今回はOpen Domain Question Answeringの第三弾としてFacebookから提案された『RAG(Retrieval-Augmented Generation)』を紹介したいと思います。
第一弾は『ORQA』、第二弾は『REALM』で第三弾がこの『RAG』です。
RAGは、ReaderにBERTをSeq2Seqの形にしたBART(Bidirectional Auto-Regressive Transformer)を使ったモデルです。
BARTを使うことことで、質問に対して文章を生成して回答することが可能になります。
そして、関連文書の抽出にDPR(Dense Passage Retrieval)という手法を組み合わせることにより、REALMやT5を超えてOpen-DomainのQAタスクやQuestion Generation(質問生成)タスクなどで非常に良好な結果が出ています。
論文はこちらです。
「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」
では、早速見ていきましょう。
目次
RAGとは
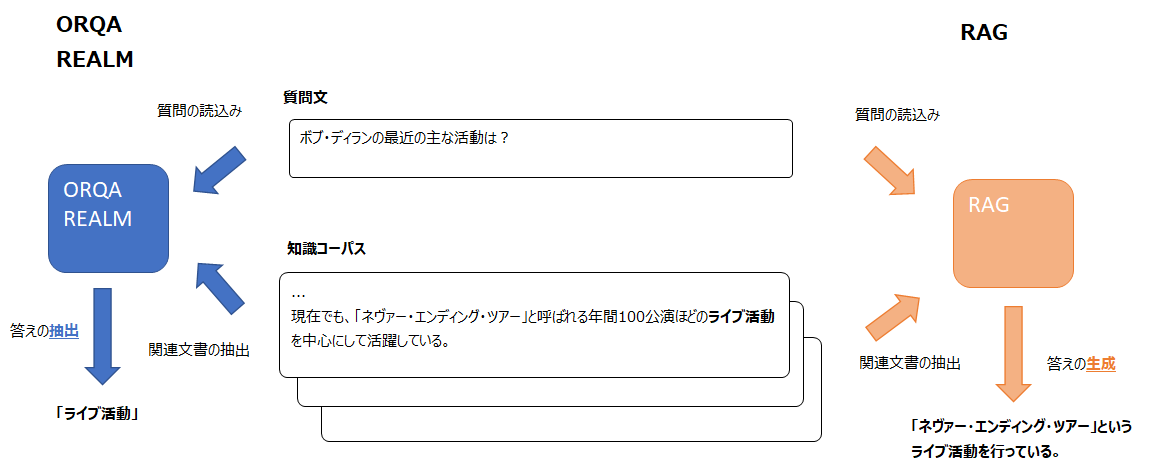
RAGがORQA、REALMと大きく違う点は、ORQAやREALMがエビデンス文書を抽出し、その文書から答えを“抽出する”モデルだったのに対し、RAGは答えを“生成する”ところです。
そのため、答えを予測するモデルにBERTではなくBART(Bidirectional Auto-Regressive Transformer)を採用しています。
BARTはBERTの考えを踏襲しながらも、エンコーダ・デコーダ形式(Sequence-to-Sequence, Seq2Seq)を採用しているモデルです。
これにより、文章生成タスクに対して特に有効になります。
ORQAやREALMでは関連文書から答えとなる単語列を抜き出すことで予測をしていましたが、RAGでは答えとなる文章を生成することが可能になります。
BARTの詳細はこちらをご覧ください。

パラメトリック・メモリとノン・パラメトリック・メモリ
本論文では、事前学習によって得られる知識をそのパラメータの中に知識が埋め込まれることから、パラメトリック・メモリと呼び、適宜知識コーパスを参照して取得する知識をノン・パラメトリック・メモリと呼びます。
ノン・パラメトリック・メモリはWikipediaの記事を使って、それらの記事の埋め込み表現となります。
そして、これらをEnd-to-Endで学習します。
つまり、従来(ORQA以前)のような知識コーパスからの抽出をどの文書を抽出するのが正しいか?というラベルを使って学習し、それとは別に文書から答えを抜き出すタスクを学習する、というような形ではなく、文書の抽出から答えの抜き出しまで一気通貫で学習します(ORQAやREALMと同じです)。
RAGの仕組み
RAGもORQAやREALMと同様に、知識コーパスから文書を抜き出すRetriever、文書から答えを生成するGenerator(ORQAでは答えを抽出するのでReaderと読んでいました)に分けられます。
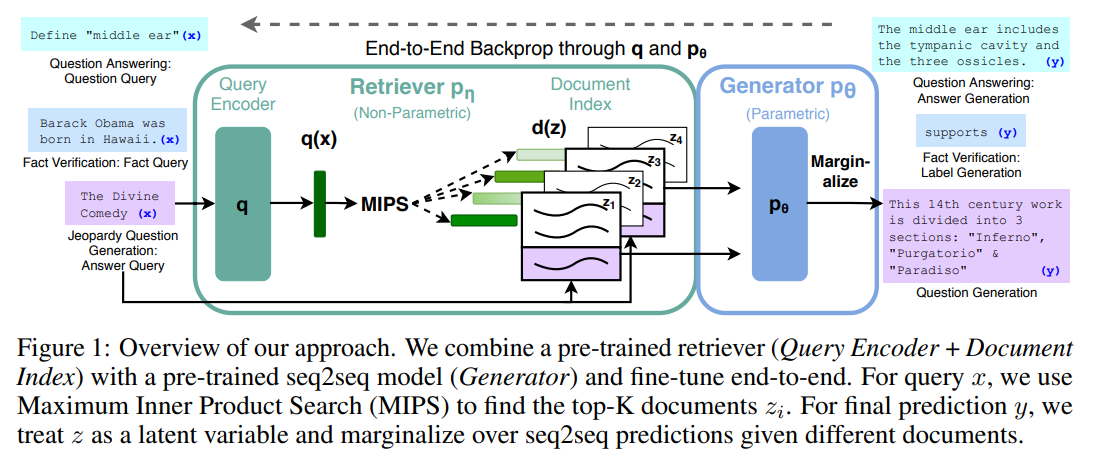
Retrieverがモデル化するのは質問文などのインプット\(x\)から知識コーパス中の文書\(z\)を抜き出すので\(p_\eta(z|x)\)となります。
\(\eta\)はRetrieverのパラメータです。
Generatorは、知識コーパスから抽出した文書\(z\)と元のインプット\(x\)を使って答えを生成します。
RAGでは文章を生成することから、直前までの単語も使い、次の単語を予測します。
したがって、Generatorは\(p_\theta(y_i|x, z, y_{1:i-1})\)をモデル化します。
\(\theta\)はGeneratorのパラメータです。
RAG-SequenceとRAG-Token
RAGでは、回答文の生成に関して、以下の2種類の方法を試します。
- RAG-Sequence
一つの答えを生成するのに1つの文書のみを使います。
まず、知識コーパスから上位\(k\)個の関連性の高い文書を選びます。
そして、文章を生成しますが、1つの文章を生成する際には\(k\)個の各文書\(z_k\)のみを使って生成します。
最後に上位\(k\)個の文書で周辺化することにより\(p(y|x)\)を求めます。
$$\begin{align}
p_\text{Rag-Sequence}(y|x)&\simeq \sum_{z_k\in \text{top-k}(p(\cdot|x)}p_\eta(z_k|x)p_\theta(y|x,z_k)\\
&=\sum_{z\in \text{top-k}(p(\cdot|x)}p_\eta(z_k|x)\prod^N_i p_\theta(y_i|x,z_k,y_{1:i-1})
\end{align}$$ - RAG-Token
一つの答えを生成するのに、単語ごとに複数の文書を見ながら生成します。
$$\begin{align}
p_\text{Rag-Token}(y|x)&\simeq \prod^N_{i=1}\sum_{z_k\in \text{top-k}(p(\cdot|x)}p_\eta(z_k|x)p_\theta(y_i|x,z_i,y_{1:i-1})
\end{align}$$
ポイントはRAG-Sequenceでは\(p_\theta(y_i|x,z_k,y_{1:i-1})\)となっていたところが、\(p_\theta(y_i|x,z_i,y_{1:i-1})\)となっていることです。
つまり、イメージとしては、文書を一つ固定して答えを生成するのではなく、出力する単語ごとに(上位\(k\)個の文書の中から)文書を選ぶというものです。
DPRを使ったRetriever
RetrieverにはDPR(Dense Passage Retrieval)というモデルを使います。
ORQAやREALMではInverse Cloze Task(ICT)という事前学習を行っていましたが、DPRはICTを使わずにRetrieverを学習します。
Inverse Cloze Taskの欠点として、計算負荷がかなり高いこと、その方法自体がどこまで適切かわからないこと、が挙げられています。
そこでDPRはInverse Cloze Taskを用いずに、Question Answeringタスクにおける質問・答えを使って、正例との類似度は高くし、負例との類似度は低くする(metric learning)というシンプルな学習を行います。
正例は、データセット内の各質問に対し、答えが記載されている、かつBM25で評価されたランクが一番高い文書を選びます。
これで、質問と正しいであろうエビデンス文書のペアができます。
そして、負例はバッチ内の正例以外(自分自身のエビデンス文書以外)との組み合わせすべてとします。
きちんと数式で定義すると、バッチサイズを\(m\)とし、\(i\)番目のミニバッチの質問文を\(q_i\)、それに対応する回答が含まれている文章を正例なので\(p_i^+\)、それ以外のミニバッチ内の文章を負例なので\(p_{i, m}^-\)とします。
ミニバッチにあるサンプルは以下のようになります。
\(\{q_i, p_i^+, p_{i, 1}^-, \cdots, p_{i, m}^-\}\)
類似度は以下のようにBERTによる文書の埋め込み表現と質問文の埋め込み表現の内積で計算します。
$$\begin{align}
\text{sim}(q, p)&=q(x)^Tp(z),\\
q(x)&={\bf{BERT}}_q(x),\\
p(z)&={\bf{BERT}}_p(z)
\end{align}$$
そして、\(i\)番目のサンプルの対数尤度を
$$\mathcal{L}(q_i, p_i^+, p_{i, 1}^-, \cdots, p_{i, m}^-)=\log \frac{e^{\text{sim}(q_i,p_i^+)}}{e^{\text{sim}(q_i,p_i^+)}+\sum^m_{j=1}e^{\text{sim}(q_i,p_{i, j}^-)}}$$
とします。
これにより、質問文に対して関連文書の類似度が高くなるように学習することができます。
さらなる詳細についてはこちらの論文をご参照ください。
『Dense Passage Retrieval for Open-Domain Question Answering』
そして、このDPRで学習したエンコーダをRAGのドキュメント・エンコーダの初期値とします。
DPRはTriviaQAとNeural Questionデータセットで学習されています。
Generator BART
generatorにはBARTを使います。
BARTはBERTをSeq2Seqにしたものですので、このタスクでは\(p_\theta(y_i|x, z, y_{1:i-1})\)をモデリングします。
つまり、インプットは入力文\(x\)とエビデンス文書\(z\)、そして直前までの単語\(y_{1:i-1}\)になり、それらをもとに次の単語\(y_i\)を逐次的に予測していきます。
学習
ファインチューニングは、質問文\(x\)と正解文\(y\)のみを使って、End-to-Endで学習します。
どの文書に答えがあるか?というラベル(gold label)は使いません。
直接以下の負の対数周辺尤度を最小化することで学習します。
$$\mathcal{L}=\sum_j -\log p(y_j|x_j)$$
ドキュメント・エンコーダ\(\text{BERT}_d\)のパラメータはファインチューニング時には更新せず、クエリ・エンコーダ\(\text{BERT}_q\)とBARTの生成部分だけを更新します。
デコーダ
\(\arg\max_y p(y|x)\)を求めますが、上記の通りRAG-TokenとRAG-Sequenceの2通りがあります。
RAG-Token
RAG-Tokenは、単語ごとに抽出のための関連文書を変える方法です。
こちらは通常のビームサーチで文章を生成することができます。
$$p'_\theta(y_i|x, y_{1:i-1})=\sum_{z\in \text{top-}k(p(\cdot|x))}p_\eta(z_i|x)p_\theta(y_i|x,z_i,y_{1:i-1})$$
RAG-Sequence
RAG-Sequenceは、関連文書を決めて、そこから文章を生成する方法です。
こちらは少しトリッキーになります。
なぜなら、最初に上位\(k\)個の関連文書を抽出し、各関連文書ごとに文章を生成するからです。
ですので、関連文書にまたがったビームサーチはできません。
そこで、RAG-Sequenceではまず関連文書ごとにビームサーチを行うことで、\(p(y_{i, 1}, \cdots, y_{i, n_i}|x, z_i)\)を求めます。
\(y_{i, j}\)は関連文書\(z_i\)をもとに出力した文章の\(j\)番目の単語を表します。
これらは\(x\)と\(z_i\)を条件とした場合の文章の尤度になりますが、最終的には\(p(y|x)\)という周辺尤度確率が必要です。
そこで、各関連文書に対して、追加で\(y\)という文章を生成し、\(p_\eta(z|x)\)を掛けて和を取ることで周辺尤度を計算します。
これを“Thorough Decoding”と呼びます。
各文書に対して\(y\)と言う文章が出力されなかった場合は\(p(y|x, z_i)=0\)と近似することも可能です。
これを“Fast Decoding”と呼びます。
実験
ノン・パラメトリック・メモリには英語のWikipediaの2018年12月末のデータを使います。
このWikipediaの記事を100単語ずつのチャンクに分け、合計2100万文書にします。
抽出する文書数\(k\)については5もしくは10を使います。
Open-Domain Question Answeringタスク
Open-domainのQAタスクには、Natural Questions(NQ)、TriviaQA(TQA)、WebQuestions(WQ)、CuratedTrec(CT)を使います。
Retrieverについては、Natural QuestionsとTriviaQAで学習したDPRモデルのパラメータを初期値として、再度学習します。
では、結果を見ていきましょう。
Open-DomainのモデルであるREALMとDPR、Closed-Domainベース(ノン・パラメトリック・メモリは使用せず、すべてパラメータに知識を詰め込む)T5と比較します。
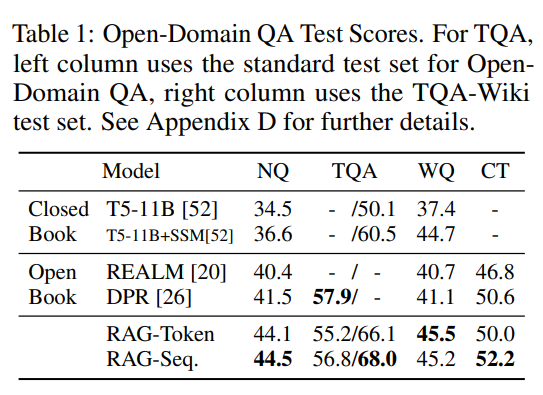
T5よりも大きく上回っており、REALMも上回っています。
DPRについては、TQA以外のデータセットでは上回っています。
RAGでは文章から答えを抜き出すのではなく生成するので、関連文書に完全に一致する答えがなかった場合でも、うまく生成できるようです。
関連文書に答えがない場合、他の抽出型のモデルでは当然精度は0%になりますが、RAGでは11.8%の精度だったとのことです。
Abstractive Question Answering
MSMARCO NLG tasks v2.1というデータセットを使います。
MSMARCOデータセットは、単に答えを抽出するタイプのタスクではなく、自由形式の答えを生成するタスクです。
MSMARCOには、10個の答えに関連する文書があらかじめ与えられていますが、ここではそれを利用せず、直接自分で探しにいきます。
結果は以下のようになっています。
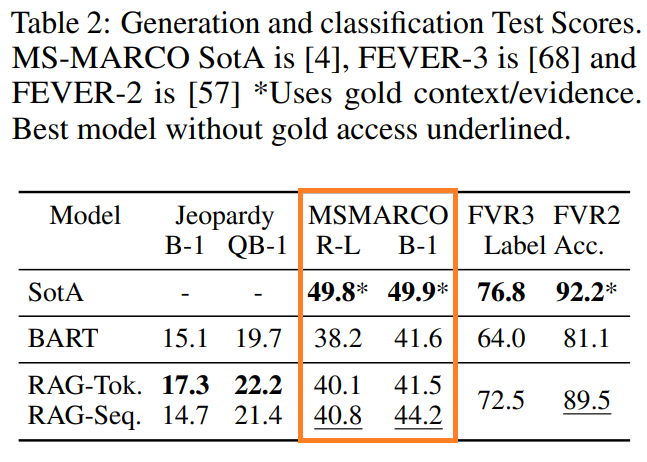
真ん中のMSMARCOの欄ですが、左側がRouge-Lスコア、右がBleuスコアです。
SoTAには5%-9%程度及びませんが、BARTよりは改善しています。
SoTAは答えに関連する10個の文書(gold passage)を与えたうえで解いていますが、RAGは自分でWikipediaから記事を抽出しており、その差が出ているようです。
特に答えがWikipediaには載っていないこともあるので、かなりハンデが大きくなっています。
こちらは、BARTにより生成された回答と、RAGにより生成された回答です。
“?”がついているのは間違った答えです。

例えば、“中耳を定義しなさい”という文では、BARTだと“中耳とは、中耳と鼻の間の部分”と良くわからない事実とは違う回答をしていますが、RAG-Tokenでは、“中耳は耳の鼓膜の奥の部分“、RAG-Sequenceでは、“中耳には鼓室と3つの耳小骨が含まれます”(難しいのでGoogle翻訳)とうまく正しく生成しています。
Jeopardy Question Generation
Jeopardy Question Generationタスクは、答えに合う質問文を答えるタスクです(昔のアメリカのクイズ番組Jeopardy!から来ています)。
例えば、“ワールドカップ”が答えとして与えられると、“1986年にメキシコで初めて2回目の開催となった国際的スポーツの競技大会”という質問文を生成します。
ここでは、SearchQAという検索エンジンの結果を集めたデータセットを使い、10万サンプルを学習データに、1万4千サンプルを検証データに、2万7千サンプルをテストデータにします。
評価方法は、BLUEスコアとQ-BLUEスコアというBLUEスコアを少し改良したものを使います。
BARTとの比較結果がこちらです。
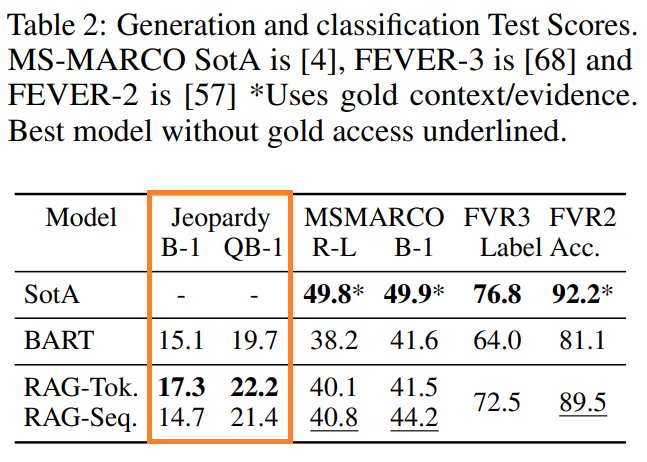
RAG-TokenについてはBARTよりも精度が2ポイントほど改善しています。
さらに、人間の目も入れて検証を行います。
FactualityとSpecificityという項目について、良い方を選んでもらうか、どちらも良い、どちらもダメ、を選択してもらいます。
Factualityは正しく関連文書から事実を抜き出し捉えているかということで、Specificityは質問と回答がきちんと関連しているかということです。
では、こちらが評価結果です。
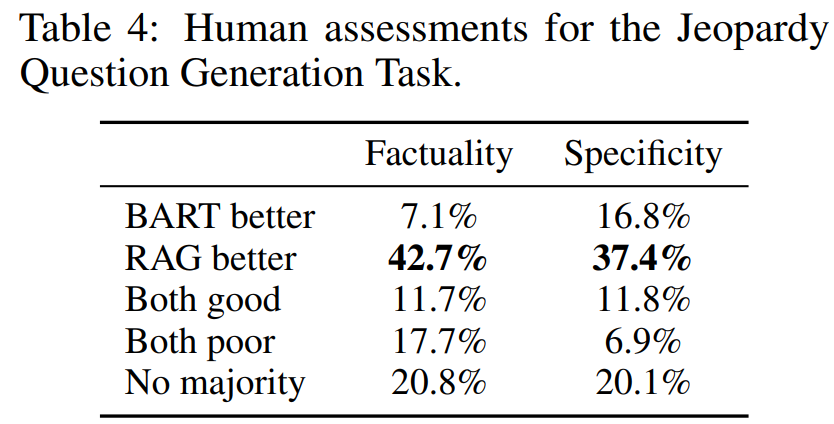
BARTの方が良いという割合はFactuality、Specificityそれぞれ7.1%、16.8%なのに対し、RAGの方が良いという割合は42.7%、37.4%と非常に多くなっています。
人の目で見るというのはコストがかかりますが、一番妥当な評価をすると思いますので、やはりBARTよりも優れていると考えられますね。
では次に、RAGが生成した文章を見てみましょう。

まず一つ目では“Washington”という答えに対して質問を生成しています。
RAG-Tokenでは、以下の通り
It’s the only U.S. state named for a U.S. president. (USの大統領の名前がついている唯一の州です)
という質問が生成されています。
RAG-Sequenceでは、
It’s the state where you’ll find Mount Rainier National Park. (レーニア山国立公園がある州です)
という質問が生成されています。
素晴らしいですね。
ところで、RAG-SequenceよりもRAG-Tokenの方が精度が良いという結果になりましたが、その差が出てくる要因を見てみましょう。
RAG-Tokenは単語ごとに参照する文書を変えるものです。
“ヘミングウェイ”を答えとなるような質問文を生成している例で、RAGは以下のような文章を生成します。
"The Sun Also Rises" is a novel by this author of "A Farewell to Arms".
ここで、“The Sun Also Rises(日はまた昇る)"はドキュメント2に記載されており、“A Farewell to Arms(武器よさらば)”はドキュメント1に記載されています。
“The Sun Also Rises”を生成する際はドキュメント2を参照し(事後確率\(p(z_2|x, y_i, y_{-i}\))が高い)、“A Farewell to Arms”を生成する際はドキュメント2を参照しています(事後確率(\p(z_1|x, y_i, y_{-i}\))が高い)。

このようにRAG-Tokenでは複数の文書から組み合わせて文章を生成することができるようです。
そして、“The Sun Also Rises(日はまた昇る)"はBARTからも生成されることから、外部知識ではなく内部パラメータにも情報が入っているようです。
ですので、RAG-Tokenでは、パラメトリック・メモリとノン・パラメトリック・メモリの両方を組み合わせて文章を生成することも可能です。
非常に面白い結果ですね。
Fact Verification
ここでは、主張がWikipediaの記事に載っていて正しいか、間違っているか、もしくは記載されていないか、を答えるFEVERというタスクを行います。
このデータセットには主張対してWikipediaの特定の記事が与えられ、それを読むことで上記の3つから答えを選びます。
RAGでは、特定されたWikipediaの記事は使用せず、自分で選んできます。
結果は以下の通りです。
左のFVR3が「正しい」、「正しくない」、「記載なし」の3値分類の場合、右が「正しい」、「正しくない」の2値分類の場合です。
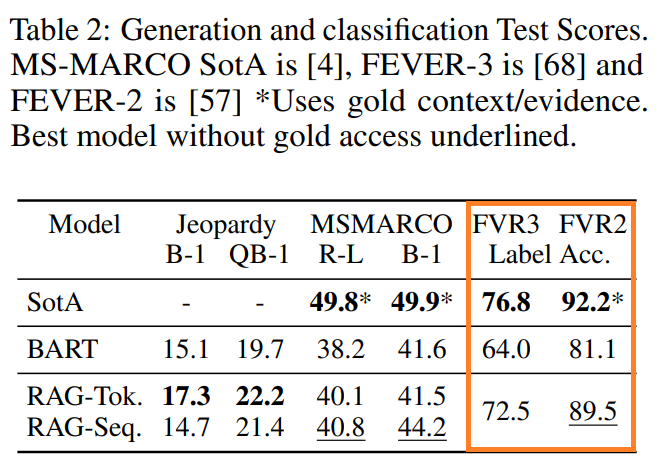
どちらもSoTAには数ポイント及びませんが、RAGは答えが載っているWikipediaの記事が特定されていない状態で答えているというハンデがあります。
RAGがデータセットで指定されている関連記事を選択できているか確認したところ、上位\(k\)個の抽出した文書うち、1番上位の文書になっている場合が71%、上位10文書に入っている場合が90%となっていたとのことです。
かなりの精度で適切な文書を選び出せていますね。
人間のレベルまでは来ていないのかもしれませんが、実務で使うとなっても、かなりの時間の節約になりそうです。
追加分析
論文ではいくつか追加で分析していますが、ここでは面白いと思ったものを一つだけご紹介しておきます。
Index Hot-Swapping
RAGがBARTよりも優れているという内容の結果はいくつか出てきましたが、一つの大きな利点として“知識コーパスをアップデートすることで、モデルをアップデートすることなく知識をアップデートできる”ということです。
BARTなどでは、内部パラメータに情報が詰まっているため、新しい知識を得ようとすると再度学習しないといけません。
RAGでは、適宜外部コーパスから必要な情報を取得し、そこから答えを見つけるため、再度学習しなくても外部コーパスをアップデートすることにより、新たな知識を使うことが可能です。
ここでの実験として、2016年断面のWikipediaを使ってインデックス(埋め込み表現)を作成し、2018年断面の新しいWikipediaを使った場合と比較します。
そして、2016年から2018年に変わった国のリーダーについて、例えば、“ペルーの大統領は誰ですか?”のような形で質問をします。
結果は2016年のインデックスを使って2016年時点のリーダーを質問した場合の精度が70%、2018年のリーダーについて質問をした場合でも68%という精度になっています。
つまり、2016年とほぼ同水準の精度で2018年の新しい情報を使って回答できています。
当然、BARTなどのモデルでは再度学習をしないと回答できません。
まとめ
今回はOpen-DomainのQAモデル『RAG』を解説しました。
GLUEベンチマークの結果だけでなく、こういった応用は非常に面白いですね。
他にも「Additional Results」として分析結果が載っていますので、ご興味のある方は読んでいただければと思います。
ではまた!