今回は自然言語処理で一つのブレイクスルーとなったBERTについて解説したいと思います。
現時点で、BERTは極めて重要なモデルですので是非しっかり理解していただければと思います。
もちろん新しい仕組みはありますが、基本的には今まで見たTransformerと事前学習-ファインチューニングについて理解していれば、それほど理解は難しくありません。
BERTで使われた主な新しい仕組みは以下の2つです。
- Masked Language Model
- Next Sentence Prediction
BERTとは“Bidirectional Encoder Representations from Transormers”の略で、その名の通り、双方向(Bidirectional)なTransformer を使ったエンコーダーという大きな特徴があります。
そして、Transformerを双方向にするために“Masked Language Model”という仕組みを導入しています。
双方向って何?というのは後程ご説明します。
これと、“Next Sentence Prediction”という次の文章(パラグラフ)かどうかを予測するタスクを事前学習に取り入れることにより、多くのタスクでSoTAを達成したのです(その後、実はNext Sentence Predictionはそれほど有効ではないという結果も多く出てきます)。
- モデルはTransformerで、
- 大規模なデータセットを使って
- “Masked Language Model”、“Next Sentence Prediction”という事前学習を行う
ことにより、かつてない精度を達成したもモデルと言えます。
このBERTが起点となり、ALBERTやRoBERTaといったBERTの改良モデルが提案されています。
また、その仕組みであるMasked Language Model、Next Sentence Predictionを改良することにより、BERTを超えるモデルも出てきています。
以下の記事では、公開されている日本語版BERTの事前学習モデルを使って、Hugging FaceのTransformersで文書分類(センチメント分析)していますので、こちらも見ていただければと思います。

ご参考 - 参考書籍
BERTを理解する、使えるようになるには以下の本がオススメです。
Hugging FaceのTransformersで日本語版BERTを動かし、センチメント分析や固有表現抽出など色々なタスクを解説してくれています。
以下の本ではPyTorchを使ってTransformerとBERTのモデル部分を実装していますので、真似をしながら自分の手で実装することで、BERTをしっかりと理解することができると思います。
自然言語処理については最後の方の一部だけですが、逆に言うと画像認識などの勉強もできて非常に参考になります。
目次
BERTとは
BERTのモデルは、基本的にはOpenAIのGPTと同じで、ベースはTransformerで、それに事前学習-ファインチューニングのプロセスを経たものです。
GPTは以下の記事でも説明していますが、Transformerに対して、大きなラベルなしコーパスで事前学習し、ターゲットタスクのコーパスでファインチューニングするというものでした。

まずは、事前学習フェーズで、Wikipediaなどのラベルのない言語コーパスで言語モデルを学習します。
ラベルが不要ですので、たくさんのデータを取得することができるため、この巨大な言語コーパスを使うことで非常に大きなモデルの学習が可能です。
特にTransformerはLSTMなどよりも計算速度が速いため、より大きなモデルの学習が可能です。
さらにTransformerはLSTMのように前から後ろ(もしくは後ろから前)に情報が流れるといった仮定もなく、Self-Attentionのみを使った非常に柔軟な仕組みであるため、巨大な学習データによりその柔軟なモデルをフルで学習できるという利点があります。
BERTはその利点を使って、巨大なコーパスで巨大なモデルを事前学習することでこれにより、言語の構造や単語の意味などを学習します。
そして、ファインチューニング・フェーズでは、事前学習したパラメータを初期値として、解きたいタスクのラベル付きデータで学習します。
例えば、センチメント分析であれば「店員さんの対応がとても親切でした!」という文章と“Positive”というようなラベルをセットで用意します。
そしてそのような組を数千(もしくは数百)から数万単位で用意し、BERTのパラメータをチューニングします。
すると、今までのようなBag-of-WordsやLSTMを使った教師あり学習のみのモデルよりも良い精度を達成することができます。
これがOpenAIのGPTと同じ部分の大まかな流れです。
BERTでは、さらにこの仕組みを若干改良しています。
ひとつは、もともとのTransformerは文章を前から読むだけ、というところです。
Transformerの記事で説明しましたが、Transformerは次の単語を予測する際に、Masked Multi-Head Attentionという仕組みで、先の単語を見ないようにしていました。
しかしながら、文章は前向きだけでなく後ろ向きにも読んだ方がよく理解できるので、それを実現しようとします。
これが“Masked Language Model(MLM)”です。
BERTと同じでTransformerを採用しているOpenAIのGPTは以下の図のように過去の単語の位置のみにattention weightを付けるので、文章を一方向にしか読みません。
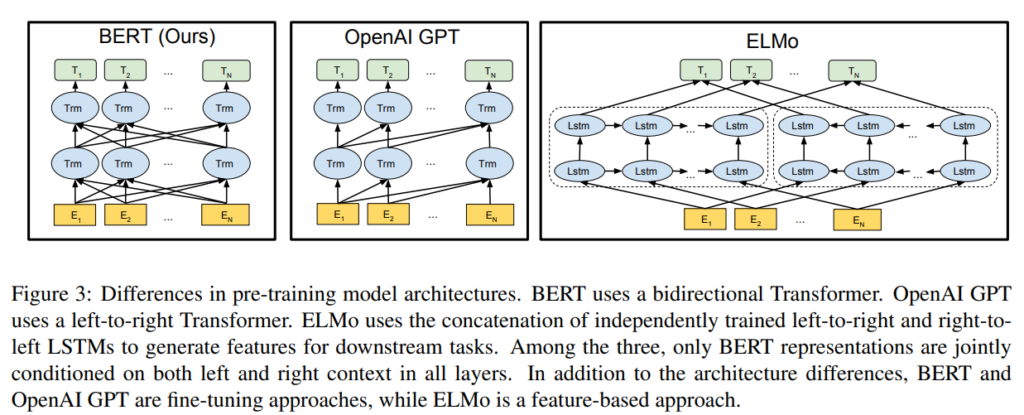
一方で、ELMoは前向きのLSTM、つまり過去の単語から次の単語を予測するのと、後ろ向きのLSTM、先の単語列から前の単語を予測するのを、それぞれ事前学習していますので双方向といえます。
しかしながら、ELMoは前向きと後ろ向きをそれぞれ別で計算していて、それらのアウトプットを結合するということをしていますので、浅い双方向と言われます。
BERTでは前向きと後ろ向きを同時に行います。
そして、もう一つが、 “Next Sentence Prediction(NSP)”です
Next Sentence Predictionは、事前学習フェーズに単語を予測するだけでなく、2つの文章をインプットとして、2つ目の文章は、1つ目の文章の次の文章か?という問題を解かせることにより、単語だけではなく、文章のつながりを学習することができ、より言語を理解させるというものです。
さてそれでは、モデルの詳細をこれから見ていきたいと思います。
その前に、なぜ双方向の方が良いのかを、XLNetの論文にある例で説明したいと思います。
なぜ双方向か?
XLNetの論文では以下のQuestion-Answeringが例として挙げられています。
以下の質問があったとします (昔Radioheadのファンだったので敢えてここで使わせてもらいます) 。
質問: Who is the singer of Radiohead?(レディオヘッドのボーカルは誰ですか?)
それに対して、以下の文章から答えの部分をstartタグとendタグで囲みます。
以下の文章があれば、Thom Yorkが答えだとわかります。
答えを含む文章1:The singer of Radiohead is Thom York. (レディオヘッドのボーカルはトム・ヨークです。)
しかしながら、以下の文章の場合、答えが前に出てきているので、文章を前から読むだけでは答えることができず、一旦前の情報に戻らないと答えられません。
答えを含む文章2:Thom York is the singer of Radiohead.(トム・ヨークはレディオヘッドのボーカルです。)
したがって、文章は双方向で読む必要があるということです。
BERTの仕組み
事前学習-ファインチューニング
BERTでは、OpenAI GPTなどのように、事前学習-ファインチューニングを行います。
事前学習では、下図の左側のように、Masked Language Model(Mask LM)とNext Sentence Prediction(NSP)を学習し、そのパラメータをファインチューニング時の初期値にします。
タスクごとに分類やQuestion-Anwerなどモデルは異なりますが、パラメータの初期値はすべて共通のものを使ってファインチューニングを行いますです。
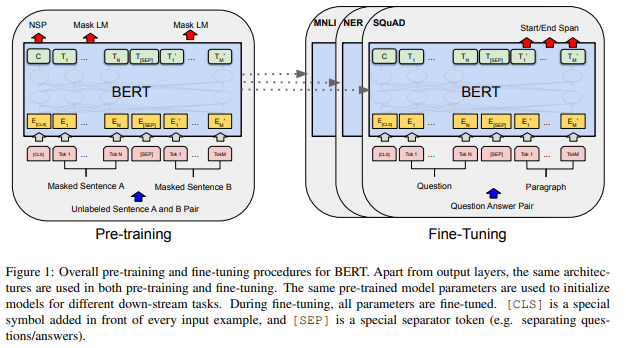
モデル構造
BERTは基本的にはTransformerの仕組みを使います。
Transformer blockを\(L\)個、隠れ層の次元を\(H\)、Attentionのhead数を\(A\)とすると、\(\text{BERT}_\text{BASE}\)は、\(L=12, H=768, A=12\)の合計110Mパラメータ、\(\text{BERT}_\text{LARGE}\)は、\(L=24, H=1024, A=16\)の合計340Mパラメータとします。
Transformerについては、以下の投稿を参考にしてください。

モデルはTransformerやOpenAI GPTを理解していれば、ほぼそのままですのでそれほど難しくないと思います。
インプットはタスクごとに違うので工夫をしてやる必要があります。
例えば、センチメント分析であれば、1つの文章もしくはパラグラフがインプットですが、Question-Answeringなどでは、文章のペアがインプットになります。
そこで、まずすべての単語列の始まりは、“[CLS]”という特別な単語を設定します。
そして、分類問題では、この単語に位置に対応する隠れ層の値(ベクトル)を分類に使用します。
Transformerによる分類問題の記事で使った方法と同じです。
Question-Answeringなど文章(パラグラフ)が2つの場合、文章と文章の間に“[SEP]”という単語を入れてやります。
これにより、モデルは文章がここで別れているということを認識させます。
ここでは、[CLS]の位置に対応する最後の隠れ層のベクトルを\(C\in\mathbb{R}^H\)とし、\(i\)番目のインプット単語に対する最後の隠れ層のベクトルを \(T_i\in\mathbb{R}^H\)とします。
もともとのTransformerでは、インプットは単語の埋め込み表現にsinを使ったpositional embeddingを加えることにより位置情報を考慮した埋め込み表現としていましたが、BERTでは、下の図の通り、単語の埋め込み表現にpositional embeddingとsegment embeddingを足したものになります。
segment embeddingは、例えば、1つ目の文章であればすべて0、2つ目の文章であればすべて1といった感じです。
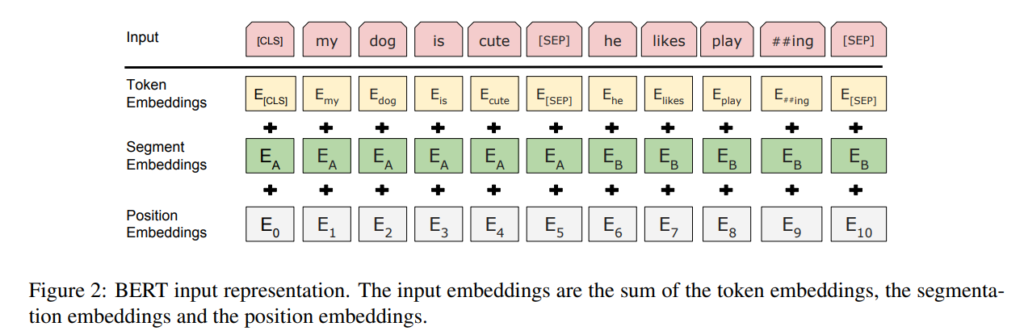
事前学習
BERTの事前学習ですが、ここが一番のポイントになります。
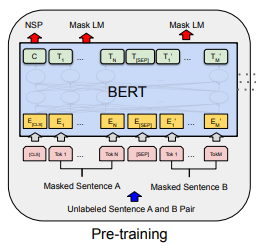
BERTでは、今までのような次の単語を当てるような言語モデルの事前学習ではなく、マスクをした部分の単語を予測するというタスクを解きます。
それがMaked Language Modelです。
また、2つの文章がつながっているか、つながっていないかを当てるタスクも解くことにより、より良い言語モデルを習得させようというものです。
それがNext Sentence Prediction(NSP)です。
事前学習のタスク
Masked LM
TransformerベースのOpenAI GPTでは、事前学習時の文章を読む方向は前に向かってのみでした。
つまり、過去の単語列をもとに次の単語を求めるというものでした。
これをBERTでは、前向きだけでなく後ろ向きにも学習させるようにします。
それががMasked Language Modelです。
その仕組みは、次の単語を予測するのではなく、単語列のうち何パーセントかの単語にマスクをかけ、そのマスクの部分を当てるというタスクに変えるのです。
例えば、15%ををランダムに選び、それらにマスクをします。具体的には、それらの単語を[MASK]に置き換えます。
ただし、単純に15%すべてを[ MASK ]に置き換えるのではなく、選んだ15%のうち
- 80%は[MASK]に置き換える
- 10%はランダムな単語に置き換える
- 10%は置き換えない
とします。
論文だと以下のように「my dog is hairy」の場合で示しています。単語「hairy」がマスクの対象なのですが、1つめは[MASK]に、2つめは「apple」に、3つめは変えない場合です。

なぜこういうことをするかというと、[MASK]という単語は事前学習だけで使われ、ファインチューニングには出てこないので、事前学習とファインチューニング間でミスマッチが生じます(これはXLNetでも指摘されています)。
その影響を低減するためとのことです。
また、これらの割合については、論文のAppendixのC.2で検証されています。
Masked LMでは、文章の15%の単語しか予測しないため、順番にすべての単語を予測する従来の手法と比べて時間がかかります。
ただし、その分精度は向上し、1度事前学習しておけばよいだけなので、事前学習に時間をかけて精度の高い言語モデルを学習することのメリットは大きいと考えられます。
Next Sentence Prediction(NSP)
Qusetion AnsweringやNatural Language Inferenceでは、2つの文の関係を理解する必要があります。
そこで、2つの文章をインプットして、それらが連続した文章かそうでないかを予測します。
文章Aと文章Bがあり、文章Bの50%は 実際に文章Aの後に続くの文章で、50%は他の文章からとってきます。
上の図1の一番左の[CLS]の単語位置に対応する隠れ層のベクトル\(C\)をNSPの予測に使います。
以下は論文の例です。InputとLabelが2組あり、Inputはマスクされながら、[SEP]で区切られています。
1つ目の例は2つの文章が連続している場合で、Labelが“IsNext”になっています。
2つ目の例は連続していない別の文章から取ってきたもので、Labelが“NotNext”になっています。
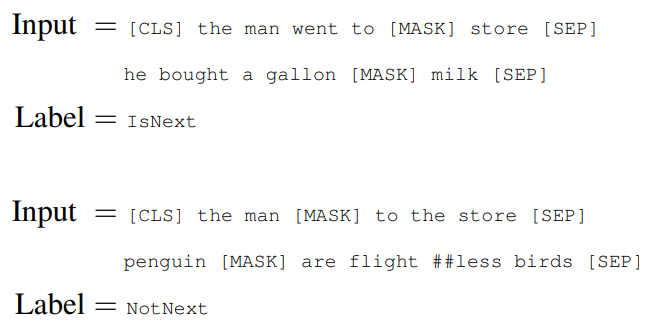
事前学習の詳細
データ
BERTでは、事前学習にBooksCorpusと英語のWikipediaを使っています。
RoBERTaなど、のちの論文に出てきますが、事前学習用のデータをさらに増やすことで、精度を上げられることがわかっています。
単語の分割にはWordPieceを使っています。
設定
バッチサイズを256とし、1つのサンプルは最大512単語です。
これで40エポック、1,000,000ステップ回します。
オプティマイザーはAdamで、学習率が1e-4、\(\beta_1=0.9, \beta_2=0.999\)としています。
0.01のL2正則化を行い、最初の10,000ステップはウォームアップ期間で、その後、線形に減少させていきます。
すべてのレイヤーでドロップアウトを行い、ドロップアウト率は0.1です。(ドロップアウトについてはこちら)
活性化関数は、OpenAI GPTと同様にGELUを使っています。
$$\begin{align}
\text{GELU}(x)&=x\Phi(x)\\
&\sim0.5x\left(1+\tanh\left[\sqrt{2/\pi}\left(x+0.044715x^3\right)\right]\right)
\end{align}$$
GELUを少し詳しく知りたい方はこちらをご参照ください。

また、損失関数は、Masked LMの尤度とNSPの尤度の合計を使います。
ファインチューニング
ファインチューニングは特に変わったところはありません。
事前学習で得られたパラメータを初期値として、各タスクごとのレイヤーを上につけて、ラベル付きデータで学習を行います。
ULMFiTなどであったlayer unfreezingなどのテクニックは使われておらず、シンプルにすべてのレイヤーを同時に学習します。
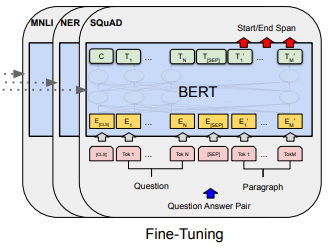
インプットは、サンプルの最初の部分に[CLS]をつけ、2つの文章が必要なタスクは、文章と文章の間に[SEP]を挟みます。
センチメント分析などでは、[CLS]の位置に対応する箇所の隠れ層のベクトルを用いて分類します。
以下の図が各タスクにおけるファインチューニング時のインプットとアウトプットです。
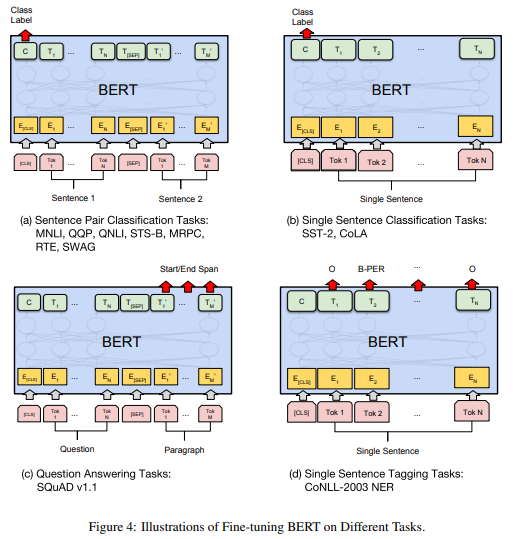
また、ドロップアウト率を0.1としていて、それ以外のハイパーパラメータはタスクによって設定を変えています。
バッチサイズは16もしくは32、オプティマイザーはAdamで学習率は5e-5、3e-5、2e-5、エポック数は2-4回となっています。
実験結果
では、上記のモデルで学習した結果です。他にもありますが、ここではGLUEベンチマークの結果だけ紹介します。
何とすべてのタスクでSoTAを達成しています。しかも、上昇幅もかなり大きいです。
平均では、ELMoと比べて11.1%、OpenAI GPTと比べて7.0%も上昇しています。
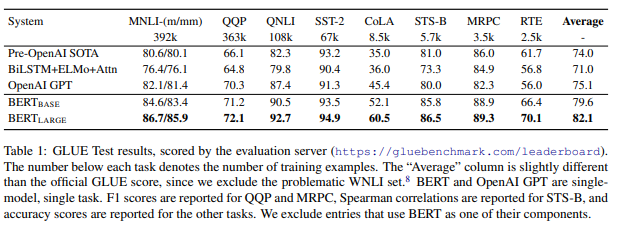
BERTとOpenAI GPTはモデルの仕組みはほぼ同じなので、事前学習の方法によりこれだけ差が出ていると考えられます。
その他
事前学習の効果
ここでは、“Next Sentence Prediction”と“Masked LM”を使うことによる双方向モデルにする効果を検証しています。具体的には以下の2パターンで、精度を見ていきます。ベースは\(\text{BERT}_\text{BASE}\)です。
- Next Sentence Prediction(NSP)を行わない:No NSP
- “Masked LM”を使わないで片方向(Left-to-Right)のみにする:LTR & No NSP
結果はこちらです。
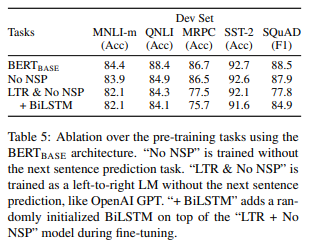
まず、No NSPにすると、SST-2データセットではほとんど変わりませんが、MNLI、QNLI、SQuADデータセットでは大きく精度が低下しています。
これらのデータセットは2つの文章の関連性を予測するタスクであり、SST-2はセンチメント分析タスクです。
したがって、(MRPCは置いておいて)2つの文章の関連性を予測するタスクではNSPは有効であることが示唆されていると思います。
次に双方向にする効果を見てみます。
LTR & No NSPでは、MRPC、SQuADデータセットが大きく低下しています。
さらに双方向の効果を見るために、最後のTransformer blockの上にBiLSTMレイヤーを加え、双方向にしたものと比較しています。
その結果、SQuADデータセットではLTR & No NSPと比べて精度が大きく改善しています。
これはELMoのような考え方ですが、BiLSTMでは2倍計算が必要、Question-Answeringでは解釈が難しい、双方向なのは一番上の層だけなのでBERTのような双方向に比べて表現力が小さいといったデメリットが挙げられています。
モデルサイズ
ここでは、モデルのサイズを大きくした場合の振る舞いを検証しています。
レイヤー数\(L\)、隠れ層の次元\(H\)、Head数\(A\)を変えた場合のDevセットの精度が以下です。
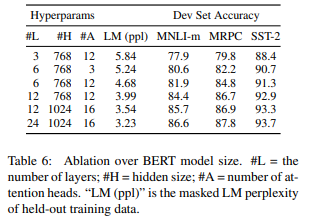
基本的に上から下に行くほどモデルサイズが大きくなりますが、モデルサイズが大きいほど言語モデルのパープレキシティ(LM(ppl))が下がり、各タスクの精度も向上しています。
MRPCのような小さなデータセット(学習用サンプルが3,600個)でもモデルを大きくした方が精度が改善しておりいます。
つまり、事前学習により言語モデルを高い精度で学習することにより、 下流のタスクが小さなデータセットであってもで精度向上が見込まれるということがわかります。
モデルのサイズについては、ALBERTの論文でさらに検証されています。

まとめ
今回は、近年のNLPにおけるブレイクスルーとなったBERTを見てみました。
新聞でもBERTの話が出たり、いろんなところで「BERTを使った…」という言葉を聞きますが、やはり論文をしっかりと読んだほうが何がすごいかとかがわかって良いですね。
また今度、実装の方も試してみたいと思います。