では、今回は畳み込みニューラルネットワーク(Convolutional Neural Network; CNN)を使ってみたいと思います。CNNは、主に画像系のディープラーニングで使われることの多いモデルです。
以下の論文を参考にモデルを構築しています。
https://www.aclweb.org/anthology/C16-1329/
CNNを使う理由
なぜCNNを使うのか?どんなメリットがあるのか?ですが、まずRNNの欠点を説明します。
RNN、特にLSTMやGRUといった種類のRNNは、長期の依存関係、単語の並び順を考慮するモデルという説明を今までしてきました。しかしながら、実は直近の単語は 順番も含めてすごくはっきりと覚えているのですが、初めの方に出てきた単語はあったことは覚えていても、順番はよく覚えていないということです。詳しく知りたい方はこちらの論文をご参照ください。
https://www.aclweb.org/anthology/P18-1027/
センチメント分析では、一番最初の時点0から単語を読み込み、順番に処理をしていって、最後の時点\(T\)でのアウトプットを使ってセンチメントを判定します。 ただ、初めの方の単語は曖昧になっていますので、図で描くとこういう状態です。
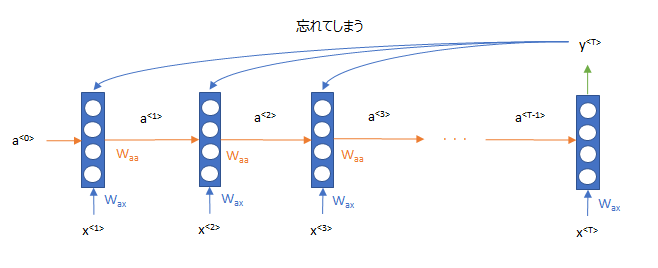
そこで、昔の情報を忘れず、直接使ってしまおう!という発想です。これにより、RNNで処理をした情報を多く使えるというものです。
図を描くと、 以下のとおり、RNNの各時点の出力\(y^{<1>}\)から \(y^{<T>}\)のすべてをインプットとし使い、畳み込みニューラルネットワーク(CNN)で処理をしようということです。
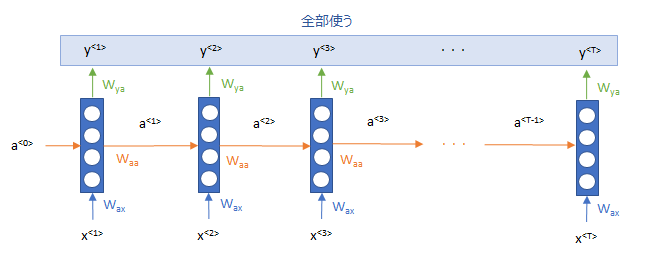
この\(y\)は時間方向にT個のh次元の行列なので、これを画像と見立ててCNNを用いることで、時間方向や隠れ層の次元の方向の特徴を捉えることを可能にします。
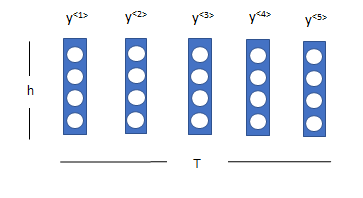
畳み込みニューラルネットワークとは
畳み込みニューラルネットワークとは、次のように、もとの画像を“畳み込み処理(Convolution)”によって、画像の各パーツを認識していくモデルです。
2012年のImageNetというコンテストで、CNNを使ったモデル(通称Alex Net)と大量の画像データを使ったモデルが、大成功を収めて以来、画像認識ではCNNが主流となっています。その後は、ResNetやVGGなどモデルをうまく大きくすることで、どんどん性能が上がり、画像認識などでは既に人間の能力を超えています。
Alex Netの論文はこちらです。
今回はCNNの詳細には触れませんが、こちらをご参照いただくか(『【入門者向け】畳み込み処理と転置畳み込み処理を理解する』)、興味がある方はCouseraの講義がおすすめですので、こちらの記事もご覧ください!
非常によく理解できると思います!

モデル構築
論文にある以下のような構造を使いました。まずは、いつも通り、Embeddingレイヤーで単語を埋め込み表現に変換します。そして、Convolutionalレイヤーでチャネル数を増やし、Max Pooling層で次元を少し落とします。その後、全結合層で最終的な分類を行います。
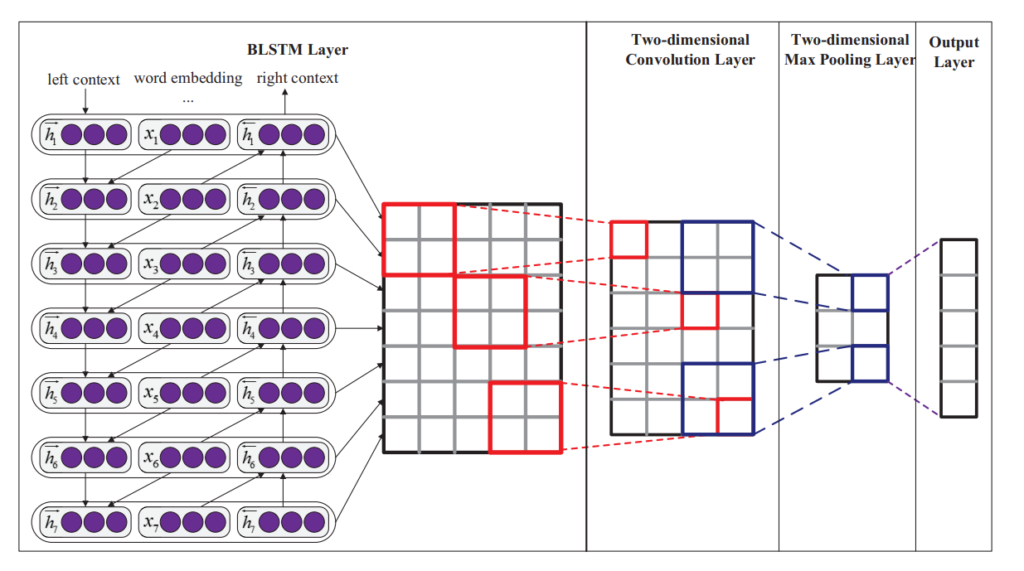
プログラムはこちらです。まだ、KerasのSequentialを使って簡単に作れますね。ドロップアウトの設定や正則化をしていないなど、かなり雑な部分もあるので、きちんとやるのであればもう少し細かく設定した方がよさそうです。
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Conv2D, MaxPooling2D, Dense, Reshape, Dropout, Flatten
def CNN(seq_len, input_dim, emb_dim, lstm_hidden_units, cnn_filters, cnn_kernel_size, pooling_size, dropout=0.0):
model = Sequential()
model.add(Embedding(input_dim=input_dim, output_dim=emb_dim, mask_zero=True)) # Embeddingレイヤー
model.add(Bidirectional(LSTM(lstm_hidden_units, return_sequences=True, dropout=dropout), merge_mode='sum')) # Bidirectional LSTMレイヤー
model.add(Reshape((seq_len, lstm_hidden_units, 1))) # ConvolutionalレイヤーのためにChannelの次元を追加
model.add(Conv2D(filters=cnn_filters, kernel_size=cnn_kernel_size, activation='tanh')) # Convolutionalレイヤー
model.add(Dropout(dropout)) # ドロップアウトレイヤー
model.add(MaxPooling2D(pooling_size)) # Max Poolingレイヤー
model.add(Flatten()) # 全結合レイヤー
model.add(Dropout(dropout)) # ドロップアウトレイヤー
model.add(Dense(1, activation='sigmoid')) # シグモイドレイヤー
return model
ハイパーパラメータはこちらです。
- 単語の埋め込み表現のサイズ:200
- LSTMの隠れ層の数:256
- CNNのフィルター数:30
- CNNのカーネルサイズ:5×5
- max poolingのサイズ:5×5
- ドロップアウト:0.5
- L2正則化の係数:0.01
モデル構築結果
結果は、
- 学習データ:87.3%
- テストデータ:83.9%
と、LSTMの82.5%を1.4%上回りました!!なかなかの結果ですね。やはり、LSTMの弱点をうまく克服できているのかもしれません。
まとめ
今回は、畳み込みニューラルネットワークを使った自然言語処理モデルを構築してみました。こちらも、KerasのSequentialを使って簡単に作れました。
では、次回はWord2Vecを文書に応用したParagraph Vector(Doc2Vec)を使ってみたいと思います!