さて、今回はMicrosoftから提案されたDialoGPTを解説したいと思います。
とは言っても、モデル構造自体はOpenAIによるGPTの仕組みと変わりませんので、モデルの解説はほとんどありません。
ですので、DialoGPTがどういうものか、どういったデータを使って、どのように工夫し、どういう結果になっているか、を中心に見ていきたいと思います。
GPTについて興味がある方は以下のGPT、GPT-2、GPT-3の記事を参考にしてみてください。



DialoGPTの論文はこちらです。
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
では、見ていきましょう。
目次
DialoGPTとは
DialoGPTはOpenAIのGPT-2をベースに対話型のAIを作ることを試みたものです。
GPT-2と言えば、LSTMを使わずにTransformerを用いて言語モデルの事前学習を行うことで良い結果を出したGPTをベースに、パラメータ数を大幅に増やし、大量のデータで事前学習をした巨大モデルです。(GPT-3になってさらに大幅に巨大化します)
それにより、まったく学習しない、もしくはごくわずかのサンプルデータを使って、タスクを解くことができるモデルができました。
GPT-2は様々なタスクで良い性能が出ましたが、特に注目されたのは、巨大なデータを使って事前学習を行ったことにより、人間にも判別しにくいフェイクニュースを作ることができる、つまり人間が書いたかのような本物らしい文章を生成することができるようになったことです。
そこで、DialoGPTでは、それを一方的な文章生成から一歩進んで、対話システムに応用しようというものです。
GPT-2による文章生成でそうだったのように、DialoGPTも対話システムにおいて人間に近い精度が出たのとのことです。
GPTの特徴
ここでは、簡単にGPT、GPT-2の説明をします。
ご存じの方は読み飛ばしていただいて結構です。
GPTはLSTMに代わって自然言語処理の中心となった仕組みであるTransformerを全面的に採用しています。
TransformerはLSTMのように1単語ずつ前から順番に処理をするのではなく、複数の単語からなる文章をまとめて1回で処理することができます。
それにより、LSTMの問題点であったGPUをフルに活用できず、処理が遅いという問題を回避しました。
また重要なのが、attentionメカニズムという仕組みを用いていることです。
attentionメカニズムは文章のどこに注意を向けるか?をモデルが学習するもので、これにより非常に柔軟性の高いモデルができるようになりました。
さて、ここまではTransformerの説明でしたが、GPTはというと、Transformerの仕組みを用いることにより、高速に処理ができるようになったことと、attentionという仮定の少ない柔軟性性の高いモデルになったことで、大規模なコーパスで言語モデルを学習することができました。
言語モデルを学習するというのは、GPTでは以下のような学習方法になります。
$$P({\bf{x}})=\prod_{i}P(x_i|x_{i-1})$$
\({\bf{x}}\)は文章中の単語列を表し、\(x_i\)は\(i\)番目の単語を表します。
これはAutoregressiveな言語モデルの学習方法と言われ、文章の次の単語、次の単語を予測することで、言語を学習するというものです。
この単語の次はこの単語かな?、この流れだとこの単語が来るよね?と人間ならある程度想像できますが、それと同じですね。
そして、GPT-2では最大で48レイヤー、15億42百万パラメータの非常に大きなモデルを使って、Wikipediaなどを含めた巨大コーパスを学習しています。
巨大コーパスで柔軟性の高いモデルを十分に学習したことにより、モデルが文章の構造を理解し、非常に自然な文章を生成できるようになりました。
学習データセット
さて、GPTでは自然な文章を生成できるようになりましたが、ここでの目的は単に文章を生成するというだけでなく、対話型の文章を生成する必要があります。
つまり、誰かの発言に答えるような文章を生成する必要があります。
そのために、DialoGPTでは質疑応答型のソーシャルメディアであるRedditのデータを利用します。
Redditはある人がした質問に対して、他の人が回答するというもので、Yahoo知恵袋や掲示板とかと同じようなものです。
これをGPTに学習されることで、文章生成と同じように対話文を生成しようというものです。
ちなみに、GPT-2もRedditのデータを使って学習していますが、学習方法が異なります。
学習方法については次で説明します。
データの詳細について説明しておきます。
Redditの2005年から2017年までのデータを使います。
その際に、すべてのデータを使うのではなく、以下のようなフィルタリングをおこないます。
- URLが含まれているサンプルを除く
- 回答文に同じ単語が3回以上出てきているサンプルを除く
- “of”や“a”などの英語における最頻出単語上位50にある単語が含まれていないサンプルを除く
- “[”や“]”といったマークアップ言語に出てくる語が含まれるサンプルを除く
- 回答が200以上のサンプルを除く
- 攻撃的な回答があるサンプルを除く(ブロックリストに載っている)
- コーパス全体に1000回以上出てくるtri-gramの90%を含んでいるサンプルを除く
以上により、残った147,116,725(約1億5000万)サンプルを使います。
学習方法
さて、上記のデータで学習をしていきますが、どのように学習するのかを見ていきましょう。
GPT-2では単純に次の単語、次の単語を予測して事前学習しましたが、DialoGPTでは対話システムを作るために少し工夫がされています。
発話の元となる文章(source sentence)を\(S=x_1, \cdots, x_m\)、それを受けた発話(target sentence)を\(T=x_{m+1}, \cdots, x_N\)とします。
そして、次のように予測していきます。
$$P(T|S)=\prod_{n=m+1}^{N}p(x_n|x_1, \cdots ,x_{n-1})$$
つまり、最初はsource sentence \(S\)をもとに、回答の一つ目の単語を予測します。
そして、次は、source sentenceと一つ目の単語をもとに次の単語を予測し、これを繰り返していきます。
次に、複数の返しがあるサンプルについてです。
この場合、各発話を\(T_1, \cdots, T_K\)とし、\(P(T_K,\cdots, T_2|T_1)\)を求めます。
つまり、最初の質問文などに対して、それに続く複数のコメントを予測していきます。
これは、
$$\begin{align}
P(T_K,\cdots, T_2|T_1)&=P(T_K,\cdots, T_3|T_1, T_2)P(T_2|T_1)\\
&=P(T_K,\cdots,T_4|T_1, T_2, T_3)P(T_3|T_2, T_1)P(T_2|T_1)\\
&=\cdots \\
&=\prod_{i=2}^KP(T_i|T_1, \cdots, T_{i-1})
\end{align}$$
と書けます。
ですので、\(i-1\)番目以前の対話をもとに\(i\)番目の対話を求める、つまり、\(P(T_i|T_1, \cdots, T_{i-1})\)を最適化すればよくなります。
Mutual Information Maximization
オープン・ドメインの文章生成では、あまり意味を持たない文章が生成されることが多いという問題があります。
例えば、コメントに対して「そうなんだぁ」とか「本当ですね」などが繰り返されたりします(実際に作ってみるとよくわかりますので、「Pythonで作る対話システム」などで勉強するのもオススメです)。
そこで、DialoGPTでは、
Mutual Information Maximization(MIM)スコア関数という仕組みを導入します。
MIMは、source sentenceからtarget sentenceを予測した結果を使って、target sentenceを与えたときのtarget setnenceが出てくる確率\(P(\text{Source}|\text{Target})\)を評価します。
つまり、実際の予測とは逆になります。
具体的には、まずsource sentenceをインプットとして、targetとなるhypothesisを\(K\)個生成します。
そして、そのhypothsisを与えたときのsource sentenceの確率を評価しランキングします。
このようにすると、例えば、生成された文章があまり意味を持たない「そうですか。」などの文章だった場合は、どんなsource sentenceにも当てはまるので\(P(\text{source sentence}|\text{hypothesis})\)が小さくなります。
具体的で意味がある文章ほど、 \(P(\text{source sentence}|\text{hypothesis})\)が大きくなるという仕組みです。
なお、他にも\(P(\text{source sentence}|\text{hypothesis})\)を報酬\(R\)として強化学習の枠組みを適用したようですが、うまくいかなかったとのことです。
実験
では、DialoGPTを使った実験の手順や結果を見ていきましょう。
手順
モデルの大きさを変えた、以下の3パターンのモデルを試しています。

一番大きいモデルで7億6200万パラメータになっており、これはGPT-2の2番目に大きなモデルと同じ設定です。
ちなみに、GPT-3では1800億パラメータとさらに巨大化していますので、DialoGPT-3のようなものが出てくるのかもしれません。
設定の詳細については論文をご参照ください。
結果
DSTC-7 Dialog Generation Challenge
DSTC(Dialog System Technology Challenges)-7というコンペで使われたデータセットを評価データとして使用します。
DSTCデータセットは、対話システムのためのデータセットですが、その7回目のDSTCで使われたデータセットになります。
レストランの予約や電車の時刻検索など最終的な答えのある対話ではなく、これといった答えがないような質問に答えるタスクになっています。
また、対話システムの中にはおしゃべりのためのシステムもあり、それはそれで重要ですが、ここでは知識をもとに対話をするということが目的になっています。
以下のようなサンプルになっています。

Turn 1からTurn 4が会話になります。
詳細は以下の論文をご参照ください。
Grounded Response Generation Task at DSTC7
このデータセットのうち、6回以上の返答があるサンプルに限定します。
最終的にのこった2208個のサンプルをテストデータセットとします。
なお、DSTCデータセットのテストデータにはRedditのデータも含まれていますが、期間の重複がないのでそこは問題ありません。
評価指標はBLEUスコア、METEORスコア、NISTスコアなどを使います。
ベンチマークモデルとして、Microsoft社が提供するPersonalityChatというTwitterデータで学習したLSTMベースのSeq2Seqモデルと比較します。
BLEUスコア、METEORスコア、NISTスコアを使った自動評価結果は以下のようになっています。
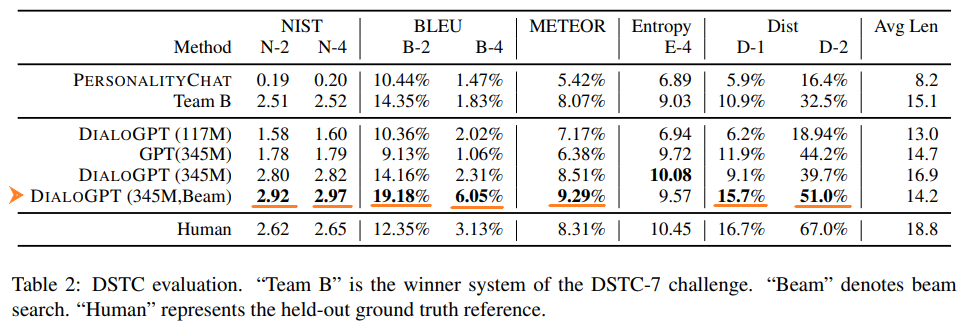
PersonalityChat、Team BよりもDialoGPTの精度の方が高くなっていますね。
Team BというのはDSTC-7 challengeで優勝したモデルです。
モデルサイズはパラメータ数が345Mの大きなモデルの方が精度が高く、同じパラメータ数でも通常のGPTよりも対話システム用に学習したDialoGPTの方が精度が高くなっています。
また、一番良いのは345Mパラメータでビームサーチ(Beam Search)を使ったモデルになっています。
ビームサイズは10としています。
なお、DialoGPTはDSTCデータセットの学習データで学習していないので、あくまで事前学習したことで知識が習得されていることになります。
人間(Human)と比べても各スコアはDialoGPTが上回っています。
ただし、これは必ずしも人間よりも現実的な回答ができているというわけではなく、学習過程で各指標が高くなるような学習がされている可能性があります。
Reddit Multi-referenceデータセット
Redditの6000サンプルからなる新たなデータセットを作成し、検証を行います。
ここでは、一からスクラッチで学習したDialoGPTとGPT-2をベースにさらに追加学習したDialoGPTを比較します。
結果は以下のようになっています。
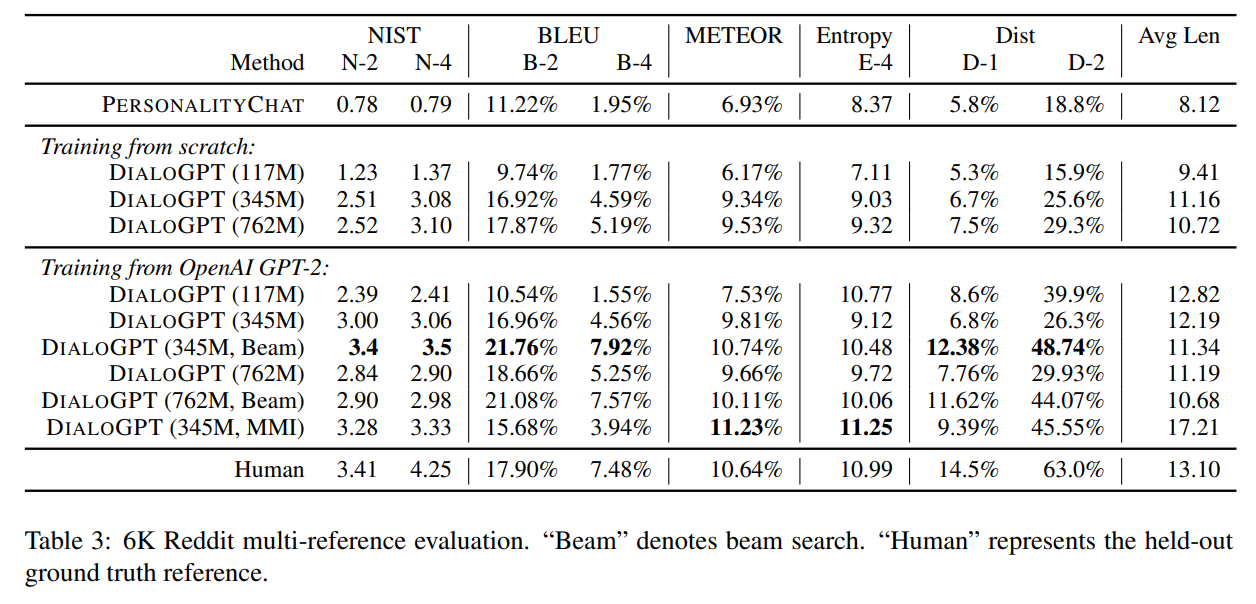
パラメータ数が117Mとモデルが小さい場合は、GPT-2に追加学習をした方がスコアが高くなっています。
パラメータ数が347Mや762Mと大きなモデルの場合は、スクラッチで作成してもほとんど差はなくなっています。
一番精度が高いのは、やはり345Mパラメータでビームサーチを使ったモデルになっており、このデータセットでも人間よりも評価は高くなっています(GPT-2から追加学習)。
MMIの効果
MMIにより大して意味を持たない回答を除くようにした場合、スコアはどのようになるか確認しています。
上表Table 3の下から2行目のDialoGPT(345M, MMI)がそれに該当します。
ビームサーチを使わないDialoGPT(345M)と比較すると、BLEUスコアは若干低下していますが、NISTスコア、METEORスコア、Entropyスコア、Distスコアについては改善しています。
生成例
実際のDialoGPTの生成例を見てみましょう。

はじめの3つは正しく答えていますね。
最後の「黒と白のシマ模様を持つ動物は何ですか?」と聞かれて「黒と白のシマシマの猫」と答えています…。
次に、複数回やりとるのある対話文の生成例です。Userの質問に対して、DialoGPTを使ったBotが回答します。

下手な訳で恐縮ですが、、、
「お金で幸せは変えますか?」
「どれぐらいのお金を使うかに依ります」
「幸せを買う一番良い方法は何でしょう?」
「単に20代前半でミリオネアになるだけで、幸せになることができます」
「それは難しすぎます!!」
「あなたはミリオネアになり幸せになることがどれだけ難しいかをわかっていません。金持ちがたくさんお金を持っているには理由があります」
とのことです。
面白いですね。
次に、ユーザーの質問に対してボットが一人で色々回答するパターンです。

どれも人間が答えているのと変わらず、違和感はありませんね。
人間による評価
今まではBLEUスコアなどを使って評価してきましたが、ここでは実際に人間の目でみて評価をしています。
Redditデータセットの6000サンプルのうちランダムに2000サンプルを使って、クラウドソーシングで評価してもらいます。
評価は以下のような画面で行います。

2つの比較するシステムが生成した文章のペア(例えばDialoGPT(345M)とPersonalityChatやDIalogGPT(345M)と人間など)に対して、1. 妥当性、2. 有益性、 3. 人間らしさの3つのカテゴリを比較してもらいます。
評価は1つめの文章が良い、どちらでもない、2つめの文章が良いの3つになっています。
では、結果を見ていきましょう。
結果は以下です。
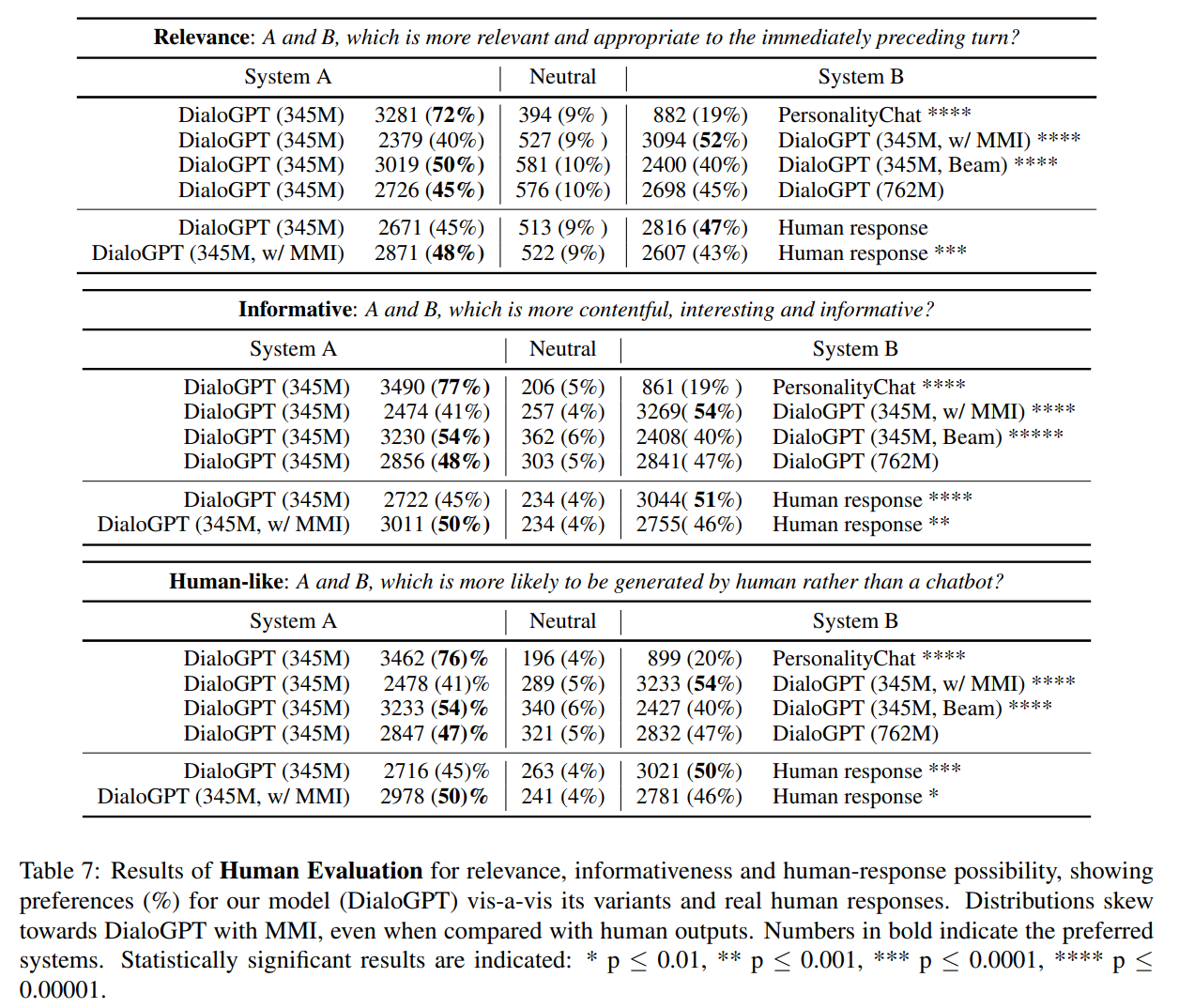
まず、上の表は3つのパートからなっていますので、一つ目から見ていきましょう。
一つ目は、妥当性(relativeness)についてです。
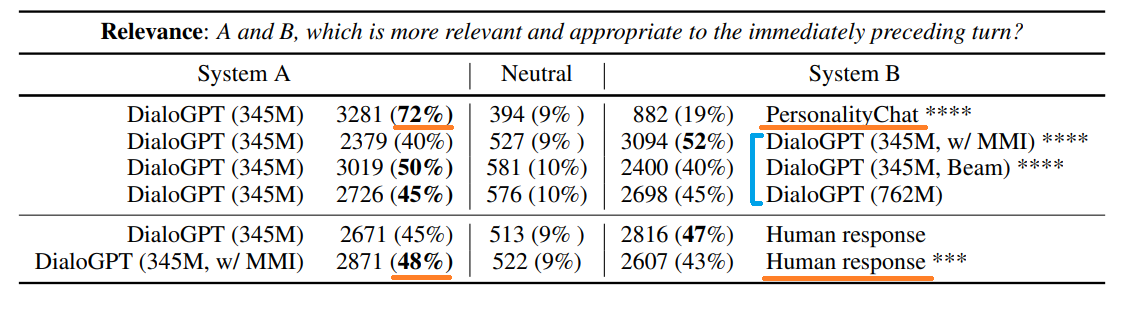
1行目はDialoGPT(345M)とPersonalityChatの比較ですが、こちらはDialoGPTの方が良いと言った人が72%となっています。
2~4行目はDialoGPT同士sの比較です。
BLEUスコアなどの指標ではビームサーチを使ったDialoGPTが良いという結果ですが、人間による評価ではMMIを使ったモデルの方が良いという結果になっています。
最後に、人間が生成した文章との比較ですが、なんとDialoGPTのMMIを使ったモデルが人間の生成した文章よりも良いと評価されています。
その要因としては、人間は少しわかりにくい表現などを使うことがあるからかもしれないとのことです。
他の有益性や人間らしさもほぼ同様の結果ですので、ご確認ください。
まとめ
今回はGPT-2を対話システムに応用したDialoGPTを紹介しました。
対話システムは自然言語処理分野でも実務への応用が非常に期待されている分野ですので、さらに発展していくといいですね。
対話システムについてはこちらの本が詳しく、非常に面白いです。
では、またお会いしましょう!