とうとうOpenAIの『DALL-E2』の順番待ち(waitlist)から、実際に使えるようになりました!
私の家はけっこう壁に小さな絵やポスターを飾っているのですが、妻にDALL-Eで生成するところを見せていると、「これ印刷することもできるの?印刷してフォトフレームに入れて飾りたいだけど」と言ってました。
AIに言葉でイメージを伝えて絵を描いてもらう、もうそんな時代が来ているのかもしれませんね。
ということで、今回は簡単にDALL-Eの解説をして、DALL-Eベータ版ではどんな感じで画像を生成できるか皆さんにご紹介したいと思います。
目次
DALL-Eとは
『DALL-E』はOpenAIが2021年に公表した“テキスト情報を入力して、それに合った画像を生成する深層学習モデル”です。
名前の由来は、スペインの画家サルバドール・ダリ(Salvador Dalí )と映画『WALL・E(ウォーリー)』から来ています。
DALL-Eの公式ページはこちらですので興味がある方は見てみてください。 ⇒ DALL·E: Creating Images from Text
DALL-Eの仕組みを1文で無理矢理まとめると、
「VQ-VAEという画像生成モデルと自然言語処理モデルであるTransformerを組み合わせてテキスト情報から画像を生成し、さらにCLIPという画像と自然言語を同時に処理するモデルで、生成された画像がテキスト情報との一致度を判定して、一致度が高い画像を出力するモデル」
です。
1文ではよくわかりませんね(笑)
そして、このややこしいモデルで、インターネットから集めた大量の画像とテキスト情報(キャプション)をデータとして学習することにより、非常に面白い画像が生成できるようになりました。
例えば「アボカドの形をしたアームチェア」など、学習データにはなかったような文章に対して、以下のように非常にクリエイティブな画像を生成することができます。

モデルの詳細に興味がある方は、以下の記事をご参照ください。(VQ-VAEやTransformerの知識が必要ですが、それらについてもサイト内で解説しています)

このように非常に面白い画像を生成することで話題になったDALL-Eですが、2022年にさらに精度が良くなった『DALL-E2』が公表されました。
論文 ⇒ 『Hierarchical Text-Conditional Image Generation with CLIP Latents』
この『DALL-E2』は「テキスト情報との整合性」、「画像のリアルさ」の点で初代のDALL-Eよりも大幅に良くなっています。

モデルは、最近『GLIDE(Guided Language to Image Diffusion for Generation and Editing)』などでも話題のDiffusion Model(拡散モデル)を採用しています。
GLIDEはDiffusion Modelを使った、テキスト情報から画像を生成するモデルです。
(DALL-E2のモデルの詳細は本サイトではまだ解説していませんが、いつかしたいと思っています)
このDALL-E2が、ウェイトリストに登録し順番が回ってくると一般利用できるようになりました。
そして、とうとう私のところにも順番が回ってきました。
背景には2022年7月20日に公表された『DALL·E Now Available in Beta』という記事にもある通り、これから数週間の間にウェイトリストにいる100万の人に開放していくということがあります。
一体何人の人が待っているのかわかりませんが、ある程度早く使えるようになっていそうですので、興味を持った方は登録してみると良いかと思います。
では、DALL-Eのベータ版について見ていきたいと思います。
実際の画像を見たい方はもう少し先に進んでいただいても結構です!
『DALL-E』ベータ版について
では、以下の公式アナウンスに基づいて、ベータ版がどういうものか説明していきたいと思います。
『DALL·E Now Available in Beta』
ベータ版でできること
ベータ版では以下ができます。
Generate:画像の生成
テキスト情報を英語で入力することで画像を生成することができます。
1回につき4枚の画像が生成されます。
これらは自分のPCにダウンロードすることもできますし、DALL-Eのプラットフォーム上に保存することもできます。
Edit:画像の編集
生成した画像を選択、または自分の持っている画像をアップロードし、その画像の一部分を消しゴムのようなもので消し、文章を入力することで、その消した部分だけを編集した新たな画像を生成することができます。
1回につき3枚の画像が生成されます。
Variations:新たな画像の生成
生成した画像を選択、または自分の持っている画像をアップロードし、それと同じコンセプトの違うバリエーションの画像が生成されます。
1回につき3枚の新たな画像が生成されます。
My Collection:保存
前述の通り、DALL-Eのプラットフォーム上に生成された画像を保存することができます。
わざわざPCにダウンロードして保存する必要がないので、非常に便利です。
My Collectionに保存しなくても、ある程度履歴は見れますが、保存しておかないと古い画像は見れなくなるので注意が必要です。
料金体系
初月は50回の生成(50クレジット)まで無料となっています。
通常の画像生成では4つの画像が生成され、EditやVariationsでは3つの画像が生成されます。
ですので、通常の生成だけだと200枚生成することができます。
翌月以降は15回の生成(15クレジット)まで無料になっています。
それ以上に画像を生成したいという場合は、15ドルで115回分(115クレジット)を追加で購入することができます。
商用利用について
DALL-Eは転載、販売、商品化など全面的に商用利用が許可されています。
公式アナウンスに記載されている利用例には、子ども向けの本のイラスト作成、刊行物の絵の作成、ゲームのキャラクターの作成などがあります。
このあたりは念のため、直接サイトをご確認いただければと思います。
安全性への配慮
DALL-Eでは、良くない使い方や差別などを避けるために、それらを制御する仕組みが搭載されています。
意識的な差別はもちろんいけませんが、近年では無意識で行ってしまっている思い込みや偏見により、一部の人を人を傷つけたり、それが大きな問題になったりしていますので、これらは非常に重要な仕組みですね。
誤用の排除
有名な人物の顔などは表示されないようになっています。(過去の偉人は大丈夫かもしれません)
ディープフェイクのように勝手に有名人の顔を使って画像を生成するといったことはできないようになっています。
例えば以下は「シカゴ・ブルズのユニフォームを着たマイケル・ジョーダンがサッカーをしている写真」として生成された画像です。
顔は描かれていませんね。

有害な画像の排除
暴力的な画像、性的な画像、政治的な画像は生成されないようになっています。
これらの画像は学習用データからも排除されています。
バイアスの抑制
CEOの画像を生成しようとすると、必ず白人男性が表示されるというようなバイアスを抑制しています。
こちらがCEOの例です。色々な性別や人種の人が生成されるようになっています。

詳細はこちらをご参照ください。
『Reducing Bias and Improving Safety in DALL·E 2』
生成された画像のモニタリング
OpenAIは生成された画像を自動および手動により、不適切な画像が生成されていないかモニタリングしているそうです。
アーティストへの助成
申請して認可されることにより、お金を支払うことができないアーティストが無料で利用することができます。
こちらのフォームから申請することができます。

DALL-Eで生成
さて前置きが長くなりましたが、実際に画像を生成して、どんなことができるか見ていきましょう。
画像の生成
では、まずは“ギターを弾くクマのぬいぐるみの画像”で生成してみましょう。
英語で入力する必要があるので、以下のように入力します。
Image of a teddy bear playing the guitar.

そして「Generate」ボタンを押すと、少し時間がかかって、以下の画像が生成されました。

ちゃんとギターを弾いたクマのぬいぐるみの写真が出来ましたね。
では、次にもう少し詳細な説明を追加してみましょう。
“ギターを弾いているプログラミング好きの赤い毛をしたクマのデジタルアート”と入力して、画像を生成します。
Image of a teddy red-haired bear who loves programming to play the guitar, digital art
以下のような赤い毛のクマのぬいぐるみの画像が生成されました。

“プログラミング好き”というのはなかなか絵で表現をするのが難しいでうが、ところどころコンピュータらしきものも見えますね。
続いて、さらにクマの色を青色にして、ギターの色を指定してみます。
Image of a teddy blue-haired bear who loves programming to play the red guitar, digital art (プログラミング好きの青い毛をした赤いギターを弾いているクマのデジタルアート)

いい感じで生成できてますね。
左から2番目の画像が可愛いので、あとでも使っていきたいと思います。
では、ここからどんどん生成していきます。
Photo of two bears on a balloon.(気球に乗った2匹のクマの写真)

バリエーションも豊富ですね。
細部については、ところどころ上手く描けていない部分があります。
続いて、以下を試してみます。
An art of animal rock bands playing an instrument at the show. (コンサートで楽器を演奏している動物のロックバンドの絵)

何かアートですね。少なくとも私には書けません(笑)
もちろん普通の風景も生成できます。
photo of beautiful countryside landscape surrounded by mountains. (山に囲まれた美しい田舎の写真)

photoではなくartにするとアートになります。
art of beautiful countryside landscape surrounded by mountains. (山に囲まれた美しい田舎の絵)

結構いい感じの絵になってますね!
子ども向けの絵でも部屋に飾りたいと思ったときには、以下のようにすれば生成できます。
Pop pictures for kids playing dogs. (子供向けの犬が遊んでいる絵)

好みはあると思いますので、イメージと違えば再度生成することができます。
ピカソ風の犬の絵が欲しい人はこんな感じです。
Picasso-style painting with a dog playing. (ピカソ風の犬が遊んでいる絵)

絵に詳しくないのですが、これはピカソ風なのですかね?
といった感じで、好きなように生成できます。
OpenAIが作った画像はもっと想像力に富んでいるものがたくさんありますので、是非waitlistに登録して、眺めてみてください。
画像の編集
では、続いて画像の編集をしてみたいと思っています。
さきほど作成した“赤いギターを弾いている青いクマ”の画像を編集します。

このクマにメガネを掛けさせたいと思います。
目の部分を消しゴムでけして、文章に“メガネをかけた”を追加します。
Image of a teddy blue-haired bear wearing glasses who loves programming to play the red guitar, digital art

すると、このようにサングラスやメガネをかけたクマになりました!!

次に、こちらも先ほど生成した”気球に乗った2匹のクマ”を編集していきます。

気球の部分を消しゴムで消して、サッカーボールにしてみたいと思います。
Photo of two bears on a balloon like a soccer ball. (サッカーボールのような気球に乗っているクマの写真)

すると以下のようなサッカーボール型の気球になりました。

クマが2匹追加されているのが気になりますが...
他にも自分の持っている画像を編集することもできます。
昔のキャンプで取った浅間山の写真を使ってみます。

浅間山にゴジラを出現させてみたいとします。
”巨大なゴジラを発見した!”として見ます。
I found huge Godzilla!
この消したところにゴジラが出現して欲しいと思っています。

すると、ちゃんとゴジラが出現しました!

もう少し大きいのをイメージしていましたが、、一応ゴジラらしきものが出てきました。
何度かゴジラが出てこないケースがあったので、テキスト情報が悪いのか、うまくいかない場合もあります。
他の画像の生成
次に、一つの気に入った画像などから、同じコンセプトの画像を生成する機能を使ってみましょう。
とりあえず、以下のような画像を生成してみます。
A picture of a frog king studying at a cafe. (カフェで勉強をしているカエルの王様の絵)

ここから、右から2番目の絵を選び、「Variations」ボタンを押します。
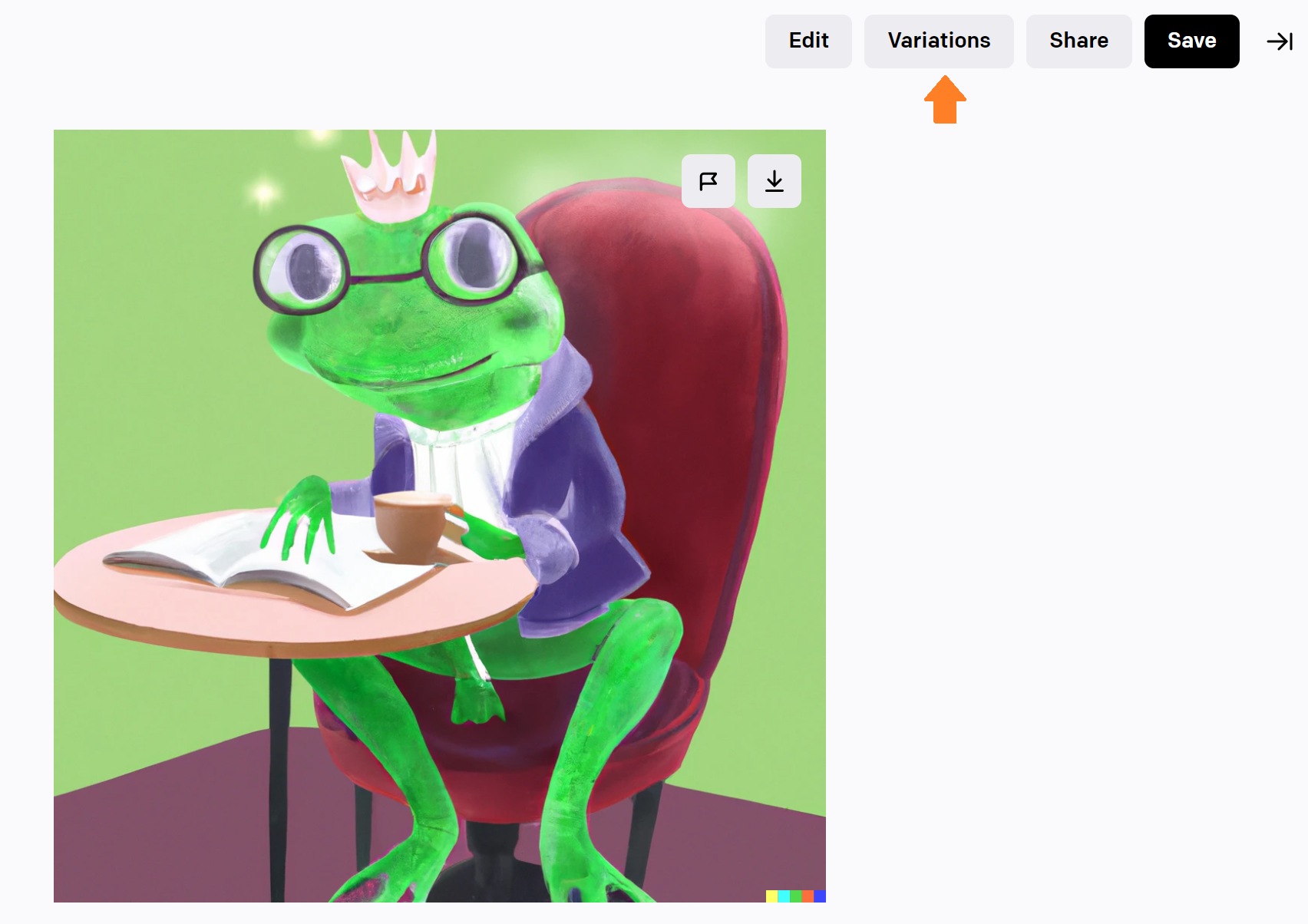
すると、似たようなコンセプトの他の絵が生成されました。

この機能を使えば、気に入っている絵などを使って、自分だけのオリジナルの絵を作ることができますね!
印刷して部屋に飾ることもできます。
オリジナルのドラクエ画像を生成
では、最後にドラクエ好きとしては、オリジナルのドラクエのイラストを作りたいので、キングスライムを生成して締めくくりましょう!
キングスライムというのは、ドラクエで人気のこのようなモンスターです。
いつも笑っていて可愛いと思うのですが、怒ったキングスライムはどんなのになるか試してみたいと思います。

こちらで生成します。
Angry king slime painting. (怒っているキングスライムの絵)
生成された画像を見てみましょう。

誰やねん、こいつ…
やはり、元のキングスライムの形は残しておいた方がよさそうです。
ということで、顔の部分だけを消しゴムで消して、同じテキストを入力してみます。

すると、以下のような画像が生成されました!

可愛くはないですが、怒っていて悪そうではあります。
顔全体を消して生成してみましょう。

何か可愛らしいのが出来ました…

とまぁ、こんな感じで色々遊べて楽しいです。
新機能の追加 - 画像の拡張機能
2022年9月に新しく「もともとある画像を拡張する機能」が追加されました。
例えば、以下の画像は“A bear studying at a cafe-like campsite(カフェのようなキャンプ場で勉強するクマ)”で生成した画像です。

それをもう少し横長の画像にしたいとします。
その場合、以下のように拡張する範囲を選んで、再度生成します。

するとその部分が埋められる形で画像が生成されます。

すごく自然に埋められていますね。
この機能も、通常の画像生成機能と同じように4枚の画像が生成されます。
他にも以下のような画像が生成されました。

また、キャプションで詳細を指定することができます。
上記と同じようにして、キャプションを“A bear studying with many birds in the back at a cafe-like campsite(カフェのようなキャンプ場で後ろにたくさんの鳥と一緒に勉強するクマ)”としてみます。
すると以下のような画像が生成されます。

これは4枚のうち比較的うまくいっている画像ですが、一応後ろに鳥が描かれていますね。
なかなか細かいところを指定して良い画像を得るのは難しいですので、何度か工夫して繰り返す必要があるかもしれません。
まとめ
今回はOpenAIのDALL-E2を使ってみました。
非常に面白くてどんな画像が出来るんだろうとドーパミンが放出されまくりますね。
まだ良い画像、それほど良くない画像がありますし、細かい部分はまだ鮮明でない場合もありますが、恐らくさらに進化していって、すごいクオリティの画像が生成される予感がしました。
気に入った画像を生成することができれば、オリジナルの絵や写真を印刷して部屋に飾ることもできますね。
waitlistに登録されていない方は是非登録して使ってみたください!
では!