さて、今回はHugginFaceのTransformersとBERT日本語モデルを使ってセンチメント分析をしたいと思います。
BERTを使ったセンチメント分析は以前こちらの記事でしましたが、今ではTransformersという非常に便利なライブラリが使えますので、そちらを使ってセンチメント分析をしたいと思います。
TransformersとBERT日本語モデルを使ったセンチメント分析は色々なサイトや本で紹介されていますが、実務でもBERTはよく使っているので改めてここでまとめておこうと思います。
また、今回は単純なファインチューニングだけですが、次回は事前学習や既存の事前学習モデルを追加で学習する方法を見ていきたいと思います。
BERTの仕組みはこちらの記事で解説していますので参考にしていただければと思います。

なお、このの記事はこちらの本を参考にしています。
『BERTによる自然言語処理入門: Transformersを使った実践プログラミング』
センチメント分析だけではなく色々なタスクについても詳しく解説されていますので、ご興味がある方は手に取っていただければと思います。
実務でもすごく使えますので非常にオススメです!
では見ていきましょう。
前準備
Google Colabを使う前提で解説していきたいと思います。
ライブラリのインストール
まずは必要なライブラリをインストールします。
今回は以下のライブラリを使います。
- transformers
Huggin Faceが提供する様々な事前学習モデルを簡単に使えるAPIを提供するライブラリ - fugashi
形態素解析用のソフトウェアであるMeCabのラッパー - ipadic
MeCabで利用している辞書であるIPA辞書(IPAdic) - pytorch-lightning
PyTorchを使ったディープラーニング・モデルの学習を簡単にするフレームワーク
Google Colab上で以下のコマンドを実行することで上記のライブラリをまとめてインストールすることができます。
!pip install transformers fugashi ipadic pytorch-lightning
インポート
続いてモジュール等をインポートしましょう。
PyTorchを使うのでtorchとDataLoaderをインポートします。
import torch from torch.utils.data import DataLoader
そして、transformersから日本語BERTのトークナイザであるBertJapaneseTokenizerと文章分類モデルのBertForSequenceClassificationをインポートします。
from transformers import BertJapaneseTokenizer, BertForSequenceClassification
ファインチューニングはPyTorch-Ligntningを使うのでpytorch_lightningをplとしてインポートします。
import pytorch_lightning as pl
最後にデータを扱うためにpandasと補助的にtqdmをインポートしておきます。
import pandas as pd from tqdm import tqdm
データの準備
ここからは、データファイルを読み込み、モデル学習時に必要なDataLoaderを作成します。
Google Colabを使っている方は、ドライブをマウントする必要がありますので、以下のようにマウントしましょう。
from google.colab import drive
drive.mount('/content/drive')
データの読み込み
以下のようにしてPandasのread_csvなどを使ってデータを読み込みます。
train_df = pd.read_csv('<データのあるフォルダ>/train.txt', sep='\t', header=None)
test_df = pd.read_csv('<データのあるフォルダ>/test.txt', sep='\t', header=None)
train_df.columns = ['text', 'label']
test_df.columns = ['text', 'label']
以下のようなデータになっています。
- 近くの川で子供を遊ばせましたが、たいへんキレイな川で流れもそこそこで浅い為、安心して遊ばせる… 1 - 二家族でフリーサイトを利用しました。 お盆休み前日からの利用でアーリーチェックインしましたが… 1 - 炊事場はちゃんと清掃されていて問題なかったです。トイレは少し汚かったです。 0
学習データ数は約2万7000サンプル、検証・テストデータは約3000サンプルです。
DataLoaderの作成
データをフィードするためのDataLoaderを作成していきます。
まずは、DataLoaderを作成するための前準備です。
create_datasetという関数を作成し、その中でテキストをエンコーディングします。
ここでのエンコーディングとは文字列をボキャブラリのIDに変換することを言います。
def create_dataset(df, tokenizer, max_length=216):
texts = df['text'].to_list()
labels = df['label'].to_list()
dataset_for_loader = []
for text, label in zip(texts, labels):
encoding = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True,
)
encoding['labels'] = label
encoding = {k: torch.tensor(v) for k, v in encoding.items()}
dataset_for_loader.append(encoding)
return dataset_for_loader
詳しく見ていきましょう。
トークナイザを使ったエンコーディング
トークナイザとは、モデルが処理できるようにテキスト情報(単語列)を単語のIDの列に変換するためのものです。
以下では、日本語BERTのトークナイザ(BertJapaneseTokenize)を使ってテキスト情報をボキャブラリのIDの列に変換しています。
encoding = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True,
)
パラメータは、max_lengthでID列の最大長を決め、paddingでID列がmax_lengthより短い場合は、max_lengthまで埋めると指定し、truncationでID列がmax_lengthより長い場合はmax_lengthで切ってしまう、と指定しています。
例として、以下のように実行してみましょう。
encoding = tokenizer(
'星空がすごくキレイなキャンプ場でした。',
max_length=20,
padding='max_length',
truncation=True,
)
encoding
結果は以下のように辞書型で返ってきます。
{
'input_ids': [2, 1414, 28808, 14, 14993, 28504, 185, 721, 18, 6709, 173, 12735, 10, 8, 3, 0, 0, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
}
この辞書型変数には以下のエンコード結果が入っています。
- input_ids
エンコードしたボキャブラリのID列です。
'星空がすごくキレイなキャンプ場でした。"がこのID列に対応します。
ちなみに2は[CLS]トークンで追加された情報になります。 - token_type_ids
センチメント分析では特に使いませんが、1文の中に複数の文章の種類がある場合(コンテンツと質問など)に使います。 - attention_mask
0の部分にはattentionは向けません。つまり、truncateしている部分にはattentionを向けないということです。
話をもとに戻してコードを確認すると、以下の部分では、トークナイザが返した辞書型変数に教師ラベルを追加しています。
encoding['labels'] = label
そして、エンコーディング結果をtorch.tensor()でPyTorchのテンソルに変換しています。
encoding = {k: torch.tensor(v) for k, v in encoding.items()}
最後に戻り値であるdataset_for_loaderというリスト型変数にラベル付きのエンコーディング結果を追加しています。
dataset_for_loader.append(encoding)
dataset_for_loaderは辞書型のエンコーディング結果が入ったリスト型変数になります。
DataLoaderの作成
では、DataLoaderを作成しましょう。
まず、さきほど作成したcreate_dataset関数を呼び出してリスト型のデータセットを作成します。
MAX_LENGTH = 216
dataset_for_loader_train = create_dataset(
train_df,
tokenizer,
max_length=MAX_LENGTH
)
dataset_for_loader_test = create_dataset(
test_df,
tokenizer,
max_length=MAX_LENGTH
)
データセットが出来上がったら、以下のようにDataloaderを呼び出して、DataLoaderを作成します。
dataloader_train = DataLoader(
dataset_for_loader_train,
batch_size=16,
shuffle=True
)
このDataloaderの引数だけ説明しておきます。
DataLoaderはループで回すと自動的にデータを渡してくれるので、その際のバッチサイズを指定する必要があります。
ですのでbatch_sizeという引数に16を指定しています。
また、学習データはシャッフルした方が効率的に学習ができるのでshuffle=Trueとします。
同様にテストデータのDataLoaderも作成しましょう。
dataloader_test = DataLoader(
dataset_for_loader_test,
batch_size=16,
shuffle=False
)
テストデータはシャッフルする必要はないのでshuffle=Falseとしておきます。
学習モデルの作成
では、ここから本丸である学習モデルを作成していきます。
PyTorch-Lightningを使ってファインチューニングをしていきます。
class BertForSentimentAnalysis_pl(pl.LightningModule):
def __init__(self, model_name, num_labels, lr):
super().__init__()
self.save_hyperparameters()
self.bert_model = BertForSequenceClassification.from_pretrained(
model_name,
num_labels=num_labels
)
def forward(self, batch):
output = self.bert_model(**batch)
return output
def training_step(self, batch, batch_idx):
output = self.bert_model(**batch)
loss = output.loss
self.log('train__loss', loss)
return loss
def validation_step(self, batch, batch_idx):
output = self.bert_model(**batch)
val_loss = output.loss
self.log('val_loss')
def test_step(self, batch, batch_idx):
labels = batch.pop('labels')
output = self.bert_model(**batch)
labels_predicted = output.logits.argmax(-1)
num_correct = (labels_predicted == labels).sum().item()
accuracy = num_correct / labels.size(0)
self.log('accuracy')
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.hparams.lr)
こちらも一つずつ説明していきます。
まず、pl.LightningModuleを継承します。
class BertForSentimentAnalysis_pl(pl.LightningModule):
コンストラクタ
コンストラクタは以下のようになっています。
def __init__(self, model_name, num_labels, lr):
super().__init__()
self.save_hyperparameters()
self.bert_model = BertForSequenceClassification.from_pretrained(
model_name,
num_labels=num_labels
)
引数はBERTのモデル名を表すmodel_name、教師ラベルの種類を表すnum_labels、学習率を表すlr(learning rate)です。
self.save_hyperparameters()を呼び出すことでこれらの引数が自動的にself.hparamsの中に設定されます。
そして、6行目のBertForSequenceClassification.from_pretrained()メソッドで学習済みBERTモデルを読み込みんでいます。
事前学習済みモデルは分類層を持たないので、num_labelsを指定することでnum_labels分を予測する分類層を作成してくれます。
学習・検証・テストステップ
forward(), training_step()、validation_step()、test_step()を実装します。
最低限必要なのはtraining_step()メソッドですがforward(), validation_step()、test_step()も使いますので、これらを実装しておきます。
- forward()
推論処理。 - train_step()
学習のため。 - validation_step()
- 検証のため。
- test_step()
- テストのため。
まず、forward()メソッドです。
これを実装することによって、model_pl(data)とすることで推論を実行することができます。
def forward(self, batch):
output = self.bert_model(**batch)
return output
以下の部分で、バッチデータを渡し、モデルが予測を行います。
output = self.bert_model(**batch)
続いてtraining_step()メソッドです。
def training_step(self, batch, batch_idx):
output = self.bert_model(**batch)
loss = output.loss
self.log('train__loss', loss)
return loss
training_stepは損失関数の値を返す必要があります。
最初は同じように予測をします。
output = self.bert_model(**batch)
アウトプットのloss属性に損失が入っているので、その値をreturn lossで返しています。
self.logはTensorboard用にログを出力しています。
validation_stepもほぼ同じです。
損失を計算してログに出力します。
def validation_step(self, batch, batch_idx):
output = self.bert_model(**batch)
val_loss = output.loss
self.log('val_loss')
学習をするわけではないので、損失を返す必要はありません。
最後にtest_stepです。
テストでは損失ではなく、精度(accuracy)を計測したいと思います。
もちろん見たい指標を設定すればよく、複数設定することも可能です。
def test_step(self, batch, batch_idx):
labels = batch.pop('labels')
output = self.bert_model(**batch)
labels_predicted = output.logits.argmax(-1)
num_correct = (labels_predicted == labels).sum().item()
accuracy = num_correct / labels.size(0)
self.log('accuracy')
以下の部分で、argmaxにより一番logitが大きいラベルを予測ラベルとし、教師ラベルと一致している件数を全体の件数で割って精度を計算しています。
labels_predicted = output.logits.argmax(-1) num_correct = (labels_predicted == labels).sum().item() accuracy = num_correct / labels.size(0)
以上でPyTorch Lightningのモデルができました。
モデルのインスタンス化
では、学習するためにモデルをインスタンス化しましょう。
今回のラベルは0, 1の2種類なのでnum_labels=2とします。
NUM_LABELS = 2
model_pl = BertForSentimentAnalysis_pl(
model_name=MODEL_NAME,
num_labels=NUM_LABELS,
lr=5e-6
)
モデルをインスタンス化したあとに以下でコンストラクタで指定したパラメータを確認できます。
model_pl.hparams
"lr": 5e-06 "model_name": cl-tohoku/bert-base-japanese-whole-word-masking "num_labels": 2
学習フェーズ
では学習の準備をしていきます。
チェックポイントの作成
何エポックか回しますが、その際に自動的にモデルを保存してくれるチェックポイントを作成します。
ここでは検証データの損失(monitor='val_loss')を見て、一番小さい(save_top_k=1, mode=min)の結果を保存します。
checkpoint = pl.callbacks.ModelCheckpoint(
monitor='val_loss',
mode='min',
save_top_k=1,
save_weights_only=True,
dirpath='/content/drive/MyDrive/NLP/bert_model/',
)
save_weights_onlyをTrueとすることでモデルの構造は保存せずウェイトのみを保存します。
保存するパスはdirpathで指定しています。
これはご自分の保存したいフォルダを指定していただければ結構です。
Trainerの作成
では、pl.Trainerで学習の設定をしていきます。
ここではエポック数を5として学習します。
GPUを使用するのでgpus=1、callbackに先ほど作成したcheckpointを指定します。
MAX_EPOCH = 5
trainer = pl.Trainer(
gpus=1,
max_epochs=MAX_EPOCH,
callbacks=[checkpoint],
)
学習
では、実際に学習していきます。
ここまで準備できているとあとは以下の1行で学習ができます。
trainer.fit(model_pl, dataloader_train, dataloader_val)
このようにプログレスバーが進んでいくかと思います。

これで学習ができました。
Tensorboardで学習状況を確認
Tensorboardで学習状況を確認するには以下のマジックコマンドを利用します。
%load_ext tensorboard %tensorboard --logdir ./
すると次のように検証データセットの学習結果を見ることができます。
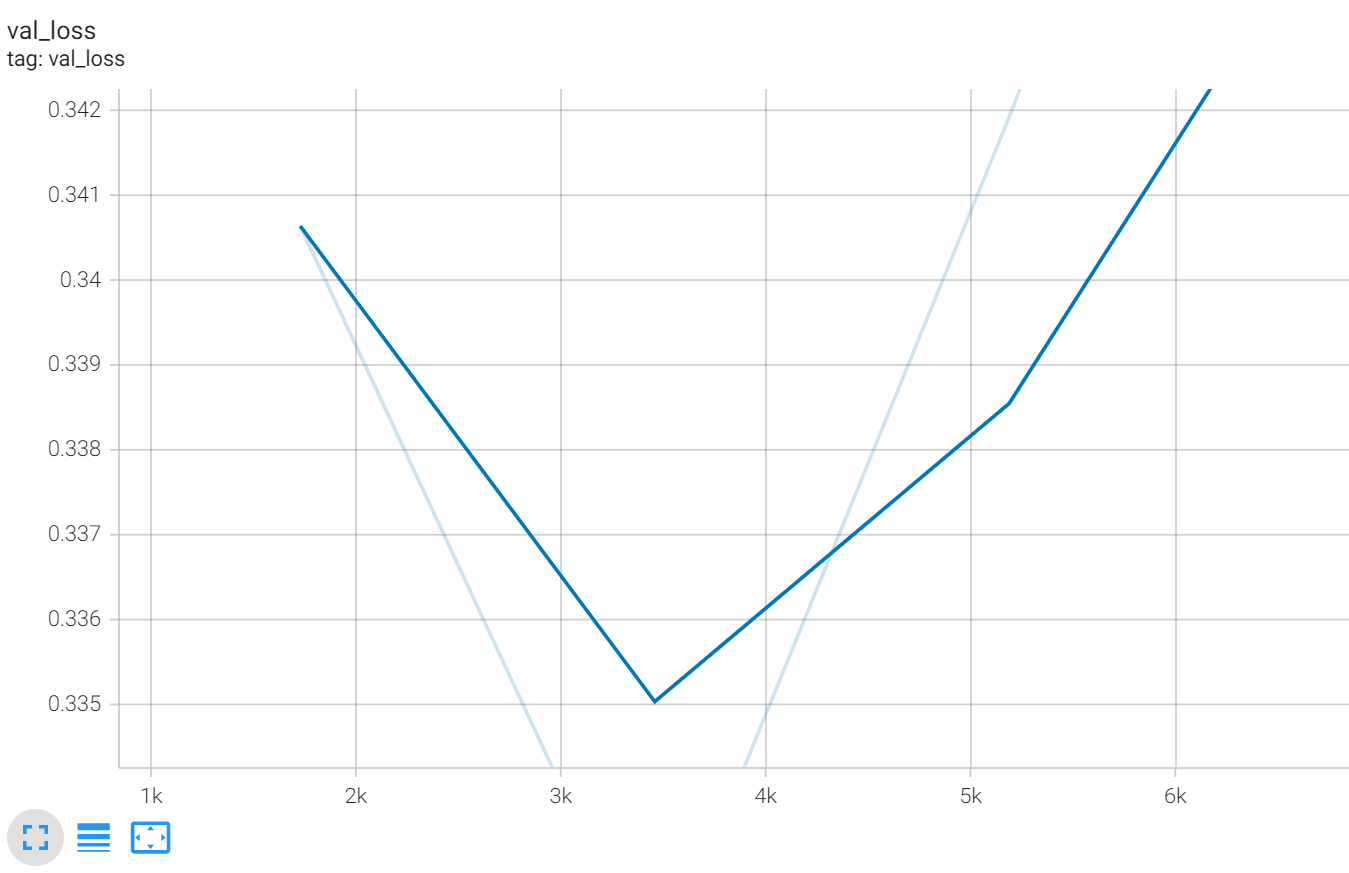
最後まで学習してしまうと学習データにオーバーフィッティングした最適ではないモデルが作成されてしまいますが、ModelCheckpointで検証誤差がもっとも小さいモデルを保存するように設定しますので、model_plのモデルには検証誤差が最も小さいモデルが設定されています。
テストデータで精度を確認
では、テストデータで精度を確認してみましょう。
今回はテストデータと検証用データは同じものを使っています。
trainer.test()でPyTorch Lightningのモデルとテスト用のデータローダを渡します。
trainer.test(model_pl, dataloader_val)
するとmodel_plのtest_stepメソッドが呼び出され、ここでは精度(accuracy)が計算されます。
結果は86.2%となりました。
BERTを使ったそれほど難しくないセンチメント分析にしては少々精度が低いかなと感じますが、その要因をエラー分析で少しだけ深堀りしたいと思います。
モデルの保存・読み込み
PyTorch Lightningモデルを保存・読み込み
チェックポイントの設定によりPyTorch Lightningのモデルが自動的に保存されていました。
これを読み込むには作成したPyTorch Lightningのモデルのload_from_checkpoint()を呼び出します。
new_model_pl = BertForSentimentAnalysis_pl.load_from_checkpoint(
best_model_path
)
BERTモデルのみを保存・読み込み
PyTorch Lightningではなく、BERTモデルとして保存したい場合は、save_pretrained()を呼び出します。
model_pl.bert_model.save_pretrained('/content/drive/MyDrive/NLP/bert_model')
これを読み込む場合は、事前学習済みモデルを読み込むのと同じでfrom_pretrained()を呼び出します。
引数はモデルが保存されているパスです。
new_model = BertForSequenceClassification.from_pretrained('/content/drive/MyDrive/NLP/bert_model')
エラー分析
ここからはBERTについての解説ではありませんが、モデルを作成する上では必ずやる必要があるエラー分析について簡単に触れておきます。
検証データで予測
まず、検証データで予測します。
ここはそれほどテクニカルではないので、あまり詳しく説明しませんがご容赦ください。
from tqdm import tqdm
batch_size = 32
num_of_iter = len(test_df) // batch_size
new_model_pl.eval()
for batch in tqdm(range(num_of_iter + 1)):
encoding = tokenizer(
test_df['text'][batch * batch_size: (batch + 1) * batch_size].to_list(),
max_length=216,
padding='max_length',
truncation=True,
return_tensors='pt'
)
encoding = {k: v.to('cuda') for k, v in encoding.items()}
with torch.no_grad():
if batch == 0:
output = new_model_pl(encoding).logits
else:
output_tmp = new_model_pl(encoding).logits
output = torch.concat([output, output_tmp])
バッチを適当に設定して、ループで回しながら、トークナイザを使ってエンコーディングし、logitsを求めています。
そして、outputにlogitsをまとめています。
推論なので6行目、18行目により勾配を計算したりしないように設定しています。
続いてサンプルごとにクロスエントロピー誤差を計算します。
from torch.nn.functional import cross_entropy
predicted_labels = output.argmax(-1)
loss = cross_entropy(output, torch.from_numpy(test_df.label.values).to('cuda'), reduction='none')
test_df['predicted_label'] = predicted_labels.to('cpu').numpy()
test_df['loss'] = loss.to('cpu').numpy()
そして、クロスエントロピー誤差が大きい順に並べて、上位のサンプルを見てみます。
test_df.sort_values('loss', ascending=False).head(10)
結果は以下のようになっています。(文章は全文表示しないようにしています)
| text | label | predicted_label | loss |
|---|---|---|---|
| 川がとてもキレイで川遊びも楽しめました! 夜は満点の星空に... | 悪い | 良い | 4.640209 |
| 整っていますが、コテージそばの炊事場は電気がなく、暗いと見えなくて... | 良い | 悪い | 4.531791 |
| 最寄りICから50分以上山道を走ります。周辺にはダムの施設しかなく、食料品を購入するには道の... | 良い | 悪い | 4.342983 |
| 受付時に丁寧な対応をして頂けたので好感が持てました。流しそうめんも本格的で4歳の子供がとても... | 悪い | 良い | 4.150795 |
1が良いセンチメント、0が悪いセンチメントです。
クロスエントロピー誤差が大きいということは、モデルが自信を持って答えたけど間違っているということです。
一部隠しているためわかりにくいかもしれませんが、見た感じ教師ラベル(label)の方が微妙な感じです。
ここでは詳しく見ませんが、精度以上にきちんと予測できている可能性はあります。
自分でアノテーションをした場合だとアノテーションの間違いがわかったり、どういう文章がうまく予測できていないかがわかり、アノテーションを追加することでモデルの改善ができます。
では、逆にクロスエントロピー誤差が小さいサンプルを見てみましょう。
test_df.sort_values('loss', ascending=True).head(10)
結果はこちらです。
| text | label | predicted_label | loss |
|---|---|---|---|
| スタッフのみなさんとても良い人たちばかりで、こちらの急なお願いも快く対応していただき... | 良い | 良い | 0.004531 |
| スタッフの皆様がとても親切でした、臨機応変で居心地も良く素晴らしかった... | 良い | 良い | 0.004648 |
| 最高でした。とっても人柄の良いご夫婦で、奥様の到着時の案内も丁寧で、安心。ご主人は子供達に... | 良い | 良い | 0.00505 |
| とても静かで解放感のあるサイトでした。 落ち葉やどんぐりも沢山落ちていて子供たちも... | 良い | 良い | 0.005194 |
これを見ることで、モデルはどういった文章を適切に予測できているかがわかります。
上位には、スタッフの方に対するコメントが多いですね。
ご参考 - アテンションについて
BERTはTransformerを使っているので、センチメント分類でどの単語が重要なのか?、どこを拠り所としてそのセンチメントが予測されているのか?がわかると嬉しいですね。
例えば、『【データ分析実践】口コミを使ったキャンプ場に関する分析7 ~Attentionメカニズム実装編 ~』記事で解説したように、以下のような感じでアテンションが可視化できると嬉しいです。

本記事のモデルでも、推論をする際に、output_attentions=Trueとするだけでアテンションを取得することは可能です。
output, attention = self.bert_model(**batch, output_attentions=True)
ただ、私が今まで使った感じだとうまくいきません。
どのレイヤーのどのヘッドのアテンションを使うか?もしくはどのように平均を取るか?ということも問題となってくるのかもしれませんが、センチメントとは関係のない単語にアテンションが大きくなっていたりして、うまく可視化できていません。
うまくできる!という方はご連絡いただければ嬉しいです。
まとめ
今回はTransformersのBERT日本語モデルを使って口コミのセンチメント分析を見てきました。
BERTは非常に重要なモデルで、実務でも使えるので是非慣れておくといいかと思います。
参考書
今回の記事は以下の本を参考にしています。
TransformersでBERT日本語モデルおよびPyTorch Lightninngの利用方法が詳しく書かれています。
今回紹介したセンチメント分析(文章分類)だけでなく、マルチラベル分類や固有表現抽出、文章校正なども載っていますので、是非一度読んで実装していただきたい本です。
こちらはBERT日本語モデルに焦点を当てているのではなく、Transformersに焦点を当てた本です。
ただ、個人的にはまず上記の本で日本語BERTを使えるようになっていただき、そのあとに読んでいただく方がよいかなと思います。
では!!