以下の投稿では、事前学習-ファインチューニングについて解説しました。この考え方は非常に重要なので一度簡単なモデルを使って実装してみたいと思います。

事前学習-ファインチューニングとは
事前学習とは簡単に言うと、特定のタスクを解くためのモデルを構築する前に、一般的な知識を得ておくということです。自然言語処理では、一般的に2種類の事前学習があります。
- 単語の埋め込み表現について、Word2VecやGloVeといった手法を用いて事前学習された結果を使う。
- 言語モデルを特定のモデルで事前に学習する。
今回は、2つめの言語モデルを特定のモデルで事前に学習することの効果を見ていきたいと考えています。
言語モデルの事前学習は一般的には、Wikipediaコーパスなどの大きなラベルなしデータを使って学習します。そして、一般的な言語モデルを習得したうえで、センチメント分析などの特定のタスクにそのモデルを使って、予測するようにパラメータを調整します。
では、早速実装してみましょう。
実装
事前学習
今回は、以下のような1層のLong Short-Term Memory(LSTM)を使いたいと思います。各時点で次の時点の単語を予測します。
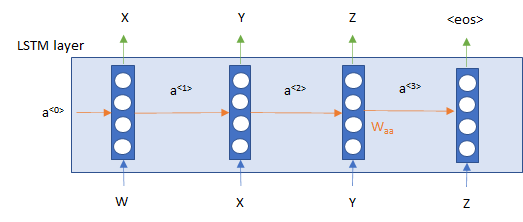
実装は普通のLSTMですが、return_sequences=Trueとすることで、各時点の隠れ層の値も出力するようにします。そして、Denseレイヤーで、ボキャブラリー・サイズの出力をします。
from tensorflow.keras.layers import LSTM, Embedding, Input, Dense, Dropout
from tensorflow.keras.models import Sequential, Model
def lstm_model(vocab_size, emb_dim, seq_length, hidden_dim, dropout_rate=0.0):
x_input = Input(shape=seq_length)
# Embedding layer
emb = Embedding(input_dim=vocab_size, output_dim=emb_dim, mask_zero=True)(x_input)
# LSTM layer
lstm_output = LSTM(hidden_dim, return_sequences=True, dropout=dropout_rate)(emb)
# Dropout layer
lstm_output = Dropout(dropout_rate)(lstm_output)
# Dense Layer: softmax
output = Dense(vocab_size, activation='softmax')(lstm_output)
model = Model(inputs=x_input, outputs=output)
return model
データはこのような形で、ひとつずらすことにより作成しています。
x_pretrain = [x[:-1] for x in x_train] y_pretrain = [x[1:] for x in x_train]
そして、モデルをコンパイルし、学習します。
epochs = 60
batch_size = 32
model = lstm_model(len(tokenizer.index_word)+1, 200, seq_length=MAX_LEN,
hidden_dim=512, dropout_rate=0.3)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
model.fit(x_pretrain_padded, y_pretrain_padded, epochs=epochs, shuffle=True,
batch_size=batch_size)
lossが十分下がったところで、事前学習を終了します。もっと続けても良いかもしれません。
... 865/865 [==============================] - 359s 415ms/step - loss: 0.6193 Epoch 57/60 865/865 [==============================] - 360s 416ms/step - loss: 0.6146 Epoch 58/60 865/865 [==============================] - 360s 416ms/step - loss: 0.6114 Epoch 59/60 865/865 [==============================] - 360s 416ms/step - loss: 0.6078 Epoch 60/60 865/865 [==============================] - 359s 416ms/step - loss: 0.6042
これで事前学習は終了です。
ファインチューニング
では、次はファインチューニングをしたいと思います。
今回はセンチメント分析なので、LSTMの各時点の出力について、次元ごとに平均を取って評価したいと思います。図にすると以下のような形です。
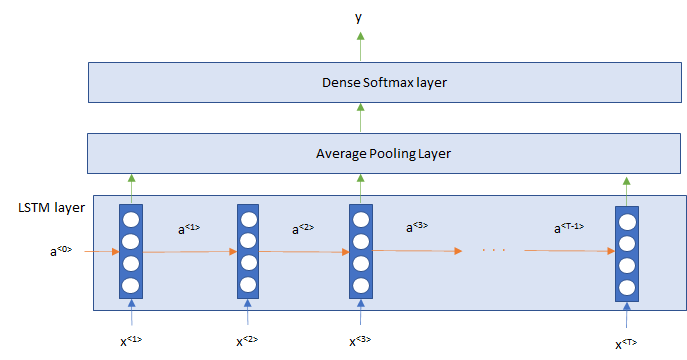
では、こちらがモデルの部分です。
from tensorflow.keras.layers import GlobalAveragePooling1D
def lstm_classification_model(vocab_size, emb_dim, seq_length, hidden_dim, dropout_rate=0.0):
# Input layer
x_input = Input(shape=seq_length)
# Embedding layer
emb = Embedding(input_dim=vocab_size, output_dim=emb_dim, mask_zero=True)(x_input)
# LSTM layer
lstm_output = LSTM(hidden_dim, return_sequences=True, dropout=dropout_rate)(emb)
# Average Pooling layer
output = GlobalAveragePooling1D()(lstm_output)
# Dropout layer
output = Dropout(dropout_rate)(output)
# Dense layer
output = Dense(1, activation='sigmoid')(output)
model = Model(inputs=x_input, outputs=output)
return model
EmbeddingレイヤーとLSTMレイヤーは事前学習で学習したウェイトを初期値として使用し、Denseレイヤーは新しくスクラッチで学習します。
# モデルの生成
pretrained_lstm_classification_model = lstm_classification_model(
vocab_size=len(tokenizer.word_index) + 1, emb_dim=200, seq_length=MAX_LEN,
hidden_dim=512, dropout_rate=0.5)
# embeddingレイヤーとLSTMレイヤーはpretrainingしたウェイトを使う
pretrained_lstm_classification_model.layers[1].set_weights(
model.layers[1].get_weights())
pretrained_lstm_classification_model.layers[2].set_weights(
model.layers[2].get_weights())
# モデルのコンパイル
pretrained_lstm_classification_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics='acc')
あとは、普通に学習させます。実験のためdata_rangeを変化させて、学習に用いるデータ数を変えています。
epochs=20
data_range=200
pretrained_lstm_classification_model.fit(x_train[:data_range],
y_train[:data_range],
epochs=epochs, shuffle=True, validation_data=(x_test, y_test))
結果
学習に使うデータ数を変えて実験しました。
まずは学習データをすべて約30,000サンプルを使った場合です。テストデータの精度は事前学習をしたほうが約2%程度上回っています。
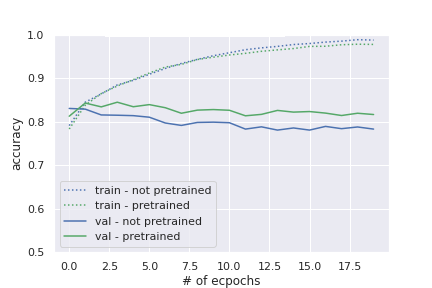
次に、学習データを3,000個に絞った場合です。学習データが少ないのですぐにオーバーフィッティングし、事前学習をしていない方はテストデータの精度が低下していっています。
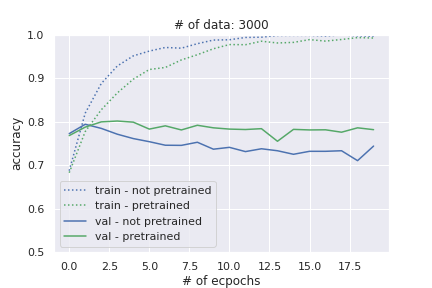
最後に、学習データを1,000個に絞った場合です。こちらも事前学習しなかった方はオーバーフィッティングし、精度が低下していっています。その差は、約6%程度もあります!!
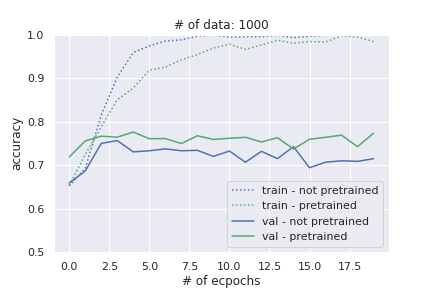
ということで、どのケースでも、テストデータの精度は事前学習した場合の方が高くなっています。また学習データが少ないほど、その差は顕著になっています。
特にデータが少ないと、事前学習なしの場合はすぐにオーバーフィッティングして、精度が悪化していきますが、事前学習をしている方では、ほとんど精度は低下していません。
非常に強力なことがわかりますね。今回は事前学習といっても、高々30,000件ぐらいでの事前学習でしたが、もっと複雑な問題ではより大きなコーパスを使って事前学習を行うと、もっと効果的かもしれません。
ちなみにULMFitというモデルでは、大規模な一般的な言語コーパスで事前学習、タスクのドメインのコーパスでファインチューニング、さらに分類問題など解きたいタスクでファインチューニングとすることでさらに良好な結果を残しています。
まとめ
では、今回は事前学習-ファインチューニングのステップを実際に実装してみて、いかに効果的かがわかりました。
ULMFiTやELMo、Open GPT、BERTなど、2018年に非常に良好な結果を残したモデルはこのステップを踏んでいますので、是非より難しいモデルでも試してみてはいかがでしょうか?
では、今後はULMFitなども試してみたいと思います!