- 時系列のデータをうまく処理するモデル
- シンプルなRNNだと勾配消失という問題があり、長期の依存関係をうまく取り扱えない
- そこでLong Short-Term Memory(LSTM)やGated Recurrent Unit(GRU)というモデルが使われる
今回は再帰的ニューラル・ネットワークについて説明したいと思います。
なぜ再帰的ニューラル・ネットワークを使うことになったかということから説明しようと思います。
参考情報
こちらの本では、Pythonによりスクラッチで再帰的ニューラルネットワークを実装していますので、参考になると思います。
ニューラル・ネットワークの基礎からしっかり説明されており、非常にわかりやすいのでオススメです。
時間のない人もすらすら読めると思いますので、一度目を通すだけでも良いと思います。
もちろん、コードを真似して書いていくということをすれば、さらにしっかりマスターできます。
他にもUdemyなどのMOOCを使えば、短期間で楽にこの辺りまでの知識を得ることができると思いますので、こちらの記事も参考にしていただければと思います。

目次
ニューラル・ネットワークを用いた自然言語処理
もともと以下の論文で(再帰的でない)ニューラルネットワークを自然言語処理に適用しようと提案されていました。
http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
その論文で用いられていた図を借りると、以下のような仕組みです。シンプルに、インプットは単語IDでそれをLook-upテーブルで埋め込み表現に変換し、それをニューラルネットワークで処理するという形です。
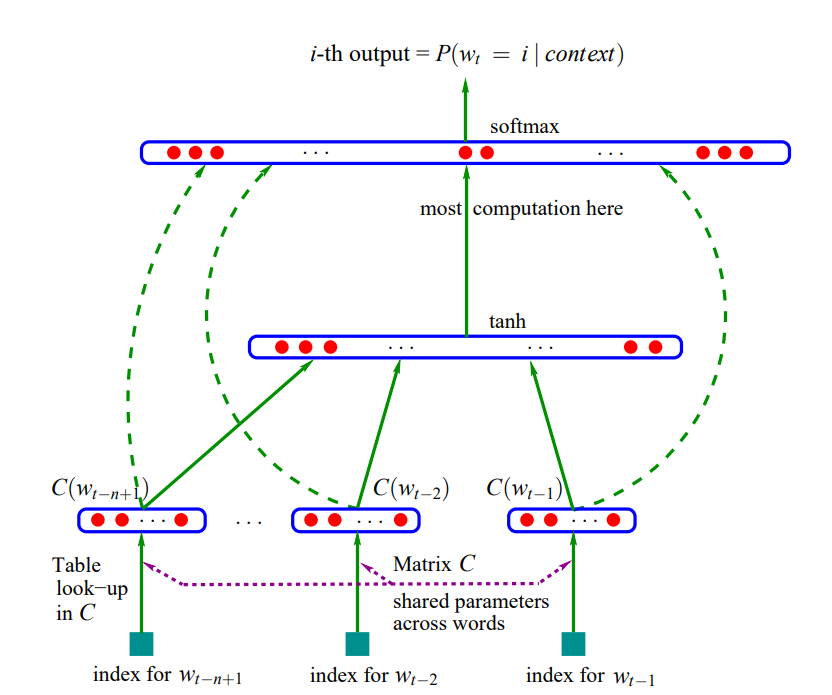
しかし、ここには以下のような2つの問題がありました。
- 文章はサンプルによって長さが違う。
- 自然言語では重要な単語の場所がサンプルによって違う 。
普通のニューラル・ネットワークだとある特定の場所の重みが大きくなったりしますが、それでは、違う場所にある重要な表現を捉えることができません。
再帰的ニューラル・ネットワークを使った自然言語処理
そこで、提案されたのが、時系列データを扱うためのRNNの利用です。
もともと、RNNは時系列のデータ処理を行うために利用されているモデルでしたが、それを自然言語処理の問題に応用できないか?ということで提案されたのがこちらの論文です。
https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf
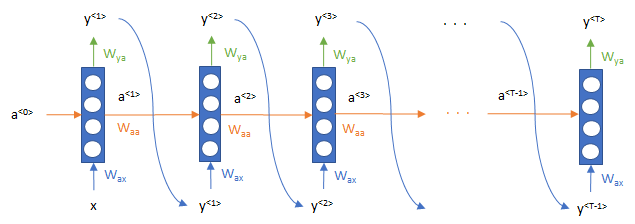
上記の論文とは表現方法が少々違いますが、一般的なRNNの仕組みは以下のようになっています。特徴的なのは、単語\(x^{<t>}\)をインプットして、そのニューロンが右に、つまり時系列方向に\(a\)が流れていっていることです。
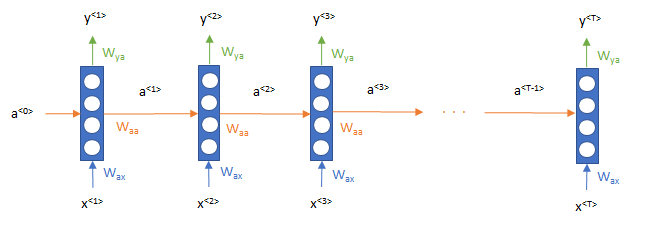
式で書くと、
$$a^{<t>}=g\left(W_{aa}a^{<t-1>}+W_{ax}x^{t}+b_a\right) $$
$$y^{<t>}=g\left(W_{ya}a^{<t>}+b_y \right)$$
となります。\(W\) はパラメータで、 \(W_{ax}\)は \(x\) から\(a\)を計算するためのパラメータ、\(W_{y_a}\)は\(a\)から\(y\)を計算するためのパラメータといった意味です。これらのパラメータは時点によって同じものを使います。\(g\)はシグモイド関数などの活性化関数を表します。
センチメント分析の場合は、\(y\)の途中結果は使わず、最後のアウトプットである\(y^{<T>}\)だけを使うことで可能です。
この仕組みにより、時間方向の流れを考慮することが可能になりました。
Long Short-Term Memory(LSTM), Gated Recurrent Unit(GRU)の出現
上記のシンプルなRNNは確かに、時系列のデータを処理できるため、単語の順番を考慮して処理ができました。しかしながら、シンプルなRNNには長期の依存関係が捉えられないという問題があります。
自然言語処理の文脈では、例えば、以下のような文章があったとしましょう。
“このキャンプ場は、トイレがきれい、お風呂もついている、スーパーも近い、薪も安い、スタッフの方々は親切、ということで非常に快適に過ごせます。”
こういった長文の場合、何が快適に過ごせるのか?がシンプルなRNNでは捉えきれません。このぐらいならも大丈夫かもしれませんが、もっと長文になると難しくなります。
その原因として、“勾配消失”、“勾配爆発”といった問題があります。ざっくり言うと、ニューラル・ネットワークの学習中に予測が外れた場合に、予測に合うようにパラメータを調整するのですが、どのぐらいパラメータを調整すればよいか?という情報が勾配です。
RNNの場合は、その勾配を一番最後の時点からどんどん前に遡って伝搬させていく必要があるのですが(これは誤差逆伝搬と呼ばれます)、 その勾配情報が途中でゼロに非常に近くなったり、あるいはすごく大きな数値になってしまったりしてしまいます。前者が“勾配消失”で後者が“勾配爆発”です。
どちらも問題なのですが、後者の“勾配爆発”は“勾配が一定以上大きくなったら、一定値で置き換える”というgradient clipという方法で一応は解決できますが、全社の“勾配消失”はそういった手法が使えません。
長くなりましたが、そこで出てきたのが、LSTMやGRUです。これらは、メモリーセルと呼ばれるセルを使って、勾配消失の問題を解消することで、長期の依存関係を捉えることを可能にします。
Simple Gated Recurrent Unit(GRU)
まずは、シンプルなGRUを考えてみます。図で描くと以下になります。
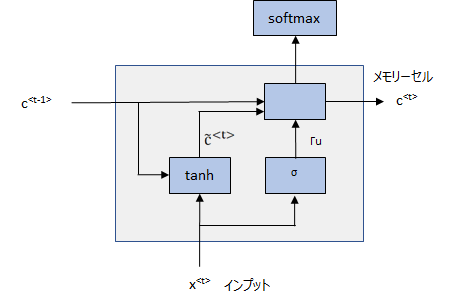
ポイントは、メモリーセルと呼ばれる変数\(c^{<t>}, t\in (1, T)\)を用意します。 そして、 前節のactivation \(a^{<t>}\)を\(c^{<t>}\)に対応させます。つまり、
$$a^{<t>}= c^{<t>} $$
とします。そして、\(c^{<t>}\) を後で置き換える候補となる\(\tilde{c}^{<t>} \)を
$$\tilde{c}^{<t>}=\tanh\left(W_{cc}c^{<t-1>}+W_{cx} x^{<t>} +b_c \right)$$
で定義します。
そして、“更新ゲート(Upgrade gate)”と呼ばれる
$$\Gamma_u=\sigma\left(W_{uc}c^{<t-1>}+W_{ux} x^{<t>} +b_u \right)$$
を導入します。この更新ゲートは0から1の間の値を取り、1であればメモリーセルを更新し、0であればメモリーセルを更新しないという役割を担います。具体的には、
$$c^{<t>}=\Gamma_u \times \tilde{c}^{<t>} +\left(1-\Gamma_u^{<t>}\right)\times c^{<t-1>} $$
という処理を行います。つまり、\( \Gamma_u =1\)であれば、
$$c^{<t>}=\tilde{c}^{<t>} $$
となり、メモリーセルの値を候補値で置き換えます。 \( \Gamma_u=0\)であれば、
$$c^{<t>}=c^{<t-1>} $$
となり、メモリーセルの値は前の時点のメモリーセルの値を更新せず、そのまま使います。こうすることで、勾配が消失しにくくなり、長期の依存関係を保持できる仕組みになっています。
Full Gated Recurrent Unit(GRU), Long Short-Term Memory(LSTM)
上ではシンプルにしたGRUについて見てきました。ここでは、一般的に使われているGRUとLSTMについて見ていきたいと思います。とはいえ、考え方はほぼ同じなのでさらっと解説します。
Full GRU
Full GRUは以下のように定式化されます。Simple GRUに\(\Gamma_r\)が付け加わっています。これは“リセットゲート(Resest gate)”と呼ばれ、メモリーセルを更新する候補値を決める際に、前時点のメモリーセルの値\(c^{<t-1>}\)をどれだけ使うかを決めるものです。1であれば\( c^{<t-1>}\)の値をフルで使い、0であれば全く使いません。
$$\begin{align}
\tilde{c}^{<t>}&=\tanh\left(W_{cc}\left(\Gamma_r\times c^{<t-1>}\right)+W_{cx} x^{<t>} +b_c \right)\\
\Gamma_u&=\sigma\left(W_{uc}c^{<t-1>}+W_{ux} x^{<t>} +b_u \right)\\
\Gamma_r&=\sigma\left(W_{rc}c^{<t-1>}+W_{rx} x^{<t>} +b_r \right)\\
c^{<t>}&=\Gamma_u \times \tilde{c}^{<t>} +\left(1-\Gamma_u\right)\times c^{<t-1>}
\end{align}
$$
LSTM
LSTMは複数のバージョンがあり、図もたくさんあってややこしいのですが、一例はこちらです。
$$\begin{align}
\tilde{c}^{<t>}&=\tanh\left(W_{cc}\left(\Gamma_r\times c^{<t-1>}\right)+W_{cx} x^{<t>} +b_c \right)\\
\Gamma_u&=\sigma\left(W_{uc}c^{<t-1>}+W_{ux} x^{<t>} +b_u \right) \hspace{10pt} \text{(Update)} \\
\Gamma_f&=\sigma\left(W_{fc}c^{<t-1>}+W_{fx} x^{<t>} +b_f \right) \hspace{10pt} \text{(Forget)} \\
\Gamma_o&=\sigma\left(W_{oc}c^{<t-1>}+W_{ox} x^{<t>} +b_r \right) \hspace{10pt} \text{(Output)} \\
c^{<t>}&=\Gamma_u\times \tilde{c}^{<t>} +\Gamma_f\times c^{<t-1>} \\
y^{<t>}&=\Gamma_o\times \tanh\left(c^{<t>}\right)
\end{align}$$
LSTMでは、“更新ゲート(Update gate)”、“忘却ゲート(Forget gate)”、“出力ゲート(Output gate)”を使用します。更新ゲートはGRUと同じで、忘却ゲートは次の時点のメモリーセルの値を決める際に\(c^{<t-1>}\)の値をどれだけ使うか、つまり、どれだけ覚えてどれだけ忘れるかを決めます。GRUの場合はこれが \(1-\Gamma_u\) となっていましたので、LSTMの方が自由度が若干高くなります。
そして、最後に\(y^{T}\)をsoftmax関数などに入れて分類します。
RNNの適用方法
では、最後に簡単にRNNの各タスクへの適用方法を見ていきましょう。
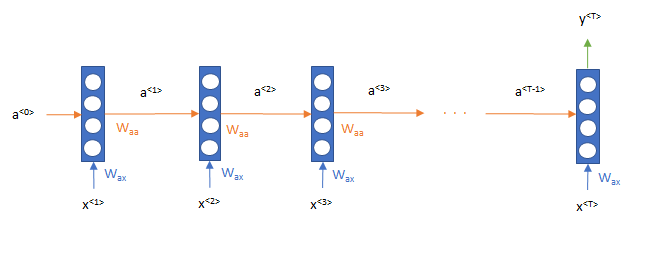
テキスト分類、センチメント分析では以下のようになります。途中のアウトプットは使わず、最後のT時点のアウトプットを使って分類します。
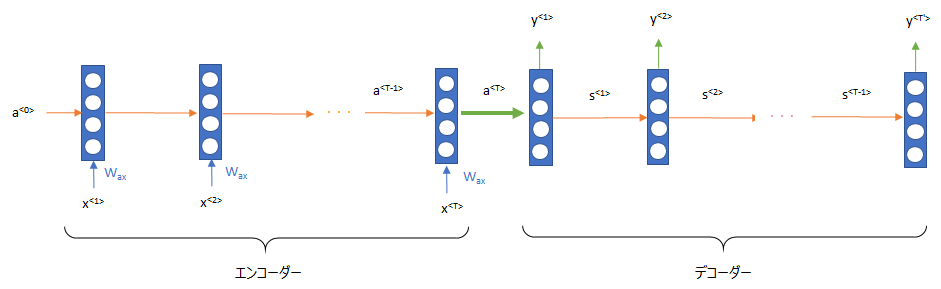
翻訳では、Sequence-to-Sequence(Seq2Se1, Encoder-Decoder)という仕組みを使います。2つのRNNを用意して、エンコーダーと呼ばれる初めのRNNを使用して、文章の埋め込み表現を生成します。そして、その埋め込み表現をデコーダーと呼ばれるもうひとつのRNNを利用して、他の言語に変換します。
文章生成では以下のような仕組みになります。各時点のアウトプットを次の時点のインプットにして、次々と単語を出力していきます。
まとめ
如何でしたでしょうか?LSTMは若干仕組みが複雑ですが、考え方はSimple GRUと同じだと思います。他にもLSTMには“覗き穴結合(Peephole connection)”と呼ばれる仕組みを導入したり、色々な工夫をされたバージョンがあります。
GRUとLSTMどちらが良いというのはなく、GRUはLSTMよりシンプルなのでモデルのサイズを大きくできるというメリットがあり、LSTMはより複雑な構造を持つので、より表現力が高いというメリットがあります。どちらが良いかは問題によって違ってくるので、両方を理解して試してみるというのが良いかと思います。
冒頭でもお話ししましたが、このあたりの基礎的な内容を理解するには、MOOCを使ったオンライン学習が最適だと考えています。
ですので、以下の記事も参考にしていただき、効率的に知識を習得していただければと思います。
