今回は、論文「Neural Machine Translation by Jointly Learning to Align and Translate」で提案され、そこから Transformer や BERT、GPT が発展していくきっかけとなった Attentionメカニズム について解説したいと思います。
Attention メカニズムは ChatGPT などの GPT シリーズの重要な仕組みでもある Transformer でも使われていますので、是非参考にしてみてください。
では早速見ていきましょう!
論文はこちらです。
『Neural Machine Translation by Jointly Learning to Align and Translate』
Attentionメカニズムとは
Attention メカニズムとは、もともと機械翻訳 (Machine Translation) のために提案されたモデルです。
日本語では注意機構と言われ、例えば、英語から日本語に翻訳する場合、どの英単語がどの日本語の単語に訳されているか?というのに注意しながら学習するモデルです。
もともと翻訳には以下のような Seq2Seq(Encoder-Decoder) と呼ばれる仕組みが一般的には使われていました。
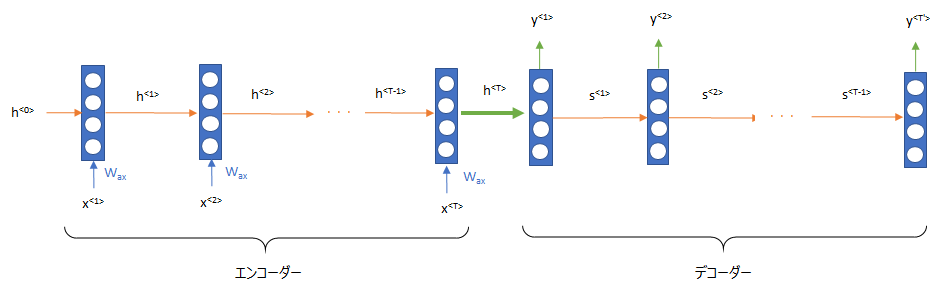
こちらでは、単語を LSTM(Long Short-Term Memory) などの RNN(Recurrent Neural Network; 再帰的ニューラルネットワーク) を使って順番に読み込み、その状態を次へと送っていきます。
そして、エンコーダの最後の状態をデコーダの初期状態として処理することで他の言語に翻訳していきます。
Seq2Seqのざっくりとした仕組み
- エンコーダでもとの言語 (英語 → 日本語なら英語) を処理し、内部的な変数にする
- エンコーダのアウトプットである内部的な変数をデコーダで別の言語に変換することで翻訳をする
ただ、ここには問題がありました。
LSTM はシンプルな RNN に比べて長期の依存関係を表現することができますが、それでも文章が長くなると長期の依存関係を取り込むことができないのです。
LSTM でも長い文章における長期の依存関係がうまく取り込めず、文章の最初の方の内容を忘れてしまう
そこで考えだされたのが Attentionメカニズム です。
つまり、Attention メカニズムとは、RNN が覚えきれない過去の情報を記憶にキャッシュするモデルであると言えます。
Attention メカニズムとは、文章が長くて RNN が覚えきれない過去の情報を記憶にキャッシュするモデル
また、非常に感覚的な説明をすると、例えば、“私は犬を2匹飼っていて、私の妹は猫を3匹飼っています” という文章を英訳する場合、 今まで文章全体をそのまま “I have two dogs and my sister has three cats” と訳すのに対して、Attentionメカニズムでは、"私" なので “I” だな、"犬" なので “dog” だけど"二匹の犬"とあるので “two dogs”、というように、単語と単語の関係に注意を向けながら学習し、推論するというものです。
では、どうやって?というのを以下で細かく見ていきたいと思います。
ご参考 - 参考書籍
こちらの本では、Python によりスクラッチで Attention メカニズムを実装していますので、参考になると思います。
ニューラル・ネットワークの基礎や RNN からしっかり説明されており、非常にわかりやすいのでオススメです。
時間のない人もすらすら読めると思いますので、一度目を通すだけでも良いと思います。
Attentionメカニズムの詳細
ここでは、論文をもとに、より詳細な仕組みを解説します。
論文では、言語を処理するモデルとして再帰的ニューラルネットワーク (RNN) の1つである GRU (Gated Reccurent Unit) を使っています。
また、文章を初めから後ろに向かってのみ処理する短方向ではなく、文章を後ろから前に向かって処理をする双方向 (Bidirectional) GRU を使っています。
再帰的ニューラルネットワークについては、こちらをご参照ください。

そして、 エンコーダー、デコーダーに双方向の GRU を使った Seq2Seq (Encoder-Decoder) モデルに attention をつけるという仕組みです。
ということで、エンコーダー、デコーダー、attention をそれぞれ詳しくみていきたいと思います。
Encoder
上記の記事で GRU について説明していますが、再度論文の式を用いて説明したいと思います。
まず、単語の埋め込み表現 (単語を意味を表す数値列に変換したもの) を \(x_1, x_2, \cdots, x_n\) とします。GRU はそれを使って、状態 \( \overrightarrow{h_i}\) の候補値である \( \overrightarrow{\underline{h_i}} \) を計算します。
$$\begin{align}
\overrightarrow{\underline{h_i}}=\tanh\left(\overrightarrow{W}e_i + \overrightarrow{U} \left[\overrightarrow{r}_i \circ \overrightarrow{h}_{i-1}\right]\right)
\end{align}$$
とします。
このときの \( \overrightarrow{r}_i \) はリセットゲート (reset gate) であり、
$$\begin{align}
\overrightarrow{r_i}=\sigma\left(\overrightarrow{W}_{r}e_i + \overrightarrow{U}_r \overrightarrow{h}_{i-1}\right)
\end{align}$$
で計算します。
そして、 状態の値をその候補値で置き換えるかどうかを決める更新ゲート (update gate) \( \overrightarrow{z}_i \) を
$$\begin{align}
\overrightarrow{z_i}=\sigma\left(\overrightarrow{W}_{z}e_i + \overrightarrow{U}_z \overrightarrow{h}_{i-1}\right)
\end{align}$$
で定義します。
あとは、前時点の状態と、置き換える状態の候補値、および更新ゲートを使って、次の時点の状態を計算します。
$$
\begin{align}
\overrightarrow{h_i}=\left(1- \overrightarrow{z_i} \right) \circ \overrightarrow{h}_{i-1} + \overrightarrow{z} _i \circ \overrightarrow{\underline{h_i}}
\end{align}
$$
これは順方向の仕組みですが、逆方向も読み込む順番が逆なだけで仕組みは全く同じです。
ですので、どうようの方法で、逆方向の状態 \(\left(\overleftarrow{h}_1, \overleftarrow{h}_2, \cdots, \overleftarrow{h}_T \right)\) を計算します。
そして、\( \overrightarrow{h}_i \) と \( \overleftarrow{h}_i \) を結合して、
$$h_i= \left[ \begin{array}{c}
\overrightarrow{h}_i \\
\overleftarrow{h}_i \
\end{array} \right] $$
をエンコーダーのアウトプットとします。
Decoder
デコーダーもエンコーダーと同様に Bidirectional GRU を使います。
\(i\) 時点の状態を以下の式で求めます。
エンコーダーと同じように前の時点 \(i-1\) での状態、状態の候補値を使います。
$$
\begin{align}
s_i=\left(1-z_i \right) \circ s_{i-1} + z _i \circ \tilde{s}_i
\end{align}
$$
そして、それぞれの値を
$$\begin{align}
\tilde{s}_i &=\tanh\left(We^y_i + U \left[r_i \circ s_{i-1}\right] + Cc_i\right), \\
z_i&=\sigma\left(W_z e^y_i + U_zs_{i-1} + C_zc_i\right) \\
r_i&=\sigma\left(W_r e^y_i + U_r s_{i-1} + C_rc_i\right)
\end{align}$$
で計算します。
ただし、デコーダーの初期状態 \(s_0\) はエンコーダーの値を使った \(\tanh\left(W_s \overleftarrow{h}_1\right)\) を設定します。
あと、\(c_i\) というのがありますが、これは context vector と呼ばれ、attentionメカニズムによって計算されます。
Attention
では、上記の context vector \(c_i\) を求めましょう。ここが attention メカニズムの肝です。
context vector は、すでに求めている元の文章 (source sentence) の状態 \(h_1, h_2, \cdots, h_n\) と \({i}\) 番目のターゲットとなる単語が利用する状態 \(s_{i-1}\) の関係を使います。
ここで、\(s_i\) ではなく \(s_{i-1}\) を使うのは、i番目の単語を求める際には \(s_{i-1}\) はまだ求まっていないからです。
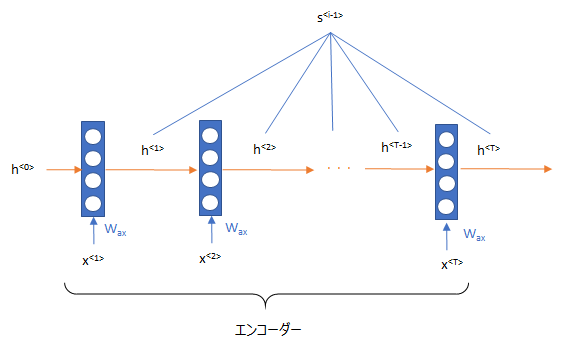
そして、これらの関係は小さなニューラルネットワークを使います。
まず、\(s_{i-1}\) と \(h_j\) を使って、
$$\begin{align}
e_{ij} = v_a^T\tanh\left(W_a s_{i-1}+U_ah_j\right)
\end{align}$$
を計算します。
そして、以下の式で attention weight を求めます。
\(e_{ik}\) の \(k\) を1からTまでを合計しているので、 \(h_{1}\) から \(h_{T}\) までを使っていることになります。
$$\alpha_{ij}=\frac{\exp(e_{ij})}{\sum^{T}_{k=1}\exp(e_{ik})}$$
この attention weight が論文でも見られる“注意を向けている場所”になります。
最後にこの attention weight に \(h_j\) を掛けて和を取ることで、エンコーダーの隠れ状態の加重平均を求めます。
$$c_i=\sum^T_{j=1}\alpha_{ij}h_j$$
これがデコーダーにインプットする context vector \(c_i\) です。
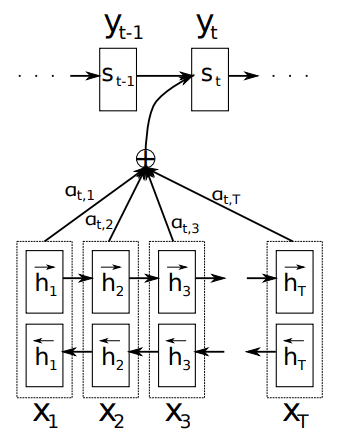
論文の図を使うとこのようになります。
\(h_j\) と \(\alpha_j\) を掛けてそれを合計したものを context vector \(c_i\) とし、\(s_t\), \(y_t\) の計算の際にインプットされています。
Attentionの可視化
論文では、単語を翻訳する際にどこに注意を向けているかを可視化しています。それがこちらです。
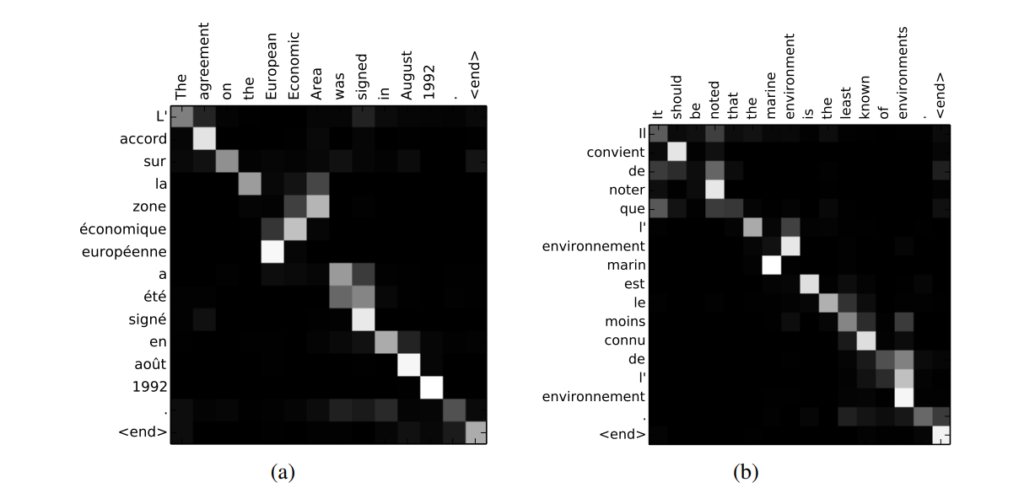
明るいところが atttention の大きなところです。
フランス語がわかりませんが (笑)、“signed” に “signe” が対応していたり、“environments” に “environnement” が対応していたり、うまく注意が向けられていることがわかりますね。
まとめ
今回は非常に重要な技術である attention について説明しました。
こちらの記事では実際のデータを使って、センチメント分析用の GRU + Attention モデルを構築しています。
どう作るか、どんな結果になるのかを見ていますので、是非ご覧ください!!

GPT などで有名な Transformer はこの Attention メカニズムを改良した Scaled Dot-Product Attention という仕組みを使っています。
こちらも参考にしていただければと思います。
