さて前回は Instance Normalization (インスタンス正規化)を見ていきましたが、今回は2018年に提案され画像認識などの分野で非常によく使われている Group Normalization を見ていきたいと思います。
今まで見てきた正規化手法の一覧
Batch Normalization
『Batch Normalizationを理解する』
Layer Normalization
『Layer Normalization(レイヤ正規化)を理解する』
Group Normalization
Instance Normalization(インスタンス正規化)を理解する』
手法自体は非常にシンプルですが、今回もまた背景や考え方を中心に解説していきたいと思います。
原論文はこちらです。
ではさっそく見ていきましょう。
目次
Group Normalizationの背景
Deep Learning の学習を効率化し、この分野の発展に大きく寄与した Batch Normalization (バッチ正規化)です。
Batch Normalization は、各レイヤへの入力をミニバッチ中の平均・分散を計算して正規化することで学習を効率化させるというものです。
(Batch Normalization がよくわからないという方は、以下の記事で詳しく解説していますのでご参照ください)

非常に多くのモデルで利用されてきたBatch Normalizationですが、いくつか欠点も浮かび上がってきました。
その中のもっとも大きな一つは“バッチ数が小さいと平均・分散の推定が不安定になり、学習が非効率になってしまう”という点です。
特に最近の潮流として、巨大なモデルで巨大なデータセットを学習し精度を高めるというものがありますが、モデルが大きくなるせいで学習時にたくさんのサンプルをメモリに割り当てられず、バッチ数を小さくして対応することが多くなっています。
今までのようにバッチ数を64や128というのはなかなか設定しにくく、8や4ということも多いです。
そのような場合、Batch Normalization だと学習が不安定もしくは非効率になる傾向があるので、Group Normalization ではそれを改善しようというものです。
実際に以下の図を見ると、青線の Batch Normalization はバッチ数が小さくなるのに従って誤差率が大きくなっていますが、Group Normalization はバッチ数に依存せず低い誤差率を保っています。
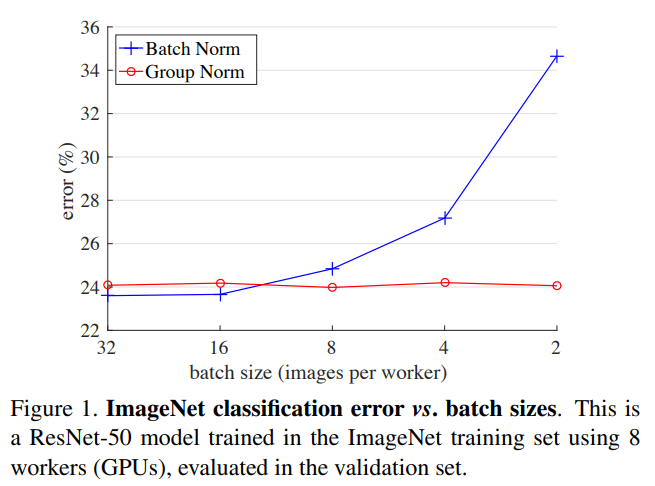
では、どうやってこの問題を解決しているかを次から見ていきましょう。
Group Normalization詳細
既存の正規化手法およびGroup Normalizationの計算方法について、以下の図に沿って説明したいと思います。
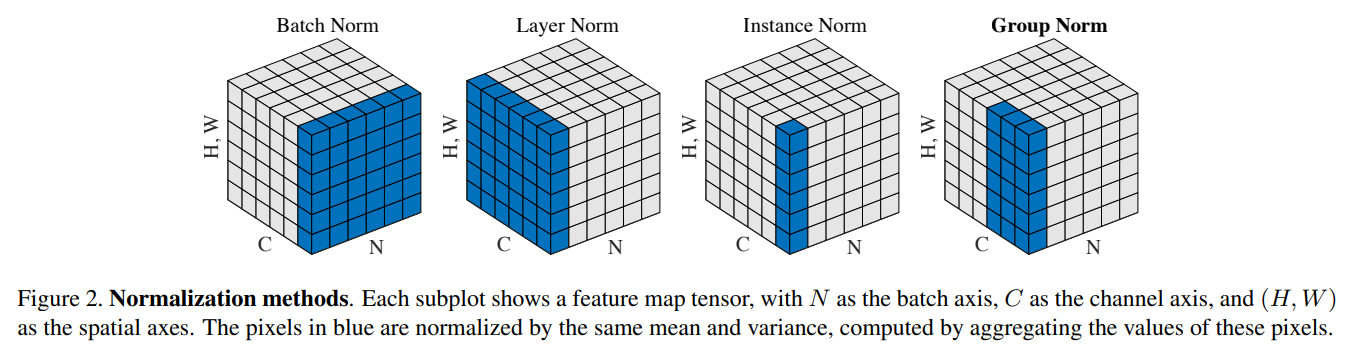
青く塗られているセルが平均・分散を計算する集合を表しています。
まず、Batch Normalization を見てみると、各チャネル\(C\)について、バッチ中のサンプル \(N\)、高さ \(H\)、幅 \(W\) の平均・分散を計算して正規化しています。
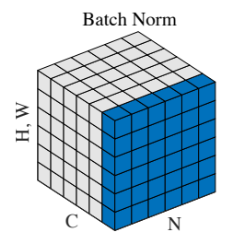
したがって、バッチ中のサンプル \(N\) の数によって学習効率が違ってきてきます。
Batch Normalizationからの発展
上記の問題を克服するには、単純にバッチ中の複数のサンプルを使うのではなく、1つのサンプルだけを使って平均・分散を計算するという方法が考えられます。
Group Normalization はその考え方ですが、実は既に同様の考え方で Layer Normalization、Instance Normalization という手法が提案されています。
Layer Normalization はもともと RNN やなどの時系列モデルで提案されたもので、Instance Normalization は画像の Style Transfer (スタイル変換)のモデルで提案されたものです。
Layer Normalization
Layer Normalization は画像サンプルでいうと、各サンプルについて、高さ \(W\)、幅 \(H\)、チャネル \(C\) の1つの平均・分散を計算します。
以下の図が Layer Normalization の考え方です。
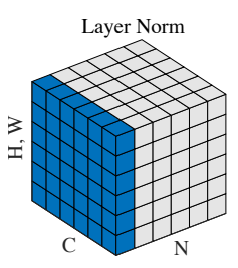
サンプル \(N\) の方向には一つしか使われておらず、高さ \(W\)、幅 \(H\)、チャネル \(C\) はすべて使われていることがわかります。

Instance Normalization
Instance Normalization は各サンプル・チャネルごとに高さ \(W\)、幅 \(H\)の1つの平均・分散を計算します。
以下の図が Instance Normalization の考え方です。
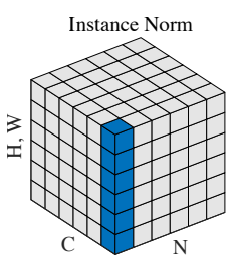
サンプル \(N\) の方向、チャネル \(C\) の方向については一つしか使われておらず、高さ \(W\)、幅 \(H\) についてはすべて使っています。

正規化方法
最後に、計算した平均 (\(\mu_i\))・分散 (\(\sigma^2_i\)) でレイヤへのインプットを正規化する点はすべて同じです。
$$\hat{{\bf{x}}}_i = \frac{{\bf{x}}_i - \mu_i}{\sqrt{\sigma^2_i}+\epsilon}$$
\(\epsilon\) はゼロ割りが発生しないように制御するための微少知です。
そして、\({\bf{y}}_i\) を学習パラメータ \(\gamma_i\)、\(\beta_i\) を使って、平均とスケールをずらします。
$${\bf{y}}_i = \gamma_i \hat{{\bf{x}}}_i + \beta_i$$
この意味や詳細については Batch Normalization の記事で解説していますので、必要に応じてご参照ください。
以上の2つの正規化方法はサンプルごとに違う平均・分散を使うのでバッチの取り方に影響は受けません。
Group Normalization
では、本題の Group Normalization です。
Group Normalization は Layer Normazliation と Instance Normalization の間のような仕組みです。
以下の図のように、チャネルを \(G\) 個の複数のグループに分けて、サンプル、グループごとに1つの平均・分散を計算します。
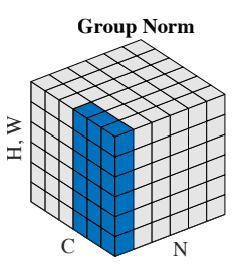
こちらの図では、チャネルを2つのグループに、つまり3つのチャネルを一つのグループとして扱っています。
グループ数を1つにした場合は Layer Normalization に、グループ数をチャネル数と同じにした場合は Instance Normalization になります。
結果として Group Normalization の方が Layer Normalization、Instance Normalization よりも効率的に学習できることになっていますが、その理由を考えてみましょう。
考えられるのは、Layer Normalization は大域的に全体の平均を取っているので、”各チャネルの特徴を捉えることができない”というものです。
一方で、Instance Normalization では、チャネルごとに平均・分散を計算するのでチャネルごとの特徴は捉えられます。
しかしながら、チャネルごとの平均なので“チャネル間の依存関係を捉えられていない”可能性が考えられます。
この中間の Group Normalization では、“グループの特徴を捉え、かつグループ内の依存関係を捉える”ことができると言えます。
実際にグループに分けることの効果はあとで実験結果を見ていきたいと思います。
定式化
では、ここから Batch Normalization、Layer Normalization、Instance Normalization、Group Normalization を一般化して定式化していきたいと思います。
\(i\) はサンプル \(N\)、チャネル \(C\)、高さ \(H\)、幅 \(W\)に対するインデックス \(i_N\)、\(i_C\)、\(i_H\)、\(i_W\) を表すとします。
\begin{align}
\hat{{\bf{x}}}_i=\frac{1}{\sigma_i}({\bf{x}}_i - \mu_i)
\end{align}
平均・分散(標準偏差)は以下の式で求めます。
\begin{align}
\mu_i &= \frac{1}{m}\sum_{k\in \mathcal{S}_i} {\bf{x_k}}, \\
\sigma_i &= \sqrt{\frac{1}{m}\sum_{k\in \mathcal{S}_i}({\bf{x}}_k-\mu_i)^2+\epsilon}
\end{align}
ここで、\(\mathcal{S}_i\) はそれぞれの手法の平均・分散を計算するためのピクセル値の集合を表し、この集合がそれぞれの手法によって異なってきます。
\(m\) はその集合の要素数です。
では各手法を見ていきましょう。
Batch Normalization
まず、Batch Normalization は以下で表されます。
$$\mathcal{S}_i=\{k|k_C=i_C\}$$
集合 \(\mathcal{S}_i\) はチャネルが \(i_C\) のピクセル値すべてになります。
つまり、同じチャネル位置の値を集めたものが平均・分散を計算する集合になります。
逆にいうと、同じチャネルのバッチ中のすべてのサンプル \(N\)、すべての高さ \(H\)、すべての幅 \(W\) がすべて使われます。
(日本語が少しおかしい & わかりにくいかもしれませんが、感覚的に説明していますのでご容赦ください...)
Layer Normalization
Layer Normalization の場合は以下です。
$$\mathcal{S}_i=\{k|k_N=i_N\}$$
そのサンプルの平均・分散の計算は、そのサンプルのみを使います。
つまり、各サンプルで一つの平均・分散が決まり、高さ、幅、チャネルのすべてのピクセル値を使って計算されます。
Instance Normalization
Instance Normalization の場合は以下になります。
$$\mathcal{S}_i=\{k|k_N=i_N, k_C=i_C\}$$
\(i_N\)、\(i_C\) を指定しているので、Batch Normalization と Layer Normalization の両方の軸を設定していることになります。
ですので、この3つの中では一番局所的で、各サンプル、各チャネルごとに、高さ、幅のピクセル値を使って平均・分散を計算します。
Group Normalization
最後に Group Normalization では、次のように表されます。
$$\mathcal{S}_i=\left\{k| k_N=i_N, \lfloor \frac{k_C}{C/G}\rfloor =\lfloor \frac{i_C}{C/G}\rfloor \right\}$$
いきなりややこしくなりましたが、\(\lfloor \cdot\rfloor\) は整数部分を表します。
簡単にいうと、チャネルを \(G\) 個のグループに分割し、\(i\) と同じサンプル、かつ同じグループに入る場所のピクセル値で平均・分散を計算するということです。
実験
ここでの実験では、ImageNet のデータを使って精度等を見ていきます。
モデルの設定はResNetの論文の通りです。
バッチ数は基本的に32を使っています。
詳細については論文をご参照ください。
正規化手法による比較
では、まずBatch Normalization、Layer Normalization、Instance Normalization、Group Normalization を使った場合の誤差率の比較です。
以下の図は、バッチ数を32として、各手法を適用した場合におけるエポック数と誤差率のグラフす。左側が学習データ、右側が検証データの結果になります。
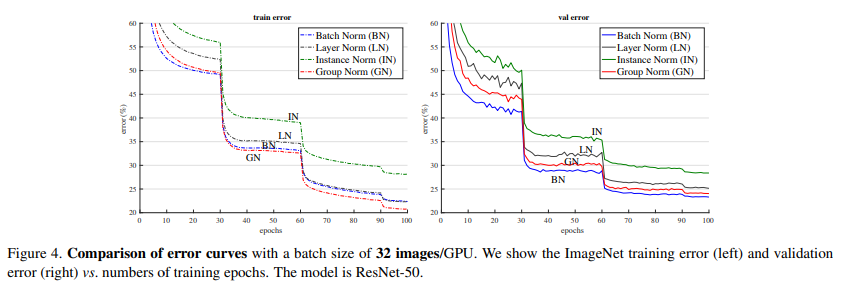
学習データではGroup Normalizationが、検証データではBatch Normalizationが良くなっており、この2つが学習データ、検証データともにLayer Normalization、Instance Normalizationと比べても良くなっています。
以下の表でもわかる通り、検証データでは Batch Normalization が一番良くなっていますが、Group Normalziation はそれと遜色のない結果になっています。
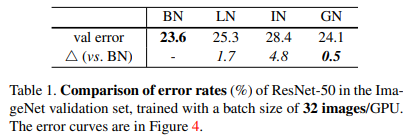
Batch Normalizationとの比較
では次に、Group Normalization の背景にあったバッチ数が少ない場合にどのようになるかを見てみます。
以下の図はバッチ数を変えた場合の Batch Normalization (左側) と Group Normalization (右側) の誤差率の推移です。
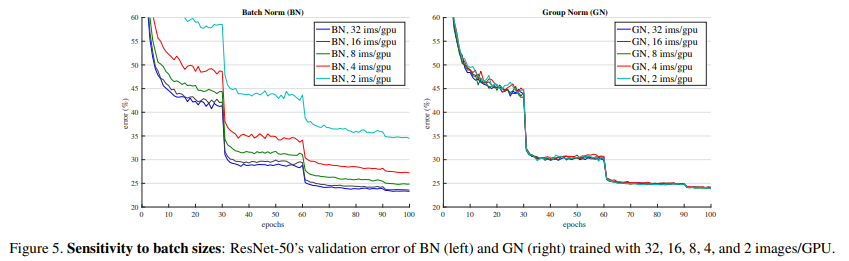
予想通り Batch Normalization はバッチ数が小さくなるほど誤差率が大きくなっていることがわかります。
一方で右側の Group Normalization については、バッチ数に影響を受けないため、どのバッチ数でも同じレベルの誤差率となっています。
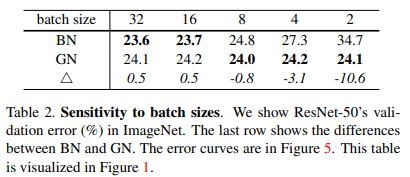
以下の表でわかる通り、バッチ数が16以上であれば誤差率は Batch Normalization の方が小さいですが、それ以下になると Group Normalization の方が低くなっており、バッチ数が2になると差は非常に大きくなっています。
最適なグループ数
では、最後に Group Normalization において、グループ数および1グループあたりのチャネル数による誤差率の違いを見てみましょう。
以下の図の上段がグループ数に1から64を設定した場合で、下段は1グループあたりのチャネル数に1から64を設定した場合の結果です。
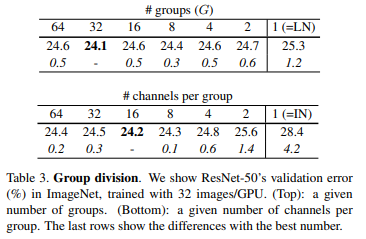
上段を見るとグループ数は32が一番誤差率が低くなっており、下段を見ると1グループあたり16チャネルの場合が一番誤差率が低くなっています。
恐らくモデルやデータなどの条件により変わってくる可能性はありますが、Layer Normalization と Instance Normalization の間に最適な解がある可能性は高そうですね。
まとめ
今回は画像分野で非常によく使われている Group Normalization について詳しく見てきました。
Batch Normalization では推論時に、バッチの取り方により推計結果が変わることを回避するために、学習時の平均・分散を使う(実際には移動平均を利用)をしていましたが、そういった工夫も不要になります。
他にも亜種が存在しますので、おいおいその辺りも取り上げられればと思っています。
では!