今回はBERTの埋め込み表現の質を改善する“Sentence-BERT”について解説したいと思います。
https://arxiv.org/abs/1908.10084
まず、ラベル付きデータを用いたセンチメント分析や、2つの文章をインプットとした類似度の予測等であればBERTの日本語モデルをそのまま使うことで、それまでのモデルと比べて非常に良い精度が達成されると思います。
しかしながら、例えば複数の文書をインプットとするような場合、具体的には複数文書のクラスタリングや複数の文書を時系列データとしてインプットとする場合においては、BERTでは簡単にいきません。
そのような場合は、おそらく初めにBERTで全ての文書を埋め込み、そのベクトルをもとにクラスタリングする方が効率が良いと考えられます。
毎回2つの文書をインプットとし、その類似度をBERTで計算しながらクラスタリングするというのは現実的ではありません。
そこで、BERTを使ってあらかじめ埋め込み表現を計算することを考えます。
一般的にはBERTの埋め込みというと、最終層かその前の層の[CLS]トークン部分の隠れ層のベクトル、もしくは各単語に対する隠れ層のベクトルの平均値を使うことが多いです。
しかしながら、論文によると、 タスクによってはそれらのBERTによる埋め込みは、GloVeで単語の埋め込みをし、その平均を取ったものよりも精度が良くないことが示唆されています。
つまり、クラスタリングをしたり、他のモデルのインプットとするには、それほど質が良くないと考えられます。
そのため、BERTベースでクラスタリングや他のモデルのインプットとできる埋め込み表現を求めるためのSentence-BERTが考えられました。
つまり、より質の良い埋め込み表現を得られるようなモデルと考えられます。
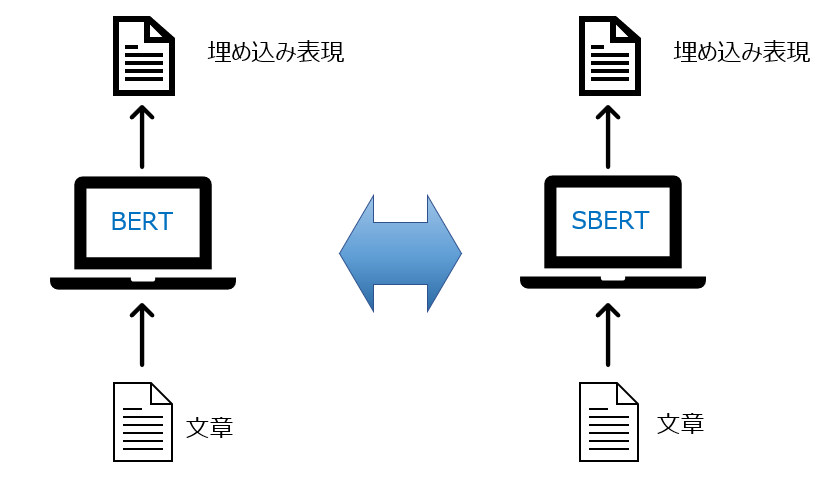
ということで、今回はクラスタリングや文書の類似度の計算で使うことができるSentence-BERTという手法を解説したいと思います。
BERTがいまいちわからないという方は、まずこちらの記事を見ていただければと思います。

Sentence-BERTの仕組み
Sentence-BERTのモデル構造はBERTと同じです。
何が違うかというと、Sentence-BERTは文書のクラスタリングなどを目的としているので、うまくクラスタリングができるようにファインチューニングします。
具体的には、“Siamese Network”というものを使って、ファインチューニングします。
Siamese Networkは簡単に言うと、2つのニューラル・ネットワークを使って、それぞれ埋め込み表現を計算し、その2つの埋め込み表現について比較する手法です。
その際に、ここでは、タスクに合わせて以下の3つの目的関数を使ってファインチューニングします。
Classification Objective Function
こちらは、文章が似ている、もしくは似ていない、というラベルが付けられているデータに対して計算する目的関数です。
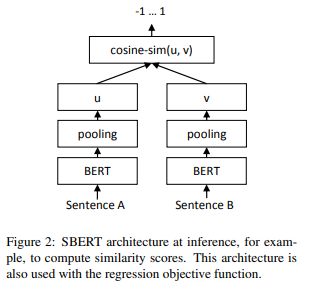
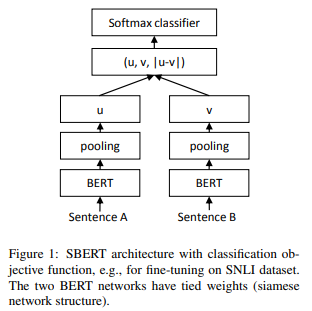
以下の図のように計算します。
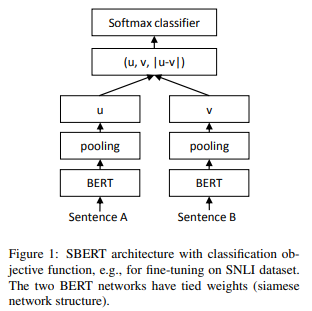
まず、BERTで埋め込み表現を計算し、それをpooling(平均や最大値を取る)して\(u\)、\(v\)を求めます。
このpoolingレイヤーは、BERTのアウトプットを時系列方向にpoolingしています。
あとで検証されていますが、平均を取った場合が精度が一番良くなります。
そして、以下の通り、Softmax関数を使って、分類します。
$$o=\text{softmax}\left(W_t\left(u, v, |u-v|\right)\right)$$
\(W_t\in\mathbb{R}^{3n\times k}\)で、\(n\)は埋め込み表現の次元、\(k\)はラベルの数を表します。
また、\((\cdot, \cdot,\cdot)\)はベクトルの連結を表します。
Regressioon Objective Function
これは、コサイン類似度がラベルとして与えられている場合です。
Classification Objective Functionとほぼ同様で、最後に2つの埋め込み表現のコサイン類似度を計算します。
これにより、似たような文章については、cosine similarityが大きくなるようにBERTの埋め込み表現をファインチューニングしています。
Triplet Objective Function
これは、画像認識の分野において、例えば人物が同じかどうかを判定する人物認証などに利用されている手法です。
まず、anchor sentenceと呼ばれる基準となる文章\(a\)を1つ指定します。
そして、それに対して、似ている(positive)文章\(p\)と似ていない(negative)文章\(n\)をそれぞれ持ってきます。
そして、“triplet loss”と呼ばれる
$$\max\left(||s_a-s_p||-||s_a-s_n||+\epsilon, 0\right)$$
という損失関数を最小化します。
\(s_a\)、\(s_p\)、\(s_n\)はそれぞれ \(a\)、\(p\)、\(n\)の埋め込み表現を表します。また、\(||\cdot||\)はユークリッド距離を使います。
何をしているかというと、このlossが小さくなればよいので、1項目の\(||s_a-s_p||\)を小さくすることで\(a\)と\(p\)は似たようなベクトルに、2項目の\(s_a-s_n\)を大きくすることで\(a\)と\(n\)は違うベクトルにします。
\(\epsilon\)はマージンと呼ばれていて、1項目と2項目の差が\(\epsilon\)以上となるようにする効果があります。
つまり、似たような文章のベクトルと似ていない文章のベクトルの差を大きく仕向けるものです。
論文では\(\epsilon=1\)としています。
実験
Semantic Textual Similarity
教師なしSTS
上記のファインチューニングをSNLIデータセットとMulti-Genre NLIデータセットを使って行います。
これらのデータセットは、各文章に対して“contradiction(矛盾)”、“entailment(正しい)” 、 “neutral(どちらとも言えない)”という3つのラベルが設定されているデータセットです。
このデータセットを使って、上記のClassification Objective Functionによりファインチューニングします。
そして、Semantic Textual Similarity(STS)タスクで精度を確認します(教師あり学習は行いません)。
タスクは、2つの文章のペアに対して、類似度が0から5で振られています。
そして、この実験では、Sentence-BERTを使って埋め込み、そのコサイン類似度を求め、0から5のラベルとの順位相関を計算します。
結果は、以下の通りです。
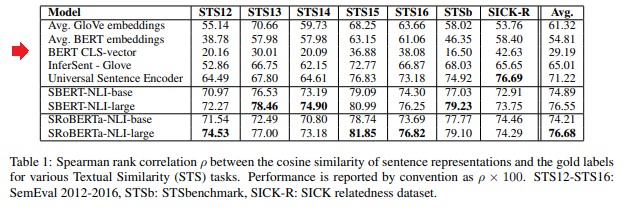
まず、BERTの[CLS]トークンに対応する部分を埋め込み表現とした場合(BERT CLS-vector)ですが、なんとGloVeで単語の埋め込み表現を求めて、それらの単語の平均を埋め込み表現とした場合(1行目のAvg. GloVe embeddings)よりも大幅に精度が悪くなっています。
BERTの[CLS]トークン部分ではなく、全単語の平均を取った場合は若干改善していますが、それでもGloVeの平均よりも悪くなっています。
そう考えるとやはり、文書のクラスタリングだけでなく、ほかのタスクでもBERTの埋め込みを使うってどうなの?と感じますね(念のためですが、BERTそのものを使うのはまったく問題ありません)。
そして、下の4行はSentence-BERTとそのRoBERTaバージョンですが、精度は大幅に改善していることがわかります。
教師ありSTS
次にSTSベンチマークというデータセットを使って学習します(教師あり学習を行います)。学習データは5,749サンプル、検証データは1,500サンプルで、最終的なテストデータは1,379サンプルとなっています。
学習データ、検証データで学習・ファインチューニングを行い、テストデータで精度を確認します。
Sentence-BERTのファインチューニングの目的関数は上記のregression objective functionを使います。
結果は以下の通りです。
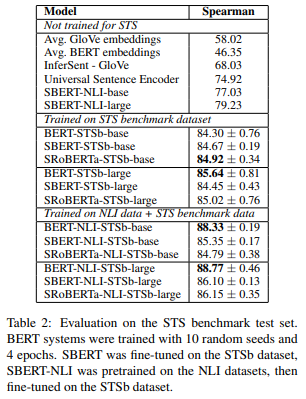
上段のSTSデータセットでファインチューニングしないモデル(つまり、教師あり学習をしない場合。“Not trained for STS”)を見ると、やはりBERTの埋め込みはGloVeの平均を取ったものよりも精度が悪くなっています。
Sentence-BERTでは、それらに比べ大幅に精度が改善しています。
中段のSTSベンチマーク・データセットで学習・ファインチューニングした場合を見ると、一番良いのはBERT-largeとなっています。
教師あり学習であれば、2つのペアをBERTに投入して、ファインチューニングしながら学習するので、やはりBERTの精度は優れています。
一方で、Sentence-RoBERTaもいい線いっています。
下段は、NLIデータでまず学習・ファインチューニングし、さらにSTSベンチマーク・データセットで追加学習した場合です。
この場合もやはりBERT-largeが一番精度が良くなっています。
Sentence-BERT、Sentence-RoBERTaもSTSベンチマーク・データセットだけで学習した場合よりも、1~2%程度精度が改善しています。
こう見ると、BERTの方が良いのではないか?と思うかもしれませんが、このような2つのペアに対して類似度を計算するといったタスクであれば、BERTを使うことができます。
しかしながら、大量の文書の類似度を計算して(1対1のペアではなく)クラスタリングする、複数の文書・文章の埋め込み表現を時系列データとしてLSTMなどに投入するような場合は、BERTでは時間が非常にかかって現実的ではありません。
また、BERTで埋め込み表現をあらかじめ計算しておくのは、この結果を見る限り得策ではなさそうです。
Sentence-BERTであれば予め埋め込み表現を計算しておき、あとは類似度を計算するだけなので、はるかに軽量です。
そういう意味で、BERTと大差ない精度が出ているということは、Sentence-BERTがクラスタリングなどのタスクにおいてBERT並みの精度が出せると考えられます。
Argument Facet Similarity
Argument Facet Similarity(AFS)というコーパスを使って確認します。
このデータセットは6,000個の会話型の文章ペアからなっており、“gun control”, “gay marriage”, “death penalty”の3つのトピックがあります。そして、そのペアについて0(まったく違うトピック)から5(完全に同じトピック)のラベルが振られています。
結果は以下です。
cosine similarityを計算し、それとラベル間のPearsonの相関係数\(r\)とSpeamanの順位相関係数\(\rho\)が記載されています。SBERTは、Regression Objective Functionを使ってファインチューニングしています。
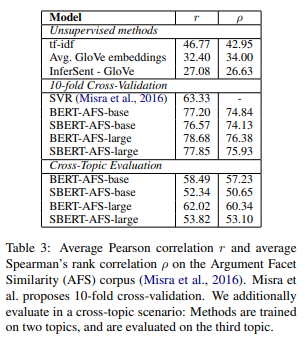
上段のTF-IDFやGloVeの平均、InferSentはあまり良くありません。
中段では、やはりBERTが一番良いですが、SBERTもほぼ同等の性能が出ていることがわかります。
最後に下段の“Cross-Topic Evaluation”ですが、これは、上記の3つのトピックのうち、2つのトピックで学習し、テストは残りの1つのトピックで学習させたものです。
これについては、SBERTよりもBERTの方が大きく上回っています。
その原因として、BERTでは、2つの文章をインプットとして、それぞれの単語などを直接attentionを使って比較することができるのに対して、SBERTでは、まず、埋め込み表現に落として、その上で比較をすることになるため、見たことのないトピックに対してはBERTよりも弱いという指摘がされています。
感覚的には、そんな気がしますね。
つまり、文書の分類を正しくするのであれば、対象となるタスクと同じようなコーパスを使ってSBERTをファインチューニングしてやる必要があるということが示唆されています。
Wikipedia Sections Distinction
次にWikipediaの節を当てるタスクです。
anchorとなるWikipediaの文章に対して、positive exampleはanchorと同じ節から取ってきた文章、negative exampleはanchorとは別の節から取ってきた文章を指定します。
そして、この3つの組を使って、上記のTriplet lossを目的関数として学習します。
そして、テストサンプルの結果が以下になります。
Accuracyは、anchorとpositive exampleの方がユークリッド距離が小さくなっている割合です。
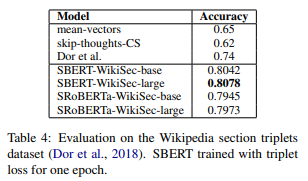
Skip-Thought VectorやBiLSTMを使っている“Dor et al.”よりも精度が良いことがわかります。
SentEval
ここでは、文章の埋め込み表現の質をはかるSentEvalを使って、SBERTの評価を行います。
細かいデータセットの説明は省略させていただきますので、気になる方は論文に簡単な説明がありますのでご参照ください。
結果は以下の通りで、7タスク中5タスクで一番良い結果を出しています。
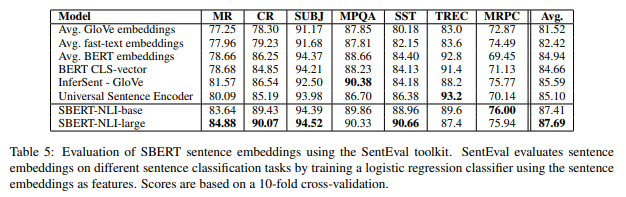
SBERTが特に良い結果を出しているMR、CR、SSTはどれもセンチメント分析です。
BERTについては、各単語部分の埋め込み表現の平均を使った場合も、[CLS]トークン部分を使った場合も、GloVeの平均よりも良くなっています。
しかしながら、SBERTの方がどのデータセットでも上回っていますので、埋め込み表現という意味ではやはり、SBERTの方が良いと考えられます。
Ablation Study
ここでは、Classification Objective Functionにのpoolingに“平均を取る”か、“最大値を取る”か、“[CLS]トークン部分を使う”か、の3つの場合を比較しています。
再掲しておくと、以下の図の“pooling”となっているです。
また、\(u, v, |u-v|\)となっている部分についても、ほかの結合の仕方を検証しています。
その結果がこちらです。
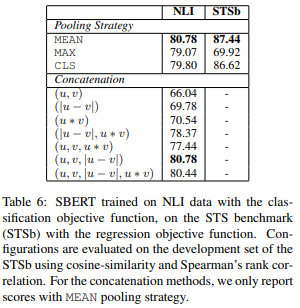
分類問題であるNLIと回帰問題であるSTSbで検証しており、NLIデータセットの方を見ると、BERTから出力される埋め込み表現の平均を取る場合(MEAN)が一番精度が高くなっています。
また、結合方法については、\(u, v, |u-v|\)が良くなっており、この結果をもとに、本論文を通してその結合方法が使われています。
それにしても結合方法については結構差が大きいですね。
単純に\(|u-v|\)だけだと精度は69.78と11ポイントも違ってきています。
まとめ
今回は、BERTの埋め込み表現の質を改善するSentence-BERT(SBERT)について学習しました。
大量の文書をクラスタリングする、あらかじめ埋め込み表現を求めてそれをLSTMなどのインプットにする、といった場合、非常に力を発揮します。
私の経験でも、手軽に使えるDoc2Vecでは全然ダメ、ならばということでBERTの埋め込みでやってみたものの結果はいまいち、と途方に暮れていたところでSentence-BERTを知り、試してみるとうまくいったということがありました。
ちなみに、こちらの記事では日本語のSentence-BERTのモデルを作成されています。
非常に有難いですね。
https://qiita.com/sonoisa/items/1df94d0a98cd4f209051
ただし、論文の結果でもありますが、違う種類のデータセットに対してはうまくいかない可能性もあるので、精度をすごく求めるのであれば、学習データの作成が大変ですが、自分でSentence-BERT学習用のデータセットを作ってファインチューニングした方が良いと思います。