今回はBERT(Bidirectional Encoder Representations from Transormers)を使って文書分類(センチメント分析)をしたいと思います。
試すと言っても今回は自分の手で実装するのではなく、公開されたモデルを利用したいと思います。
現在NLP(自然言語処理)を使って何等かの予測をする場合、BERTは他のモデルと比べてかなり精度が良いと考えていますので、使い方は知っておいた方が良いと思います。
BERTの仕組みについてはこちらの記事をご参照ください。

データはいつも通りキャンプの口コミデータを使って、5段階評価のうち星5個か星3個以下かの二値分類を行います。
データセットについてはこちらをご参照ください。

ここでは、Googleが公開しているソースコードを利用して、少し修正しているだけですが、自分で実装してみたいという方には以下の本がオススメです。
自然言語処理専門の本ではありませんが、BERTやTransformer、他にも画像認識やGANなどを自分で実装しながら学ぶことができ、さらにPyTorchも学べる非常に良い本です。
あと、この記事は若干情報が古いのですが、今ではHugging FaceのTransformersを利用することにより、もっと簡単にBERTの日本語モデルを使うことができます。ですので、BERTの使い方であればこちらの記事をご参照いただければと思います。

では早速使っていきましょう。
使い方
今回はこちらのBERT日本語Pretrainedモデルを利用させていただきました。
これは、Googleが公開しているソースコードを使って、日本語のWikipediaコーパスを使ってBERTを事前学習しています。
形態素解析にJUMAN++を使用していますので、JUMAN++をインストールする必要があります。
Windowsへのインストールが大変だったので、AWS(Amazon Web Service)を使用しました。
AWSの利用方法
(ちなみに、私はAWSのEC2を使える程度の理解度なのでご了承ください。また知っている人は読み飛ばしてください)
まず、こちらから(https://aws.amazon.com/jp/)AWSのアカウントを作成します。
そして、AWSコンソールにログインし、EC2インスタンスを作成していきます。
まず、AMI(Amazon Machine Image)を選択します。AMIはOSやライブラリ類がパッケージのような形で提供されており、用途に合わせて選ぶことができます。
今回は、Tensorflowを使いたいので、検索バーで「Deep Learning」と入力して検索し、“Deep Learning AMI (Ubuntu 18.04) Version 29.0”を選択しました。
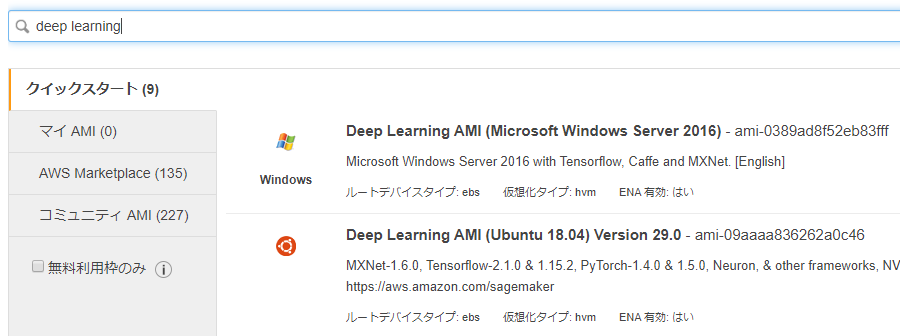
インスタンス・タイプはp2.xlargeというGPUを使うことができるインスタンスを選択します。もっとたくさんGPUを使いたいとかあればp2.xxlargeなどさらに上のグレードもあります。ただし、その分値段が高くなります。
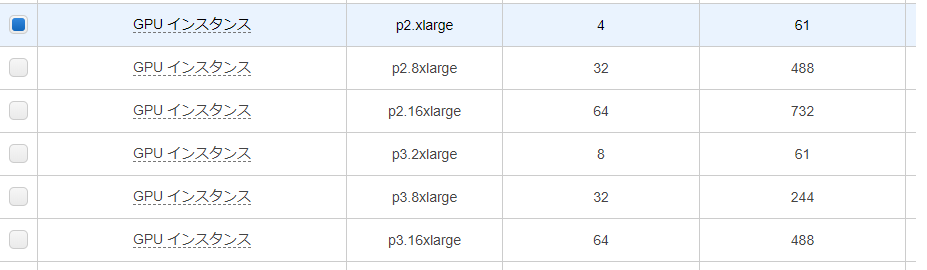
それ以外はデフォルトのままでも大丈夫です。
たまに容量不足で動かなくなってしまうことがあるので、使い方によってはストレージのサイズを増やしても良いと思います。
そして、インスタンスの起動まで進めていきます。
以下の画面では新しいキーペアを作成します。EC2サーバーに入るときにこのキーが必要になりますので、大切に保管しておきましょう。
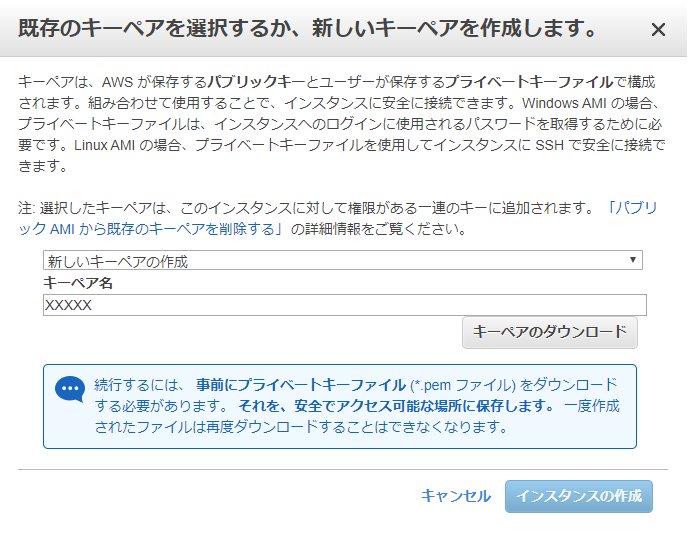
これでEC2インスタンスの作成ができました。
あとは、インスタンスを選択して、「アクション」から「インスタンスの状態」→「開始」や「停止」なので操作します。
使わないときは「停止」しておかないとお金がかかってしまいます。
EC2サーバーに入るには、SSHクライアントというのが必要になります。
いくつかあるようですが、私はTera Termを使っていますので、クライアントPCに普通にインストールすれば大丈夫です。
そして、Tera TermからEC2サーバーにログインします。
EC2インスタンスを起動し、Tera Termを立ち上げます。
Tera Termのホスト欄にパブリックDNSを入力します。
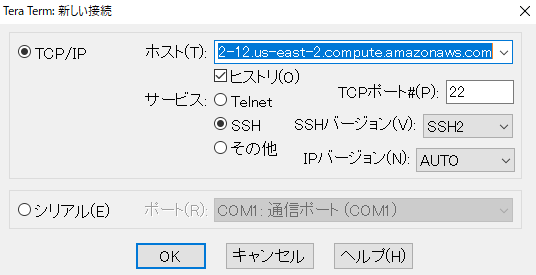
そして、ユーザー名に“ubuntu”を入力し、秘密鍵を指定します。
これでEC2サーバーに入ることができると思います。
JUMAN++インストール
JUMAN++のインストールはこちらのサイトを参考にしています。
https://qiita.com/Gushi_maru/items/ee434b5bc9f020c8feb6
まとめると以下のコマンドを流せば大丈夫です。
# jumanpp-2.0.0-rc3 download wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz # unzip a file tar xvf jumanpp-2.0.0-rc3.tar.xz # cmake install sudo apt install cmake -y # build jumanpp cd jumanpp-2.0.0-rc3/ mkdir build cd build/ cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local make # install jumanpp sudo make install
なお、pyknpというパッケージもインストールする必要がありますので、pipで普通にインストールします。
pip install pyknp
BERTの準備
では、BERTの事前学習モデル(パラメータ等)とBERTのプログラムを取得します。
まず、以下のHPから日本語版BERTの事前学習モデルをダウンロードし、EC2サーバーに保存します。
そして、Googleが公開しているBERTのプログラムも以下から取得し、EC2サーバーに保存します(Git cloneすれば良いです)。
https://github.com/google-research/bert
これであとは評価させたい文章をJUMAN++で分かち書きして、tsvファイルにして読み込ませれば評価してくれます。
ただ、以下のサイトではJUMAN++での分かち書きも一括してやってくれるような修正方法が載っていますので、これを真似したいと思います。
https://qiita.com/neonsk/items/27424d6122e00fe632b0
まず、公式のBERTではJUMAN++で分かち書きするようにはなっていませんので、JUMAN++で分かち書きする用のクラスを作成します。
以下のようにBERTプログラムのTokenizer.pyにJumanPPTokenizerクラスを追加します。
class JumanPPTokenizer(BasicTokenizer):
def __init__(self):
"""Constructs a BasicTokenizer.
"""
from pyknp import Juman
self.do_lower_case = False
self._jumanpp = Juman()
def tokenize(self, text):
"""Tokenizes a piece of text."""
text = convert_to_unicode(text.replace(' ', ''))
text = self._clean_text(text)
juman_result = self._jumanpp.analysis(text)
split_tokens = []
for mrph in juman_result.mrph_list():
split_tokens.extend(self._run_split_on_punc(mrph.midasi))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
print(split_tokens)
return output_tokens
そして、FullTokenizerクラスを以下のように修正します。
これで、もともとのBasic Tokenizerを使うのではなく、先ほど作成したJumanTokenizerを使うようになります。
def __init__(self, vocab_file, do_lower_case=True):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
# jumanPPTokenizerを活用するように修正
# self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
self.jumanpp_tokenizer = JumanPPTokenizer()
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
def tokenize(self, text):
split_tokens = []
# for token in self.basic_tokenizer.tokenize(text):
for token in self.jumanpp_tokenizer.tokenize(text):
for sub_token in self.wordpiece_tokenizer.tokenize(token):
split_tokens.append(sub_token)
最後に、run_classifier.pyのインプットデータの処理部分のプログラムを修正します。
BERTのプログラムでは、以下のようにCoLAやMNLIなどタスクによって処理方法を変えているので、そこに今回処理したいタスクを追加します。
今回は“nap”というタスクを設定し、そのタスクが指定された場合は“NapProcessor”を呼び出すようにします。ディクショナリの一番下に追加しています。
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"nap": NapProcessor, # 実行時に呼び出すtask_name : クラス名
}
最後に先ほど定義した“NapProcessor”の処理を追加します。
これは、もとのCoLAなどの処理をもとにしています。学習データやテストデータを読み込むメソッド、ラベルを定義するメソッド、サンプルを整形するメソッド(_create_examplesメソッド)があります。
BERTでは、2つの文章をインプットすることも可能になっていますが今回は1文(1パラグラフ)だけの分類問題なので、_create_examplesで、text_bはNoneとします。
class NapProcessor(DataProcessor):
"""Processor for the original data set """
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
# 分類するlabelの定義
return ["1", "0"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
print("lines = " + str(lines))
for (i, line) in enumerate(lines):
print(str(i) + "番目:" + str(line))
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
# 入力となるテキストをtext_aに格納するように設定
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
BERTの実行
あとは、引数を自分のディレクトリ構成などに合うように指定して、実行します。
1行目はパラメータを保存しているディレクトリを指定します。
# 任意のディレクトリのPATHを設定 export BERT_BASE_DIR=/Users/Desktop/Techcology/bert/Kyoto_Univ/Japanese_L-12_H-768_A-12_E-30_BPE python run_classifier.py \ --task_name=komachi \ --do_train=true \ --do_eval=true \ --data_dir=./input_data/fine_tuning/nap \ --vocab_file=$BERT_BASE_DIR/vocab.txt \ --bert_config_file=$BERT_BASE_DIR/bert_config.json \ --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \ --max_seq_length=128 \ --train_batch_size=32 \ --learning_rate=2e-5 \ --num_train_epochs=3.0 \ --output_dir=./output_data/fine_tuning/komachi \ --do_lower_case False
何か間違っていたのかもしれませんが、“bert_model.ckpt.がない!”と言われたら、ファイル名が“ model.ckpt.”になっているかもしれませんので、3つのファイル名をbert_model.ckpt.meta、 bert_model.ckpt.index、bert_model.ckpt.data-00000-of-00001にしてみてください。
結果
結果はテストデータで85.3%でした。Transformerの83.2%を約2.1%、CNNの83.9% を約1.4%上回りました。
どれだけ頑張ってもCNNを上回れませんでしたが、ようやく上回ることができました。
ただし、BERTの事前学習に使っているコーパスはWikipediaなので、口コミとは若干分布が違うのかなと思います(仕事で使用しているときは、もっと改善しましたので)。
では皆さんも是非一度は自分の手を動かしていただければと思います!