今回は自然言語処理のブレイクスルーとなったBERTの事前学習方法を改良し、GeneratorとDiscriminatorを使った事前学習することで、BERTを大きく上回る精度を出したELECTRAの解説をしたいと思います。
ELECTRAはBERTで使っているMasked Language Modelが「文章中のマスクした15%しか学習できない」ということに着目し、それを改善するような事前学習方法を提案しています。
GAN(Generative Adversarial Network; 敵対的生成ネットワーク)のようなアイデアを自然言語処理の事前学習に流用した非常に面白い論文だと思います。
論文はこちらです。
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
目次
ELECTRAとは
ELECTRAとは、Efficiently Learning an Encoder that Classifies Token Replacements Accuratelyの略で、その名の通り、“置き換えた単語を適切に分類する方法を効率的に学習するエンコーダー”です。
と言っても、何のことかわからないと思いますので、もう少し説明します(すぐにこの意味がわかると思います)。
モデルの仕組みはTransformerを使ったBERTとほぼ同じで、事前学習の方法にGAN(Generative Adversarial Networks; 敵対的生成ネットワーク)のアイデアを取り込み、事前学習の質を高めるものです。
BERTの事前学習のどこに課題があったかというと、BERTでは文章中の15%の単語を[MASK]に置き換え、この部分の元の単語が何だったかを予測することで、言語モデル(Language Model; LM)の事前学習をしていました。
これをMasked Language Model(MLM)と呼びます。
これがまさにBERTを双方向にした核の部分だったのですが、一方で以下のような問題があります。
- 文章中の単語のの15%しか学習しないので効率が悪い。
- 事前学習には[MASK]という単語が出てくるが、ファインチューニングでは文章中には[MASK]という単語は出てこないので、ミスマッチが起こる。
1つめについては、片方向の言語モデルでは次の単語、次の単語と予測していく方法では文章中のすべての単語を予測するので起こらない問題ですが、Masked Language Modelを使って言語モデルを双方向にするには、(すべてをマスクするわけでにはいかないので)必要な犠牲と考えられていました。
2つめはBERTの論文にも指摘されている部分で、その後のXLNetなどの論文でも指摘されていることです。
ですので、2つめに関してはBERTでも課題と認識しており、一定の対応は行っています。
これらの問題に対応するため、ELECTRAでは“replaced token detection”という考え方を使います。
結論からいうと文章の15%だけを予測するのではなく、すべての単語を予測する方法で精度を改善させます。
具体的な方法は、GANのように、①Generatorが文章中の15%の単語を別の単語に置き換え、②Discriminatorが置き換えた単語かどうかを学んでいきます。
①がBERTの言語モデル(Masked Language Model)に当たり、②を学習したものがELECTRAです。
つまり、BERTが文章の15%を書き換え、それを見破るように学習したものがELECTRAです。
ただし、GANではGeneratorもどんどん学んでいき、Discriminatorが本物か区別できないように仕向けていきますが(敵対的)、ELECTRAではそれはせず、Generatorは小さめのモデルを使い、ある程度Discriminatorが本物か区別できるようにしています。
そして、Discriminator部分だけをELECTRAとして使います。
この方法により、ELECTRAは文章の15%だけでなく、文章中の全単語について学習することができるので、言語モデルの事前学習を効率に行うことができ、計算時間は非常に少なくて済みますし、同じモデルサイズでも下流タスクでの性能が大幅に改善しています。
以下の図の通り、青色のMasked Language Modelによる事前学習に対して、同じ計算量(FLOPs)のReplaced Token Detectionによる事前学習モデルがGLUEデータセットのスコアで大きく上回っていることがわかります。
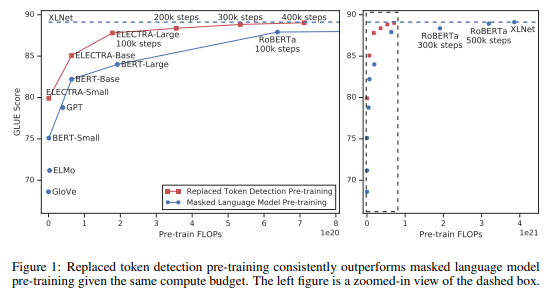
同じサイズでは、BERTやXLNetを上回り、小さいサイズでもBERTやより大きなモデルであるGPTをを超える性能が出ています。
では、ここまででいったん簡単に要点をまとめておきます。
- ELECTRAはBERTの仕組みと同じTransformerベースで、言語モデルの事前学習を効率的に行うことで、計算時間の短縮、モデル精度の改善を行った。
- BERTの文章中の15%の単語を[MASK]に置き換える“Masked Language Model”ではなく、ELECTRAではGenerator(小さいBERT)が文章中の単語を別の単語に置き換え、Discriminatorがそれを置き換えられた単語か元の単語かを予測するモデルを学習することで、言語モデルを学習する。(“replaced token detection”)
では、詳細に入っていきましょう。
事前学習手法
ELECTRAの考え方
ELECTRAの事前学習の方法は以下の図です。
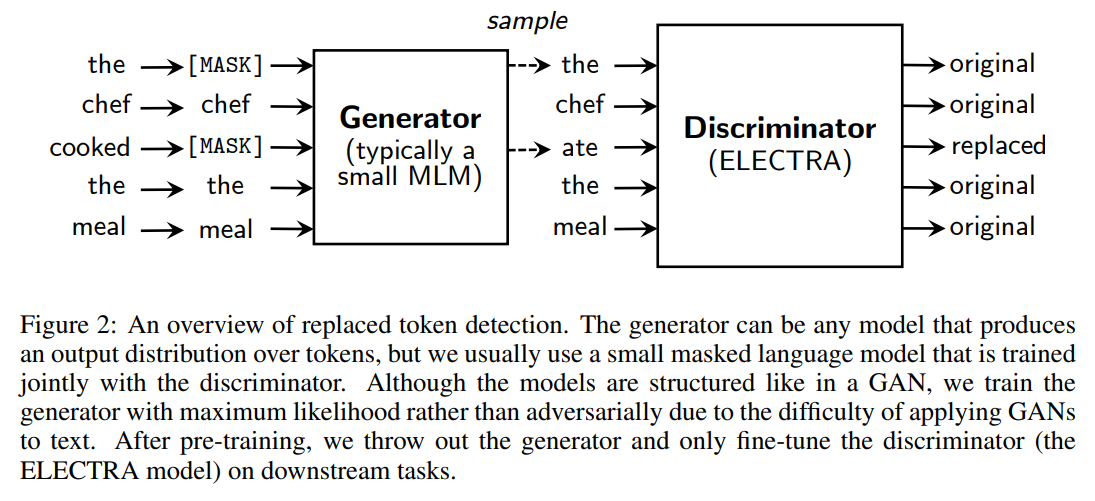
“the chef cooked the meal”という文章であれば、まず、そのうちいくつかの割合で(例えば15%)単語を[MASK]に置き換えます。
これが何の単語だったかを予測するのがBERTなどのMasked Language Modelでしたが、ELECTRAでは、Generatorがその[MASK]の部分を予測します。
ここで、図中に“typically a small MLM”とありますが、Generatorには小さめのモデルを使用します。
これは、Generatorが賢すぎると、Discriminatorが見分けられず、精度がそれほど改善しないという結果からです。
そして、出来上がった文章は“the chef ate the meal”です。
“the”の部分についてはGeneratorも“the”と予測しており、変更されていません。
“cooked”の部分が“ate”に変わっています。
“料理した”が“食べた”になっていますね。
主語はシェフなので、文章としてはあり得ますが、意味が少しだけ変です。
そして、Discriminator(ELECTRA)がどの部分が置き換えられているか?、どの部分が置き換えられていないか?を予測します。
この場合の正解は“ate”の箇所だけreplacedでそれ以外はoriginalです。
発想としては、[MASK]の部分だけを何という単語だったかを考えるよりも、すべての単語について正しい単語かどうかを考えることにより、フルで頭を使うようなイメージです。
「あ、[MASK]が出てきた!この単語は何かなぁ」ではなく、一つ目の単語からすべて「この単語は本物かなぁ?偽物かなぁ?」と考えるということで、[MASK]ではない部分もしっかり考えることにより、無駄がなくなるということです。
また、その単語が書き換えられていると予測したとしても、元の単語が何だったか?までは学習しません。
これは最後の「ELECTRAの学習効率の分析」のところで出てきますが、元の単語を予測しない方が学習効率が良いとのことです。
数式による解説
では、少し細かい部分を数式付きで解説します。
ただし、原論文と少し表記を変えている部分があります。
GeneratorをG、DiscriminatorをDとします。
インプットとなる単語を\({\bf{x}}=[x_1, \cdots, x_n]\)とし、その隠れ層のベクトルを\(h({\bf{x}})=[h_1, \cdots, h_n]\)とします。
Generatorによる単語の置き換え
そして、マスクする単語数を\(k\)とすると(例えば文章の15%とします)、1から文章の長さ\(n\)までの数字を一様分布に従うように\(k\)個取り出すことで、マスクする単語を選びます。
$$m_i \sim \text{unif}\{1, n\} \text{ for }i=1 \text{ to } k$$
つまり、\(m_i\)番目の単語をマスクするということです。
そして、\({\bf{m}}=[m_1, \cdots, m_k]\)に当たる単語を[MASK]で置き換え、
$${\bf{x}}^{masked}={\bf{\text{REPLACE}}}({\bf{x}},{\bf{m}},\text{[MASK]})$$
というマスクされた単語列を生成します。
そして、Generatorは各\(m_i\in {\bf{m}}\)に対し、
$$\hat{x}_i=p_G(x_{m_i}|{\bf{x}}^{masked})$$
で、もとの単語を予測します。
そして、そのマスクされた単語をGeneratorが予測した単語で置き換えることにより、“変換された単語列”を生成します。
$${\bf{x}}^{corrupt}={\bf{\text{REPLACE}}}({\bf{x}},{\bf{m}},\hat{{\bf{x}}})$$
Generatorが[MASK]に対して\(\hat{x}_i\)を求めるのは、softmax関数を使って
$$p_G(x_t|{\bf{x}})=\frac{\exp\left(e(x_t)^T h_G({\bf{x}})_t\right)}{\sum_{x'}\exp\left(e(x'_t)^T h_G({\bf{x}})_t\right)}$$
の確率で単語をアウトプットします。
ここで、\(e\)は単語の埋め込み表現を表します。
ようは、Generatorが思うもっとも確率の高い単語をアウトプットするということです。
これがDiscriminatorのインプットになります。
Discriminatorによる判定
次に、disciminatorがインプットの各単語\(x_t\)が本物か、それともGeneratorが作り出した単語かを以下で予測します。
以下のようにSigmoid関数で、本物であれば1に近く、Generatorが作り出した単語であれば0に近い値を出力します。
$$D({\bf{x}}, t)=\text{sigmoid}\left(w^T h_D({\bf{x}})_t\right)$$
損失関数
損失関数は以下のGenerator用の通常のMasked Language Modelの損失関数とDiscriminator用の損失関数の和になります。
$$\begin{align}
\mathcal{L}_\text{MLM}({\bf{x}}, \theta_G)&=\mathbb{E}\left(\sum_{i\in{\bf{m}}}-\log p_G(x_i|{\bf{x}}^\text{masked})\right) \\
\mathcal{L}_\text{Disc}({\bf{x}}, \theta_D)&=\mathbb{E}\left(\sum_{t=1}^n-\mathbb{I}_{x_t^\text{corrupt}=x_t}\log D({\bf{x}}^\text{corrupt}, t)
- \mathbb{I}_{x_t^\text{corrupt}\neq x_t}\log \left(1-D({\bf{x}}^\text{corrupt}, t)\right)
\right)
\end{align}$$
1つ目の\(\mathcal{L}_\text{MLM}({\bf{x}}, \theta_G)\)は、Generator側の損失関数で、これを最小化することでGeneratorが賢くなっていきます。
2つ目の\(\mathcal{L}_\text{Disc}({\bf{x}}, \theta_D)\)はDiscriminatorの損失関数です。
Discriminatorの1項目は、元の単語と変換後の単語が同じ場合で、その場合は\(D({\bf{x}}^\text{corrupt}, t)\)が1に近い(originalと予測する)ほどよく、2項目は元の単語が違う単語に変換されてる場合で、\(D({\bf{x}}^\text{corrupt}, t)\)が0に近い(replacedと予測する)ほど損失が小さくなります。
そして、GeneratorのMLMの損失とDiscriminatorの損失を以下のように合計したものを最小化します。
$$\begin{align}
\min_{\theta_G, \theta_D} \sum_{{\bf{x}}\in\chi } \mathcal{L}_\text{MLM}({\bf{x}}, \theta_G) +
\lambda\mathcal{L}_\text{Disc}({\bf{x}}, \theta_D)
\end{align}$$
ですので、ここはGANの目的関数のように敵対的にだます側と見やぶる側が競い合うのではなく、両方の尤度を最大化するという仕組みです。
論文によるとこの方がうまくいったとのことです。
実験
GLUEベンチマークやSQuADデータセットを使ったQuestion Aswewringタスクでモデルの性能を確認します。
ELECTRAのモデルは以下の2パターンを使います。
- Base
BERT-Baseと同じモデルサイズで、同じデータセット(English WikipediaとBooksCorpus)を使って事前学習します。 - Large
BERT-Largeと同じモデルサイズで、XLNetと同じデータセット(BERTのデータセットとClueWeb、CommonCrawl、Gigaword)を使って事前学習します。
モデルについて
基本的にモデルの仕組みはBERTと同じですが、ELECTRAにはGeneratorとDiscriminatorがあるので、一部ELECTRA用に改良している部分があります。
以下では、BERTと違う点について説明していきます。
ウェイトの共有
GeneratorとDiscriminatorで、単語の埋め込み表現と位置情報の埋め込み表現(positional embedding)のパラメータを共有します。
GeneratorとDiscriminatorのモデルサイズを同じにして、パラメータを共有する場合としない場合を比較すると、共有しない場合のGLUEスコアが83.6で、埋め込み表現のみを共有した場合84.3、すべてのパラメータを共有した場合84.4となり、パラメータを共有した方が精度が良くなったとのことです。
その要因としては、Generatorはマスクされた部分の単語が何か?をすべてのボキャブラリーを検討して予測しますが、Discriminatorは与えられた単語が本物か偽物かを判断するだけなので、その単語の埋め込み表現のみを更新するため、Discriminatorの学習が効率的に進まないと考えられます。
小さなGeneratorを使う
何度も出てきていますが、ELECTRAではGeneratorとDiscriminatorの2つを学習します。
ですので、GeneratorとDiscriminatorのモデルサイズを同じにした場合、普通のMasked LMと比べて2倍学習時間がかかることになります。
それを回避するために、Generatorのレイヤーのサイズを小さくすることで、小さなモデルにします。
以下の左の図はDiscriminatorのサイズとGeneratorのサイズの組み合わせによるGLUEスコアの値です。
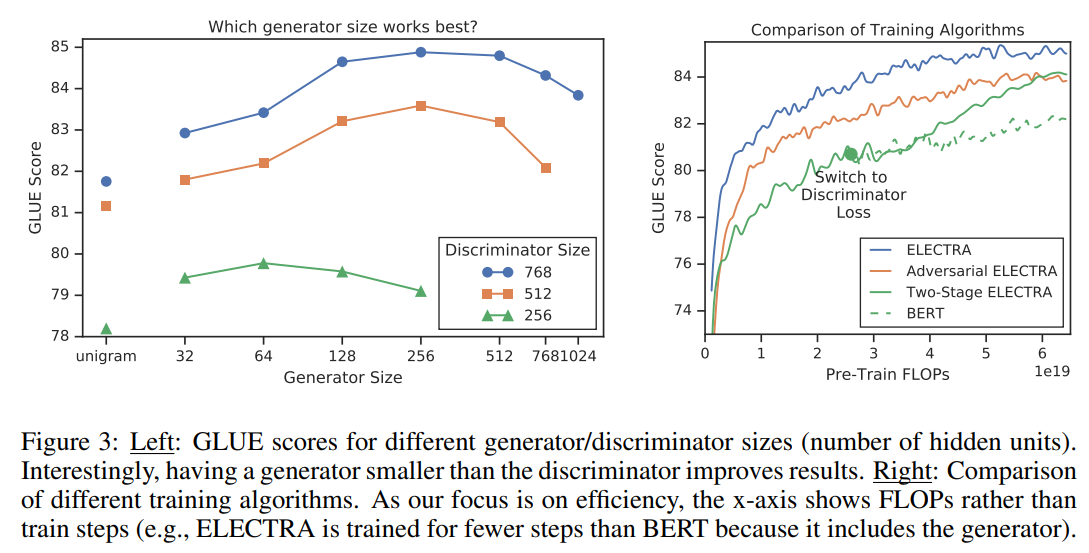
まず、Discriminatorのサイズが大きい方が精度が高くなっていることがわかります(青>オレンジ>緑)。
では、対応するGeneratorのサイズはどんなものが良いかというと、Discriminatorと同じぐらいのサイズよりも少し小さめの方が良いようです。
例えば、Discriminatorのレイヤーサイズが512の場合(オレンジ)、Generatorのサイズが256の場合に一番精度が高くなっています。
ちなみに、一番左のunigramというのは、コーパス中に出てくる中で最も頻度が高い単語を設定するという方法だそうです。
上の結果から、GeneratorはDiscriminatorよりも4分の1から2分の1程度の小さい方が良いということがわかります。
考えられる要因としては、Generatorが賢すぎるとDiscriminatorが見抜くのが難しすぎるのかもしれません。
学習アルゴリズム
前述の通り、ELECTRAでは、以下の目的関数を最適化します。
$$\begin{align}
\min_{\theta_G, \theta_D} \sum_{{\bf{x}}\in\chi } \mathcal{L}_\text{MLM}({\bf{x}}, \theta_G) +
\lambda\mathcal{L}_\text{Disc}({\bf{x}}, \theta_D)
\end{align}$$
他にも以下のような2段階の目的関数を最適化を試したようですが、結果はあまり良くなかったようです。
- まず、Generatorのみを\(\mathcal{L}_\text{MLM}\)についてnステップ学習する。
- GeneratorのウェイトでDiscriminatorのウェイトを初期化し、Generatorのウェイトは変えずに、Discriminatorだけ\(\mathcal{L}_\text{Disc}\)についてnステップ学習する。
ようするに、Generatorだけをまず学習し、そのあとDiscriminatorだけを学習するというものです。
2段階目のDiscriminatorのウェイトをGeneratorのウェイトで初期化しない場合、GeneratorがDiscriminatorよりも賢すぎるため、Discriminatorの学習が失敗することがあるとのことです。
他にもGANのように敵対的に学習させることも行っています。
その結果が以下の右の図です。
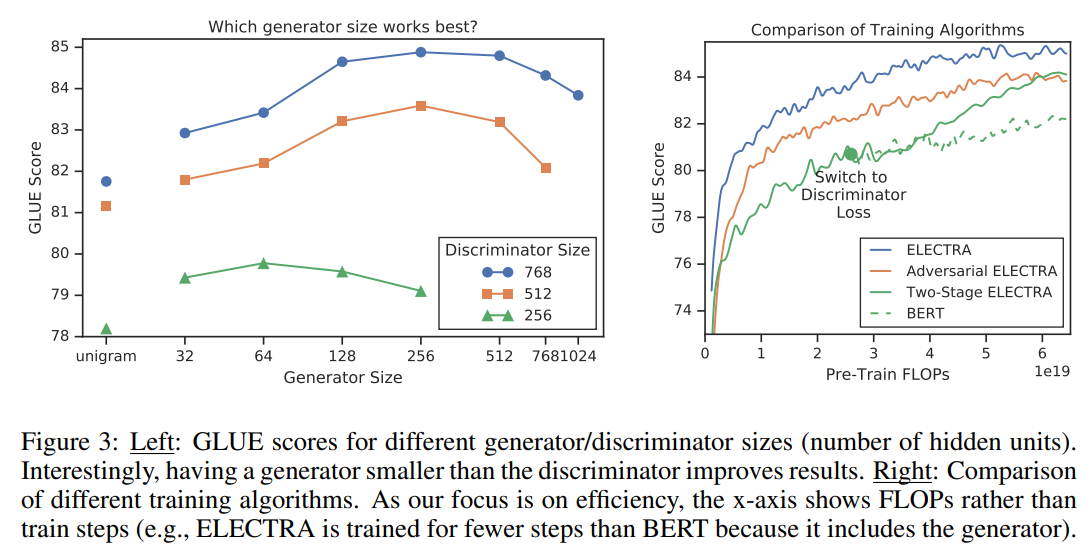
青の線がGeneratorとDiscriminatorを同時に学習する場合のGLUEスコア、オレンジが敵対的に学習する場合、緑の実線が2段階の学習、緑の点線がBERTです。
どれもBERTは上回っていますが、一番良いのはGeneratorとDiscriminatorを同時に学習する場合です。
緑の2段階の学習の場合、1段階目のGeneratorの損失最小化から2段階目のDeiscriminatorの損失最小化に進むと、一気に精度が改善していますが、それでもELECTRAを超えていません。
小さなモデルの結果
ここでは通常のBERTよりも小さいサイズのモデルを使ってBERTとELECTRAの学習効率について見ていきます。
小さいサイズとは文章の長さを512単語から128単語にし、 バッチサイズを256から128に減らします。また隠れ層の次元を768から258にし、単語の埋め込み表現を768次元から128次元に減らします。
結果は以下です。

BERT-SmallとELECTRA-SmallのGLUEスコアを比較すると、同じパラメーター数でELECTRA-Smallの方が4.8%精度が改善していることがわかります。
さらにELECTRA-Smallよりもはるかに大きい GPT に対しても1.1%程度上回っています 。
また、ベースサイズで比較するとELECTRA-BaseはBERT-Baseと比べて2.9ポイント上回っています。
これはBERT-Largeも上回っている水準です。
大きいモデルの結果
続いて大きなサイズのモデルについて見ていきます。
大きなサイズのモデルについては XLNetと同じデータセットを使って事前学習をします。
そして、ELECTRAを40万ステップ学習したものと175万ステップ学習したものを使います。
GLUEデータセットの結果は以下のようになっています。
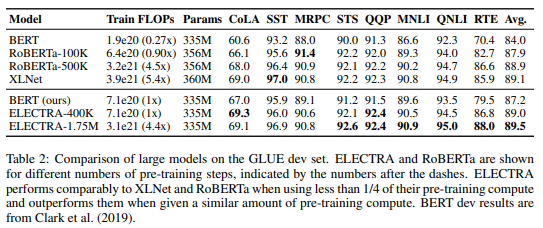
ELECTRA-400kはRoBERTaやXLNetと同等の精度が出ています。ただしELECTRA-400kはRoBERTaやXLNet と比べて1/4以下の計算量になっています。
またRoBERTaやXNLNet と同程度の計算量であるELECTRA-1.75Mを比較するとELECTRA-1.75Mがアウトパフォームしていることがわかります
続いてSQuADデータセットについて見ていきましょう。
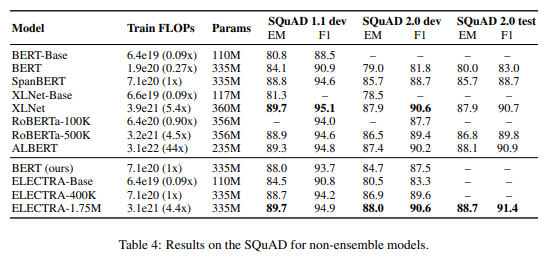
ELECTRA-Base同じサイズでBERT-Baseと比べて精度がかなり改善しています
またELECTRA-400kはRoBERTaやXLNet、ALBERTなどとほぼ同等の精度です
さらに学習ステップを長くした ELECTRA-1.75MについてはXLNet、RoBERTaやALBERTを上回っています。
ELECTRAの学習効率の分析
では最後に、BERTに対するこのELECTRAの精度の改善はどこからきているのか?を検証していますので、それをご紹介します。
ここではELECTRA、BERTと以下の3つの手法を比較します。
この3つはBERTとELECTRAの間にあるような手法になります。
- ELECTRA 15%
BERTは文章中の15%をマスクしそのマスクした単語を予測するので、1つの文章当たり15%の単語のみを学習します。
それに合わせて、ELECTRAについても15%だけを予測するようにします。
具体的には、[MASK]の部分だけについて損失を合計するようにします。 - Replace MLM
BERTの事前学習では、15%を[MASK]に置き換えてその部分を予測しますが、ファインチューニングでは[MASK]という単語は出てこず、これが事前学習とファインチューニングの乖離を生んでいます。
それを対処することでBERTがELECTRAに近くづくかを確認します。
具体的には、[MASK]部分をGeneratorにより別の単語に置き換え、その部分のオリジナルの単語が何かを予測するようにします。
つまり単純に[MASK]という単語をなくすものです。 - All-Tokens MLM
こちらはかなりELECTRAに近いですが、Generatorが[MASK]部分を違う単語に置き換え、そして、Discriminatorが文章中のすべての単語について置き換えられているか?そして、もし置き換えられているなら元の単語は何か?についても学習します。
ELECTRAと違うのは後者の「もし置き換えられているなら元の単語は何か?」を学習する点です。
こちらの方が効率よく学習できそうですが、結果はそうなってはいないようです。
では、結果を見てみましょう。
結果は以下のとおりです。

こちらのことがわかります。
- ELECTRA 15%はBERTとあまり変わらない。
つまり、ELECTRAを使っても文章中の15%しか学習しないと、BERTとほぼ同水準になります。
したがって、文章中のすべての単語を予測することが重要ということがわかります。 - Replace MLMはBERTとあまり変わらない。
[MASK]という単語を使わなくても、それほど改善はしないようです。
これはBERTが既にこの問題に多少対応していることが考えられます(詳細はBERTの記事をご参照ください)。
しかしながら、0.2ポイントは改善しているので、BERTの対応は十分ではないとも考えられます。 - All-Tokens MLMではBERTから大きく改善している。
1つめの結果を裏付けるような結果で、文章中のすべての単語について予測することで精度が大幅に改善しています。
ELECTRAに近い水準になっています。 - All-Tokens MLMよりもELECTRAの方が精度が高い。
All-Tokens MLMでは、その単語が置き換えられているか?を判定し、また置き換えられているなら元の単語が何だったか?も予測します。
実はこれが良くないようで、ELECTRAのように置き換えられているかどうかだけの予測の方がいいようです。
これは、考察で言及されていますが、ELECTRAはBERTのようにすべての単語を見にいかないのでパラメータの効率がいいとのことです。
まとめ
今回はBERTの事前学習方法を改良したELECTRAについて見てきました。
事前学習にGANのような発想を適用することで、BERTと同じモデルでも大幅に精度が改善するという結果になりました。
GPTのように、モデルを大きくしていくことにより大きなメリットがある一方で、モデルを大きくすることには限界があり、同じモデル、モデルサイズでも学習を効率化し、良い精度を出すということも重要な方向だと思います。
これらを組み合わせることで、BERTをさらに大きく上回り、もう一度ブレイクスルーを起こすようなモデルが出てくるのが楽しみです。
では!!