前回はEDINETからEDINET APIを使って、企業の有価証券報告書情報(決算書)を取得し、さらにそこから欲しい情報を取り出せるようにしました。

今回はその取り出し情報を使って、データの可視化を行っていきたいと思います。
もちろんPythonのMatplotlibなどでもできるのですが、せっかくなのでPlotly社のPlotlyというパッケージを使ってインタラクティブな可視化をしていこうと思います。
Plotlyを使えば下図のようなグラフの点にカーソルを合わせるとその数値が表示されたり、特定の箇所を拡大させたりするようなグラフを簡単に作ることができます。
これは実際にデータ分析をする上では非常に有効で、分析の効率やクオリティが格段にアップすると思います。
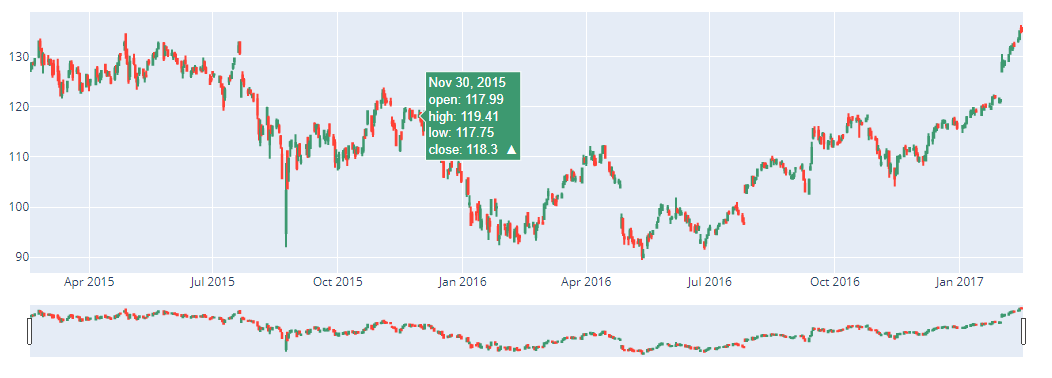
個人的にはMatplotlibよりもわかりやすいので、特にインタラクティブにする必要がなくても使っています。
目次
Plotlyによる描画の基礎
ここでは、Plotlyで図を描く場合の基本的な方法を解説します。
Plotlyでは、図の要素は“データ”と“レイアウト”に分かれ、それらをそれぞれ指定することで描画することができます。
データ
データに実際に描きたい図の種類を決め、それにデータやマーカーの種類や色などを設定します。
以下は棒グラフの場合です。goというのはplotly.graph_objectで、そのBar(クラス)を使います。
data = go.Bar(x=x_values,
y=y_values,
width=0.5,
name=title,
marker={'color': '#4169e1'},
)
引数は、上から順番に“横軸のデータ”、“縦軸のデータ”、“棒の太さ”、“データの名称”、“マーカー”を表します。
"marker"には色だけでなく、他にも設定することが可能なのですが、その場合は辞書形式で設定します。
複数のデータを一つのグラフに表示したい場合はリストに入れます。
data = [go.Bar(x=x_values_1,
y=y_values_1,
width=0.5,
name=title_1,
marker={'color': '#4169e1'},
),
go.Bar(x=x_values_2,
y=y_values_2,
width=0.5,
name=title_2,
marker={'color': '#38a1db'},
)
]
もちろんこういう形でも書くことができます。
data1 = go.Bar(x=x_values_1,
y=y_values_1,
width=0.5,
name=title_1,
marker={'color': '#4169e1'},
),
data2 = go.Bar(x=x_values_2,
y=y_values_2,
width=0.5,
name=title_2,
marker={'color': '#38a1db'},
)
data = [data1, data2]
レイアウト
そして、図全体のレイアウトを決めるのがレイアウトです。
layout = go.Layout(title=('売上高と経常利益'),
yaxis=dict(title='({億円})))
引数は1行目から順に“グラフのタイトル”、“y軸のタイトル”です。
もちろん、“x軸のタイトル”なども指定することは可能です。
表示
そして、これまでに作成したデータとレイアウトをgo.Figure()の引数として渡せば描画できます。
fig = go.Figure(data, layout) fig.show()
では、実際に見たいものを作って、慣れていきましょう。
今回は、キャンプ用品でお世話になっているスノーピーク社の業績等について見ていきたいと思います。
棒グラフを使った売上高推移の可視化
では、まず棒グラフを使って、売上高の推移をプロットしてみましょう。
事前準備
ここから少し、可視化のためのDataFrame等の設定をします。
本質的な部分ではないため、次の「Plotlyによる描画」まで飛ばしていただいても大丈夫です。
とりあえず、表示しやすいようなDataFrameにまとめる勘定科目のリストと、勘定科目と日本語名との対応表の辞書型変数を作成します。(勘定科目ではないものもありますがそこはご容赦ください)
account_names = [
'net_sales_summary_non_consolidated',
'ordinary_income_summary_non_consolidated',
'net_asset_summary_non_consolidated',
'total_asset_summary_non_consolidated',
'equity_ratio_summary_non_consolidated',
'roe_summary_non_consolidated',
'number_of_employees_summary',
'net_asset_per_share_summary',
'dividend_per_share_summary',
'profit_per_share_summary',
'price_earnings_summary',
'payout_ratio_summary',
'temporary_workers_summary',
'total_return_per_share_summary'
]
account_dict = {'net_sales': '売上高',
'ordinary_income': '経常利益',
'net_asset': '純資産',
'total_asset': '総資産',
'equity_ratio': '自己資本比率',
'roe': 'ROE',
'number_of_employees': '従業員数',
'net_asset_per_stock': '1株当たり純資産',
'net_asset_per_share': '1株当たり純資産',
'dividend_per_share': '1株当たり配当金',
'profit_per_share': '1株当たり当期利益',
'price_earnings': '株価収益率',
'payout_ratio': '1株当たり配当金',
'temporary_workers': '臨時雇用者数',
'total_return_per_share': '株主総利回り'}
前回作った書類の一覧が入ったDataFrameから文書ID(doc_id)と提出日(date)、決算日(period_end)を取ってきます。
import glob
doc_id = df_doc_summary_all.query(f'secCode=="{seccode}0"').docID.values[0]
print(doc_id)
date = df_doc_summary_all.query(f'secCode=="{seccode}0"').submitDateTime.values[0]
print(date)
period_end = df_doc_summary_all.query(f'secCode=="{seccode}0"').periodEnd.values[0]
period_yyyymm = to_date_from_str(period_end)
# データの読み込み
file_path = save_path + date[:10] + '/' + doc_id + '/XBRL/PublicDoc/*.xbrl'
file_path = glob.glob(file_path)[0]
df = get_xbrl_data(file_path, account_df)
関数の中身は記載しませんが、8行目のto_date_from_strという関数は文字型の日付を日付型に変換するものです。
10行目は、提出日と文書IDから保存したファイルのパスを特定し、globでXBRLファイルを検索しています。
そして15行目が、前回作成したget_xbrl_data関数で、XBRLパーサーを使ってaccount_dfに記載されているデータを取得している部分になります。
次に、本質的な部分ではありませんが、作成したDataFrameはすべて行方向にデータが並んでいるため、以下でそれを扱いやすいように整形します。
def calc_fiscal_year(prior_year, asof):
return datetime.date(int(asof.year - prior_year), asof.month, asof.day)
dates = []
for i, account_name in enumerate(account_names):
df_sub = df.query(f'name == @account_name')[['prior_year', 'value']]
df_sub['fiscal_month'] = df_sub['prior_year'].apply(calc_fiscal_year, asof=period_yyyymm)
df_sub.drop('prior_year', axis=1, inplace=True)
df_sub['value'] = df_sub['value'].apply(cast_to_float)
df_sub['name'] = account_name.replace("_non_consolidated", "").replace("_summary", "")
if i == 0:
summary_df = df_sub.set_index(['name', 'fiscal_month']).unstack()
dates = [date for date in summary_df['value'].columns.values]
else:
summary_df = pd.concat([summary_df, df_sub.set_index(['name', 'fiscal_month']).unstack()])
summary_df
これにより、以下のようなsummary_dfというDataFrameができました(まだデータは下に続きます)。
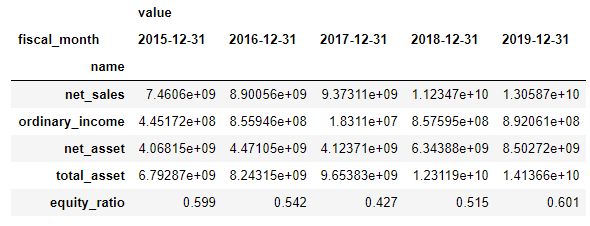
あと、表示したときに単位を決める関数を作っておきます。これがないとトヨタ自動車のような会社は非常に売上高が大きいので見にくくなってしまうためです。ここは皆さんが好きに工夫していただければと思います。
def adjust_decimals(values, unit):
min_value = values.min()
if min_value < 1e6: # 百万円以下(
return values / 1e3, f'千{unit}' # 千円
elif min_value < 1e12:
return values / 1e8, f'億{unit}' # 億円
else:
return values / 1e12, f'兆{unit}'# 兆円
Plotlyによる描画
ここからがPlotlyによる描画部分です。
Plotlyをインポートします。
import plotly.graph_objs as go
では、実際にグラフ表示するコードを作成します。
account_name = 'net_sales'
account_title = account_dict.get(account_name)
years = [to_fiscal_year(idx) for idx in summary_df['value'].columns]
values, digit = adjust_decimals(summary_df.loc[account_name, 'value'].values, unit='円')
texttemplate=[f'{value:0.1f}{digit}' for value in values]
data = [go.Bar(x=years,
y=values,
width=0.5,
text=texttemplate,
textfont=dict(color='#4169e1',
size=14),
textposition='outside',
name=title,
marker={'color': '#4169e1'},
)
]
layout = go.Layout(title=f'{title}の推移',
yaxis=dict(title=f'({digit})'))
fig = go.Figure(data, layout)
fig.show();
6行目まではデータの準備で、8行目から18行目がデータの作成、19行目と20行目がレイアウトの作成、21行目と22行目が図の表示になります。
6行目と11行目から13行目は、棒グラフの上に数値を表示するためです。
texttemplateに文字として表示する売上高の額を設定し、textfontは文字情報のフォントで辞書型で設定しています。
また、textpositionは文字情報の表示位置です。
これを実行すると売上高の推移を棒グラフでプロットすることができます。一番右のバーのようにカーソルを当てると金額等の情報が表示されます。
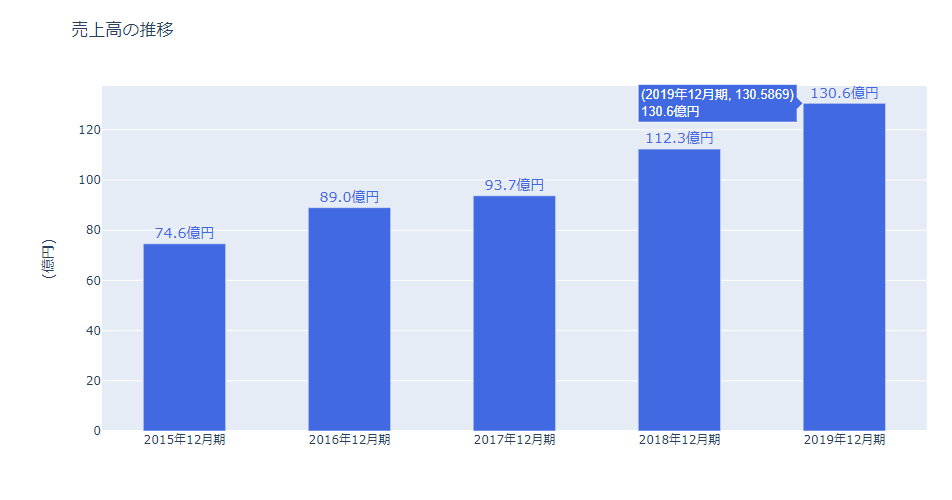
ふむふむ、最近はキャンプ人口が増えているので、売上高は順調に伸びているようですね、となります。
線グラフで可視化
続いて線グラフを描いてみましょう。
こちらもそれほど変わりません。
go.Barをgo.Scatterにすることで線グラフになります。
account_name = 'roe'
unit = '%'
account_title = account_dict.get(account_name)
# 事前準備
years = [to_fiscal_year(idx) for idx in summary_df['value'].columns]
if unit=='%':
values = summary_df.loc[account_name, 'value'].values * 100
digit = unit
elif unit=='円':
values, digit = adjust_decimals(
summary_df.loc[account_name, 'value'].values, unit)
elif unit=='人':
values, digit = adjust_decimals(
summary_df.loc[account_name, 'value'].values, unit)
texttemplate=[f'{value:0.1f}{digit}' for value in values]
# 線グラフ描画部分
data = [go.Scatter(x=years,
y=values,
name=digit,
mode='lines+markers+text',
textposition='middle center',
marker=dict(color=color,
size=size,
line=dict(width=2,
color='white'),
symbol='star'),
line=dict(dash='dash'),
textfont=dict(color='#FFFFFF'),
text=texttemplate,
yaxis='y2' # ← 2軸グラフ用
)
]
layout = go.Layout(title=f'{title}の推移',
yaxis=dict(title=f'({digit})'))
fig = go.Figure(data, layout)
fig.show();
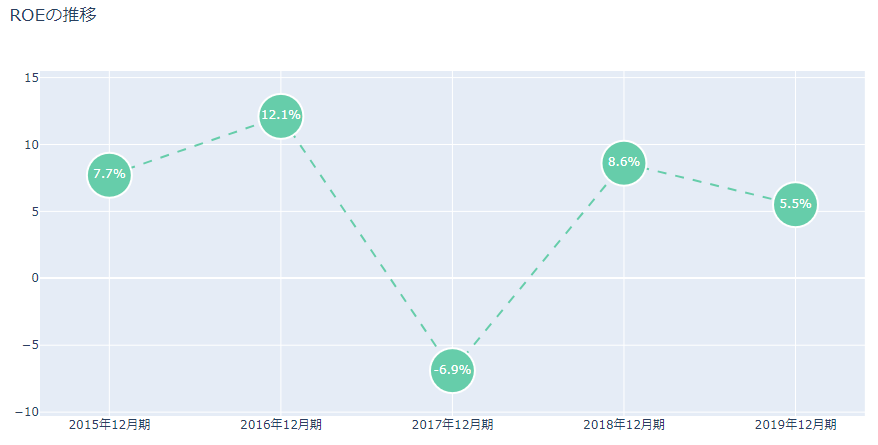
2017年12月期だけマイナスになっていますね。何かあったのだと思いますが、ここでは深入りはしません。
複数のデータをプロット
2つのデータをプロットするのも簡単です。
ここではtrace_1、trace_2という変数にそれぞれgo.Scatterで設定したデータを代入し、それをリストにして渡してやるだけです。
color='#66cdaa', size=45):
years = [to_fiscal_year(idx) for idx in summary_df['value'].columns]
values_1, digit_1 = summary_df.loc[account_name_1, 'value'].values, unit
values_2, digit_2 = summary_df.loc[account_name_2, 'value'].values, unit
values_1 = values_1 - values_2 # 総従業員数から臨時従業員数を引く
texttemplate_1 = [f'{value:0.0f}{digit_1}' for value in values_1]
texttemplate_2 = [f'{value:0.0f}{digit_2}' for value in values_2]
trace_1 = go.Scatter(x=years,
y=values_1,
name='正社員数',
mode='lines+markers+text',
textposition='middle center',
marker=dict(color=color,
size=size,
line=dict(width=2,
color='white'),
),
line=dict(dash='dash'),
textfont=dict(color='#FFFFFF'),
text=texttemplate_1,
)
trace_2 = go.Scatter(x=years,
y=values_2,
name='臨時従業員数',
mode='lines+markers+text',
textposition='middle center',
marker=dict(color='#ff69b4',
size=size,
line=dict(width=2,
color='white'),
symbol='diamond'),
line=dict(dash='dash'),
textfont=dict(color='#FFFFFF'),
text=texttemplate_2,
)
data = [trace_1, trace_2]
layout = go.Layout(title=f'{title}の推移',
yaxis=dict(title=f'({digit_1})'))
fig = go.Figure(data, layout)
fig.show();
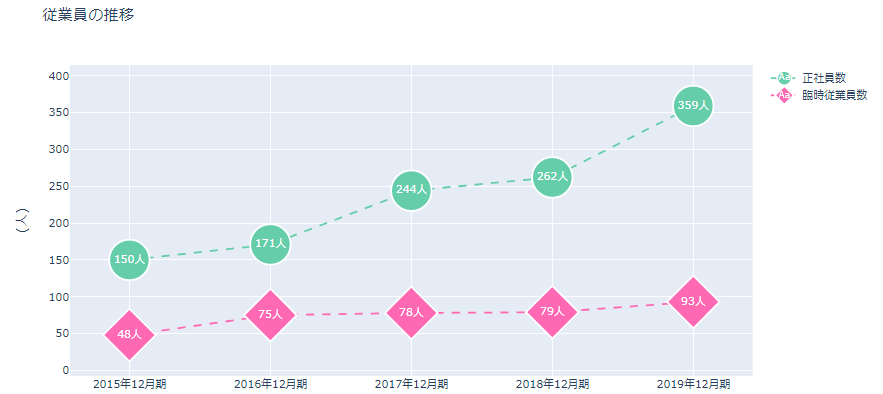
売上増加に伴い従業員も増えていますね。2019年は臨時社員数に比べて正社員数が大幅に増えています。
2軸のグラフで利益額と利益率を可視化
次に、最後に棒グラフと線グラフを一緒にプロットしましょう。
やることは、経常利益と経常利益率の推移を見ることです。
ただし、この場合、経常利益と経常利益率では水準が違うので、2軸のグラフにしてやる必要があります。
2軸のグラフは少し作業が増えます。
まず、1つ目のグラフに“yaxis='y1'”、2つめのグラフに“yaxis='y2'”として、どちらのy軸かを設定します。
years = [to_fiscal_year(idx) for idx in summary_df['value'].columns]
values, digit = adjust_decimals(
summary_df.loc[account_name, 'value'].values, unit='円')
texttemplate=[f'{value:0.1f}{digit}' for value in values]
trace1 = go.Bar(x=years,
y=values,
width=0.5,
text=texttemplate,
textfont=dict(color='#4169e1',
size=14),
textposition='outside',
name=title,
marker=dict(color='#4169e1'),
yaxis='y1' # ← 2軸グラフ用
)
per_sales = summary_df.loc[account_name, 'value'].values /
summary_df.loc['net_sales', 'value'].values * 100
texttemplate=[f'{value:0.1f}%' for value in per_sales]
trace2 = go.Scatter(x=years,
y=per_sales,
name='利益率(%)',
mode='lines+markers+text',
textposition='middle center',
marker=dict(color='#00bfff',
size=45,
line=dict(width=1,
color='white')),
line=dict(dash='dash'),
textfont=dict(color='#FFFFFF'),
text=texttemplate,
yaxis='y2' # ← 2軸グラフ用
)
data = [trace1, trace2]
そして、layoutにyaxis、yaxis2を設定するのですが、yaxisに“side='left'"、yaxis2に“side='right”を設定することで、1つ目の軸は左側ですよ、2つめの軸は右側ですよ、ということを教えてやります。
また、2つめの軸には“overlaying='y'”を設定することにより2軸グラフにし、“showgrid=False"とすることで目盛り線が重複しないようにします。
layout = go.Layout(title=title+'の推移',
yaxis=dict(side='left',
title=f'({digit})'),
yaxis2=dict(side='right',
overlaying='y',
showgrid=False,
title='(%)')
)
fig = go.Figure(data, layout)
fig.show();
その結果、以下のような図が描画されます。
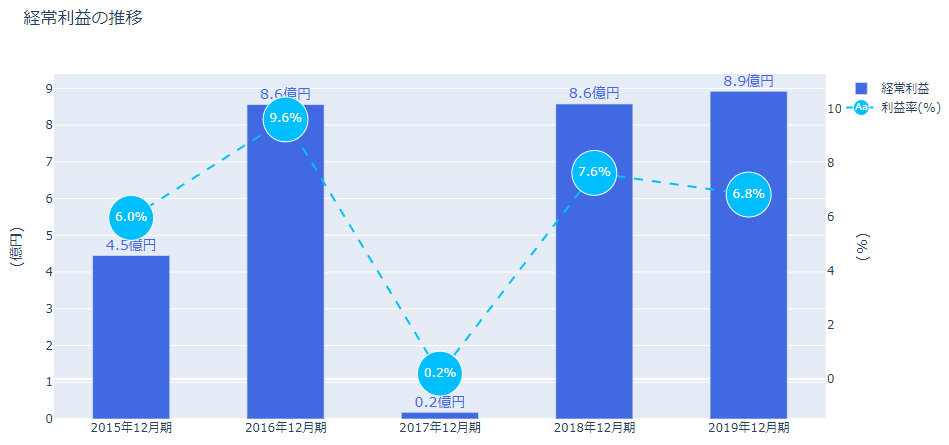
2017年12月期は何等かの理由で経常利益が落ち込んでいます。
そして、2019年12月期の売上高は増加していましたが、経常利益はそこまで増えておらず、経常利益率は下がっていることがわかりますね。
数値情報でわかることはこれぐらいですので、あとは気になったところがあれば分析者は有価証券報告書の文章を読んで原因を調べていくことになります。
もっと深い分析は今後やっていきたいと思います。
散布図
では、最後に散布図を描いてみましょう。
これはインタラクティブな可視化が活きるところだと思います。
ここでは、150社程度のデータを集め、横軸に売上高を縦軸に経常利益をプロットすることにより、売上高と経常利益の関係を確認します。
またこの際に、従業員数もわかるようにマーカーのサイズを指定します。
あまり実践的でなく、いい例ではないかもしれませんが、とりあえず今回はPlotlyの紹介ということでご容赦ください。
以下のように、go.Scatterでmodeに'markers'を指定するだけです。
data = go.Scatter(x=sales,
y=income,
mode='markers',
marker=dict(color='#b94047',
size=np.log(1+employees/10000)*30),
text=company_names
)
layout = go.Layout(title=f'売上高と経常利益(点の大きさは従業員数の多さを表す)',
xaxis=dict(title='売上高'),
yaxis=dict(title='経常利益'))
fig = go.Figure(data, layout)
fig.show();
#pyo.plot(fig)
あと、textに企業名を設定しており、これによりカーソルを当てると、企業名が表示されるようになります。
すると、以下のような散布図が表示されます。
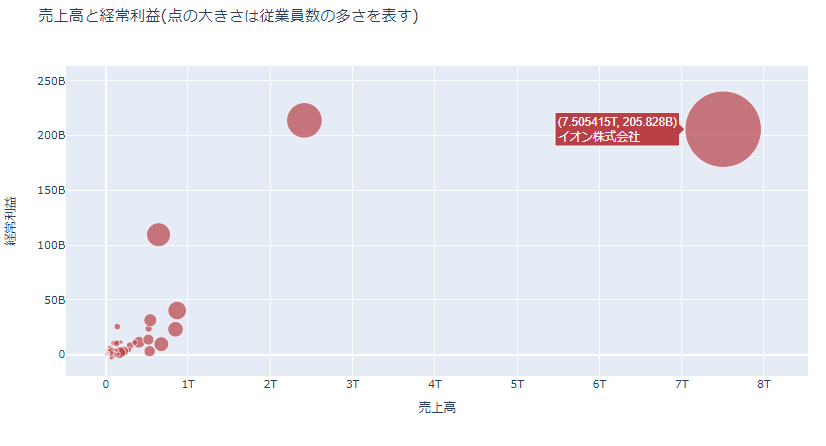
図を見ると、売上と経常利益の額には相関があり、従業員数とも相関がありそうだ、ということがわかります。(当然と言えば当然ですが)
右の大きな点は何者?ということでカーソルを当てると、日本を代表する小売企業であるイオンであることがわかります。
従業員も一番多く、売上、経常利益の額も大きいです。
さらに、左下には点がたくさんありますが、よく見えないので、そこを以下のようにマウスで選択します。
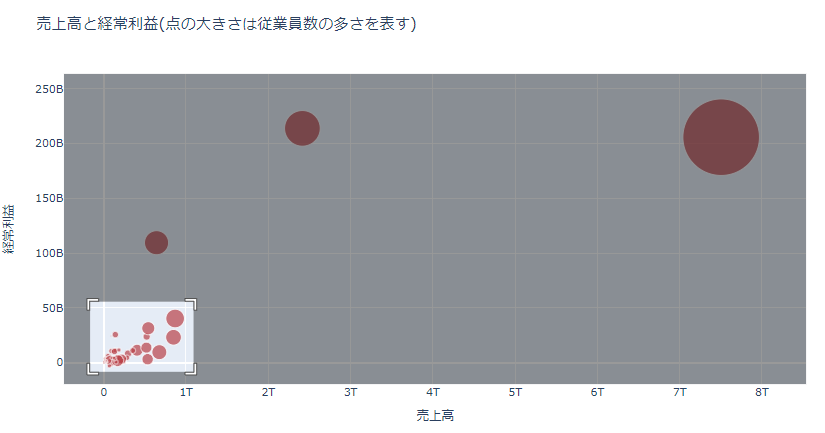
するとその部分が拡大されて表示されます。
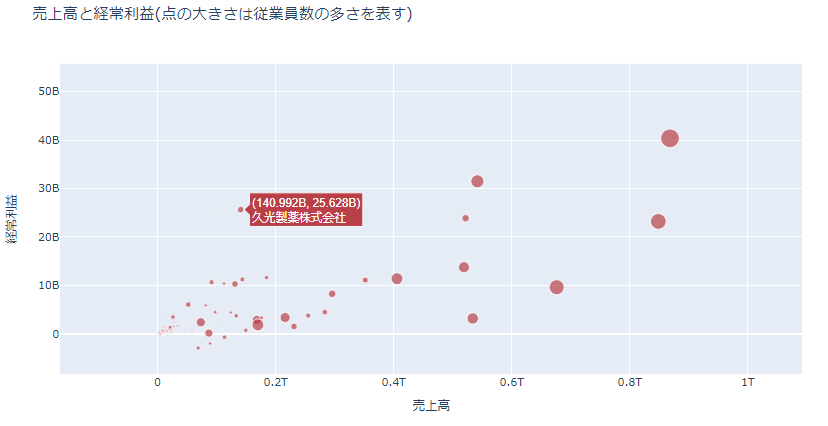
これで、見えなかった気になる部分も見ることができます。
例えば、売上は比較的小さいにもかかわらず、経常利益額が大きい点を見ると、サロンパスで有名な久光製薬ということがわかります。
(詳しくは知りませんが)きっとブランドとして利益率が高いのでしょう。
まとめ
今回はPlotlyを使ってインタラクティブな可視化をしました。
Matplotlibやseabornによる可視化もいいですが、インタラクティブな可視化をすることにより、よりデータの分析がしやすくなるのではないかと思います。
以下の記事では、基礎からもう少し詳細にplotlyの使い方について解説しています。
また、PlotlyやDashに関するUdemyの講座のレビューをこちらの記事でしています。
ご参考までにどうぞ!

今後は、Plotly社のダッシュボード作成用のパッケージであるDashを使って、企業を選ぶとダッシュボードが表示される仕組みを作成したいと思います。
では、また!