さて、以下の記事ではDiffusionモデルについて解説をしましたが、今回はそのDiffusionモデルを応用してDALL-Eのようにテキスト情報から画像を生成するモデル「GLIDE(Guided Language to Image Diffusion for Generation and Editing)」について解説したいと思います。

画像生成でGANを超えた『Diffusion Models Beat GANs on Image Synthesis』とかなかなか刺激的なタイトルもあり最近話題になっているDiffusionモデルですが、今回は「テキスト(キャプション)から画像を生成するタスクでDALL-Eを超えた」というのがこのGLIDEです。
DALL-Eって何?という人はこちらの記事をご参照ください。非常に面白い画像が生成できる話題のモデルです。

ちなみにDALL-EもそうですがGLIDEもOpenAIから提案されているモデルです。
DALL-Eで使われているモデルのベースはVQ-VAE(Discrete VAE)ですが、VQ-VAEなどのVAE系はGANと比べるとまだ画像が鮮明でないという課題がありました。
一方で最近話題のDiffusionモデルではGANを超えるほどのクオリティを持つ画像を生成することが可能になってきています。
ですので、VQ-VAEベースのDALL-EよりもDiffusionモデルベースのGLIDEが画像の質で上回るのも必然かもしれません。
しかしながら、GLIDEは画像の質だけではなく、キャプションと画像の関連性でもDALL-Eを上回っています。
しかも、DALL-Eでは画像を生成したあとにCLIPを使ってキャプションと画像の関連性をランキングし、より合っている画像を選択していましたが、GLIDEではそういった選択をしていません。
論文にある一例を見てみましょう。
以下の文章から生成された画像です。
ソファの上の壁にコーギーの絵が描かれていて、ソファの前には丸いコーヒーテーブルがあり、コーヒーテーブルの上に花瓶がある居心地の良いリビングルーム。
“A cozy living room with a painting of a corgi on the wall above a couch and a round coffee table in front of a couch and a vase of flowers on a coffee table”
左上が(a) DALL-E、右上が(b) guidanceをしないGLIDE、左下が(c) CLIP guidanceを使ったGLIDE、右下が(d) classifier-free guidanceのGLIDEです。

どれもうまくできていますが、(a) DALL-Eは少しぼやけている感じがしますね。
結論としては(d)が一番良いということですが、(b)のunguidedよりも多様性がなくなっているのがわかります。
こちらはguidanceというテクニックを使って、多様性と画像の質を調整していることによるものです。
では、その話題のGLIDEを以下の原論文に沿って解説していきたいと思います。
『GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models』
なお、分量が多いため、詳細ではなく感覚的な説明をしている部分もありますので、そのあたりはご自身で論文を確認していただければと思います(どこかのタイミングで各要素の詳細を解説する記事を作りたいとは思っていますが、いつになるかわかりません…)。
また、以下の記事では実際に公開されているGLIDE(filtered)を使って画像生成を行っています。

フルのデータセットで学習されたモデルではないので、DALL-Eの論文のようなことはできませんが、イメージは沸くと思いますので、よかったらご参考にしてください。
目次
Diffusion Modelの概要
GLIDEはテキスト情報をインプットとして、テキスト情報に合った画像を生成するモデルです。
そこで使われているのがDiffusionモデルと呼ばれる仕組みで、Diffusionモデル自体はもともと画像を生成するモデルであり、それをテキスト情報に合った画像を生成するモデルに改良したものがGLIDEと言えます。
ここでは、以下の論文で提案された通常の(Denoising)Diffusionモデルによる画像生成をさらっと説明します。
『Denoising Diffusion Probabilistic Models』
詳細について知りたい方は、以下の記事を参考にしていただければと思います。
diffusionモデルは、以下の図のように(1) forward processと(2) reverse processの2つの過程を考えます。
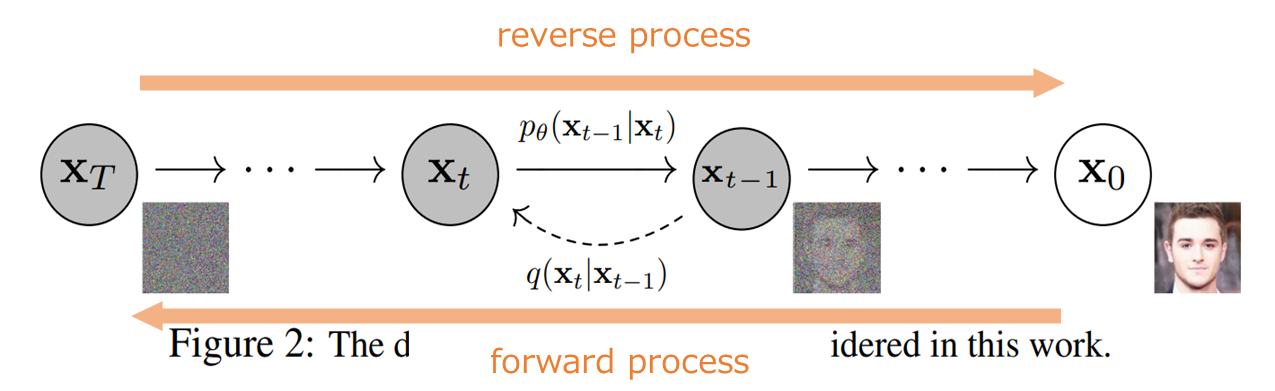
forward processは画像にノイズを加えていって、最終的にはノイズだけになる確率過程です。
一方のreverse processはforward processの逆で、ノイズから画像になっていく確率過程です。
つまり、画像にノイズを加えていって、最終的にノイズのみになる確率過程を考え、その逆をたどることでノイズから画像を生成することができる、というものです。
こちらはさらにざっくりイメージです。
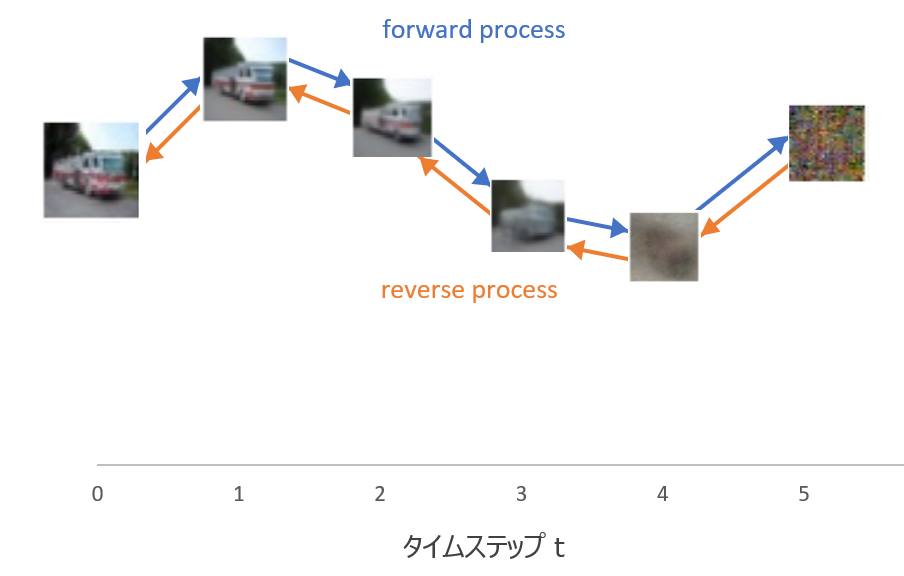
上記の図で言うと、forward processは\({\bf{x}}_0\)にノイズを加えて\({\bf{x}}_1\)、\({\bf{x}}_2\)、...となり、最終的に\({\bf{x}}_T\)というノイズだけになります。
reverse processはその逆をたどり、ノイズ\({\bf{x}}_T\)から画像\({\bf{x}}_0\)を生成します。
\({\bf{x}}_T\)を平均ゼロ、分散1の標準正規分布とすることで、まず標準正規分布に従うノイズを生成し、そこからreverse processで画像を生成することができます。
画像にノイズを加えていくforward processは、以下の正規分布に従うマルコフ過程で定義されます。
forward processの確率過程
$$\begin{align}
q_\theta({\bf{x}}_{1:T}|{\bf{x}}_{0}):&=\prod^T_{t=1}q({\bf{x}}_{t}|{\bf{x}}_{t-1}),\tag{1}\\
q({\bf{x}}_{t}|{\bf{x}}_{t-1})&=N({\bf{x}}_{t}; \sqrt{1-\beta_t }{\bf{x}}_{t-1}, \beta_t {\bf{I}}) \tag{2}
\end{align}$$
\(N\)は正規分布の分布関数を表します。
そして、forward processの分散\(\beta_t\)が小さい場合、reverse processも同じ関数形で表されることが知られており、以下のように定義されます。
reverse prcessの確率過程
$$\begin{align}
p_\theta({\bf{x}}_{0:T}):&=p_\theta({\bf{x}}_{T})\prod^T_{t=1}p_\theta({\bf{x}}_{t-1}|{\bf{x}}_{t}), \tag{3}\\
p_\theta({\bf{x}}_{t-1}|{\bf{x}}_{t})&=N\left({\bf{x}}_{t-1}; \mu_\theta({\bf{x}}_t, t), \Sigma_\theta({\bf{x}}_t, t)\right) \tag{4}
\end{align}$$
この\(\theta\)がニューラルネットワークのパラメータです。
そして、VAEのように変分下界を最大化することでノイズから画像を生成するreverse processのパラメータを求めるというのがDiffusionモデルです(変分下界についてはこちらの記事『【Tensorflowによる実装付き】Variational Auto-Encoder(VAE)を理解する』をご参照ください)。
上記の論文では、下界の最大化ではなく、以下のノイズを加えた画像からノイズを再構築するという目的関数に単純化した方法を提案しています。
$$L_\text{simple}(\theta)=\mathbb{E}_{{\bf{t}}, {\bf{x}}_0, {\bf{\epsilon}}}\left[\| \epsilon-\epsilon_\theta \left(\sqrt{\bar{\alpha}}{\bf{x}}_0
+\sqrt{1-\bar{\alpha}_t}\epsilon, t \right) \|^2\right]$$
これがDenoising Diffusionモデルです。
ただし、この論文の実験では\(\Sigma_\theta\)はニューラルネットワークのパラメータとせず固定値にした方が結果がよかったため、分散の項は固定値にしています。
\(\Sigma_\theta\)の学習
Diffusionモデルは1000ステップなどステップ数が多く、GANやVAEに比べて画像の生成に時間がかかるという問題がありました。
そこで、ステップ数を減らす改良が提案されてきました。
上記のDenoising Diffusionモデルではreverse processの共分散項\(\Sigma_\theta\)はニューラルネットワークで求めるパラメータとせずに固定値にしていましたが、以下の論文では、ステップ数が少ない場合は\(\Sigma_\theta\)は学習させて方が良く、分散のパラメータも学習することでステップ数を減らしても画像の質が落ちないようにすることができることを発見しました。
『Improved Denoising Diffusion Probabilistic Models』
この際にニューラルネットワークで直接\(\Sigma_\theta\)を求めるのではなく、以下の\(v\)を求めるようにしています。
$$\Sigma_\theta=\exp\left(v\log\beta_t+(1-v)\log\tilde{\beta}_t\right)$$
\(\beta_t\)はforward processの分散の項で、\(\tilde{\beta_t}\)は以下で表されます。
$$\tilde{\beta}_t = \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t}\beta_t $$
そして、\(\beta_t\)と\(\tilde{\beta}_t\)を補間する係数\(v\)を求めるというものです。
また、目的関数を\(L_\text{simple}\)の最小化から\(L_\text{simple}+\lambda L_\text{VLB}\)というハイブリッドな損失関数の最小化としています。
\(L_\text{VLB}\)は通常の変分下界(Variational Lower Bound)による損失関数で、\(\lambda\)はハイパーパラメータです。
ステップ数を小さくすると、それだけ学習が速くなりますので、GLIDEでも同じように\(\Sigma_\theta\)を学習させます。
これにより、もともと1000ステップ必要だったのモデルが100ステップで同レベルの画像を生成できるようになりました。
Guided Diffusion
上記のDenoising Diffusionモデルを、質(fidelity、quality)と多様性(diversity)を調整できるように改良したのが、以下の論文で提案されたGuided Diffusionモデルです。
『Diffusion Models Beat GANs on Image Synthesis』
この論文では、クラスラベルを与えた場合の画像の生成について改良を行っています。
BigGANでは、画像の生成時に潜在変数(ノイズ)をサンプリングする際に、正規分布の端の方はサンプリングしないように、truncateすることで、多様性(diversity)は下がるものの、より質(quality, fidelity)の高い画像のみを生成することを可能にしていました。
それと同様の考えで、単にインプットにラベルを与えて学習・生成するだけでなく、より本物らしい画像を生成するために、本物らしい画像に誘導するというものです。
それがClassifier guidanceです。
Classifier guidanceは、サンプリング時に別途用意した分類モデル(classifier)を使ってラベル通りの画像を生成するように誘導(guidance)する、というものです。
具体的な方法としては、まず、ラベルもインプットとしてDiffusionモデルを学習します。
これでラベルにあった画像の生成が可能になります。
そして、画像生成時にImageNetなどで学習された分類モデルを使用してラベルにあった画像を生成していくように誘導するというものになります。
どのように生成するかを見てみましょう。
この別途学習した分類モデルによる評価\(p_\phi(y|x)\)の勾配\(\nabla_{x_t}\log p_\phi(y|x_t)\)を利用します。
diffusionモデルでサンプルを生成するには、
$$p_\theta(x_{t-1}|x_t)=N(x_{t-1};\mu_\theta(x_t|y), \Sigma_\theta(x_t|y))$$
に従って、次のサンプルを生成します(\(\mu_\theta\)は\(\epsilon_\theta\)から計算できます)。
その際に、
$$\hat{\mu}(x_t|y)=\mu_\theta(x_t|y)+s\sigma\nabla_{x_t}\log p_\phi(y|x_t)$$
と、分類モデルの勾配を利用して、平均を\(s\cdot\sigma\cdot\nabla_{x_t}\log p_\phi(y|x_t)\)だけずらします。
\(s\)はスケールパラメータで、それが大きいほど分類モデルがうまく判別できる方向に、より強く画像を引っ張っていくことになります。
感覚的には、\(x_t\)から\(x_{t-1}\)に動く方向の平均である\(\mu_\theta\)を、ラベル\(y\)の方向\(\nabla_{x_t}\log p_\phi(y|x_t)\)に向けるというものです。
パラメータ\(s\)を調整することより、BigGANで使われたノイズのtruncateのように、画像の質(fidelity)と多様性(diversity)を調整することが可能になります。
このclassfier guidanceをラベルではなく任意のキャプションに対する画像生成に応用したのが、あとで出てくるCLIP guidanceです。
(CLIPをよくご存じの方にはキャプションに対しては分類モデルの代わりにCLIPを使うというのは自然に感じるかもしれませんね)
Guided Diffusionの問題点
Guided Diffusionを使ってラベルで条件付けした画像を生成するには、別途ImageNetなどで学習した分類モデルを用意する必要があります。
しかも、きれいな画像だけでではなく、ノイズが混ざったものに対しても分類できないといけないので、ノイズを加えた画像も分類できるよう別途学習してモデルを作成しないといけません。
別途学習する必要をなくして、Diffusionモデルも分類モデルも同時に学習させようというのが、このあとに出てくる①Classifier-free Guidanceです。
また、今回は決められたラベルから画像を生成するのではなく、任意のキャプションから画像を生成しないといけません。
そこでclassifier guidanceのclassifierとしてCLIPを使おうというのが②CLIP guidanceになります。
classifier-free guidanceとCLIP guidanceが並列に出てきているのでややこしいですが、分類モデルを別途学習する必要をなくしたclassifier-free guidanceとキャプションに対応するために分類モデルの代わりにCLIPを使うclassifier guidanceに分かれています。
- classifier-free guidance
分類モデルを別途学習せず、生成される画像をよりテキスト情報に合うように調整する方法 - CLIP guidance
CLIPを別途学習し、そのモデルを使って生成される画像をよりテキスト情報に合う画像に調整する方法
結論を先に言うと、classifier-free guidanceの方がclip guidanceよりも良いという結果になります。
Classifier-free Guidance
Classifier-free guideという考え方自体はGLIDEで初めて提案されたのではなく、以下の論文で既に提案されています。
『Classifier-Free Diffusion Guidance』
この手法では別途分類モデルを用意する必要はなく、Diffusionモデルと分類モデルを同時に学習します。
まず、条件付きの画像生成は、ラベルもインプットとして、\(\epsilon_\theta(x_t|y)\)をニューラルネットワークで求めることで可能です。
ここがポイントですが、学習時に\(y\)を一定の確率でnull label \(\emptyset\)に置き換えます。
つまり、画像をラベルなしで学習する場合とラベル付きで学習する場合があるということです。
これで無条件の画像生成とラベル付きの条件付き画像生成を学習します。
そしてサンプリングの際は、\(\epsilon_\theta(x_t|y)\)を
$$\hat{\epsilon}_\theta (x_t|y)=\epsilon_\theta (x_t|\emptyset)+s\cdot\left(\epsilon_\theta(x_t|y)-\hat{\epsilon}_\theta (x_t|\emptyset)\right)$$
という感じで\(\epsilon_\theta(x_t|y)\)の方に誘導するように調整します。
\(s\)はスケールパラメータで、これが大きいほど、条件付けした画像の方に強く引っ張られます。
考え方自体はclassifier guidanceと同じで、無条件のノイズ\(\hat{\epsilon}_\theta (x_t|\emptyset)\)を\(\epsilon_\theta(x_t|y)\)の方向に動くように仕向けるというものです。
GLIDEの場合だとテキスト情報(Caption)なので、これを\(c\)とおいて、
$$\hat{\epsilon}_\theta (x_t|c)=\epsilon_\theta (x_t|\emptyset)+s\cdot\left(\epsilon_\theta(x_t|c)-\hat{\epsilon}_\theta (x_t|\emptyset)\right)$$
で画像を生成します。
一応理屈としては、(implicitな)分類モデルは
$$p^i(y|x_t)\propto \frac{p(x_t|y)}{p(x_t)}$$
と書けるので、\(\epsilon^*\)をスコアとすると
$$\begin{align}
\nabla_{x_t}\log p^i(y|x_t)&\propto \nabla_{x_t}\log p(x_t|y)- \nabla_{x_t}\log p(x_t)\\
&\propto \epsilon^*(x_t|y)- \epsilon^*(x_t)
\end{align}$$
という関係があり、ここから導かれるものです。
非常に雑な説明になってしまいましたが、最後のスコアのところはscore matchingという考え方で、diffusionモデルと関連の深いモデルになっていますので、興味のある方はこちらの論文をご参照下さい(いつかこちらも解説できればと思っていますが…)。
『Generative Modeling by Estimating Gradients of the Data Distribution』
以上が別途分類モデルを使わない手法です。
CLIP Guidance
次に、別途モデルを用意する手法です。
classifier guidanceでは、分類モデルを使用していましたが、ImageNetなどで学習した分類モデルは任意のキャプションには対応していません。
そこで、CLIP(Contrastive Language-Image Pre-training)というモデルを使用します。
CLIPについてはこちらの記事をご参照ください。

CLIPは画像の埋め込み表現\(f(x)\)とキャプションの埋め込み表現\(g(c)\)の内積を計算し、関連性が高いペアほどこの内積が大きくなるように学習するものでした。
つまり、この内積が大きいほど画像とキャプションの関連性が高くなるので、画像を生成する際に、このCLIPによる内積が大きくなるように誘導するという考え方です。
具体的には、ニューラルネットワークで求める平均\(\mu_\theta(x_t|c)\)を以下のように勾配分だけずらします。
$$\hat{\mu}_\theta(x_t|c)=\mu_\theta(x_t|c)+s\cdot\Sigma_\theta(x_t|c)\nabla_{x_t}\left( f(x_t)\cdot g(c)\right)$$
このCLIP guidanceはclassifier-freeではないので、CLIPの学習済みモデルが必要になります。
さらキレイな画像だけを学習したCLIPではなく、ノイズが付いた画像を評価できるCLIPモデルが必要になるので、ノイズ画像に対しても学習しないといけません。
実験
モデル
ではざっくりとモデルの説明をしますが、詳細については論文をご参照ください。
Diffusionモデル
まず、Diffusionモデルは以下で提案されているADM(Ablated Diffusion Model)モデルを使います(Classifier guidanceが提案された論文です)。
『Diffusion Models Beat GANs on Image Synthesis』
AWDモデルは、もともと提案されていたU-Netと仕組みは大きく変わりませんが、チャネル数やattention headの数を変えたり、Adaptive Group Normalizationを適用したりといった改良をしたものです。
テキスト情報
そして、テキスト情報のエンコーディングはTransformerを使います。
Transformerはキャプションである文章を\(K\)個のトークン列を受け取り処理をします。
そのうち、最後のトークンの埋め込み表現をADMモデルのインプットであるクラス情報(class embedding)とします。
さらにTransformerの最終レイヤの埋め込み表現(\(K\times n_{dim}\))をADMモデルのattentionレイヤのインプットとします。
ADMモデルは23億パラメータ、Transformerは12億パラメータです。
データセット
データはDALL-Eと同じデータセットを使います。
詳細はこちらの記事に記載していますが、インターネットから集めてきた画像とテキスト(Alt-text)のペア2億5000万サンプルです。
Diffusionモデルの学習
このADMモデルの学習は、64x64の画像で行います。
つまり、このDiffusionモデルではキャプション情報を使って64x64ピクセルの画像を生成します。
Upsampling
64x64ピクセルの画像を生成したら、別途用意して学習するupsampling用のDiffusionモデルで256x256にupsamplingします。
このupsampling用のDiffusionモデルは15億パラメータです。
ファインチューニング
キャプションで条件付けしたDiffusionモデルをまず学習し、そのあとに無条件で画像を生成することができるように、ファインチューニングを行います。
このファインチューニングも通常の(事前)学習と同様ですが、学習データのうち20%について、キャプションを\(\emptyset\)に置き換えます。
これにより、無条件の画像も学習できます。
サンプリング
サンプリングの時は、前述の通り、
$$\hat{\epsilon}_\theta (x_t|c)=\epsilon_\theta (x_t|\emptyset)+s\cdot\left(\epsilon_\theta(x_t|c)-\hat{\epsilon}_\theta (x_t|\emptyset)\right)$$
として\(\hat{\epsilon}_\theta (x_t|c)\)の求めます。
そして、そこから\(\mu_\theta (x_t|)\)を計算して\(x_t\)を順番に生成していきます。
CLIP guidance
CLIP guidanceについてはCLIPをノイズ付きの画像でも学習させています。
結果
では結果をさらっと見ていきましょう。
まず、classifier-free guidanceによるキャプションから生成した画像です。
写真、絵、ステンドグラス、ピクセルアートなどすごくよくできていますね。

次は、画像の一部を塗りつぶして、キャプション通りに画像を生成しています。
塗りつぶした部分にシマウマを描画したり、髪の毛を赤にしたりといったことが自然にできていますね。

良くできているもんだと感心しますが、続いて定量的な評価を見ていきます。
まず、CLIP guidanceとclassifier guidanceの比較ですが、他にも結果はありますが、ここでは人間の目で比較した結果を見てみます。
以下は、CLIP guidanceとclassifier-free guidanceでどちらの画像がより本物らしいか、キャプション合っているかを選んだ結果です(スコアに変換されており、詳細は論文のappendixに載っています)。
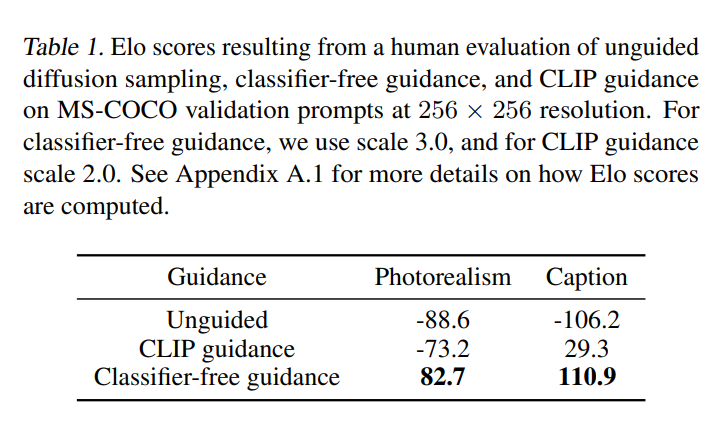
プラスで大きい方が良いのですが、本物らしさ、キャプションに合っているかの両方について、CLIP guidanceよりもclassifier-free guidanceがよい評価になっています。
DALL-Eとの比較
では、DALL-EなどのモデルとFID(Frechet Inception Distance)を比較します。
zero-shotでないFIDもありますが、正確な比較はできないので参考としておきます。
FIDは小さいほど良い指標です(FIDについてはこちらの記事『Frechet Inception Distance(FID)を理解する』を参照ください)。
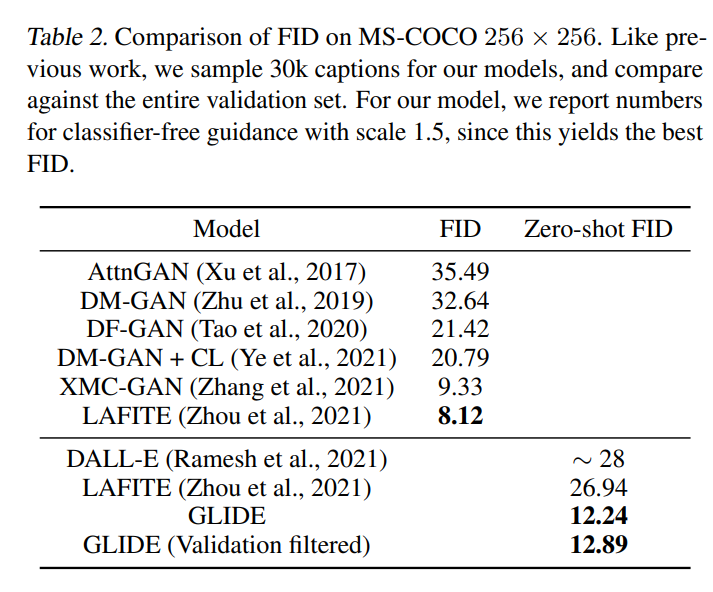
下段のDALL-Eとの比較ではGLIDEの方が小さく、精度として上回っていることがわかります。
続いて、人間の評価です。
DALL-Eで、CLIPを使ってランキングしない場合と、ランキングした場合、それぞれと比較しています。
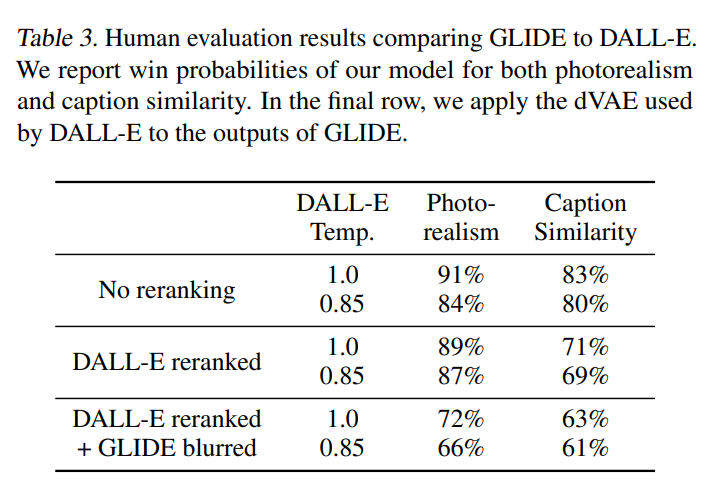
中段のDALL-Eとの比較を見ると、本物らしさではGLIDEが圧勝ですね。
これはVQ-VAEが多少画像がぼやけるというの一つの要因です。
キャプションとの類似性についてもGLIDEが勝っています。
VQ-VAEがぼやけることが一つの要因と書きましたが、一番下は、前述のVQ-VAEはぼやけるという要因を除いて比較した場合です。
GLIDEをVQ-VAEを使ってぼやけた画像にしているそうです(何となく想像はできますが詳細がわからないので触れないようにします)。
それでもGLIDEの方が上回っているので、VQ-VAEがぼやけることだけが要因ではなく、それを除いてもGLIDEの方が配置など本物らしい画像を生成できるようです。
最後に、画像を見て比較しましょう。
一番上から、本物の画像、GAN、DALL-E、CLIP guideのGLIDE、Classifier-freeのGLIDEとなっています。

少なくとも画像の鮮明さでDALL-Eを上回っているのは間違いなさそうです。
GLIDE同士では、一番左の列車の画像を見るとclassifier-free guidanceのGLIDEの方が良さそうです。
まぁやっぱり本物が一番本物っぽいですね…。
まとめ
今回はDALL-Eを超えたというGLIDEを見てきました。
定量的にも視覚的にも確かにDALL-Eを超えているように見えますね。
他にも比較分析やサンプル画像がありますので、ご自身でもご確認いただければと思います。
Diffusionモデルはまだまだ発展していきそうなので楽しみですね。
Classifier guidanceの詳細など、結構説明しきれていいない部分もあるので、今後別の記事で説明していければと思います!
早く知りたい方は論文をご参照ください。
また、以下の記事では実際に公開されているGLIDE(filtered)を使って画像生成を行っています。
フルのデータセットで学習されたモデルではないので、DALL-Eの論文のようなことはできませんが、イメージは沸くと思いますので、よかったらご参考にしていただければと思います。
では!