さて今回は、以前こちらの記事で紹介しているOpenAIの『CLIP』を使って遊んでみたいと思います。
ここでは、CLIPの詳細については全く触れないので、興味がある方は以下の記事を参考にしてください。

CLIP(Contrastive Language-Image Pre-training)は、自然言語処理と画像処理を融合したモデルです。
大量の画像とテキストのペアをインターネットから取得し、巨大なモデルを学習することで、zero-shotの設定(初めて見た画像に対する分類等)で分類することが可能になっています。
以下は、ImageNetで学習したモデル(ResNet)とCLIP(Vision Transformerベース)の比較結果です。
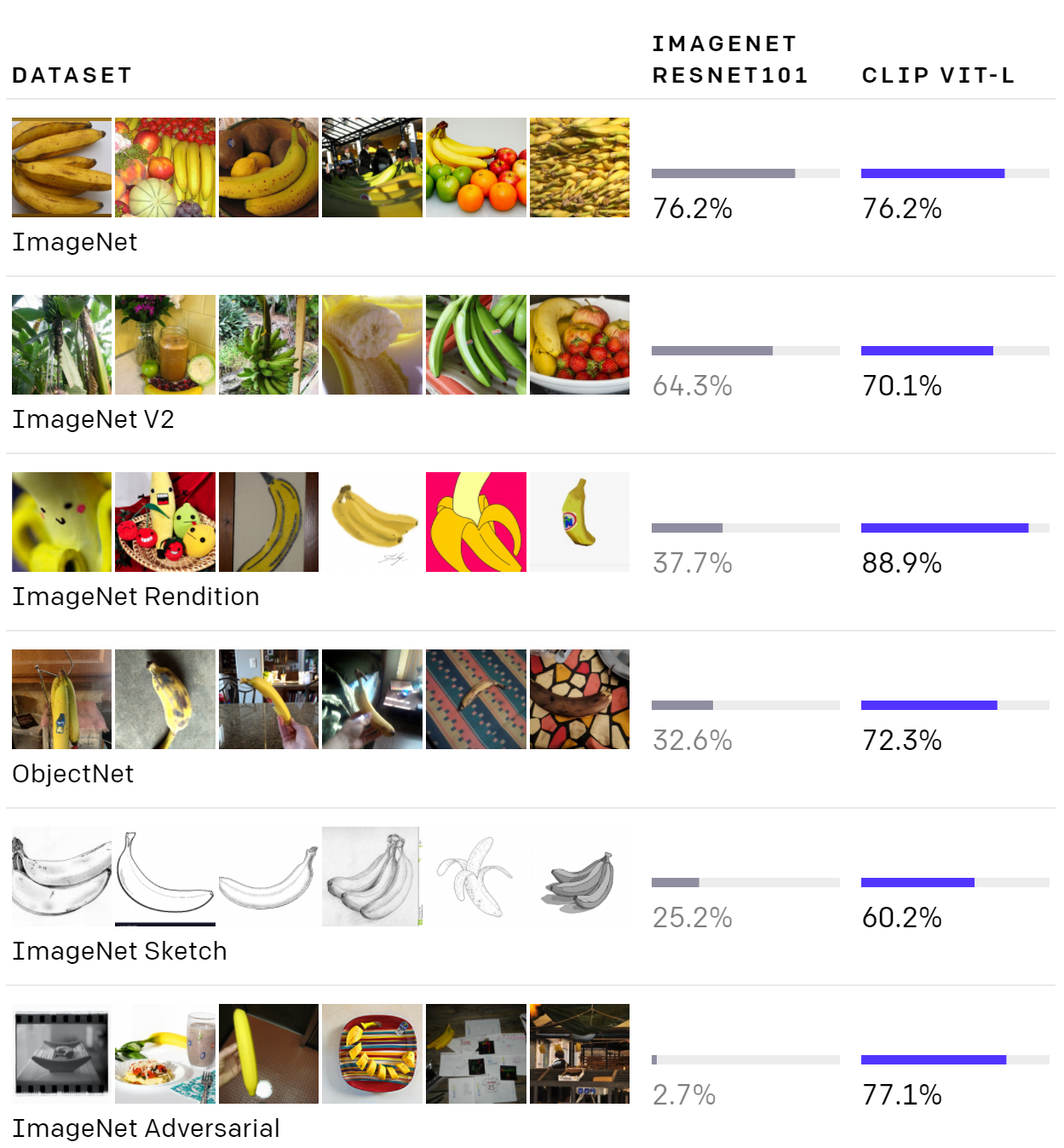
上段のImageNetにある画像やImageNetに近い画像であればResNetでもある程度の精度が出ていますが、3段目より下になると精度が大幅に低下しています。
一方のCLIPでは、スケッチ画像や一見難しい画像でもそれほど精度が低下せず、一定の水準を保っています。
さて、この『CLIP』の使い道ですが、一つの使い道として、自然言語で表されるテキスト情報と画像情報の一致度を返す、というものがあります。
これはOpenAIによる『DALL-E』で使われています。
DALL-Eでは、テキスト情報をインプットとして画像を生成しますが、必ずしもテキストと生成された画像の内容が一致していない場合があります。
そこで、複数の画像を生成し、それぞれについてCLIPでテキスト情報と生成した画像の一致度を求めます。
そして、一致度が高いものだけを返す、とすることで、テキスト情報と内容が一致した画像のみを返すことができます。
今回はそれを試してみたいと思います。
CLIP APIの準備
以下のCLIP APIを使います。
https://github.com/openai/CLIP
使い方は非常に簡単です。
まず、必要なパッケージインストールしましょう。
!pip install ftfy regex tqdm !pip install git+https://github.com/openai/CLIP.git
Googleドライブを使うので以下のようにマウントします
from google.colab import drive
drive.mount('/content/drive')
PyTorchで実装されているんでtorchをインポートし、clipというCLIPモジュールをインポートします。
import torch
import clip
import matplotlib.pyplot as plt
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
そして、clip.load()でVision Transformerのモデルを使うため"ViT-B/32"というモデルをロードしています。
また、preprocessに画像の処理モジュールが返されています。
なお、"clip.available_models()"とすると使えるモデルの一覧が表示されます。
'RN50', 'RN101', 'RN50x4', 'RN50x16', 'ViT-B/32', 'ViT-B/16'の6つが使えるようです。
ドラクエ画像で試す
では、ここでは写真ではなくドラクエのイラスト画像にCLIPを適用してみたいと思います。
一致するモンスター名を予測する

左から、スライム、キングスライム、メタルスライム、メタルキング、ドラキー、アームライオンです。
では、この5つの名前がどれに対応しているか予測してもらいましょう。
英語にしか対応していないので、英語で書きます(Multilingual CLIPというものも存在しますが今回は使用しません)。
monsters = ['スライム', 'キングスライム', 'メタルスライム', 'ドラキー', 'アームライオン'] texts_en = ["a slime", "a king slime", "a metal slime", "a metal king", "a drakey", "an arm lion"]
以下のようなコードで、各モンスターがどのテキストと近いかを出力してくれます(もう少し良い出力の仕方があると思いますが)。
file_base_dir = 'Your Folder'
for i, monster in enumerate(monsters):
print(f'--- {monster} ---')
original_image = Image.open(file_base_dir+f"{monster}.jpg")
image = preprocess(original_image).unsqueeze(0).to(device)
texts = clip.tokenize(texts_en).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(texts)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
for i in range(probs.shape[-1]):
print(f'{texts_en[i]}: {probs[0, i]*100:0.1f}%')
imageをpreprocess()で前処理し、clip.tokenize()でトークナイズします。
そして、model()で一致確率probsを計算します。
結果は以下でした。
| TEXT | スライム | キングスライム | メタルスライム | メタルキング | ドラキー | アームライオン |
|---|---|---|---|---|---|---|
| a slime | 82.70% | 3.10% | 36.30% | 3.50% | 20.90% | 0.00% |
| a king slime | 12.50% | 95.80% | 6.10% | 77.20% | 30.60% | 0.10% |
| a metal slime | 4.60% | 0.90% | 57.60% | 17.00% | 17.20% | 0.00% |
| a metal king | 0.00% | 0.20% | 0.00% | 2.10% | 4.60% | 0.60% |
| a drakey | 0.20% | 0.00% | 0.00% | 0.10% | 26.60% | 0.50% |
| an arm liion | 0.00% | 0.00% | 0.00% | 0.00% | 0.10% | 98.80% |
スライム、キングスライム、メタルスライム、アームライオンはうまく当てられていますね。
メタルキングはキングスライムと予測しています。ドラキーは迷っている感じでしょうか。
何となくではありますが、スライム、キングスライム辺りはしっかりと知っていて、アームライオンはライオンの画像をよく知っているというところでしょうか。
一致する文章を予測する
では、次にちょっとした文章で試したいと思います。
以下の「アームライオン」の画像に対し、

次の5個の文章との一致度を計算します。
- "a lion with many arms"(たくさんの手があるライオン)
- "a tiger with many arms"(たくさんの手があるトラ)
- "a cute lion"(かわいいライオン)
- "a lion with many heads"(たくさんの頭を持つライオン)
- "a sleeping lion"(寝ているライオン)
コードは以下のような感じです。
monsters = ['アームライオン']
texts_en = ["a lion with many arms", "a tiger with many arms", "a cute lion", "a lion with many heads", "a sleeping lion"]
for i, monster in enumerate(monsters):
original_image = Image.open(file_base_dir+f"{monster}.jpg")
image = preprocess(original_image).unsqueeze(0).to(device)
plt.figure()
plt.imshow(original_image)
plt.show()
text = clip.tokenize(texts_en).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
for i in range(probs.shape[-1]):
print(f'{texts_en[i]}: {probs[0, i]*100:0.1f}%')
結果は、"a lion with many arms"(たくさんの手があるライオン)が46.7%と最高になっていますので、当てられていますね。

"a lion with many heads"(たくさんの頭を持つライオン)が27.7%と少し高くなっていますが、"a tiger with many arms"(たくさんの手があるトラ)は2.8%と非常に低いので、ライオンであるということは確実にとらえています。
あとは、手がたくさんあるライオン、もしくは手がたくさんある動物というのをあまり見たことがなく、少し迷っているのかもしれませんね。
他にも、ドラクエVのボス「ミルドラース」で試してみました。ちょっと意外でしたが、うまく予測していますね…

日本語から予測する
ただ、英語で文章を作るのは面倒臭いので、日本語でできないか、試してみました。
Multilingual CLIPというのもありますが、今後のことも考えて、Google翻訳と組合せてみます。
まず、Google翻訳をインストールします(バージョンを指定しないと後続の処理がうまくいきませんでした)。
!pip install googletrans==4.0.0-rc1
Translatorをインポートします。
from googletrans import Translator
あとは、Translateメソッドで日本語のインプットを英語に翻訳し、前と同じようにCLIPで予測します。
スライムナイトの画像に対し、以下の5つで試します。
- スライムに乗った騎士
- 馬に乗った騎士
- 剣で遊んでいる騎士
- スライム
- スライムに乗った魔法使い
うまくいけば1番目が1番高く、その次に3番目の一致度が高くなる想定です。
texts_jp = ["スライムに乗った騎士", "馬に乗った騎士", "剣で遊んでいる騎士", "スライム", "スライムに乗った魔法使い"]
monsters = ['スライムナイト']
translator = Translator()
texts_en = [translator.translate(text_jp, dest="en", src="ja").text for text_jp in texts_jp]
print(texts_en)
for monster in monsters:
original_image = Image.open(file_base_dir+f"{monster}.jpg")
image = preprocess(original_image).unsqueeze(0).to(device)
plt.figure()
plt.imshow(original_image)
plt.axis('off')
plt.show()
text = clip.tokenize(texts_en).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
for i in range(probs.shape[-1]):
print(f'{texts_jp[i]}: {probs[0, i]*100:0.1f}%')
結果は以下のようになりました。

「スライムに乗った騎士」が53.7%と一番一致しており、「剣で遊んでいる騎士」が2番目になっています。
妥当な結果ですね。
次に「エビルアップル」です。どうやらCLIPは「エビルアップル」を知っているようですね。

英語に翻訳するとEvil appleと正しく翻訳されていました。
ちなみに、「エビルアップル」というテキストをインプットから除くと、ちゃんと「リンゴの形をしたモンスター」を予測しています。

「エビルアップル」の緑色バージョン「ガップリン」については名前を知らないようですね。

「リンゴの形をしたモンスター」が予測されていますので、恐らくzero-shotで正しく判定できているということだと思います。
テキストと一致する画像を抽出する
では、DALL-Eで使われていたように、与えられたテキスト情報と一致度が高いtop5を抽出してみましょう。
データは以下のようなドラクエVのモンスター223種類の画像を使用します。

コードは以下のようにしています。今回はテキスト情報に対する画像の一致度を求めるので、logit_per_textの値を使います。
texts_jp = ["---- text -----"]
translator = Translator()
texts_en = [translator.translate(text_jp, dest="en", src="ja").text for text_jp in texts_jp]
print(texts_en)
text = clip.tokenize(texts_en).to(device)
with torch.no_grad():
logits_per_image, logits_per_text = model(images, text)
probs_per_text = logits_per_text.softmax(dim=-1).cpu().numpy()
probs_per_text = probs_per_text.reshape(-1)
sort_index = np.argsort(probs_per_text)[::-1]
# top 5
fig, ax = plt.subplots(ncols=5, nrows=1, figsize=(15, 15))
for i in range(5):
print(f'{names[sort_index[i]]}: {probs_per_text[sort_index[i]]*100: 0.1f}%')
ax[i].imshow(original_images[sort_index[i]])
ax[i].axis('off')
では、結果を見ていきましょう。
『舌の長いモンスター』
図は左がtop1でtop5まで表示しています。
確かに舌が長いですね。

『スライムに乗った騎士』
ちゃんとメタルライダーとスライムナイトが選ばれています。

『リンゴのようなモンスター』
DALL-Eの『アボカドの形をしたアームチェア』のようなイメージですね。うまくいっています。

『骸骨(がいこつ)』
悪くないですね。

『可愛いモンスター』
まぁ、可愛いのではないでしょうか。(1つはよくわかりませんが)

『帽子をかぶっている』
帽子に見えなくもないですが…

まとめ
ということで、CLIPを使って色々遊んでみました。
簡単に使えますので、興味がある方は試してみてください。
自然言語処理と違い(CLIPは自然言語処理も含んでいますが)画像認識のモデルは基本的には世界共通なので、学習済みモデルを簡単に使えていいですね。
あと、遊んでみるのはそれはそれで楽しいですが、今後はDALL-EのようにCLIPを応用していければなぁと思っています。
では、また!!