今回はBag-of-Wordsという手法を使って口コミの分析、評価をしたいと思います。
Bag-of-Wordsについてピンとこないという方は、以下の投稿でイメージを掴めるようにしておりますのでご参照ください!
https://data-analytics.fun/2020/03/06/bag-of-words/
目次
データについて
データについては前回と同様、キャンプ場の口コミを利用させていただきます。
各レビューには 1から5の星マークがついています。
単語の出現回数
Bag-of-Wordsとは簡単に言うと、単語の順番を考えずに、単語の出現回数のみを使うモデルです。
ということで、まず文章を単語に分割します。
例えばある項目に関して、全体で出現回数が多い名詞は以下のようになっています。
| 単語 | 出現回数 |
|---|---|
| 受付 | 2737 |
| スタッフ | 2584 |
| 方 | 2564 |
| 説明 | 2448 |
| 対応 | 2360 |
| 時 | 2311 |
| 丁寧 | 2131 |
| ゴミ | 1972 |
| こと | 1544 |
| 親切 | 1508 |
やはり「受付」の「スタッフ」に関することが多いようです。
確かに、最初や何かを聞きにいったときの「受付」の「スタッフ」の「方」の「説明」が「丁寧」だったり「親切」にしてもらえると嬉しいですよね。
あと、他の項目ではこんな感じです。
| 単語 | 出現回数 |
|---|---|
| トイレ | 5879 |
| 場 | 4951 |
| 炊事 | 3468 |
| シャワー | 3180 |
| 風呂 | 2202 |
| お湯 | 2087 |
| サイト | 1798 |
| 綺麗 | 1720 |
| 利用 | 1674 |
| こと | 1296 |
「トイレ」、「炊事・場」「シャワー」、「お風呂」に関することが多いようです。
ファミリーや最近は女子キャンプも多いので「トイレ」や「お風呂」が「綺麗」な方がいいですね。
また、「炊事・場」は「お湯」が出ると手が凍りそうにならなくて助かりますよね。
他の項目は特に掲載しませんが、周辺環境であれば「温泉」、「スーパー」、「コンビニ」などが上位に入っています。
といった具合で、単語の回数を調べるだけで、こんなに楽しくなってきます(笑)。
口コミから評価を予測する
では、次に口コミから評価、つまり星の数1~5個を予測するモデルを作ってみたいと思います。
モデルは単語の出現回数を説明変数としたシンプルなロジットモデル(ロジスティック回帰モデルを分類問題に適用)を使いたいと思います。
ただし、Bag-of-Wordsの解説記事にも記載しましたが、そのまま単語の回数を説明変数として使ってしまうと、どの文章にも出てくるような単語の重みが高くなってしまう場合がありますので、説明変数をTF-IDF(Term Frequency - Inverse Document Frequency)に変換したいと思います。
TF-IDFへの変換やモデル構築は、TensorflowのKeras APIを使いました。Scikit-Learnを使ってもよかったのですが、普段業務ではTensorflowの方がよく使うので、使い慣れているTensorflow Keras APIを使いたいと思います。
評価の分布
まず、全体の星の分布を見てみましょう。星5個と4個が圧倒的に多いですね。星1個とか星2個とかはあまりありません。
皆さん楽しむことができているということでしょうか。
いいですね、皆さん満足して帰ることが多いようです。
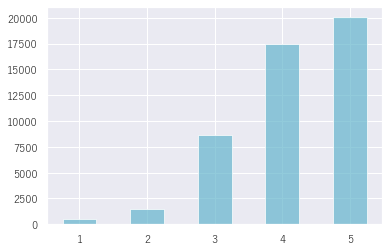
(横軸: 星の数, 縦軸: 件数)
ただし、モデルで予測するとなるとこれは多少問題があります。
この問題については、今は触れずに最後に簡単に触れたいと思います。
興味がある方は読んでいただければと思います。
モデル構築の設定
まず、全データを学習データ60%、テストデータ40%として以下の設定で学習しました。
- 使った単語の数は出現回数の多い5000単語
- バッチサイズ64
- エポック数100
- L2正則化係数0.1
L2正則化係数といったハイパーパラメータはvalidation setを作成して、最適な設定に合わた結果です。
モデル構築結果
では、モデルの構築結果です。
学習データの正解率は約62%、テストデータの正解率は56%となっています。
多少オーバーフィッティングが見られますが、自然言語処理ではテストデータに学習データにない単語や表現が出てくることが多いので、どうしてもある程度オーバーフィッティングしてしまいます。
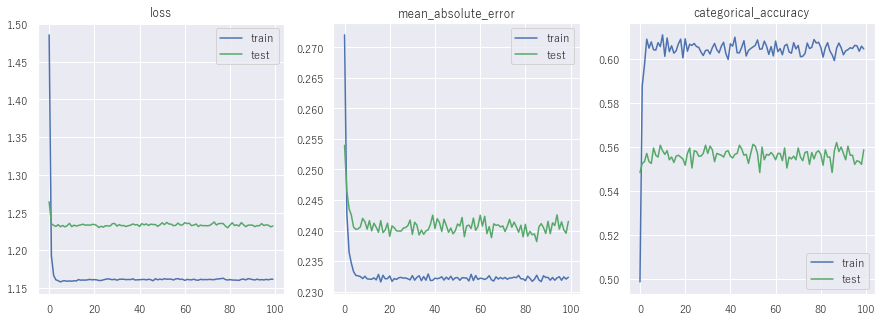
星の数に影響する単語を分析
では、どんな単語が星の数に影響しているかを見てみましょう。
ロジットモデルの係数を大きい順に並べていきましょう。
TF-IDFを正規化して平均0、分散1にしているため係数の大きさが単語の効きと考えます(正規化していない場合、単に係数を比較すると説明変数の大きさに影響を受けてしまうので、係数に説明変数の標準偏差をかけるなどする必要があります)。
サービスについて見てみましょう。
以下は星5個に分類する係数です。
やはり、星5個をもらうためには、「スタッフ」が「丁寧」だったり「親切」だったりする必要がありますね。
「普通」だったり「残念」に感じさせるようではダメということですね。当然の結果ということでしょうか。
| 良い単語 | 係数 | 悪い単語 | 係数 |
|---|---|---|---|
| 丁寧 | 0.088 | 普通 | -0.097 |
| 親切 | 0.082 | ない | -0.077 |
| 素晴らしい | 0.058 | 残念 | -0.070 |
| さん | 0.057 | 可 | -0.067 |
| いただく | 0.056 | 不可 | -0.065 |
| スタッフ | 0.054 | 悪い | -0.065 |
載せているのはこれだけですが、他にも悪い単語として、「音楽」や「チェックイン」、「混む」なども上位にありましたので、夜中音楽がかかっているのを注意しなかったり、チェックインの受付が混んでいて時間がかかっていると評価が悪くなるということですね。
シンプルなロジットモデルを使ういいところは、なぜそういう評価になったかがわかりやすいところですね。
ディープラーニングを使うとなかなかそこが難しいです。
今回は単純なBag-of-Words、TF-IDFを使ってロジットモデルを構築し、予測しましたが、次回以降では少しずつ複雑なモデルにしたり工夫を加えていきたいと思います。
2値問題
では、次は星の数そのものを当てるのではなく、星5個か星3個以下という2値問題を予測してみましょう。こちらであれば若干問題設定が簡単になります。
星3個以下にしたのは、星1個、星2個がほとんどないからです。
データについて
全体の90%を学習データに、残りの10%をテストデータにしています。
- 学習データ数:27,654
- テストデータ数:3,073
- 学習データ正例数:18,030
- テストデータ正例数:2,024
モデル構築結果
結果は、こちらです。これについても改善できるよう色々試したいと思います。
- 学習データ:81.9%
- テストデータ:77.7%
星の数に影響を与える単語
では、先ほどと同じように評価がよくなる単語と悪くなる単語を見てみましょう。
下の表はそれぞれ1位から10位まで表示しています(係数は省略しています)。
一つ一つは触れませんが、全体として納得の結果かなと思います。こういったモデルはわかりやすくていいですね。
| よい単語 | 悪い単語 |
|---|---|
| 綺麗 | 残念 |
| 親切 | 普通 |
| 清潔 | だらけ |
| 最高 | 改善 |
| 感謝 | 都 |
| 丁寧 | 仮設 |
| オーナー | 微妙 |
| 快適 | 不十分 |
| 満足 | 簡易 |
データの偏りについて
上で星4個や星5個が非常に多くて、星1個、星2個というサンプルが少ないというのは、予測上は問題が出てくると言いました。
これは、星の数が1個、2個を分類するのが非常に難しいということです。
イメージとしては、ほとんどのレビューが星4個とか星5個なので、基本的には星4個、5個と予測するほど精度が上がるということです。
少々悪そうなレビューがあって、それを星1個と予測すると、大外れしてしまう可能性がありますので、なかなか星1個!と予測するインセンティブが非常に少なくなってしまいます。
こういったラベルの偏りは非常に難しい問題です。
一般的には、Data augmentationといったデータを増やしたりすることが多いです。
例えば、数値の場合ですとSMOTE(Synthetic Minority Over-sampling Technique)など少数のサンプルを増やすやり方があり、かなり有効です。
画像でも左右を逆にしたりノイズを載せたりと色々な方法があるのですが、自然言語処理の場合はそういった手法が使えません。
ラベルの偏りの問題については、いつかまとめて投稿したいと思います。
まとめ
今回はBag-of-Words、TF-IDFという手法を用いて、ロジットモデルで星の数の予測モデルを構築しました。
このモデルは、どういった単語が影響しているかがわかって楽しいですね。
ただ、今回はロジットモデルについての説明はしていませんし、エポック数、バッチサイズなどの説明もしていません。
もしそういったところから知りたいという方は以下の書籍などを読めばよくわかると思います。
次はWord2Vecを使って遊んでみたいと思います!