今回はTransformerで口コミの評価をしたいと思います。
Transformerは、RNNやCNNを使わないことから、高速に計算できるモデルとして、BERTやXLNetなどでも使われている重要な仕組みです。
理論的な解説は以下の投稿でしていますので、基本的にはこの通りに実装したいと思います。

参考書籍
PyTorchを使った実装であれば、以下の書籍がオススメです。
PyTorchを使ってTransformerとBERTのモデル部分を実装しています。
真似をしながら自分の手で実装することで、TransformerとBERTをしっかりと理解することができると思います。
自然言語処理については最後の方の一部だけですが、逆に言うと画像認識などの勉強もできて非常に参考になります。
目次
Transformerを使ったセンチメント分析
なぜTransformer?
Transformerと言えば、Attentionメカニズムを使ったモデルです。Attentionと言えば、下記の投稿で説明しているRNN + Attentionメカニズムを使ったモデルです。

なぜ、このRNN + Attentionメカニズムのモデルではダメなのか?それは、RNNは前の時点における処理が終わるまで次の時点の処理に進めないことに起因する、計算処理の遅さにあります。
Transformerでは、この欠点を克服しようと、RNNを使わずにPositional Encodingという手法とSelf-Attentionという仕組みを使って、時系列のデータを扱うことを可能にしました。
Transformerの仕組み
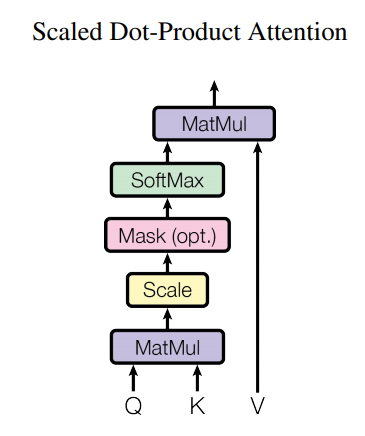
Transformerの仕組みは、以下の全体図とScaled Dot-Product Attentionがわかりやすいです。ただし、センチメント分析では、下図の左側部分(エンコーダー部分)のみを使用し、そのアウトプットを分類のためのレイヤーに通して分類します。
実装
では、今回もTensorflowを用いた実装をしたいと思います。今回もTensorflowの以下のチュートリアルと、こちらの本を参考にしています。
https://www.tensorflow.org/tutorials/text/transformer
Positional Encoding
では、まず、以下のPositional Encodingレイヤーを作成したいと思います。
以下の式の通りにfor文でぐるぐる回せば実装できますが、チュートリアルの方法がすごくシンプルなので、それをそのまま使います。get_anglesメソッドではPythonのブロードキャストを使ってうまく計算しています。
$$\begin{align}
PE_{pos, 2i} &= \sin\left(pos/100000^{2i/d_{model}} \right) \\
PE_{pos, 2i+1} &= \sin\left(pos/100000^{2i/d_{model}} \right)
\end{align}$$
class PositionalEmbedding(tf.keras.layers.Layer):
def __init__(self, vocab_size, emb_dim, max_seq_len):
super(PositionalEmbedding, self).__init__()
self.embedding_layer = Embedding(input_dim=vocab_size,
output_dim=emb_dim,
mask_zero=True)
self.pe_size = max_seq_len
self.emb_dim = emb_dim
def call(self, x):
embeddings = self.embedding_layer(x)
pos_encoding = self.positional_encoding(self.pe_size,
self.emb_dim)
pos_embeddings = embeddings * tf.math.sqrt(
tf.cast(self.emb_dim, tf.float32))
+ pos_encoding
return pos_embeddings, pos_encoding
def positional_encoding(self, position, d_model):
'''
Positional Encoding
'''
angle_rads = self.get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])# 偶数番目
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])# 奇数番目
pos_encoding = angle_rads[np.newaxis, ...] # バッチの次元を足す
return tf.cast(pos_encoding, dtype=tf.float32)
def get_angles(self, pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i // 2))
/ np.float32(d_model))
return pos * angle_rates
そして、positional encodingと単語の埋め込み表現に\(\sqrt{d_{\text{model}}}\)を取って足したものが、位置情報を考慮した単語の埋め込み表現になります。
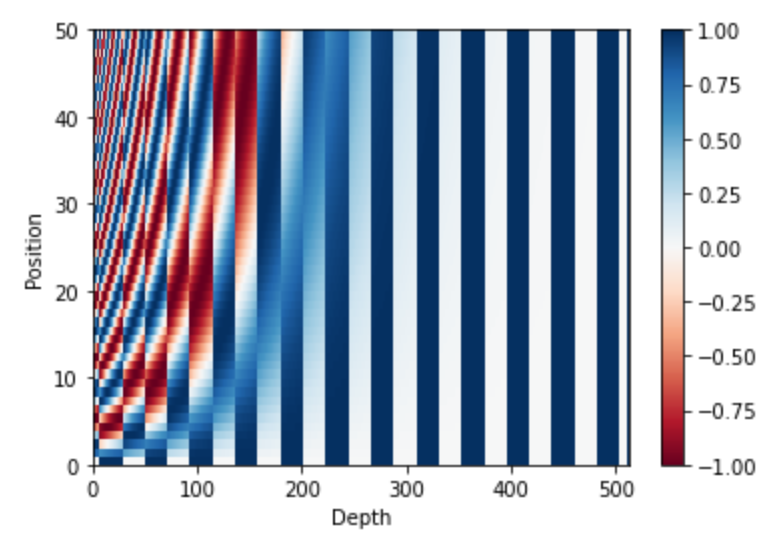
一応、これを図示するとこのようになります。こういった位置情報を単語の埋め込み表現に足しこみます。
pe = PositionalEmbedding(vocab_size=10, emb_dim=512, max_seq_len=50)
# batch_size: 10, seq_length: 500
pos_embeddings, pos_encoding = pe(np.zeros((10, 50)))
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel('Depth')
plt.xlim((0, 512))
plt.ylabel('Position')
plt.colorbar()
plt.show()
Multi-Head Attention
では、次にエンコーダー部分(以下、Transformer Blockと呼びます)を作っていきます。
まずその中にある、Multi-Head Attentionを実装していきたいと思います。Multi-Head Attentionとは、複数のScaled Dot-Product Attentionの集まりです。
Scaled Dot-Product Attention
ではまず、上の図のScaled Dot-Product Attentionモジュールを作成します。
qがquery、kがkey、vがvalueです。以下の式でcontext vectorを計算します。
$$Attention=\text{softmax}\left(\frac{QK^T}{\sqrt{d_{\text{model}}}}\right)V$$
class ScaledDotProductAttention(tf.keras.layers.Layer):
def __init__(self, d_model):
super(ScaledDotProductAttention, self).__init__()
self.q_dense = Dense(d_model)
self.k_dense = Dense(d_model)
self.v_dense = Dense(d_model)
def call(self, q, k, v, mask):
"""
q, k, v: (batch_size, num_heads, seq_len, d_model)
"""
# qk: (batch_size, num_heads, seq_len, seq_len)
qk = tf.matmul(q, k, transpose_b=True)
d_k = tf.cast(tf.shape(k)[-1], tf.float32)
# attention_logits: (batch_size, num_heads, seq_len, seq_len)
attention_logits = qk / tf.math.sqrt(d_k)
# 不要な部分にマスク
# mask: マスクする箇所が1、それ以外は0
if mask is not None:
attention_logits+= (mask * -1e9)
# attention_weights: (batch_size, num_heads, seq_len, seq_len)
attention_weights = tf.nn.softmax(attention_logits, axis=-1)
# output: (batch_size, num_heads, seq_len, d_mdel)
output = tf.matmul(attention_weights, v)
return output, attention_weights
ゼロ・パディングした部分のattentionウェイトがゼロになるように、attention logitsに(mask * -1e9)を足しています。マスクを作成する関数も作成しておきます。
def create_mask(x):
mask = tf.cast(tf.math.equal(x, 0), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :]
あとは、次元に注意しながら、式に従って計算を行います。
Multi-Head Attention
続いて、Multi-Head Attentionレイヤーを作成します。Multi-Head Attentionはquery, key, valueを複数のheadに分け、その各headに対してScaled Dot-Product Attentionを適用します。
仕組みはシンプルで、 queryを\(QW_i^Q \)で線形変換してheadに分け、それを上述のattentionの関数によりcontext vectorを計算します。そして、最後にそれを連結して、線形変換するというだけです。
$$\begin{align}
\text{MultiHead}(Q, K, V) &= \text{Concat}\left(\text{head}_1, \cdots, \text{head}_h\right) W^O\\
\text{where } \text{head} _i &= \text{Attention}\left(QW_i^Q, KW_i^K, VW_i^V\right)
\end{align}$$
下記の実装では、処理の次元の操作に注意して、headをまとめて計算しています。
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.depth = d_model // self.num_heads
self.wq = Dense(d_model)
self.wk = Dense(d_model)
self.wv = Dense(d_model)
self.attn_layer = ScaledDotProductAttention(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
# もともと(batch_size, seq_length, d_model)
# 最後の次元d_modelをnum_headsとdepthに分ける
# ⇒ (batch_size, seq_length, num_heads, depth)
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
# 処理の都合上 (batch_size, num_heads, seq_length, depth)に次元を入れ替える
x = tf.transpose(x, perm=[0, 2, 1, 3])
return x
def call(self, v, k, q, mask):
# v, k, q: (batch_size, seq_len, d_model)
batch_size = tf.shape(q)[0]
# multi-head用
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k)
v = self.wv(v)
# headに分ける
# (batch_size, num_heads, seq_len, depth)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
# attention_output: (batch_size, num_heads, seq_length, d_model)
attention_output, attention_weights = self.attn_layer(q, k, v, mask)
# attention_output ⇒ (batch_size, seq_length, num_heads, d_model)
attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3])
# headに分けた結果を連結する
# concat_attention_output ⇒ (batch_size, seq_length, d_model)
concat_attention_output = tf.reshape(attention_output,
(batch_size, -1, self.d_model))
output = self.dense(concat_attention_output)
return output, attention_weights
Feed Forwardレイヤー
さて、ここまでで重要な部分“Positional Encoding”と“Multi-Head Attention”ができたので、あとはそれほど目新しい部分はありません。
では、下図のTransformer BlockのうちのFeed Forwardレイヤーを実装します。
Feed Forwardレイヤーは、以下の式の通り2層の全結合層で表されます。活性化関数はReLUが使われています。間にはドロップアウトを入れます。(ドロップアウトについてはこちら)
$$\text{FFN}(x)=\max\left(0, xW_1+b_1\right)W_2 + b_2$$
class FeedForward(tf.keras.layers.Layer):
def __init__(self, d_model, dff, dropout_rate=0.0):
super(FeedForward, self).__init__()
self.dense_1 = Dense(dff, activation='relu')
self.dropout = Dropout(dropout_rate)
self.dense_2 = Dense(d_model)
def call(self, x):
x = self.dense_1(x)
x = self.dropout(x)
output = self.dense_2(x)
return output
Transformer Block
では、今まで作ったパーツを使って一つのTransformer Blockにしたいと思います。何度も出しますが、Transformer Blockはこちらの図です。
レイヤー正規化層を入れ残差結合を使っています。
class TransformerBlock(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff_dim, dropout_rate=0.0):
super(TransformerBlock, self).__init__()
self.layer_norm_1 = LayerNormalization()
self.multi_head_attn = MultiHeadAttention(d_model, num_heads)
self.layer_norm_2 = LayerNormalization()
self.feed_forward = FeedForward(d_model, dff=dff_dim,
dropout_rate=dropout_rate)
self.dropout_1 = Dropout(dropout_rate)
self.dropout_2 = Dropout(dropout_rate)
def call(self, x, mask, training):
# 残差結合、正規化、アテンション
x_normed = self.layer_norm_1(x)
# Self-attentionなのでq, k, vはすべて同じ
attention_output, attention_weights = self.multi_head_attn(x_normed,
x_normed, x_normed, mask)
x2 = x + self.dropout_1(attention_output, training=training)
# 残差結合、正規化、Feed forward
x_normed = self.layer_norm_2(x2)
feed_forward_output = self.feed_forward(x_normed)
output = x_normed + self.dropout_2(feed_forward_output,
training=training)
return output, attention_weights
Classificationレイヤー
最後のレイヤーは、Transformer Blockから得られた文書の埋め込み表現に対して、分類するためのレイヤーです。
このレイヤーでは、1番目の時点の隠れ層の値のみを使用して分類します。ですので、ここに分類に必要な情報が集約されるようにモデルが構築されていきます。BERTの文書分類問題においてもこの方法が使われています。そのため、文章の先頭には[cls]を入れるという処理をしており、「ここの キャンプ場は …」という文章であれば「[cls] ここの キャンプ場は …」となるようにしています。
class ClassificationHead(tf.keras.layers.Layer):
def __init__(self, output_dim):
super(ClassificationHead, self).__init__()
self.dense = Dense(output_dim)
def call(self, x):
x_0 = x[:, 0, :] # 文章の先頭の次元だけを分類に使用する
output = self.dense(x_0)
return output
Training Schedule
オプティマイザーはAdamを使いますが、論文では学習率を以下のように設定しています。
$$lrate=d^{-0.5}_{\text{model}}\cdot\min\left(step\_num^{-0.5}, step\_num\cdot warmup\_steps^{-1.5}\right)$$
warmup_stepsは4000を設定しています。今回のモデル構築では、一定の場合と差は出ませんでした。そのまま使うのではなく、もう少し注意深くチューニングした方がよいのかもしれません。
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps ** -1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model)
optimizer = tf.keras.optimizers.Adam(learning_rate,
beta_1=0.9, beta_2=0.98, epsilon=1e-9)
その他の機能
あとは細々した機能で、Attentionメカニズムのときとほぼ同じです。
損失関数は、binary_cross_entropyを使います。
def loss_function(label, predict):
loss_ = tf.keras.losses.binary_crossentropy(label, predict,
from_logits=True)
return tf.reduce_mean(loss_)
学習用の関数です。
@tf.function
def train_step(x, y_label):
loss = 0
with tf.GradientTape() as tape:
mask = create_mask(x)
output, attention_weights = model(x, mask, training=True)
loss += loss_function(y_label, output)
batch_loss = (loss / len(y_label))
variables = model.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
# accuracyの計算用
predict_label = tf.math.greater(output, 0.0)
correct = tf.equal(y_label, tf.cast(predict_label, y_label.dtype))
correct = tf.reduce_sum(tf.cast(correct, 'int32'))
return batch_loss, correct, len(y_label)
精度計算用の関数です。
def calc_accuracy(dataset, model, steps_per_epoch):
correct_num = 0
total_num = 0
for x_input, y_label in dataset.take(steps_per_epoch):
mask = create_mask(x_input) # マスク
predict, _ = model(x_input, mask, training=False) # 予測
# 0以上なら1, 0以下なら0
predict_label = tf.math.greater(predict, 0.0)
# 正解かどうかを判定
correct = tf.equal(y_label, tf.cast(predict_label, y_label.dtype))
# 正解数を集計
correct_num += tf.reduce_sum(tf.cast(correct, 'int32'))
total_num += len(y_label) # 全データ件数
print(total_num)
return correct_num / total_num
最後に学習部分です。
EPOCHS = 10
import time
model = TransformerClassification(d_model, num_heads, dff_dim, vocab_size,
max_seq_len=max_seq_len, dropout_rate=dropout_rate)
for epoch in range(EPOCHS):
start = time.time()
total_loss = 0; correct_num = 0; total_num = 0;
test_correct_num = 0; total_num_test = 0
for (batch, (x_input, y_label)) in enumerate(train_dataset.take(
steps_per_epoch)):
batch_loss, correct, total = train_step(x_input, y_label)
correct_num += correct
total_num += total
total_loss += batch_loss
if batch % 100 == 0:
print('Epoch {} Batch {} Loss {:.4f} Acc \
{:.1f}%'.format(epoch + 1,
batch,
batch_loss.numpy(),
correct_num / total_num * 100))
# テストセットの計算
test_acc = calc_accuracy(test_dataset, model, steps_per_epoch)
print('Epoch {:02} Train Loss {:.4f} Train Acc {:.1f}%'.format(epoch,
total_loss / steps_per_epoch,
correct_num / total_num * 100))
print(' Test Acc {:.1f}%'.format(test_acc * 100))
print('Time taken for 1 epoch {} sec\n'.format(time.time() - start))
これで、すべて完成しました。あとはdatasetを作成して計算を流すだけです。ハイパーパラメータが多く調整が難しいですね。
モデル構築結果
ハイパーパラメータは色々試しましたが、最終的には以下の設定としました。論文のように大きなモデルにしなくても全然大丈夫でした。
num_layers = 4 d_model = 128 dff_dim = 128 num_heads = 4 max_seq_len = 200 vocab_size = len(tokenizer.index_word) + 1 dropout_rate = 0.3
そして、何とか完成させたモデルを回した結果です。
- 学習用データ: 83.7%
- テスト用データ: 83.2%
残念ながら精度改善とまではいかず、LSTM+Attentionの精度とまったく同じでした。また、LSTM+CNNの83.9%は上回れませんでした。
ただ、計算してみればわかりますが、計算時間が格段に速くなっています!これは、RNNを使わないことによる高速化の恩恵で、まさしくTransformerが狙っていたものです。ですので、モデルを大きくすることが可能で、データ量が多くなったときに更なる飛躍が狙えるはずです!!
Attentionの可視化
では、またAttentionメカニズムのときと同様に、attentionの可視化をしてみましょう。
コードはこちらです。
from IPython.display import HTML
def highlight(word, attn):
"Attentionの値が大きいと文字の背景が濃い赤になるhtmlを出力させる関数"
html_color = '#%02X%02X%02X' % (
255, int(255*(1 - attn)), int(255*(1 - attn)))
return '<span style="background-color: {}"> {}</span>'.format(html_color, word)
def sigmoid(x):
return 1 / ( 1 + np.exp(-x))
def mk_html(tokenizer, sentence, preds, attention_weights, sample_idx, layer, head):
"HTMLデータを作成する"
# ラベルと予測結果を文字に置き換え
if preds < 0.0:
pred_str = "星3個以下"
pred_prob = 1 - sigmoid(preds)
else:
pred_str = "星5個"
pred_prob = sigmoid(preds)
# 表示用のHTMLを作成する
html = '<br>確率{:0.0f}%で"{}"です。<br><br>'.format(pred_prob * 100, pred_str)
for l in range(layer + 1):
# indexのAttentionを抽出と規格化
layer_attention_weights = attention_weights[l]
layer_attention_weights = layer_attention_weights[sample_idx, head, 0]
layer_attention_weights = (layer_attention_weights - \
min(layer_attention_weights)) / (max(layer_attention_weights) \
- min(layer_attention_weights))
html += f'[{l+1}段目のattention]<br>'
for index, attn in zip(sentence, layer_attention_weights):
if index==0:
break
html += highlight(tokenizer.index_word[index], attn)
html += "<br><br>"
return html
レイヤー数とhead数分のattentionが出てきますが、わかりやすくするために、レイヤー数を2、head数を1としたモデルで見てみたいと思います。テストデータの精度は82.6%なのでそれほど変わりません。興味がある方は、レイヤー数やhead数を増やして、レイヤーごとにどのようなattentionになっているかを見てもよいと思います。
では、まずこちらの文章です。
何度もリピートして利用させて頂いています。何と言っても、 管理人さんの人柄が 大好きです。貸してくださるキャンプ道具も全て 手作りで、設営も手伝ってくれたり、 一緒に子供たちとアケビを 取りに行ってくれたり、管理人さんと話がしたいためにここを選ぶ感じです。 夜は星空がキレイで、フクロウの鳴き声がまた幻想的です。本当にオススメで大好きな キャンプ場です!
星5個の確率100%ということで、きちんと評価されています。1段目と2段目のattentionがあることで若干わかりにくくなっていますが、“大好き”などの単語はきちんと評価されていそうです。
では、次は悪いレビューです。
駐車料金高すぎ。下の方の駐車場に車を駐車した人は行きも帰りも地獄。 あれで1000円はありえない。入場料についても高すぎる。 三連休のど真ん中なので仕方ないにしろ、待ち時間長すぎる。アスレチック90分、幼 児用室内カート40ー50分。その他長すぎるために乗っていない。
こちらも星3個以下と正しく評価されていますね。
そして微妙なやつです。
スタッフの方はすごく親切で説明も丁寧でした。ただ、トイレが汚いのは嫌でした。 二度と行きたくなくなりました。
まぁ、文章が文章なのでなんとも言えませんが、星3個以下と正しく評価されています。確率は61%とやはりクリアではないので、まあ良いのではないでしょうか。
まとめ
如何でしたでしょうか?今回はTransformerを実装して、評価をしてみました。
Transformerは非常に軽量なので使いやすいですね。ただし、文章が長くなると、文章の2乗のオーダーで負荷が高くなってしまうという問題もあります。それを改善したTransformer XLやReformerなどといったモデルも考えられているので、いつか実装してみたいと思います。
では、また次回に会いましょう!!