このサイトでは基本的に自然言語処理の論文等をご紹介してきましたが、今回はOpenAIが発表した画像生成モデル『Image GPT』の論文を解説したいと思います。
こちらはOpenAIの記事で紹介されている画像ですが、画像の上半分だけをインプットとして、残りを『ImageGPT』が生成するというものです。
一番左がインプットで、一番右が本物の画像です。そして、真ん中の4つの画像がImageGPTにより生成された画像です。
非常によくできていますね。

自然言語処理のGPTでは、文章の途中までをインプットとして、その続きを生成したり、ニュースのタイトルをインプットして、人間でも偽物と見分けがつかないようなニュース記事を生成していました。
それと同じようなことを画像認識にも適用した形です。
ということで、今回はそのImage GPTの論文を解説していきたいと思います。
論文は「Generative Pretraining from Pixels」です。
目次
Image GPT
まず自然言語処理で使われているGPTについて説明します。
知ってるよ、という方は飛ばしていただいて、Image GPTのところから読んでいただいて結構です。
詳しい解説はこちらをご参照ください。


自然言語処理のGPT
GPTはもともと自然言語処理のために考え出されたモデルであり、Transformerというモデルの仕組みを使って大量の文章データで事前学習したモデルです。
事前学習
事前額学習は具体的には、Wikipediaなどの文章のかたまりのデータセットを用意し、
「グリニッジ・ヴィレッジ周辺のフォーク・ソングを聴かせるクラブやコーヒーハウスなどで弾き語りをしていた」
という文章があるとすると、まず、「グリニッジ・ヴィレッジ」という単語を与え、次の単語に何が来るかを予測します。
ここでは、「周辺」が正しいので、「周辺」を予測するようにパラメータを調整します。
その次は、「グリニッジ・ヴィレッジ周辺」の次の単語を予測し、「の」が正しいので、「の」の予測確率が高くなるようにパラメータを調整します。
という感じで、前から順番に次の単語、次の単語と逐次的に文章を生成するように予測していくことで、言語というものを学習します。
そこから「Generative Pre-trained Transformer」と名付けられました。
これを非常に大きなモデルで大量の文章を使って学習することで、文章の構造や単語の使われ方など、言語の基本を学習します。
解きたいタスクを学習する前に一般的な文章データを使って学習するので、これを事前学習と呼びます。
この事前学習は、巨大なデータセットを使って学習することが一般的なので非常に長い時間がかかります。
ファインチューニング
いったん事前学習で言語を理解すると、あとは分類問題など特定の解きたいタスクのラベル付きデータを使って学習します。
事前学習で文章の構造などを理解しているので、これまでと比べて少量のラベル付きデータで学習しても、高い精度を達成することができます。
ここで、事前学習で得たパラメータを初期値として、分類するためのレイヤーを一番上に付けます。
そして、ラベル付きデータで分類するためのレイヤーやそれまでの中間レイヤーを再度学習します。
これをファインチューニングと呼びます。
Image GPTの概要
では、ここではImage GPTの概要について説明します。細かい仕組みについては後述します。
Image GPTはGPTの画像版で、論文のタイトル「Generative Pretraining from Pixels」の通りピクセル情報を使ってそれを生成するように事前学習するというものです。
ですので、Image GPTは自然言語処理のGPT(GPT2、GPT3)と同じようなモデルと事前学習手法を画像に適用したものになります。
自然言語処理のGPTでは最初の数単語を与えてやると、事前学習で学習した内容からその続きの文章を生成することができ、ニュースのタイトルを与えてやると、人間でも本物と区別のつかないようなニュース記事を生成することが可能です。
それと同様に上の例では、画像の一部分(初めのピクセル)を与え、その続きの画像を生成したということです。
では、その仕組みを見ていきましょう。
Image GPTでは自然言語処理のGPTと同じように大量のラベルなし画像を使って事前学習をします。
以下が学習全体の例です。
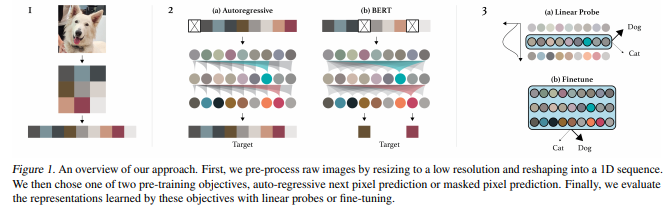
事前学習のポイントは、一番左の図のように、画像をいったん解像度の低い画像に変換し、そして、それを1列に並べます。
この画像では、ピクセルを左上から右に並べ、一番右にきたら次は1つ下の段の一番左に、そしてまた右に並べるという感じです。

ここで解像度を低くする理由はTransformerではあまり長い系列を扱おうとすると急激に処理が重くなるからです。
これをすることで、自然言語処理と同じ扱いにすることができます。
そして、ピクセル情報を予測する形で学習します。
これを非常に大きなモデルを使って、様々な種類の画像を事前学習することで、画像の一般的な並びを学習することができます。
- 自然言語処理のGPTを画像処理に応用したモデル。
- ラベルの付いていない大量の画像を使ってピクセル情報を予測することで事前学習を行う。
Image GPTの仕組み
では、論文に沿って学習方法を見ていきましょう。
事前学習
Autoregressiveな事前学習とBERTの事前学習
事前学習には2通りの方法を使います。
1つは、GPTと同じ次のピクセル、次のピクセルを予測する方法で、これを“Auto-regressive”なモデルと呼びます。
つまり、前から順番に見ていき、最後のピクセルの次のピクセルを予測するということです。
もう1つは自然言語処理では非常に有名なモデルである“BERTで採用された方法”です。
詳しく解説しませんが、BERTは文章の前から読むだけではなく、後ろからも読めるような“双方向”のモデルです。
それを可能にしたのがMasked Language Modelという事前学習手法なのですが、これは文章中の単語の15%を[MASK]に置き換え、その[MASK]となっている箇所の単語を予測することで、言語を理解しようとするものです。
これと同じで、特定のピクセルについてマスクし、マスクされていないピクセルの情報をもとにマスクされているピクセルを予測します。
先ほどの図だと、左側がAutoregressiveな事前学習、右側がBERTのように特定のピクセルをマスクし、その部分(のみ)を予測するという事前学習になります。
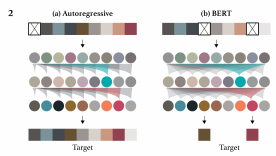
丸と丸の間にある影のようなものは、attention(注意)を表し、attentionの向ける方向を表しています。
以下は上図について、Autoregressiveのattentionを部分を取り出したものです。

Autoregressiveの場合、自分自身の位置よりも前の箇所にだけattentionが向いています。
つまり、自分自身よりも前の箇所だけを見ているということになります。
一方でこちらは、BERTの手法ですが、attentionが自分の位置よりも後ろの位置にまでattentionが向いています。

つまり、自分よりも後ろの位置も見ていることになります。
これにより、BERTは後ろの情報も使うことができることから双方向のモデルと言われます。
詳細についてはBERTの記事をご参照ください。

定式化
では、それぞれを定式化しておきます。
Auto-regressiveなモデル
まずは、Auto-regressiveなモデルの方です。
一つのデータを\(x=x_1, \cdots, x_n\)とします。
これを\(\pi\)という順番に並び替えます。
この並べ方は左上から右に向かって並べたり、左上から下に向かって並べたりするということです。
そして、\(x\)の尤度\(p(x)\)は、条件付き期待値の形で以下のように書くことができます。
$$\begin{align}
p(x)&=p(x_{\pi_1}, \cdots, x_{\pi_n})\\
&=\prod^n_{i=1}p(x_{\pi_i}|x_{\pi_1}, \cdots, x_{\pi_{i-1}}, \theta)
\end{align}$$
\(\theta\)はパラメータを表します。
つまり、\(x_{\pi_1}\)から順番に\(x_{\pi_2}\)、\(x_{\pi_3}\)と計算することで尤度を計算することができます。
そして、データセット\(X\)全体に対して、以下のように対数尤度を最大化(負の対数尤度を最小化)することで学習します。
$$\mathcal{L}_\text{AR} = \mathbb{E}_{x\sim X}\left[-\log p(x)\right]$$
BERT
次に、BERTのようにマスクを使ったモデルについてです。
\([1, n]\)の中から\(M\)という部分列を選んできます。
\(M\)は\(n\)の15%で、つまり15%をマスクするという意味です。
そして、マスクしていない部分の情報で条件付けし、マスクをした部分\(x_M\)の対数尤度が最大(負の対数尤度が最小)になるように学習します。
$$\mathcal{L}_\text{BERT}=\mathbb{E}_{x\sim X}\mathbb{E}_M \left[-\log p(x_i|x_{[1, n]\backslash M})\right]$$
モデルの構造
モデルは基本的にはTransformerです。
Transformerの詳細については、以下の記事を参照ください。

Transformerは、自然言語処理分野では欠かせない仕組みになり、画像処理でも最近利用されるようになってきたので、理解していると良いと思います。
まず、インプットを\(x_1, \cdots, x_n\)とし、それを各時点について\(d\)次元の埋め込み表現に変換します。
それを\(h_1^1, \cdots, h_n^1\)とします。
これをTransformerブロックに投入し、そのアウトプットをまたTransformerブロックに投入するということを繰り返します。
オリジナルのTransformerブロックは以下のような仕組みです。
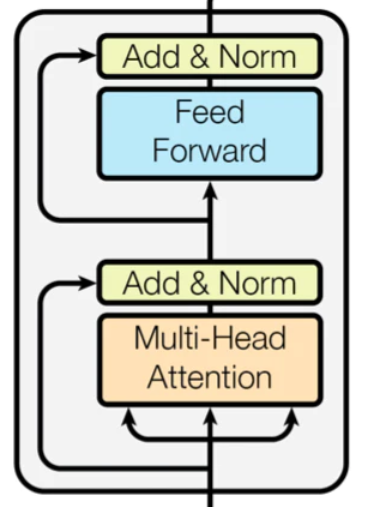
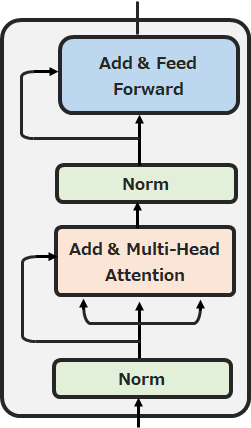
Image GPTではこれを少し変えて以下のようなTransformerブロックになっています。これを何回も繰り返します。
では、一つ一つ見ていきましょう。
まず、\(l\)番目のTransformerブロックのインプットである\({\bf{h^l}}=h_1^l, \cdots, h_n^l\)をレイヤー正規化(Layer Normalization)層を使って正規化します。
$$n^l=\text{layer_norm}({\bf{h}}^l)$$
レイヤー正規化とは、バッチ正規化(Batch Normalization)を少し修正したもので、レイヤーへのインプットを正規化する(平均・分散をそろえる)と考えていただいて大丈夫です。
詳細を知りたい方はこちらの記事をご参照ください。

そして、次にMulti-Head Attention層に投入し、その結果を残差結合します。
$$a^l=h^l+\text{multihead_attention}(n^l)$$
Multi-Head Attention層とは、Self-Attentionという手法を使った層であり、Transformerの核の部分になります。
ただ、ここを説明していると非常に時間がかかるので、中身を知りたい方はこちらの記事をご参照ください。
前述しましたが、このときにAuto-regressiveなモデルの方は、自分自身より前の位置にしかattentionを向けません。
ですので、Autoregressiveなモデルでは、自分より先の情報にattentionを向けないようにマスクします(自分より先を見ていません)。
BERTの方ではそれは不要で、すべての箇所にattentionを向けることができます(これがGPTの片方向とBERTの双方向の違いです)。
最後にMulti-Head Attention層のアウトプットをレイヤー正規化層、全結合層に流します。(Transformer論文ではFeed Forward層と呼ばれていたものです)
$$h^{l+1}=a^l+\text{mlp}(\text{layer_norm}(a^l))$$
このときも残差結合を行います。
以下の図を再掲しておきます。
なお、時系列モデルであるLSTMや画像処理でよく使われるCNNと違って、このままでは位置の情報がありません。
自然言語処理の話で言うと、LSTMは前から順番に処理をしていくので、情報が順番に並んでいることになるのですが、Transformerはすべてのインプットを同時に処理するので(通常のパーセプトロンのようなもの)、その単語が何番目の単語か?、もしくは2つの単語はどちらが前にあるか?といった位置情報が必要になってきます。
そこで、Transformerではpositional embeddingという方法で位置情報を付加します。
これは、最初の埋め込み表現に、位置情報を示す埋め込み表現を足し算するというものです。
もともとのTransformerでは、sin・cosを使って位置情報を示す埋め込み表現を表しましたが、BERTではその位置情報を示す埋め込み表現も学習させます。
その手法を踏襲して、Image GPTも位置情報を示す埋め込み表現を学習させるようにします。
これにより、ピクセルを1列に並べ替えましたが、その並べ方に依存しなくなります。
そして、最終的には\(L\)番目のレイヤーのアウトプットをレイヤー正規化層を通した\(n^L\)を求めます。
$$n^L=\text{layer_norm(h^L)}$$そしてその\(n^L\)を使って、softmaxレイヤーで次のピクセルなり、BERT型であればマスクされた部分のピクセル情報を予測します。
分類方法
今までは事前学習、つまりラベルなしデータをもとに画像の仕組みを学習する方法に関する説明でした。
ここからは、実際に画像が何か?を予測する方法について解説します。
この方法には“ファインチューニング”と“linear probing”があります。
- ファインチューニング
事前学習で学習したTransformerの一番上に分類層を追加し、教師ありデータを使って分類層とTransformerのパラメータを再度学習する。
- linear probing
事前学習で学習したTransformerの特定のレイヤーのアウトプットをインプットとして、線形分類を行う。このとき、Transformerのパラメータについては更新しない。
ファインチューニング
ファインチューニングは、事前学習したモデルの一番最後に分類用の層を追加し、教師ありデータで再度追加の学習を行うものです。
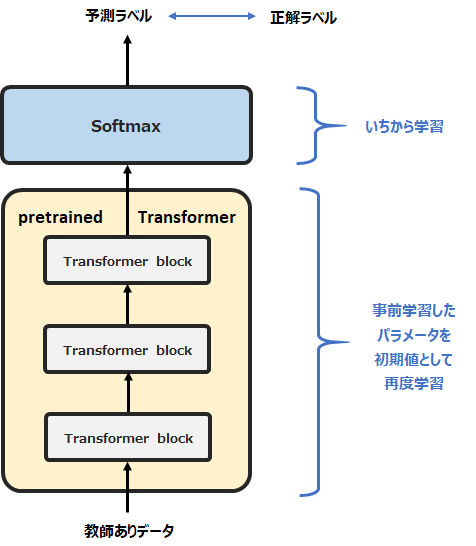
このときに最後の分類層以外のMulti-Head Attention層などのパラメータの初期値には、事前学習で学習したパラメータを使います。
これにより、非常に良い初期値をもとに追加で学習するので、少ない教師データでも高い精度が出ます(これを転移学習と呼びます)。
具体的にImage GPTではどうするかというと、最終アウトプットである\(n^L\)を使います。
\(n^L\)は\(d\times n\)次元なので、average-pooling(次元ごとに平均を取る)によりこれを\(d\)次元にします。
$$f^L=\langle n_i^L\rangle_i$$
これが画像情報が凝縮されたベクトルになります。
そしてsoftmax層で分類を行い、損失を計算します。
この場合の損失関数は、
$$\mathcal{L}_\text{GEN}+\mathcal{L}_\text{CLF}$$
とします。ここで\(\mathcal{L}_\text{GEN}\in \{\mathcal{L}_\text{AR}, \mathcal{L}_\text{BERT}\}\)です。
Linear Probing
Linear Probingは、Transformerの特定のレイヤーの値を取ってきて(埋め込み表現とも言います)、それをインプットとして線形分類する方法です。
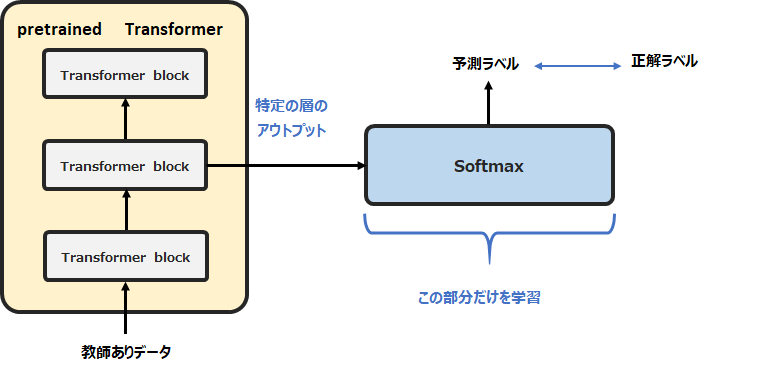
つまりファインチューニングのように特定のレイヤーの値は更新せず、事前学習で得られた特定のレイヤーの値を固定して、それを線形分類器のインプットとします。
一般的には複数のレイヤーのうち最後の方のレイヤーが良いとされていますが、ここではどの層が良いかも検証しています。
\(l\)番目のレイヤーの平均を取り、
$$f^l=\langle n_i^l \rangle_i$$
\(\mathcal{L}_\text{CLF}\)のみを最小化するように学習します。
学習方法
データセット
事前学習用のデータセットはImageNet ILSVRCを使います。
ImageNet ILSVRCデータセットは、ImageNetデータセットから抜き出した1000個のカテゴリーのラベル付きの120万画像のとても大きなデータセットです。
ILSVRCデータセットの学習データセットのうちの96%を事前学習用データとして、残りの4%を検証用データとします。
そして、ILSVRCデータセットの検証用データセットをテスト用データとして使います。
事前学習ではラベルは不要ですので、ラベルは使いません。
そして、Largeサイズのモデルについては、Webから集めた100万画像も追加します。
事前学習の良いところは、質を担保するためにある程度のフィルタリングは必要ですが、ラベルを付ける必要がないためデータの収集コストが低いことです。
ファインチューニングやLinear Probingには、CIFAR-10、CIFAR-100、STL-10データセットを使います。
解像度の削減
Transformerはインプットの系列が長くなると非常に計算負荷が大きくなるという問題があり、具体的には、インプットの長さ\(n\)の2乗に計算負荷が大きくなります(これに対応するために、Sparse Transformer、Longformer、Reformerなどattentionを工夫するモデルがいくつか出ています)。
今回の画像データは、2242×3なのでそのまま1列に並べると15万個の系列になってしまい、これはTransformerでは処理できません。
そこでImage GPTでは、画像の解像度を下げ322×3、482×3、642×3とします。
これをImage Resolution(IR)と呼びます。
それでも、642×3でもなかなか多い方です。
そこで、Image GPTでは、さらにRGBパレットを\(k=512\)のK-Meansを使ってクラスタリングすることにより、色を512個で表現することにより、次元をさらに322、482、642と1/3に落とします。
これをModel Resolution(MR)と呼びます。
これでTransformerで処理できるようになります。
モデル
一番大きいiGPT-XLは60レイヤーで隠れ層の次元を3072とした68億パラメータのモデルとします。
その次に大きいiGPT-LはGPT-2と同じ48レイヤーで、次元数が1536とGPT-2から少し減らした14億パラメータ(GPT2は次元数1600の約15億パラメータ)のモデルとします(論文では140万になっていますが、たぶん間違いです)。
iGPT-Mは36レイヤー1024次元4億5500万パラメータ、iGPT-Sは24レイヤー512次元の7600万パラメータとします。
より細かいハイパーパラメータの設定は論文をご参照ください。
実験結果
どのレイヤーが良い埋め込み表現か
では、事前学習の結果、レイヤーごとにインプットの埋め込み表現が得られますが、どのレイヤーの埋め込み表現が良いかを確認します。
ここでは、Linear Probingにより、レイヤーの埋め込み表現をインプットとして線形分類により画像の分類精度を確認します。
このlinear probingによる分類精度が高いほど、“良い埋め込み表現”であると考えます。
iGPT-Lを使った結果は以下のようになっています。
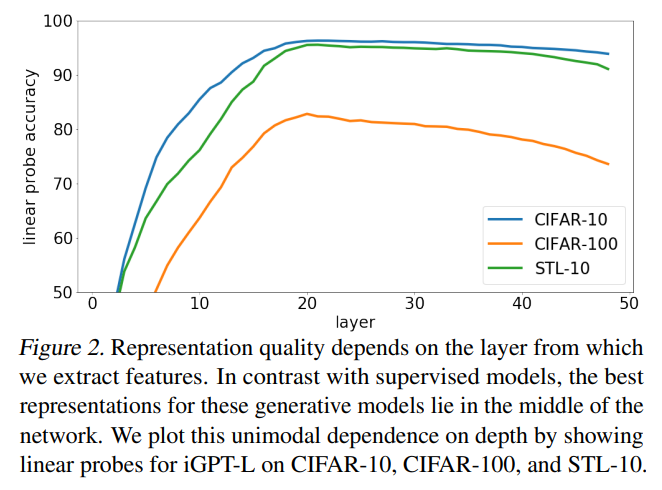
まず、CIFAR-10、STL-10データセットの精度が90%後半であり、非常に精度が高いことがわかります。
そして、下位のレイヤーでは精度が低く、上位のレイヤーにいくにつれて精度が改善し、中間を過ぎたあたりからまた下落していきます。
恐らく低位から少しずつ画像の全体感を捉えていき、上位のレイヤーでは次のピクセルを予測するための局所的な情報が詰まっていると考えられます。
ですので、中間のレイヤーがほどよく全体感をつかんだ情報が詰まっていると考えられます。
より良い生成モデルはより良い埋め込み表現を学習
続いて、事前学習の精度とlinear probingの精度を比較します。
iGPT-S、iGPT-M、iGPT-Lとモデルサイズを変えて事前学習を行います。
その事前学習の精度とそれらの特定のレイヤーの埋め込み表現を使ってlinear probeで画像の分類問題を解いたときの精度を比較した結果が以下です。
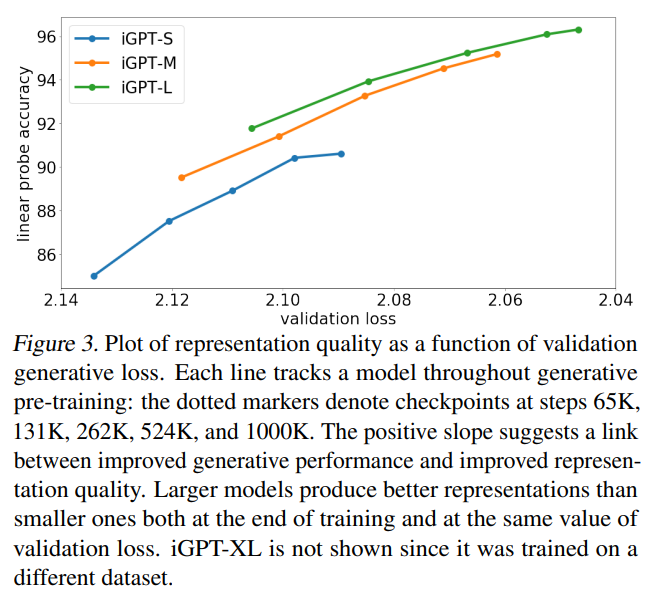
ここからいくつかのことがわかりますが、まず、モデルサイズが大きいほど事前学習の精度(validation loss)が高く(小さく)なっています。
同様にモデルサイズが大きいほど、後続のタスクである分類問題の精度も良くなっています。
そして、同じ事前学習の精度(validation loss)であっても大きなモデルの方が後続の分類タスクの精度が良くなっています。
Linear Probingの精度
ここでは、他の事前学習モデルとlinear probingにより評価した結果を比較します。
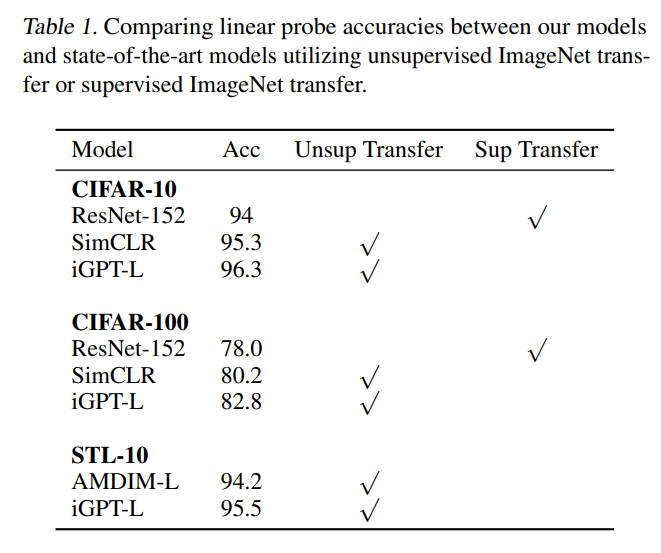
まず、CIFAR-10、CIFAR-100では、ResNet-152やSimCLRを上回って(Linear Probingによる)SoTAを達成しています。
CIFAR-10、CIFAR-100の解像度は322なのでImage GPTのImage Resolutio(IR)と同じです。
STL-10でもAMDIM-Lを上回ってSoTAを達成しています。
STL-10の解像度は962ですが、解像度を322に落としたImage GPTが上回っています。
ImageNetデータセットのLinear Probe
ImageNetでlinear probeの精度を確認します。
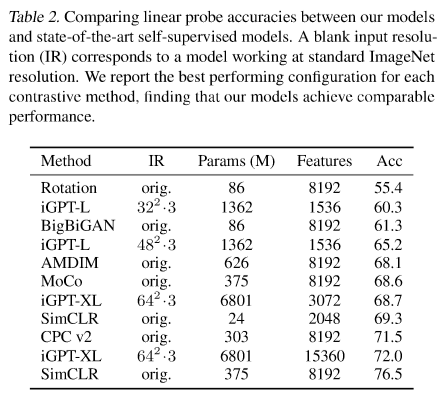
ImageNetでは、基本的にはSoTaに及びません。
原因としては、ImageNetは比較的解像度が高く、Image GPTでは解像度をかなり落としていることが考えられます。
iGPT-Lでは、解像度を322で60.3%、解像度482で65.2%という精度で、SimCLRの76.5%には遠く及びません。
特徴量を3072、解像度を642にしてiGPT-XLで評価すると68.7%まで改善します。
SimCLRでは非常に高次元ですので、Image GPTでもそれを試します。
ただ、8192次元にするのは計算負荷が高すぎるため、各レイヤーの隠れ層の値を結合することにより高次元の特徴量とします。
iGPT-XLで5レイヤーをつなげると15360次元となり、72.0%の精度になります。
それでもSImCLRは解像度を落としていないので、76.5%とiGPT-XLよりも高い精度になっています。
ファインチューニング
今までは、事前学習で得られた埋め込み表現をもとに線形分類した精度を見てきましたが、ここではファインチューニングの精度を見ます。
繰り返しになりますが、ファインチューニングでは、分類層だけでなくAttention層などのパラメータも更新するので、基本的にはLinear Probingよりも精度は改善します。
一般的に一番上位のレイヤーに分類層を付け加えますが、ここではLinear Probiingで一番良い精度だったレイヤーに対して分類層を付け加えます。
結果は以下の通りです。
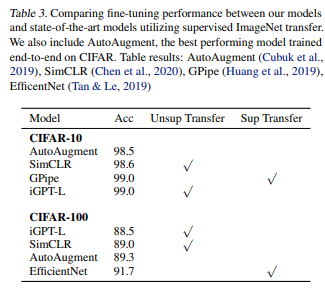
CIFAR-10では99.0%の精度となり、CIFAR-10のみの教師あり学習で最も良い精度を出していたAutoAugmentの精度を上回っています。
そして、GPipeと同程度の精度となっています。GPipeはImageNetを使った転移学習手法です。
CIFAR-100では88.5%の精度になっており、EfficieentNetなどにはまだまだ及びません。
BERT
BERTの事前学習方法を使った場合の精度について見ていきます。
結果は以下ですが、水色とオレンジがlinear probeによる精度で、BERTのみにある濃い青と濃いオレンジは、ファインチューニング時のインプットにもマスクをする場合です(これにより事前学習時とファインチューニング時でインプットの分布が同じになります)。
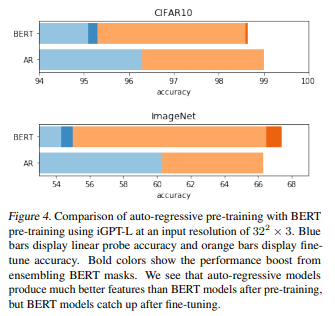
CIFAR-10、ImageNetデータセットともにLinear ProbeではAutoregressiveなモデルの方が精度が高くなっていますが、ファインチューニングではほぼ同程度の差になっています。
BERTでファインチューニング時にもマスクすることにより精度が若干改善し、CIFAR-10でAutoregressiveなモデルにはわずかに及ばず、ImageNetでは若干上回っています。
まとめ
今回は、自然言語処理のモデルGPTを画像分野に応用したImage GPTについて見てきました。
Image GPT以外にもVisionTransformerなどTransformerが画像に応用されてきていて面白いですね。
Transformerについては、画像処理分野においても重要になってきているので、しっかりと理解した方が良いですね。
一応オススメの本を載せておきます。
TransformerやBERTも理解でき、画像処理、GAN、さらにPyTorchも理解できる非常によい本だと思います。
『DALL-E』など面白い話もありますし、今後、少しずつ画像分野も記事にしていければと思います。
では!