まとめ
今回は、EDINETのAPIを使って、EDINETから有価証券報告書を取得し、XBRLパーサーを使ってXBRLデータから必要な情報を抜き出してみました。
次回はこれらの情報をもとにPlotlyを使って、インタラクティブにデータを可視化する仕組みを作っていきます。
では!