前回はWord2Vecを使った単語の埋め込み表現を使って遊びました。その前は、Bag-of-Wordsモデル+ロジットモデルを使って、データの分析及びレビュー評価を行いました。
今回は、今までの知識を使いながらも、新たに再帰的ニューラル・ネットワーク(Recurrent Neural Network; RNN)の一つLSTM(Long Short-Term Memory)を使ってモデルを構築したいと思います。
LSTM(Long Short-Term Memory)とは
LSTMとはRecurrent Neural Networkの一つで、それ以前のシンプルなRecurrent Neural Networkでは、勾配消失や勾配爆発といった現象が起こってしまい、長い時系列データの処理ができませんでした。そこで出てきたのが、LSTMです。LSTMは1997年に以下の論文で最初に提案され、その後も、LSTMをもう少しシンプルにしたGRU(Gated Recurrent Unit)などが提案され、それらもよく使われているモデルです。
このモデルのポイントは、長期の時系列のデータをうまく扱えられることにあり、文章を単語の時系列データと見ることにより、うまく翻訳やセンチメント分析に適用することができます。
LSTMについてはこちらをご参照ください。

LSTM自体は1997年に既に提案されていましたが、自然言語処理に適用されたのは2014年とかなり後になります。その論文はこちらです。
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.248.4448&rep=rep1&type=pdf
ちなみに、シンプルなRecurrent Neural Networkを使った自然言語処理は2010年のこちらの論文です。
https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf
構築するモデルについて
今回は以下のようなモデルを構築します。
文章を左から右に読むLSTMではなく、左から右と右から左に読む両方を使ったBidirectional LSTMを使いたいと思います。以下のようなイメージです。
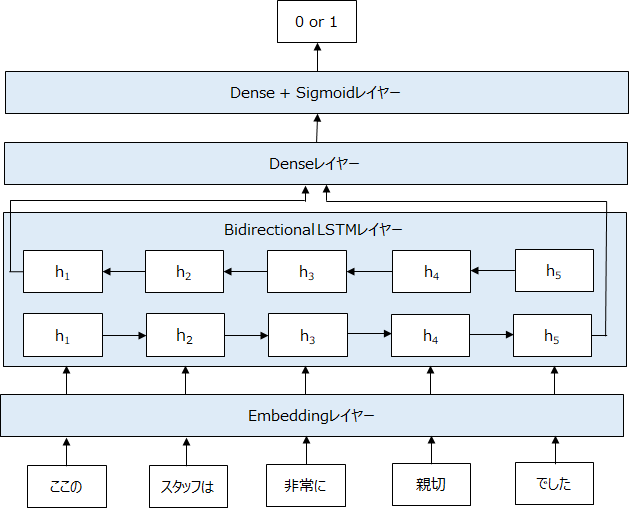
プログラムはTensorflowのKeras APIを使っています。まだまだシンプルにSequentialを使って構築可能です 。 (ドロップアウトの設定などちょっと雑ではありますが…)
from tensorflow.keras.layers import Embedding, LSTM, Bidirectional
def lstm_model(input_dim, embedding_dim=128, hidden_units=32, dropout=0.0, l2_regularizer=0.0):
model = Sequential()
model.add(Embedding(input_dim=input_dim, output_dim=embedding_dim))
model.add(Bidirectional(LSTM(hidden_units, dropout=dropout,
kernel_regularizer=regularizers.l2(l2_regularizer))))
model.add(Dense(1, activation='sigmoid', kernel_regularizer=regularizers.l2(l2_regularizer)))
return model
モデル構築結果
2値分類
ここでは、また、星の数が5個か3個以下かという2値分類を行いたいと思います。
結果は、
- 学習データ:82.2%
- テストデータ:80.5%
と、前回のBag-of-Words + 2項ロジットモデルでは78.7%だったので、約1.8%向上しています。
これは、文章の順番を考慮したことにより、より「何が、どうだったか?」というような情報をうまく捉えられているからだと思います。
如何でしたでしょうか?単純な単語の出現回数だけだったモデルから、単語の順番を考慮することができるようになりました。
まとめ
今回は、単語の順番をきちんと考慮したRecurrent Neural Networkの一つであるLSTMを用いてモデル構築をし、少しですが精度が改善しました。
次回は、Bag-of-Wordsの一種になりますが、埋め込み表現を使った非常にシンプルながら、なかなか精度の良いモデルを試したいと思います!