では、今回は分析や星の数を当てるモデルを構築するのではなく、以下で説明したWord2Vecという単語の埋め込み表現(Word Embedding)を作成してみましょう。

手順
Word2Vecによる埋め込み表現を作成するには、Pythonからも使えるパッケージGensimを使うと便利です。
手順としては、まず、MeCabなどを使って単語を分かち書きし、単語のリスト(一文)のリストを作成します。そして、以下のように記述するだけで、作成することができます。
from gensim.models import word2vec w2v = word2vec.Word2Vec(review_list, size=200, window=10, hs=0, min_count=5, sg=1)
引数の意味は、以下です。
- size:埋め込み表現の次元
- window:周りの単語数
- hs:1であれば階層的softmaxという手法を使い、0であればネガティブ・サンプリングを使う。
- min_count:ここで指定した回数以上出現する単語を使用する
- sg:1であればSkipgramモデル、0であればCBOWモデルを使用する
上記の記事でお伝えしたように、Word2VecにはCBOW(Continuous Bag-of-Words)モデルとSkipgramモデルがあり、論文にはデータが多ければ、難しいタスクを解いているSkipgramの方が精度が良くなると記載されています。今回は、どちらでも良いのですが、Skipgramモデルを使用したいと思います。
得られた埋め込み表現を表示するには、以下のようにすることで、「スタッフ」という単語の埋め込み表現が出力されます。200次元なので200個の数字が並ぶベクトルです。
[in] w2v.wv.get_vector('スタッフ')
[out] array([-0.10871489, 0.03330744, -0.13977288, 0.36985087, 0.1458227 ,
-0.16090228, -0.21420392, 0.45256346, -0.38824964, -0.4067191 ,
0.04928603, -0.1577138 , -0.07832763, 0.38792014, 0.12570931, ...
似たような単語を表示させる
では、得られた埋め込み表現と近い単語を見ていきたいと思います。
例えば、「丁寧」という単語だと、類似度が高い順に以下のようになります。楽しいですね!
w2v.wv.most_similar('丁寧', topn=10)
('ていねい', 0.7364639639854431),
('的確', 0.7348081469535828),
('簡潔', 0.7028412818908691),
('適切', 0.69715815782547),
('親切', 0.6884415149688721),
('姉さん', 0.6863903999328613),
('皆様', 0.6858173608779907),
('受け答え', 0.6783715486526489),
('にこやか', 0.6670461893081665),
('親身', 0.6665120124816895)]
「最高」だと以下になります。いいですね、キャンプに行きたくなります(笑)
[in] w2v.wv.most_similar('最高', topn=10)
[out] ('絶好', 0.7122818231582642),
('絶景', 0.7114722728729248),
('抜群', 0.7094724774360657),
('気持ちいい', 0.6915913820266724),
('夕日', 0.6838008165359497),
('ラッキー', 0.6823089122772217),
('格別', 0.68138188123703),
('浜辺', 0.6810903549194336),
('富士山', 0.6782779097557068),
('夕焼け', 0.6760900616645813)]
つまり、「最高」と「絶好」は似ているベクトルということがわかりますが、単語の出現回数やTF-IDFを使った場合だと、まったく別の単語として扱われるのですが、このような埋め込み表現を使うと、似たような単語であるという意味を考慮することができます。
単語の線形関係を見る
もとのThomas Mikolovらによる論文では例として、
$$\text{King} - \text{Man} + \text{Woman} = \text{Queen} $$
となることが示されています。では、今使っているデータセットではどういった関係があるか調べてみましょう。
まずは、「夜」+「空」について見てみました(引き算についてはいいのが思い浮かばなかったので、皆さんはほかにも試してみてください)。「月明かり」、「見上げる」、「天の川」、「幻想」など、キレイですね。
[in] w2v.wv.most_similar(positive=['夜', '空'], negative=[], topn=10)
[out] [('月明かり', 0.8167630434036255),
('見上げる', 0.8019725680351257),
('必見', 0.7924213409423828),
('天の川', 0.7913674116134644),
('上空', 0.7845269441604614),
('曇り空', 0.7844141721725464),
('幻想', 0.7841042280197144),
('満月', 0.7746438980102539),
('拝める', 0.7701787948608398),
('夜空', 0.7698823809623718)]
ほかには、「海」+「風」は「潮風」となっています。ほんと、楽しいですね(笑)
[in] w2v.wv.most_similar(positive=['海', '風'], negative=[], topn=10)
[out] [('潮風', 0.7553023099899292),
('吹き抜ける', 0.7487195730209351),
('海辺', 0.7455430030822754),
('海風', 0.7316983938217163),
('波', 0.7131586074829102),
('強める', 0.7120276093482971),
('爽快', 0.7108045816421509),
('強い', 0.7035248279571533),
('風雨', 0.6937786936759949),
('夕陽', 0.688016414642334)]
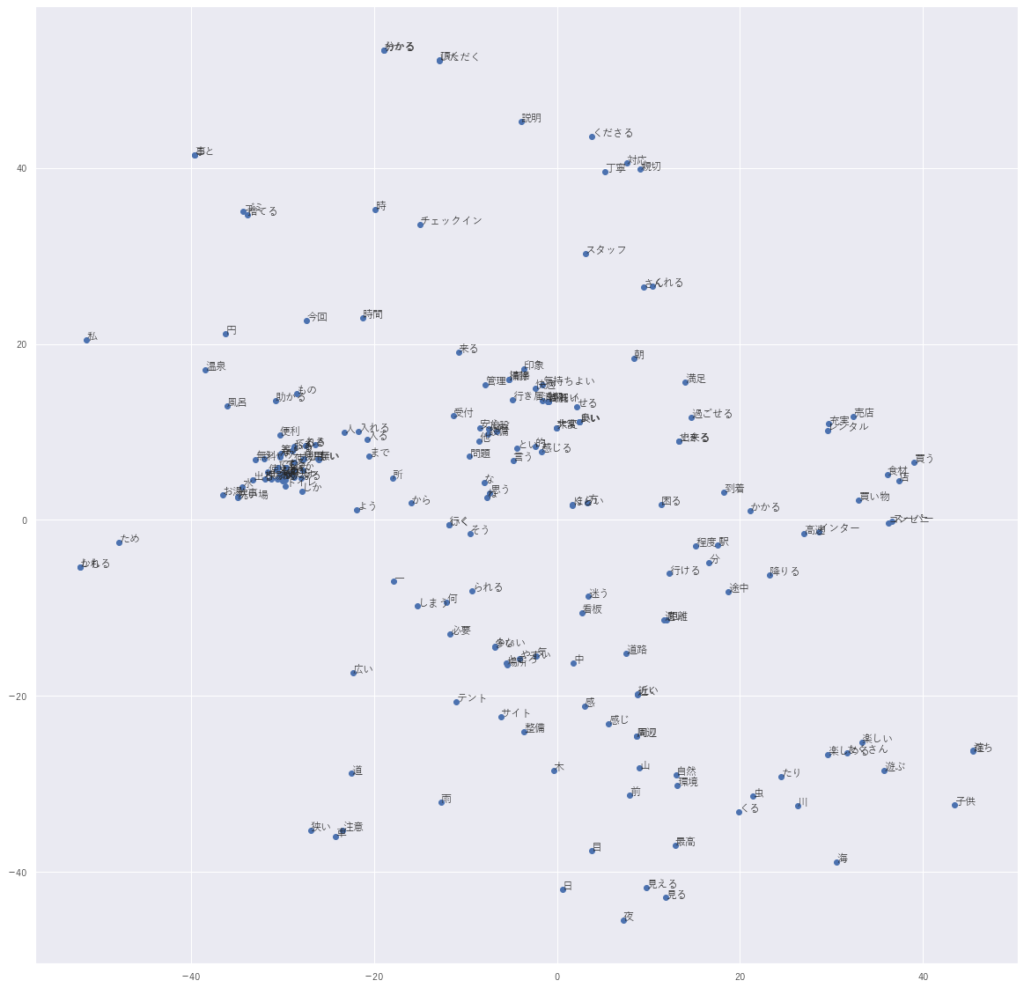
T-SNEで可視化する
では、最後に、T-SNEという非線形の次元圧縮法を使って、単語の分散表現を2次元のマップに落としたいと思います。
まず、scikit-learnのTSNEというクラスを使って、2次元に圧縮します。
from sklearn.manifold import TSNE tsne = TSNE(n_components=2, random_state=0) np.set_printoptions(suppress=True) tsne.fit_transform(vec)
そして、あとは散布図を描いて、点のところに単語をつけてやります。
word_list = w2v.wv.index2word[:plot_count]
plt.figure(figsize=(20,20))#図のサイズ
plt.scatter(tsne.embedding_[:plot_count, 0], tsne.embedding_[:plot_count, 1])
count = 0
for label, x, y in zip(word_list, tsne.embedding_[:, 0], tsne.embedding_[:, 1]):
count +=1
plt.annotate(label, xy=(x, y), xytext=(0, 0), textcoords='offset points')
if(count>=limit):
break
結果はちょっと重なっていてみづらいですが、見やすいところだと、「温泉」と「風呂」が近くにあったり、「丁寧」と「親切」や「対応」といった単語があったりと、同じような文章で使われる単語が近くに集まっていることがわかります。ほかにも細かいところを見ると、色々となるほどーという単語があるかと思います。
まとめ
今回はWord2Vecを使って埋め込み表現を作成し、色々遊んでみました。何となく埋め込み表現が何者かわかっていただけたのではないでしょうか?
もっと詳しく知りたい方は、以下の本が参考になります。こちらは、TensorflowなどのAPIを使わずにPythonだけでスクラッチで作っているので、細かいところまで手を動かして理解することができます。
では、次回はRecurrent Neural Networkを見ていきたいと思います!