では、今回は『Longformer: The Long-Document Transformer』について解説したいと思います。
LongformerもReformerやSparse Transformerと同じで、self-attentionの仕方を工夫することで、Transformerが長い文章に対してメモリ消費量が急激に増加する(\(O(n^2)\))ことに対応するモデルです。
これにより、文書全体のような長い文章に対してもTransformerを使うことができるようになります。
また、BERTやRoBERTaと同じように事前学習-ファインチューニングを行うことで、長い文章のタスクに対してBERTやRoBERTaを上回るような精度を達成しています。
Longformerを簡単にまとめると以下のようになります。
- Transformerのself-attentionの方法を工夫することで、長い文章に対してもTransformerベースのモデルを使えるようにする
- 事前学習-ファインチューニングを行うことにより、長い文章に対するタスクの精度を向上させる。
Sparse Transformerにかなり似ていますので、興味があればこちらも参考にしてみてください。

では、詳細を見ていきましょう。
目次
Transformerの問題点
先ほども述べましたが、Transformerの問題点はインプットとなる文章が長くなるとメモリの消費量が非常に大きくなることです。
具体的には、文章の長さ\(n\)に対して、\(O(n^2)\)で増加します。
この原因はTransformerの主要な部品であるScaled Dot-Product Self-attentionにあります。
Scaled Dot-Product Self-attentionは、クエリ\(Q\)、キー\(K\)、バリュー\(V\)を用いて、
$$\begin{align}
\text{attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}V\right)
\end{align}$$
という形で表されます(詳細はTransformerの解説記事をご参照ください)。
このとき、\(Q\)、\(K\)はサイズ\(n\times d_k\)の行列ですので、その積は\(n\times n\)となります。
例えば、2000トークンの文章をインプットとすると2000×2000で400万個の要素を持つ行列が出来上がります。
それをバッチサイズ分計算するとなると非常に大きなメモリを消費します。
Longformerとは
そこでLongformerでは、そのScaled Dot-Production attentionの方法を工夫します。
簡単に言うと、Scaled Dot-Product attentionでは、すべての単語からすべての単語へ注意を向けており、それが\(n^2\)のメモリ消費量に繋がっていましたが、それを重要な単語から重要な単語へのみ注意を向けるようにします。
では、具体的にどのようにするかを見てきましょう。
Attentionの種類
Longformerでは以下のアテンションのパターンを考えます。
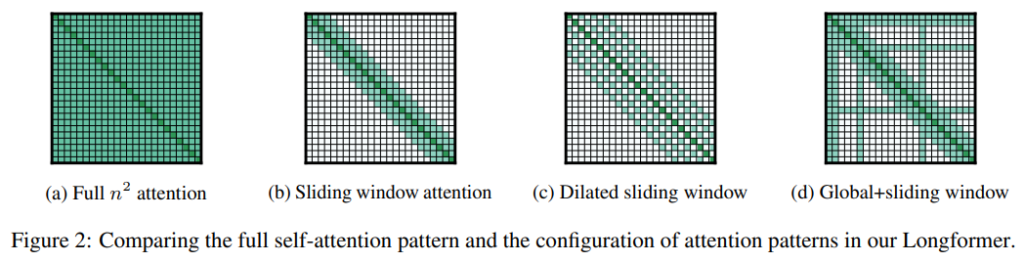
(a) Full n2 attention
Transformerで使われているScaled Dot-Product Attentionです。
すべての単語からすべての単語にattentionが向けられています。
(b) Sliding Window Attention
左から2番目の図のように、自分自身のすぐ近くだけにattentionを向けます。
ウィンドウサイズを\(w\)とし、自分自身から左右それぞれ\(\frac{1}{2}w\)個の単語にattentionを向けます。
これにより、メモリ使用量が\(O(n^2)\)から\(O(n\times w)\)になり、文章の長さ\(n\)に対して線形になります。
レイヤーによって\(w\)を変えることも可能ですし、実際に論文ではそうしています。
(c) Dilated Sliding Window
右から2番目の図です。
ギャップサイズを\(d\)としてattentionを向ける単語を\(d\)個ずつ飛ばしていきます。
multi-head attentionのheadごとに\(d\)を変えることにより、パフォーマンスが改善するとのことです。
(d) Global Attention
一番右の図です。
これは、Sliding Window Attentionと一緒に使います。
Sliding Window Attentionはすべての単語に注意を向けないものでしたが、Global Attentionは特定の単語位置の単語については、すべての単語に対してattentionを向け、またすべての単語はその特定の単語位置にattentionを向けるようにします。
例えば、BERTによる文書分類では、一番初めの単語に[CLS]というスペシャル・トークンを付加して、その位置にある隠れ層の値を分類に使用しています。
つまり、その位置は非常に重要ということです。
ですので、文書分類の場合は[CLS]トークンの位置はすべての単語に対してattentionを向け、すべての単語は[CLS]トークンの位置にattentionを向けるように設定します。
Question-Answeringタスクでは、質問文の箇所がすべての単語位置にattentionを向け、すべての単語は質問文にattentionを向けます。
この特定の単語位置はあくまで数単語なので\(O(n)\)のままになります。
Linear Projection
Transformerでは、\(Q\)、\(K\)、\(V\)は線形写像が行われていますが、Longformerでは、sliding window attentionとglobal attentionでは違う写像を行います。
したがって、sliding window attentionでは\(Q_s\)、\(K_s\)、\(V_s\)を使い、global attentionでは\(Q_g\)、\(K_g\)、\(V_g\)という別の写像を使います。
Attentionパターン
ウィンドウサイズをレイヤーごとに変えることで、さらに工夫しています。
Sliding Window Attentionの設定
まず、低位のレイヤー(はじめの方のレイヤー)についてはウィンドウサイズを小さくし、上位のレイヤーについてはウィンドウサイズを大きくしていきます。
これにより以下の効果があります。
- 低位のレイヤーはより局所的な情報を集約する
- 上位のレイヤーは全体的な情報を集約する
Dilated Sliding Window Attentionの設定
低位のレイヤーにはdilated sliding window attentionは行いません。
これは、低位レイヤーではしっかりと局所的な情報を集約するためです。
また、上位のレイヤーでもdilationを行うのは2つのheadのみに限定します。
実験
では、実験方法とその結果を見ていきましょう。
学習
まず、局所的な情報の学習には多くの時間をかけた方がうまくいくことがわかったとのことです。
ですので、学習フェーズを5つに分割し、そのステージごとにインプットの文章の長さを伸ばしていき、またウィンドウサイズを増加させる、ということを行います。
はじめは、文章を短く、ウィンドウサイズを小さくし、次のフェーズではそれらを倍にします。
それと同時に学習率を半分にしていきます。
細かいハイパーパラメータは以下の図の通りですが、低位のレイヤーではウィンドウサイズを32からはじめて5番目のフェーズでは512まで増やしています。
また、文章の長さは2,048からスタートし23,040まで増やしていきます。

結果
では、学習結果を見ていきましょう。
まず、小さいモデルを使ってtext3データセットとenwik8データセットで比較しています。
それぞれ1.10BPC(BPC; Bit-Per-Character)、1.00(BPC)と、Transformer-XLやReformerなどを上回っています。
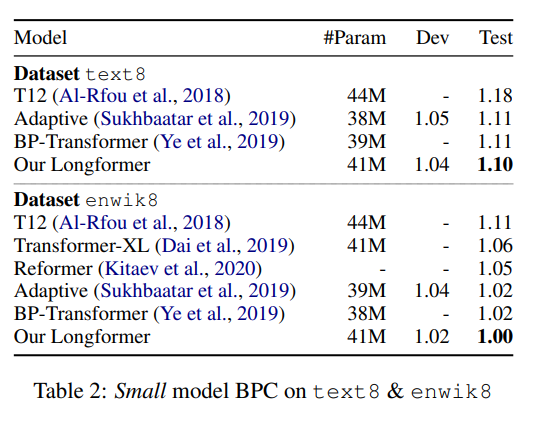
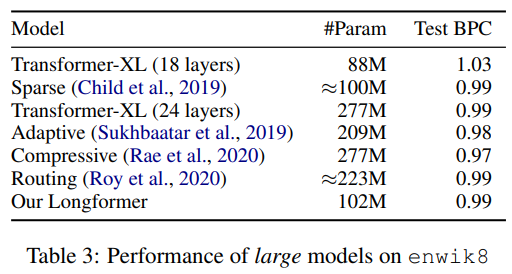
さらにモデルを大きくしたLongformerでは、Sparse Transformerと同水準、その他のパラメータ数が2倍程度あるモデルに対しては若干劣っているものの大差ない水準を達成しています。
Ablation Study
ウィンドウサイズを増加させたりdilationを行ったりする影響を分析しています。

上段では、ウィンドウサイズの影響を分析していますが、ウィンドウサイズを固定した場合と比較して、ウィンドウサイズを減少させていく場合では精度が悪化、増加させていく場合では精度が改善しています。
また、dilationについては、dilationをしない場合よりも2つのattention headでdilationをする場合の方が精度が改善していることがわかります。
事前学習-ファインチューニング
では、BERTなどと同じように事前学習-ファインチューニングを行い、特定のタスクでその精度を確認します。
これはTransformer-XLやReformerでは議論されていないことです(Transformer-XLの仕組みを取り入れているXLNetで行われていますが)。
文章の長さはBERTの8倍の4,096単語まで処理できるようにします。
事前学習は負荷が高いので、RoBERTaのチェックポイント(モデルパラメータ)を利用します。
そのためSliding Window AttentionのウィンドウサイズがRoBERTaのattenionの長さと同じになるように512とします。
そして、RoBERTaではPosition Embeddingが512個までしかないので、RoBERTaの初期値を使うことができません。
そこで、4,096個の単語数に対応するため、RoBERTaのPosition Embeddingを8個コピーするという方法を取ります。
それでいいの?と思いますが、それでも結構うまくいくようです。
そして、BooksCorpus、English Wikipediaに加えて、文章が長めのRealNewsデータセット、Storiesデータセットを使って事前学習をします。
タスクの説明
まずタスクの説明をしておきます。
QAタスク
以下の3つのデータセットを使います。
- WikiHop
複数の文書から成る手掛かり文を読んで、それらの情報をつなげて回答する必要があるデータセットです。

- TriviaQA
1つのサンプルが質問、答え、エビデンスの3つからなるデータセットです。

HotpotQA
こちらも複数の文書から成る文章を手掛かりに回答するデータセットです。

Coreference Resolutionタスク
以下のデータセットを利用します。
- OntoNotes
文章がTree構造で表現されているデータセットです。
なお、このタスクではglobal attentionは使いません。
Classificationタスク
以下のデータセットを使います。
- IMDB
映画のレビューで、比較的短い文章から成ります。 - Hyperpartisan
ニュースのデータセットで比較的長い文章が多くなっています。
詳しい情報はこちらをご参照ください → 『SemEval-2019 Task 4: Hyperpartisan News Detection』
[CLS]トークンに対してglobal attentionを適用します。
結果
では、それぞれのタスクを解いた結果です。
結果は以下の通りで、QAタスク、Coreference Resolution、文書分類ともにベースラインであるRoBERTaを超えています。

特にWikiHop(一番左)やHyperpartisan(一番右)という文章が長いデータセットについて、RoBERTaよりも改善幅が大きくなっています。
IMDBデータセットのような文章が短いタスクについては精度はほとんど変わっていません。
したがって、Longformerが文章の長いタスクをうまく処理できていることがわかります。
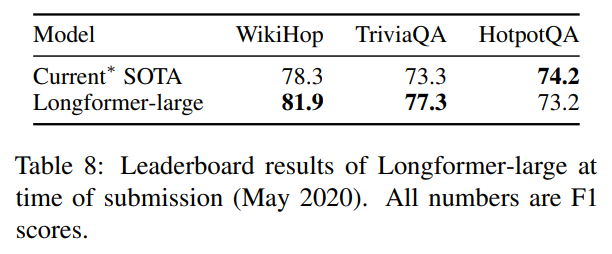
Longformer-large
さきほどはLongformer-baseを使ったRoBERTaとの比較でしたが、次は大きなモデルのLongformer-largeを使います。
WikiHopとTriviaQAデータセットで結構な差をもってSoTAを達成しています。
Hotpotは若干下回っています。
Ablation Study
WikiHopデータセットを使って、Longformerの使っている手法の影響を分析しています。

まず、一番上のLongformerに対し、下段の上から3つ目と4つめののLongformer(seqlen: 512)、Longformer(seqlen: 2,048)を見ると精度が71.7、73.1と悪化していることから、文章の長さを長くすることにより精度が改善しているということがわかります。
次に、下段の上から5番目のLongformer(no MLM pretraining)、6番目のLongformer(no linear proj.)、7番目のLongformer(no linear prj. no global atten)ですが、これはそれぞれ“事前学習なし”、“sliding window attentionとglobal atentionで線形写像を分けない”、“global attentionなし“の場合です。
どの場合でも精度は悪化していますので、事前学習を追加で行うこと、線形写像を分けること、global attentionはどれも重要であることがわかります。
また、下段の上から2つ目の精度が改善していることから長く事前学習することが有効であることもわかります。
Longformer-Encoder-Decoder(LED)
これまでは、エンコーダーのみのTransformerを使ってきましたが、ここでは、Seq2Seqのようなエンコーダー・デコーダーを使った要約タスクの性能を見ていきます。
パラメータはBARTのものをそのまま使います。
ちなみに、BERTではなくBART(Bidirectional and Auto-Regressive Transformers)で、こちらはBERTをSeq2Seqの形に応用したものです。
BARTはLongformer-Encoder-Decoderと同じ構造になりますので、そのパラメータをそのまま使います。
ただし、インプットする文章がBARTが1,000に対してLongformerが16000と長いので、その分はRoBERTaのときと同様にBARTのPositional Embeddingを16回コピーして使います。
それ以外には事前学習は行いません。
データセットはArXivデータセットを使っています。
結果
結果は以下の通りです。
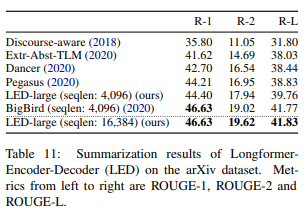
ROUGE-1、ROUGE-2、ROUGE-Lは要約タスクの精度を測る指標です(ここでは詳細は割愛します)。
BigBirdを上回ってSoTAを達成していることがわかります。
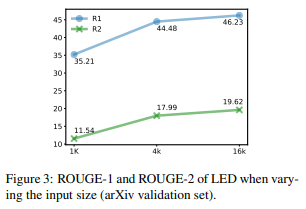
また、以下はLongformerで入力する文章を増やしていった場合の精度の変化ですが、長くインプットする方が精度が改善していることがわかります。
まとめ
今回は長い文章に対応したTransformerであるLongformerの論文を解説しました。
Sliding Window Attenion、Dilated Sliding Window Attention、Global Attentionという3つのアテンションを使って、長い文章でもメモリの使用量がそれほど大きくならないように工夫されていました。
実務でも文章が比較的長いデータセットを使うことも多いので、いずれ使ってみたいと思います。
誰か日本語で事前学習をしてくれないかなぁと思いますが…。