今回はまたしてもBag-of-Wordsモデルを使っていきたいと思います。ただ、前回のように単語の出現回数をもとにしたTF-IDFのようなやり方ではなく、前回使ったWord2Vecなどの単語の埋め込み表現を利用したモデルを構築したいと思います。
Word2Vecを使った単語の埋め込み表現に関する記事はこちらです。

構築するモデル
- 埋め込み表現の平均を取るだけのシンプルなモデル
- その割に精度が良い!
今回構築するモデルは極めてシンプルですが、その割に精度が良くて驚きます。次回見てみるLSTMより圧倒的にはやいですし、より複雑なモデルを構築するのに、ベンチマークとしていいと思います。
モデルは以下の図のように、インプット→embeddingレイヤー→average poolingレイヤー(単純に平均を取るだけ)→Denseレイヤー with シグモイド関数 or ソフトマックス関数、という形で非常にシンプルです。
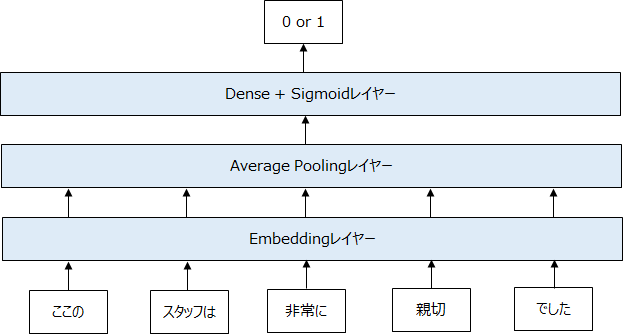
Average Poolingレイヤーは何をやっているかというと、Embeddingレイヤーからの出力は、“文章の長さ”ד単語の埋め込みの次元”ですが、それを文章方向に平均をとることで、単語の埋め込み表現と同じ次元のベクトルにしています。これを“文章の埋め込み表現”とするものです。
プログラムはこんな感じです。こちらも、Sequentialを使って簡単に表現できます。必要に応じてドロップアウトや正則化を入れてもいいです。
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Embedding, GlobalAveragePooling1D, Dense
from tensorflow.keras.optimizers import Adam
embedding_dim = 200
model = Sequential([
Embedding(MAX_WORD+1, embedding_dim),
GlobalAveragePooling1D(),
Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['acc'])
history = model.fit(
x_train, y_train,
epochs=5,
validation_data=(x_test, y_test), validation_steps=20)
またこのモデルも単語の順番を考慮せず、すべての埋め込み表現を各次元ごとに平均しているだけなので、Bag-of-Wordsの一種と言えます。ただ、単語の意味を考慮し、出現する単語のベクトルの平均を取ることで、文章をざっくりと表現しているといれると思います。
構築結果
結果は、
- 学習データ:83.2%
- テストデータ:81.5%
と前回のTF-IDFと2項ロジットモデルの77.7.%を3.8%も上回っています!非常にシンプルですがなかなか精度が良いので、TF-IDFと並んでベンチマークとして良いと思います。前回の結果はこちらです。

一方で、英語のセンチメント分析の論文の結果を見ていると、あまり精度が良くないので、言語的な原因もあるのかもしれません。
まとめ
今回は埋め込み表現を使用した非常にシンプルなモデルを構築し、なかなか良い精度が出ることがわかりました。皆さんもすぐに出来ますので、複雑なモデルを試す前に一度こういったモデルで比較してみてはいかがでしょうか?
では、次回は単語の順番も考慮するLSTMを使ってみたいと思います!!