前回はplotlyを使ったインタラクティブな線グラフの作成方法について説明しました。

今回は、インタラクティブな散布図(Scatter Plot)を作成する方法について解説したいと思います。
インタラクティブな散布図はかなり使えますので、散布図を使って分析する際はインタラクティブなグラフを使うことをオススメします。
なぜインタラクティブな散布図が良いかというと、以下のようにたくさんのサンプルが合った場合、部分的に拡大したり、詳細をテキストで補足表示することで分析が非常に効率的になり、より深くデータを見ることができるからです。
今回、最終的にできあがる散布図は以下のようなものです。
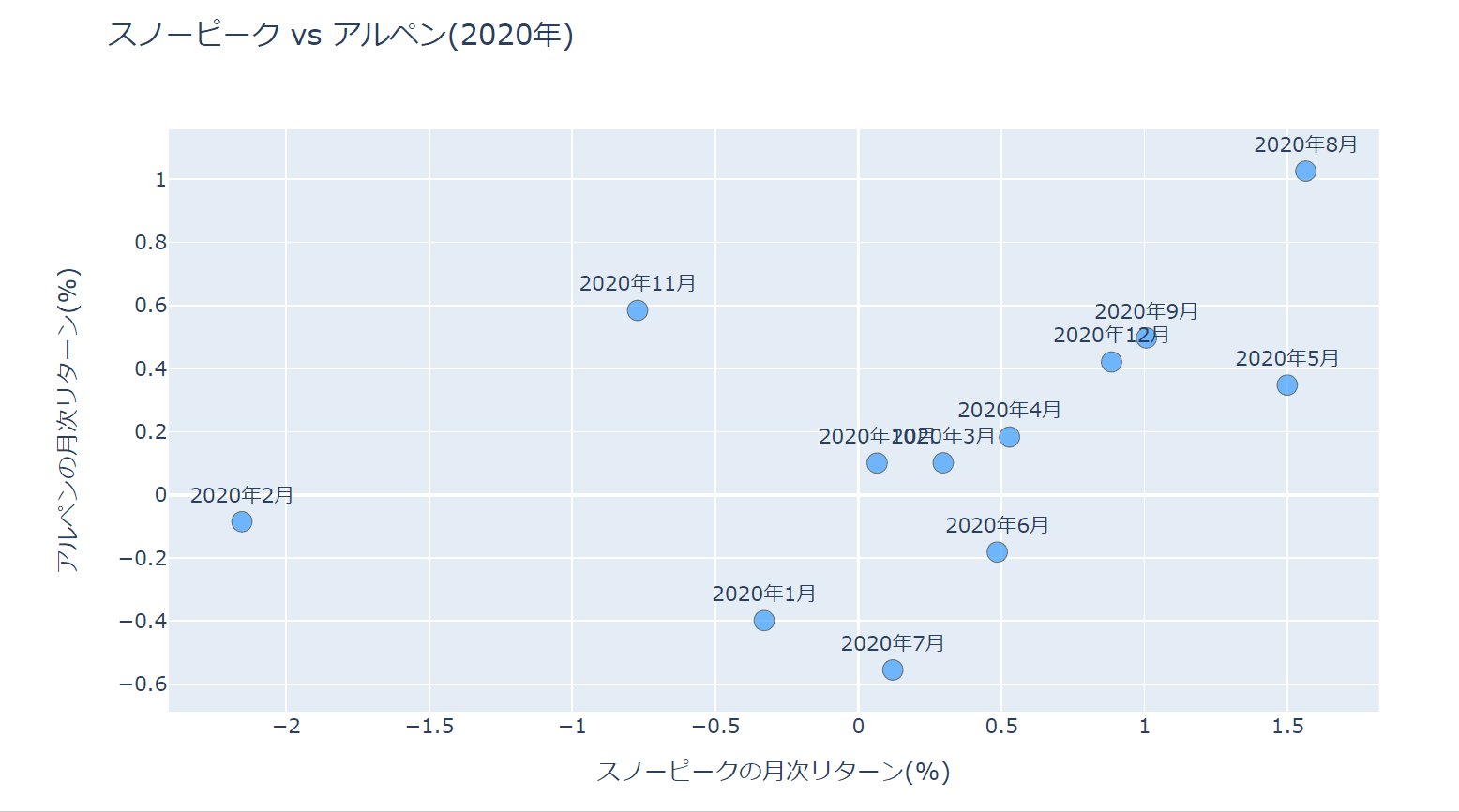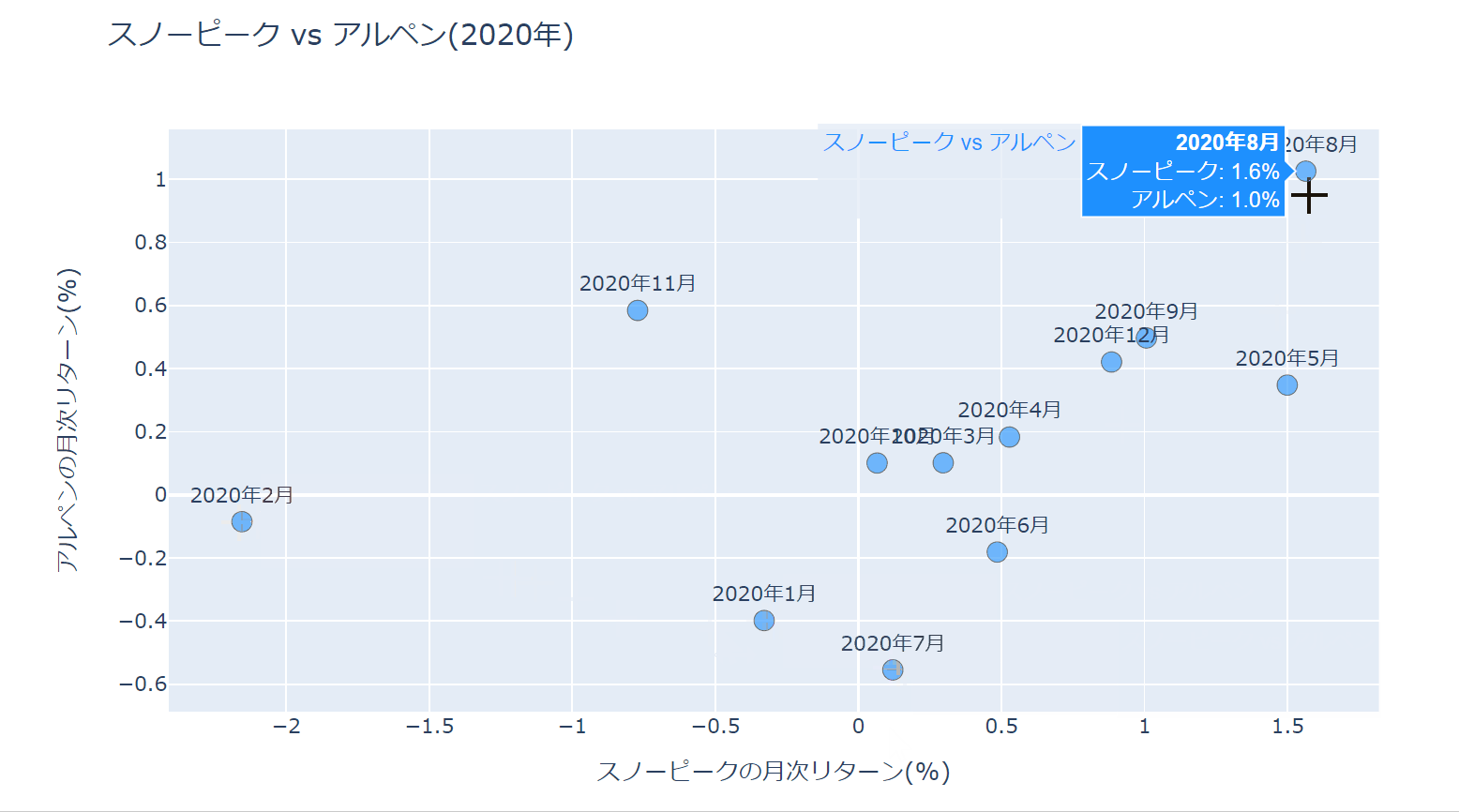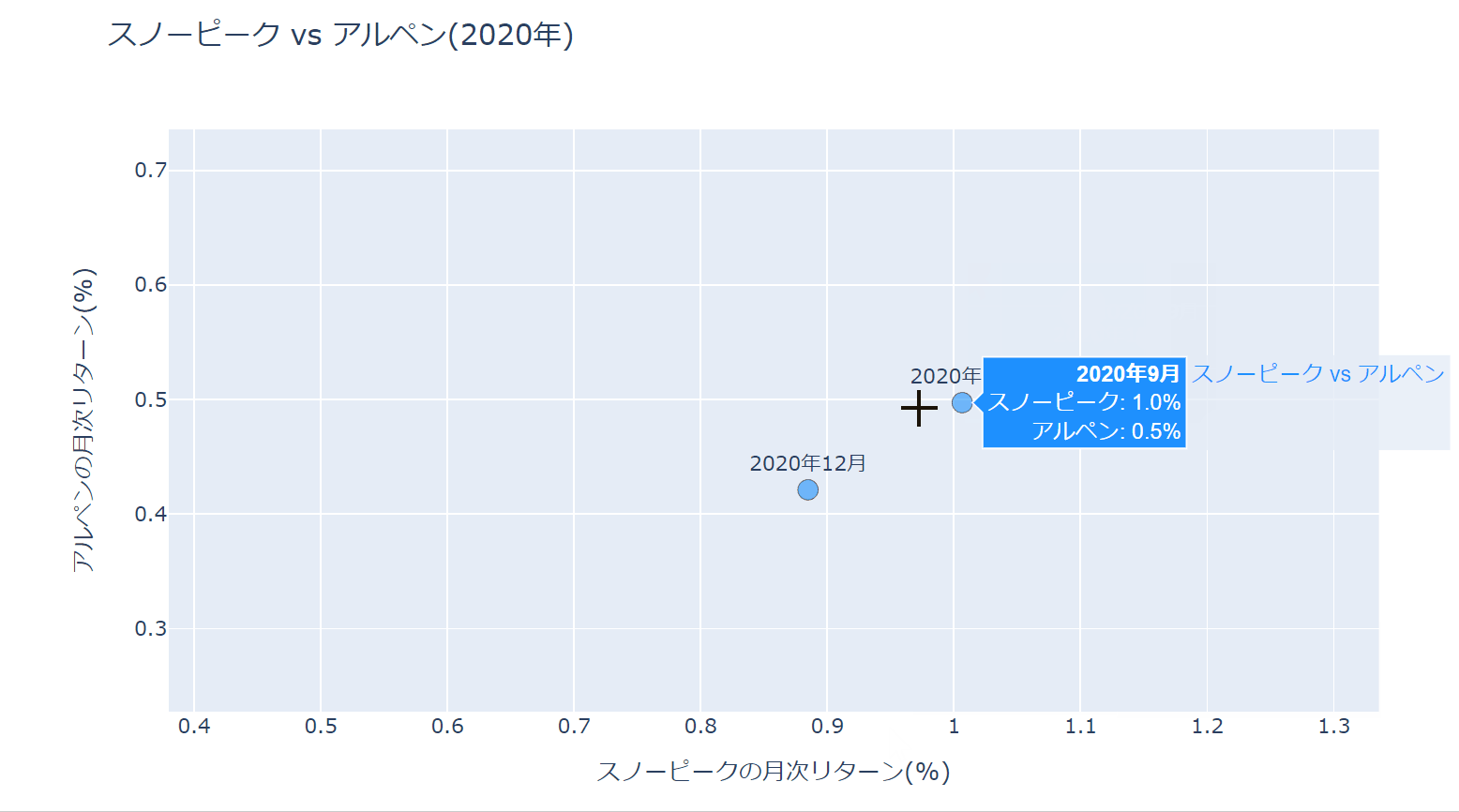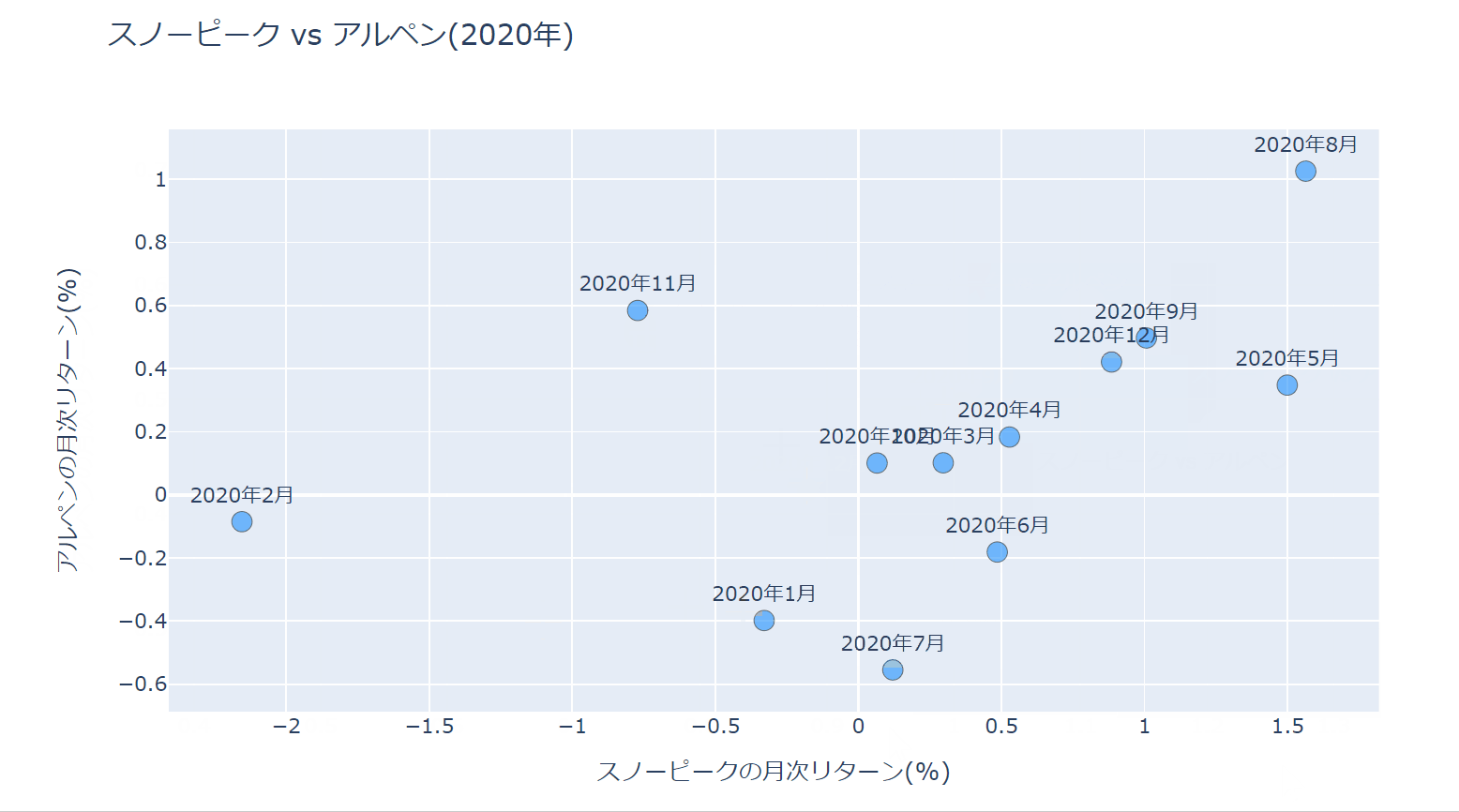
では、早速見ていきましょう。
Plotlyの基本的な使い方
Plotly Express
まずは高レベルAPIであるPlotly Expressを使った方法です。
こちらはデータフレームがあれば、簡単にキレイなグラフが作成できます。
以下のようなスノーピークとアルペンの日次のリターンデータを使います。
Date スノーピーク アルペン 2019-06-04 -0.025937 0.009823 2019-06-05 0.031803 0.013984 2019-06-06 0.009315 -0.013190 2019-06-07 0.009946 -0.008509 2019-06-10 0.012662 0.006129 ... ... ...
この2銘柄のリターンの散布図を描いてみましょう。
まず、plotly.expressをインポートします。
import plotly.express as px
そして、以下の2行だけで描画できます。
fig = px.scatter(df_leisure, x='スノーピーク', y='アルペン', hover_name='Date') fig.show()
もしくは、以下の1行だけでも大丈夫です。
px.scatter(df_leisure, x='スノーピーク', y='アルペン', hover_name='Date')
MatplotlibやPandasの機能を使って1行で書くことは可能ですが、plotlyの場合インタラクティブなグラフができますので、簡単により詳細を見ることができます。
以下のように大きく外れている点の日付を確認したり、特定の部分を拡大して詳細を分析したりすることが可能です。
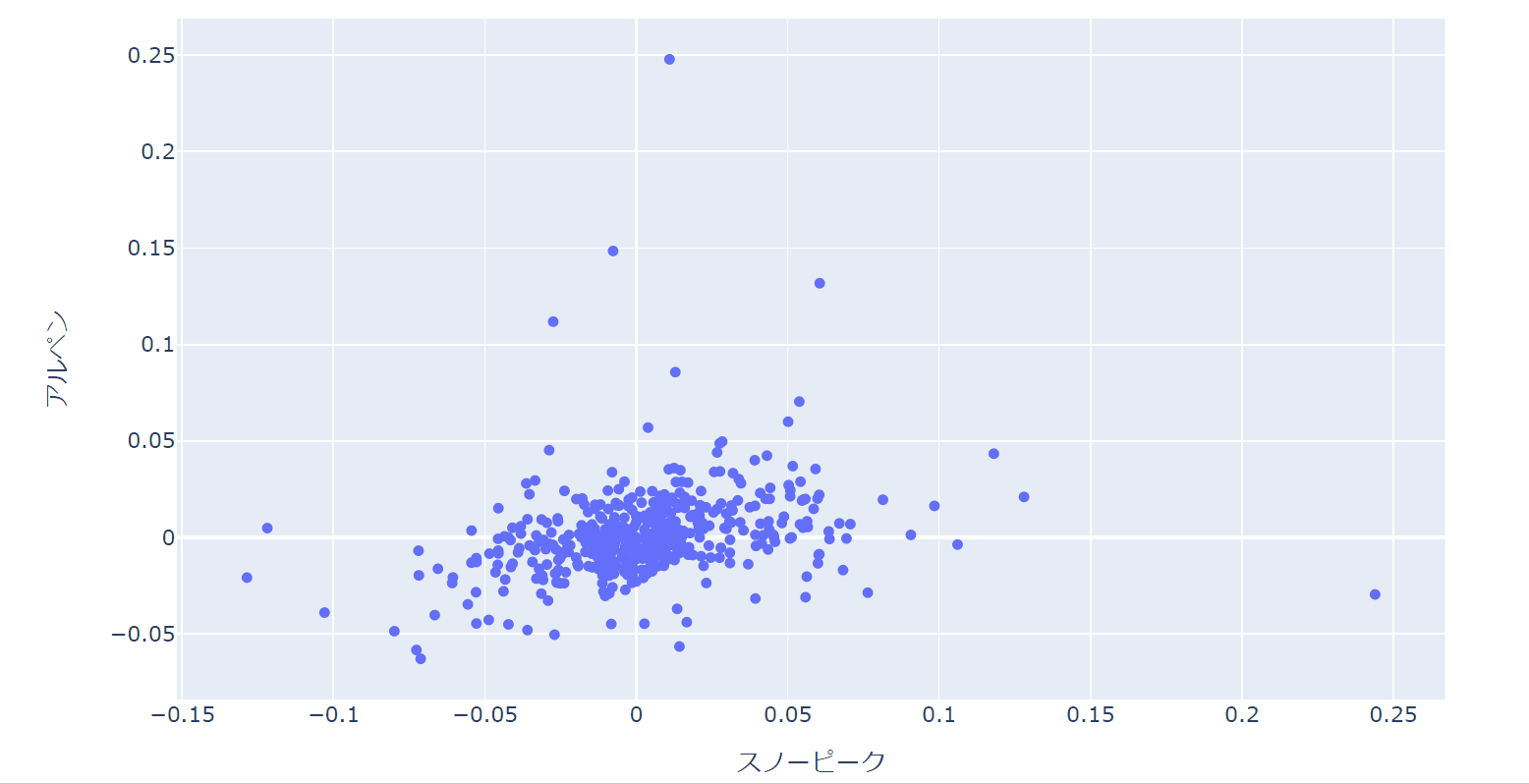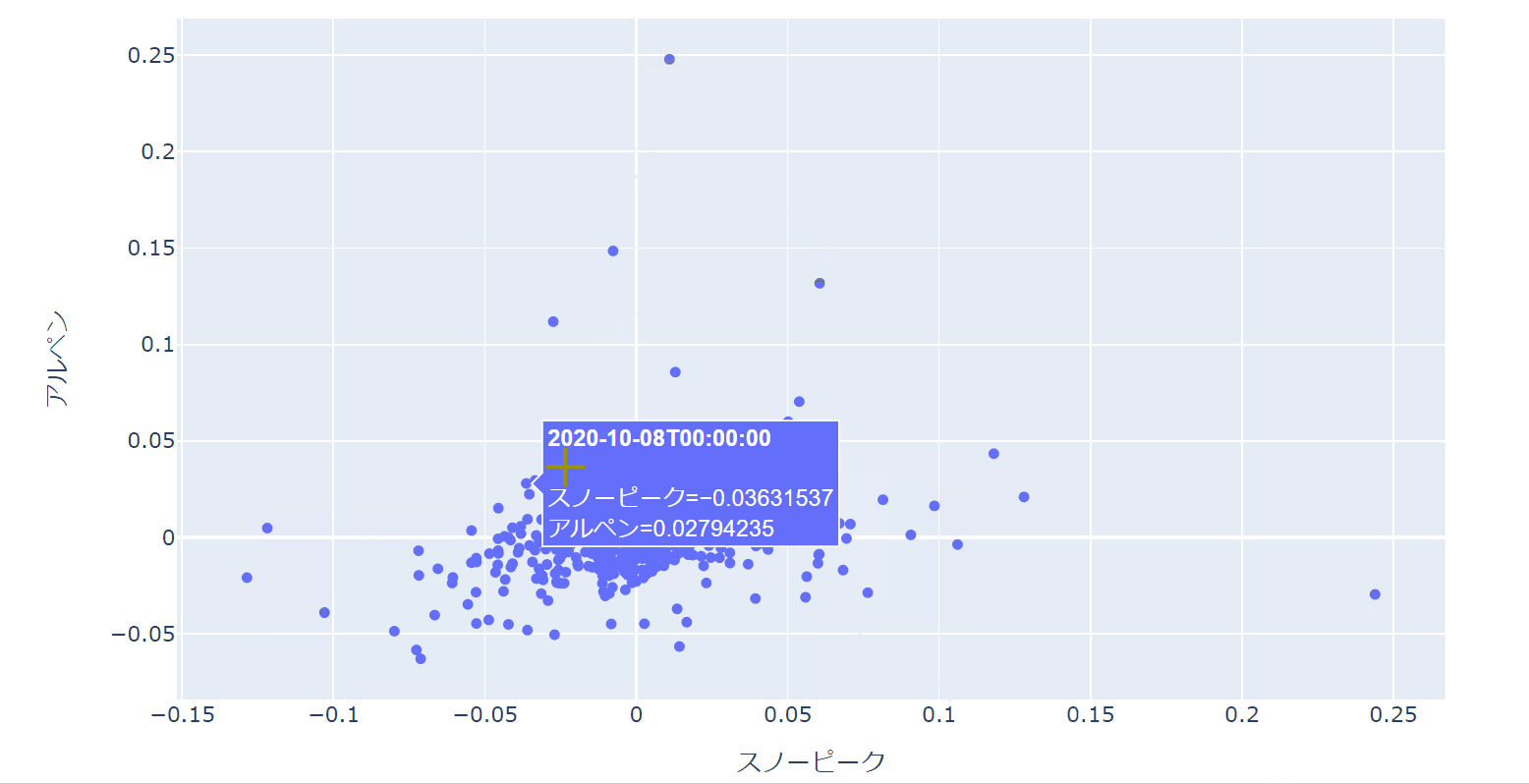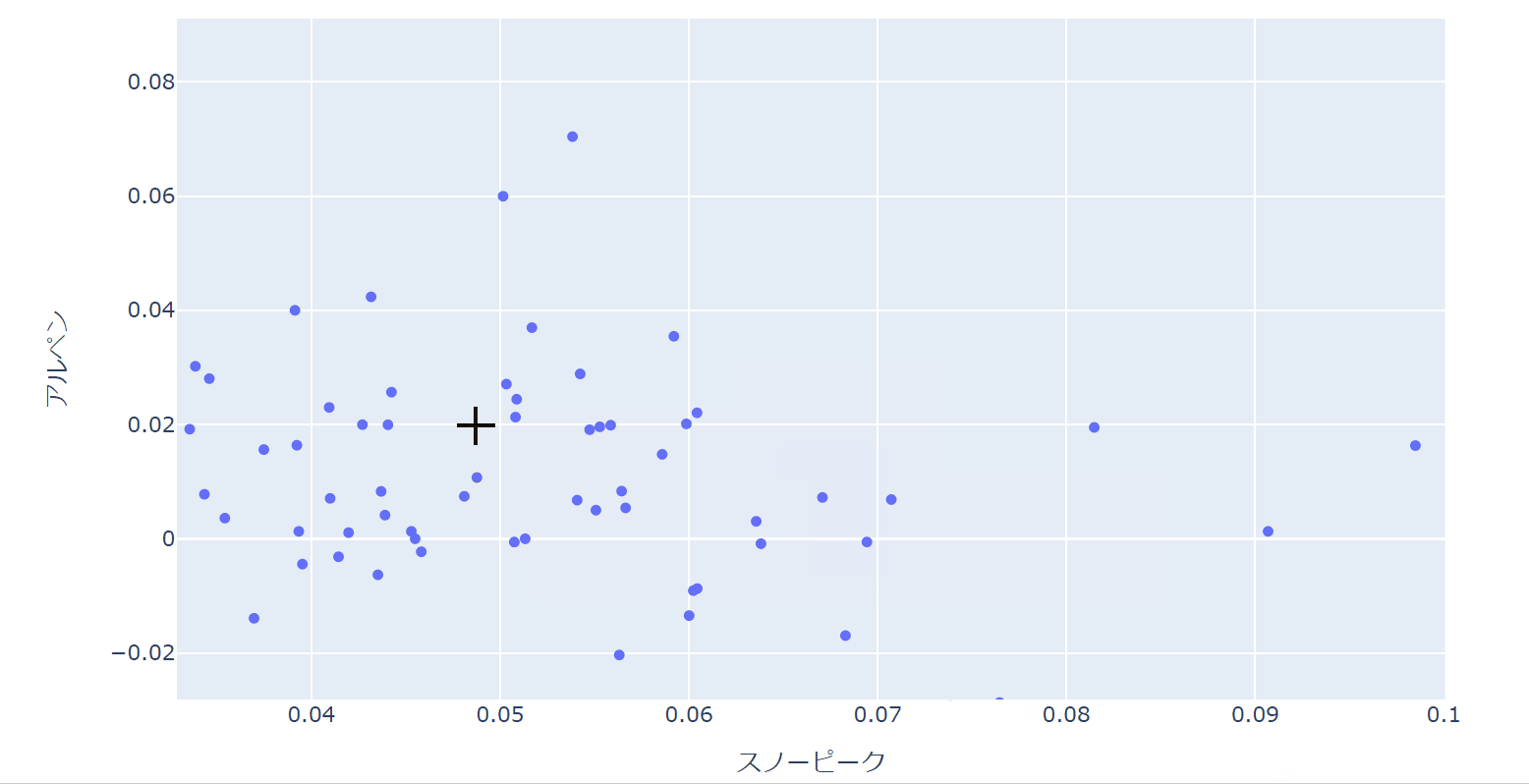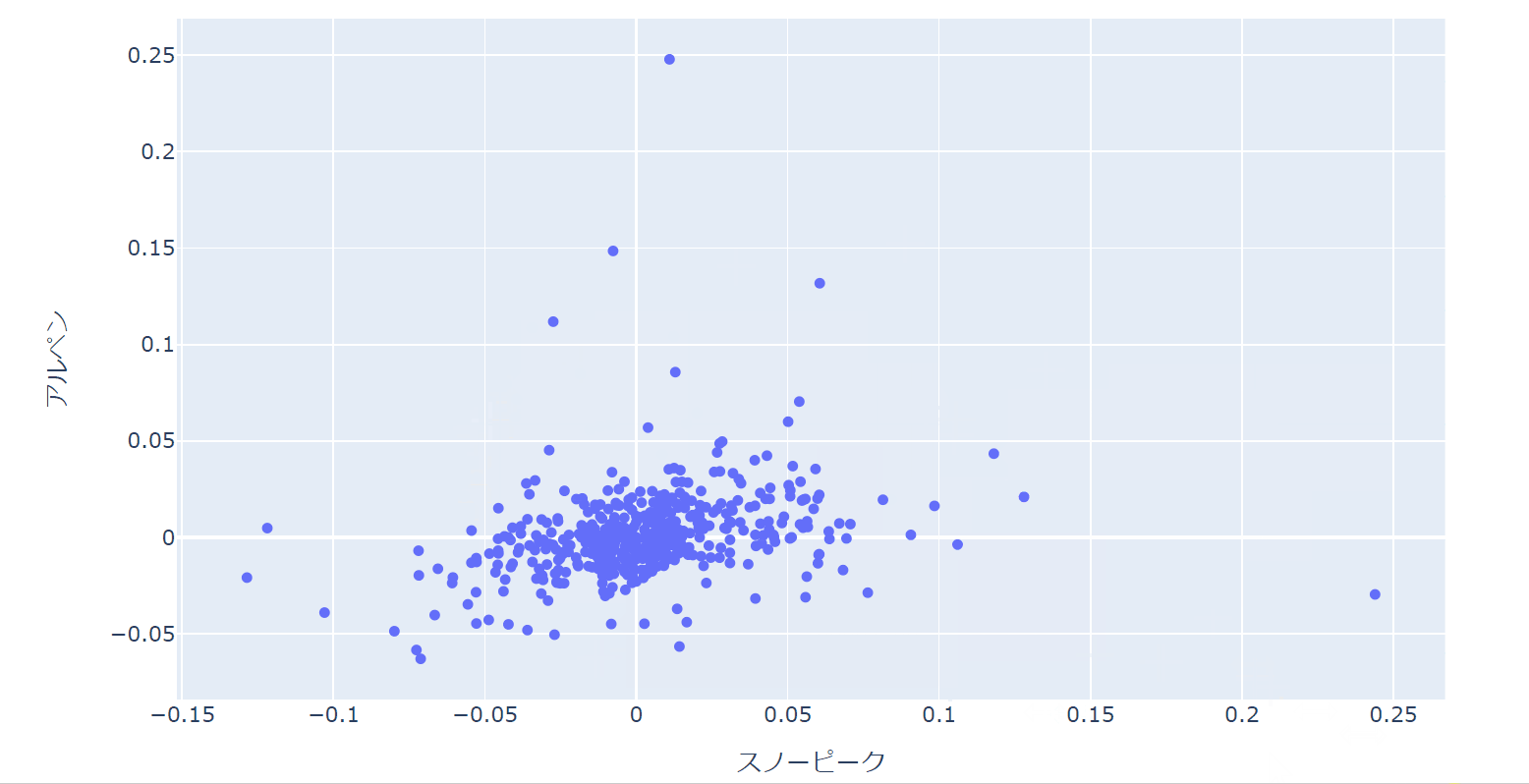
もしニュースデータや適時開示データなどのテキストデータなどを持っていれば、それを設定することで、カーソルを当てるとその日にどんなイベントがあったかを表示させることも原理的には可能です。
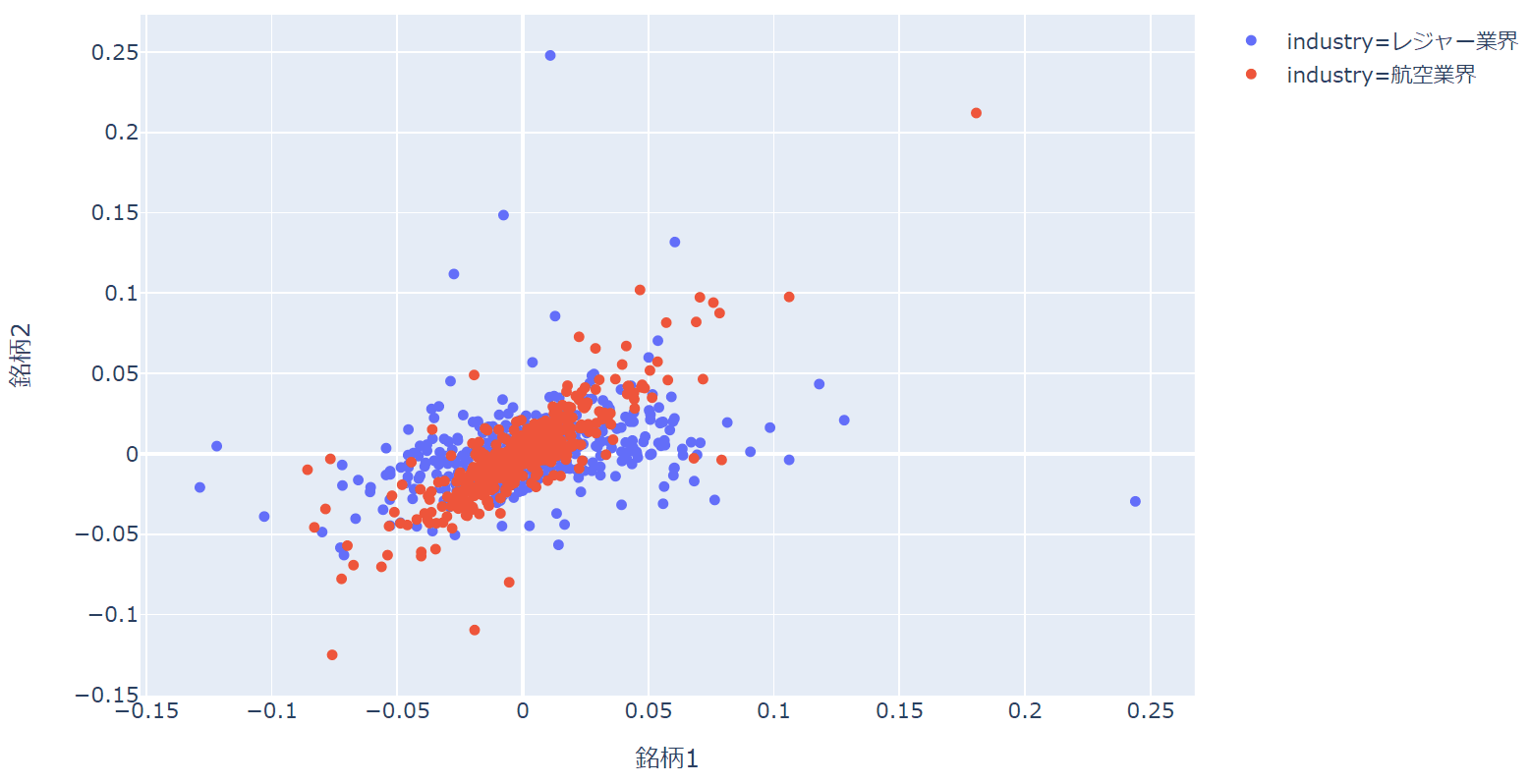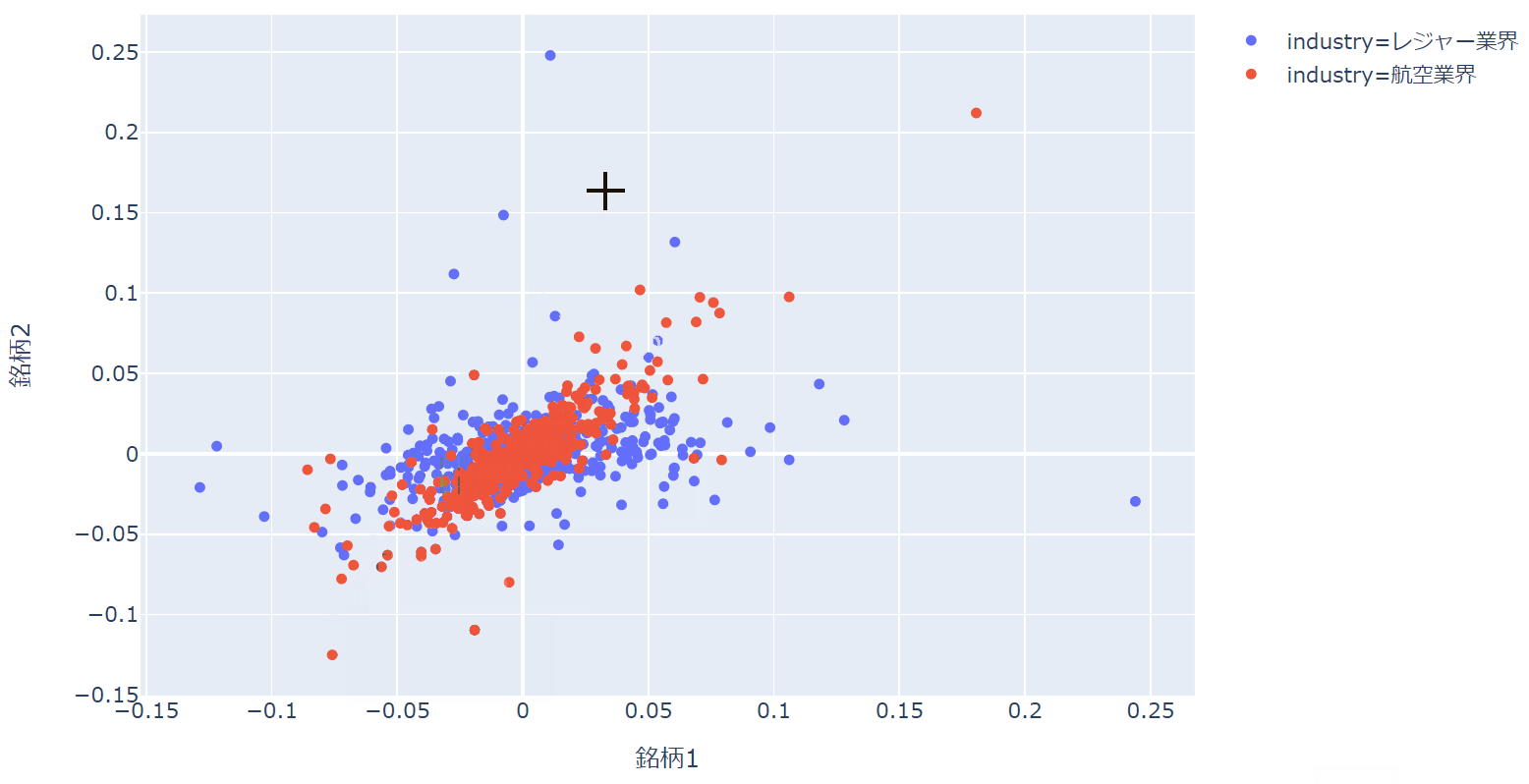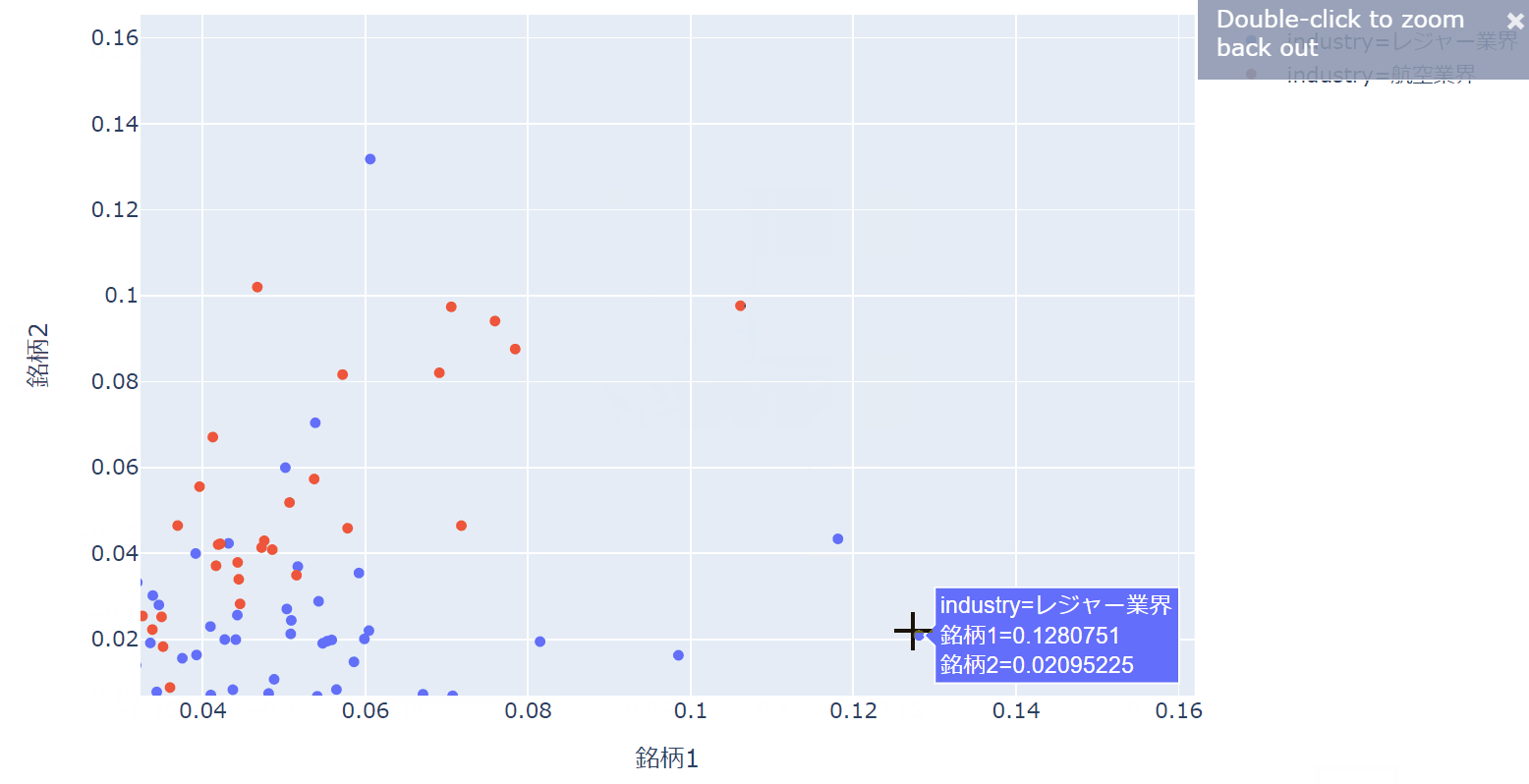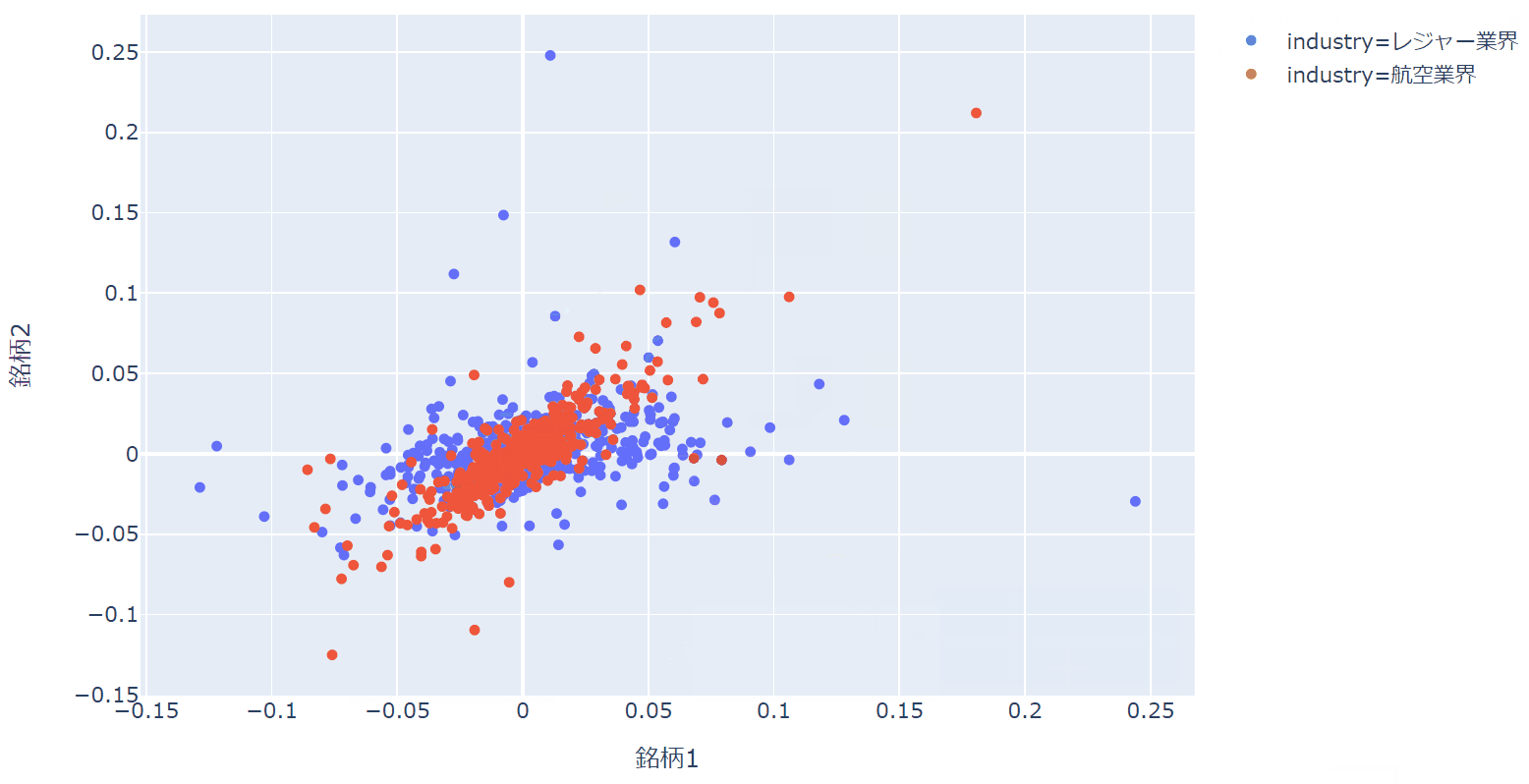
次は、レジャー業界と航空業界の2銘柄の相関を見たいという設定です。(あまり良い例ではないかもしれませんが、ご容赦ください)
レジャー業界はスノーピーク(銘柄1)とアルペン(銘柄2)、航空業界はANA(銘柄1)とJAL(銘柄2)です。
銘柄1 銘柄2 industry -0.025937 0.009823 レジャー業界 0.031803 0.013984 レジャー業界 0.009315 -0.013190 レジャー業界 0.009946 -0.008509 レジャー業界 0.012662 0.006129 レジャー業界 ... ... ... -0.007957 -0.008030 航空業界 0.029076 0.040051 航空業界 0.026111 0.018435 航空業界 0.010444 0.008045 航空業界 -0.002067 -0.002793 航空業界
そして、以下の2行で描画します。
fig = px.scatter(df_concat, x='銘柄1', y='銘柄2', color='industry') fig.show()
xにx軸の値の列名、yにy軸の値の列名を設定します。
グループに分類して色分けする場合は、colorに分類するための列を指定します。
この場合はindustry列を指定しています。
plotly.graph_objects
では、続いてplotly.graph_objectsを利用する方法を見ていきましょう。
高レベルAPIであるplotly expressよりも柔軟性が高いため、やりたいことがplotly expressで実現できない場合はこちらを使うと良いでしょう。
まずは、plotly.graph_objectsをインポートします。
import plotly.graph_objects as go
あとは以下で描画します。
data = go.Scatter(x=df['スノーピーク'].pct_change(),
y=df['アルペン'].pct_change(),
mode='markers')
go.Figure(data)
線グラフのときと同じで、go.Scatter()を使います。
xにはx軸の値、yにはy軸の値を入れます。
あと、重要なのはmode='markers'とすることです。
デフォルトではmode='lines'となっているので、markersを指定しないと線グラフが作成されてしまいます。
これで、以下のようなグラフが作成されます。
複数のグループを表示させたい場合は、go.Scatter()をリストにしてgo.Figure()に渡してやるだけです。
data_leisure = go.Scatter(x=df['スノーピーク'].pct_change(),
y=df['アルペン'].pct_change(),
mode='markers',
name='スノーピーク vs アルペン')
data_airline = go.Scatter(x=df['ANA'].pct_change(),
y=df['JAL'].pct_change(),
mode='markers',
name='ANA vs JAL')
go.Figure([data_leisure, data_airline])
nameはどちらのデータかわからなくなるので、凡例に表示させるために使用しています。
add_trace
add_traceも線グラフの場合とまったく同じように使用することができます。
まず、go.Figure()で図のひな型を作成しておき、add_traceでデータを追加していく方法です。
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['スノーピーク'].pct_change(),
y=df['アルペン'].pct_change(),
mode='markers',
name='スノーピーク vs アルペン'))
fig.add_trace(go.Scatter(x=df['ANA'].pct_change(),
y=df['JAL'].pct_change(),
mode='markers',
name='ANA vs JAL'))
少し発展的な使い方
ここまでは散布図の基本的な作成方法を見てきました。
ここからは、もう少しだけ細かい設定をしていきたいと思います。
より細かい設定方法については以下の記事をご参照ください。

データの設定
マーカーの設定
マーカーのサイズや色、形などを指定したい場合です。
無駄な線なども入っていますが、解説用と思ってください。
ここで設定しているのは、
- マーカーサイズ:marker.size, marker_size
- マーカーの形:marker.symbol, marker_symbol
- マーカーの透明度:marker.color, marker_color
- マーカーの線の太さ:marker.line.width, marker_line_width
- マーカーの線の色:marker.line.color, marker_line_color
です。
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['スノーピーク'].pct_change(),
y=df['アルペン'].pct_change(),
mode='markers',
marker={'size': 12,
'symbol': 'circle',
'color': '#1e90ff',
'opacity': 0.6,
'line': {'width': 0.5,
'color': '#000000'}},
name='スノーピーク vs アルペン'))
fig.add_trace(go.Scatter(x=df['ANA'].pct_change(),
y=df['JAL'].pct_change(),
mode='markers',
marker_size=12,
marker_symbol= 'diamond',
marker_color='#3cb371',
marker_opacity=0.4,
marker_line_width=0.5,
marker_line_color='#000000',
name='ANA vs JAL'))
1つ目のスノーピーク、アルペンのデータについては、markerのプロパティを辞書形式で渡しています。
もちろんdict()とすることでも可能です。
2つ目のANA、JALのデータについては、個別にmarker_size、marker_symbolなどとして指定しています。
どちらの方法でも可能ですが、たくさんのプロパティを設定する場合は、辞書形式の方が楽ですね。
1つ2つ設定するだけの場合は後者の方が楽かと思います。
こちらが出来上がった散布図です。
テキストの設定
月次のリターンデータを作成します。
def year_month(date):
return f'{date.year}年{date.month}月'
# 日次データの作成
df_pct_change = df[['Date']].copy()
df_pct_change['スノーピーク'] = df['スノーピーク'].pct_change()
df_pct_change['アルペン'] = df['アルペン'].pct_change()
df_pct_change.dropna(inplace=True)
# 月次データの作成
df_pct_change['year_month'] = df_pct_change['Date'].apply(year_month)
df_pct_change_monthly = df_pct_change.groupby('year_month').mean()[['スノーピーク', 'アルペン']]
こんな感じです。
スノーピーク アルペン
year_month
2019年10月 -0.008560 0.000673
2019年11月 0.000647 0.002824
2019年12月 0.000415 -0.000636
2019年6月 0.002002 -0.002737
2019年7月 -0.002246 0.001057
では、テキストを設定して散布図をプロットしてみましょう。
やり方は引数textにリスト形式で表示したいテキスト情報を設定するだけです。
fig = go.Figure()
text = df_pct_change_monthly.index
fig.add_trace(go.Scatter(x=df_pct_change_monthly['スノーピーク'],
y=df_pct_change_monthly['アルペン'],
mode='markers',
marker={'size': 12,
'symbol': 'circle',
'color': '#1e90ff',
'opacity': 0.6,
'line': {'width': 0.5,
'color': '#000000'}},
text=text,
name='スノーピーク vs アルペン'))
こうすることにより、カーソル当てた際にいつのリターンか?を簡単に確認できます。
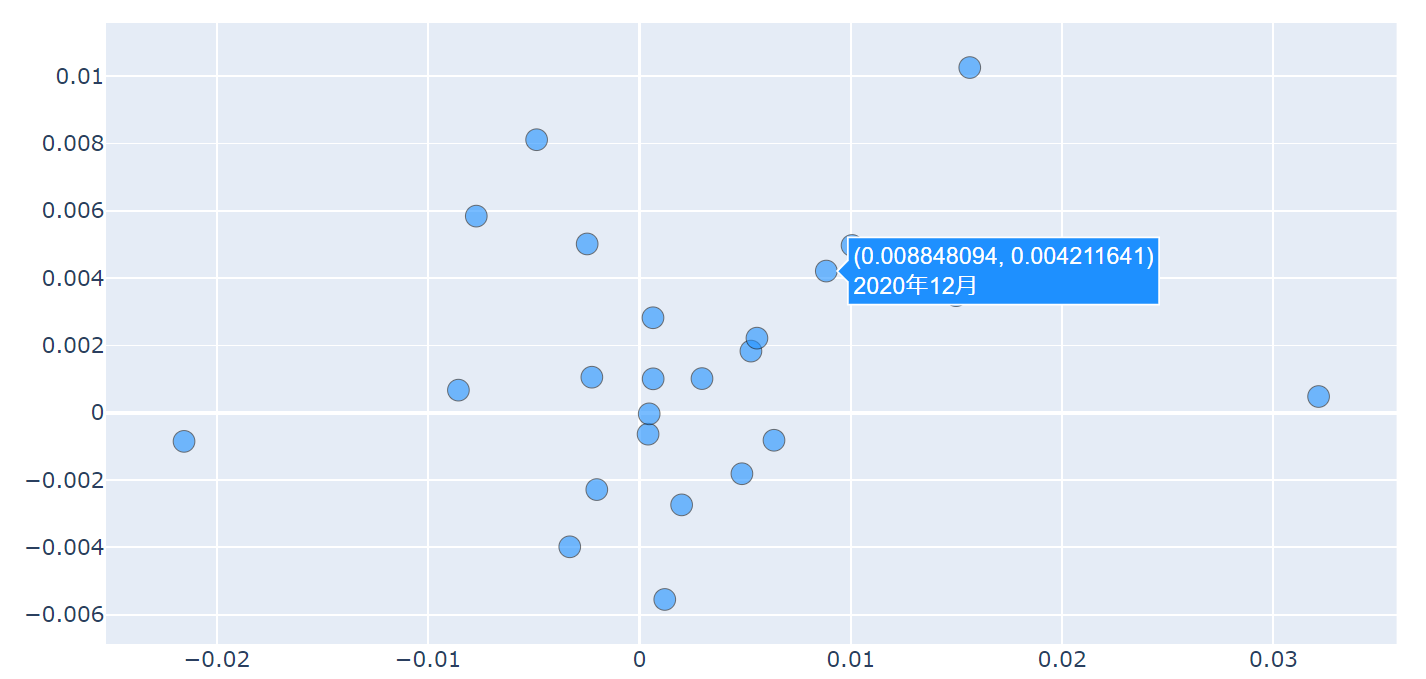
「あ、外れ値がある?これはいつのリターンだろう?」と思って、pythonでデータを調べる必要はありません。
グラフだけで確認できます。
これは意外と大きな点で、データ数によっては時間の大幅な短縮になりますし、場合によっては調べるのが面倒くさくてスルーしてしまうということがなくなります(「何でここを確認していないの!?」なんてことありませんか?)。
グラフ上にテキスト情報を表示したい場合には、modeを"markers+text"とします。
そして、そのままではマーカーとテキスト情報が重なってしまいますので、ここではtextposition='top center'として、マーカーの上部にテキスト情報を表示するようにします。
fig = go.Figure()
text = df_pct_change_monthly.index
fig.add_trace(go.Scatter(x=df_pct_change_monthly['スノーピーク'],
y=df_pct_change_monthly['アルペン'],
mode='markers+text',
marker={'size': 12,
'symbol': 'circle',
'color': '#1e90ff',
'opacity': 0.6,
'line': {'width': 0.5,
'color': '#000000'}},
text=text,
textposition='top center',
name='スノーピーク vs アルペン'))
これにより作成される図は以下です。
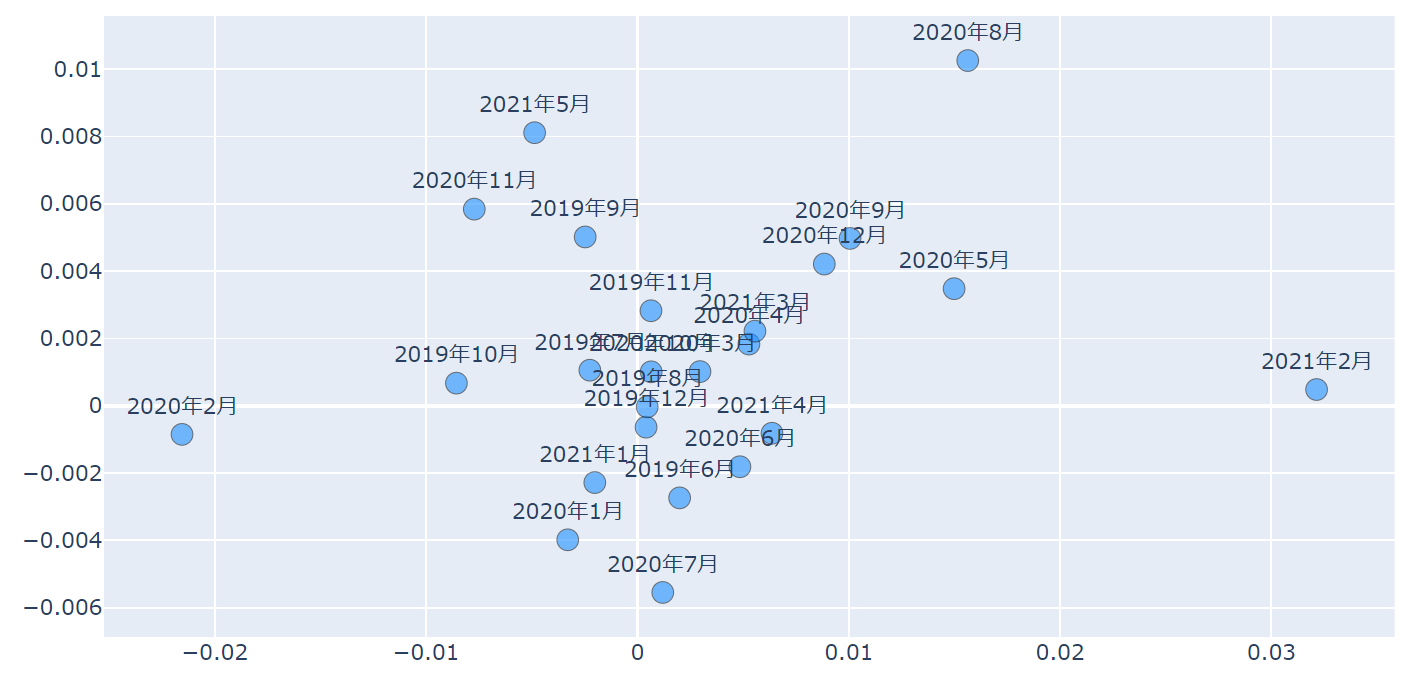
少し汚いですが、あくまで例ということで、皆さんはもっとキレイなものを作っていただければと思います。
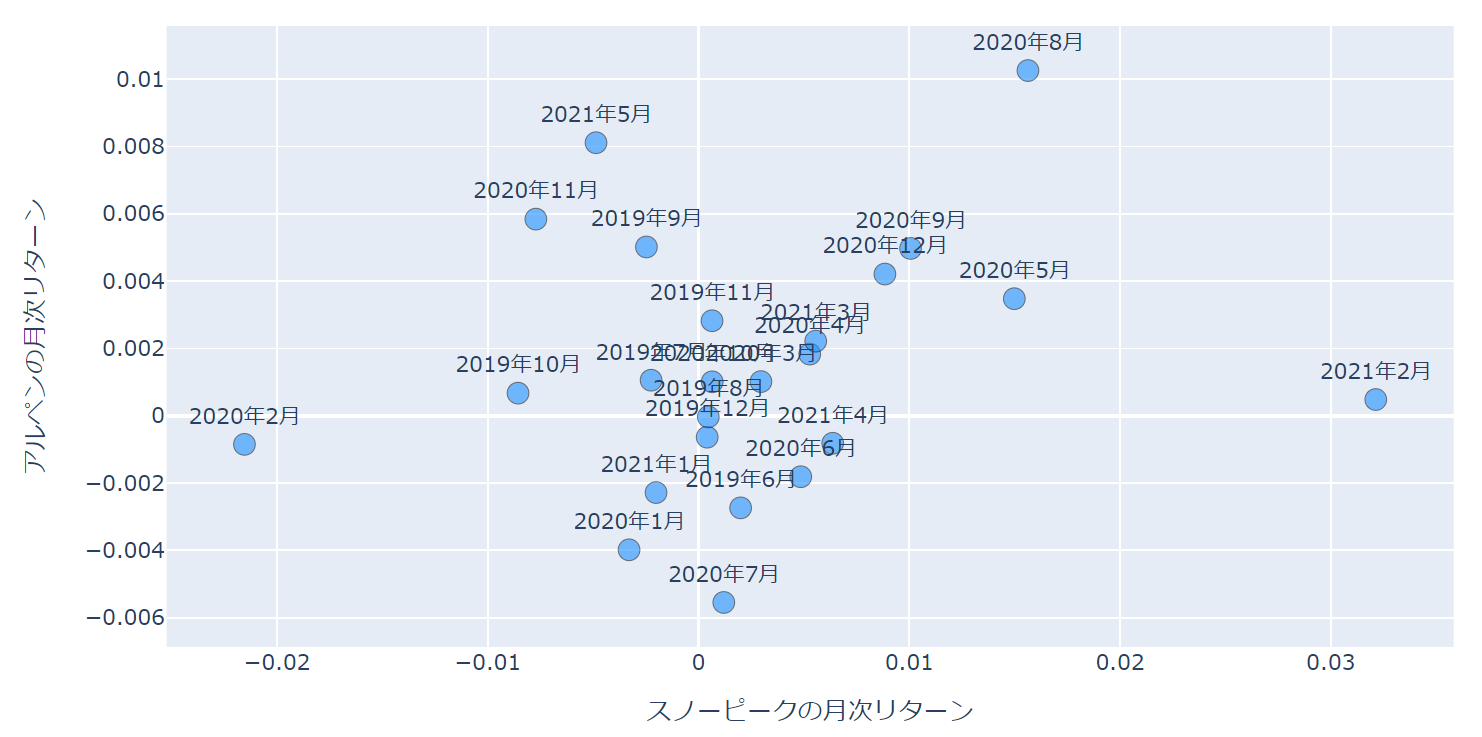
軸ラベルの設定
今の状態では横軸と縦軸が何を表しているのかわかりませんので、軸ラベルの設定をしたいと思います。
軸ラベルを設定するには、go.Layout()で指定します。
そして、それをgo.Figure()に渡してやります。
fig = go.Figure()
text = df_pct_change_monthly.index
data = go.Scatter(x=df_pct_change_monthly['スノーピーク'],
y=df_pct_change_monthly['アルペン'],
mode='markers+text',
marker={'size': 12,
'symbol': 'circle',
'color': '#1e90ff',
'opacity': 0.6,
'line': {'width': 0.5,
'color': '#000000'}},
text=text,
textposition='top center',
name='スノーピーク vs アルペン')
layout = go.Layout(xaxis={'title': 'スノーピークの月次リターン'},
yaxis={'title': 'アルペンの月次リターン'})
go.Figure(data, layout).show()
update_layout
add_traceを使っている場合は、update_layout()で指定します。
どちらでも結果は同じになります。
fig = go.Figure()
text = df_pct_change_monthly.index
fig.add_trace(go.Scatter(x=df_pct_change_monthly['スノーピーク'],
y=df_pct_change_monthly['アルペン'],
mode='markers+text',
marker={'size': 12,
'symbol': 'circle',
'color': '#1e90ff',
'opacity': 0.6,
'line': {'width': 0.5,
'color': '#000000'}},
text=text,
textposition='top center',
name='スノーピーク vs アルペン'))
fig.update_layout(xaxis={'title': 'スノーピークの月次リターン'},
yaxis={'title': 'アルペンの月次リターン'})
fig.show()
すると以下のようにx軸、y軸のラベルが作成されます。
その他
では、最後にまとめてもう少し改良してみましょう。
fig = go.Figure()
fig.add_trace(go.Scatter(x=df_pct_change_monthly['スノーピーク']*100,
y=df_pct_change_monthly['アルペン']*100,
mode='markers+text',
marker={'size': 12,
'symbol': 'circle',
'color': '#1e90ff',
'opacity': 0.6,
'line': {'width': 0.5,
'color': '#000000'}},
text=df_pct_change_monthly.index,
textposition='top center',
hovertemplate='<b>%{text}</b><br>' +
'スノーピーク: %{x:0.1f}%<br>' +
'アルペン: %{y:0.1f}%',
name='スノーピーク vs アルペン'))
fig.update_layout(xaxis={'title': 'スノーピークの月次リターン(%)'},
yaxis={'title': 'アルペンの月次リターン(%)'},
hovermode='closest',
hoverlabel_align='right',
title='スノーピーク vs アルペン(2020年)')
fig.show()
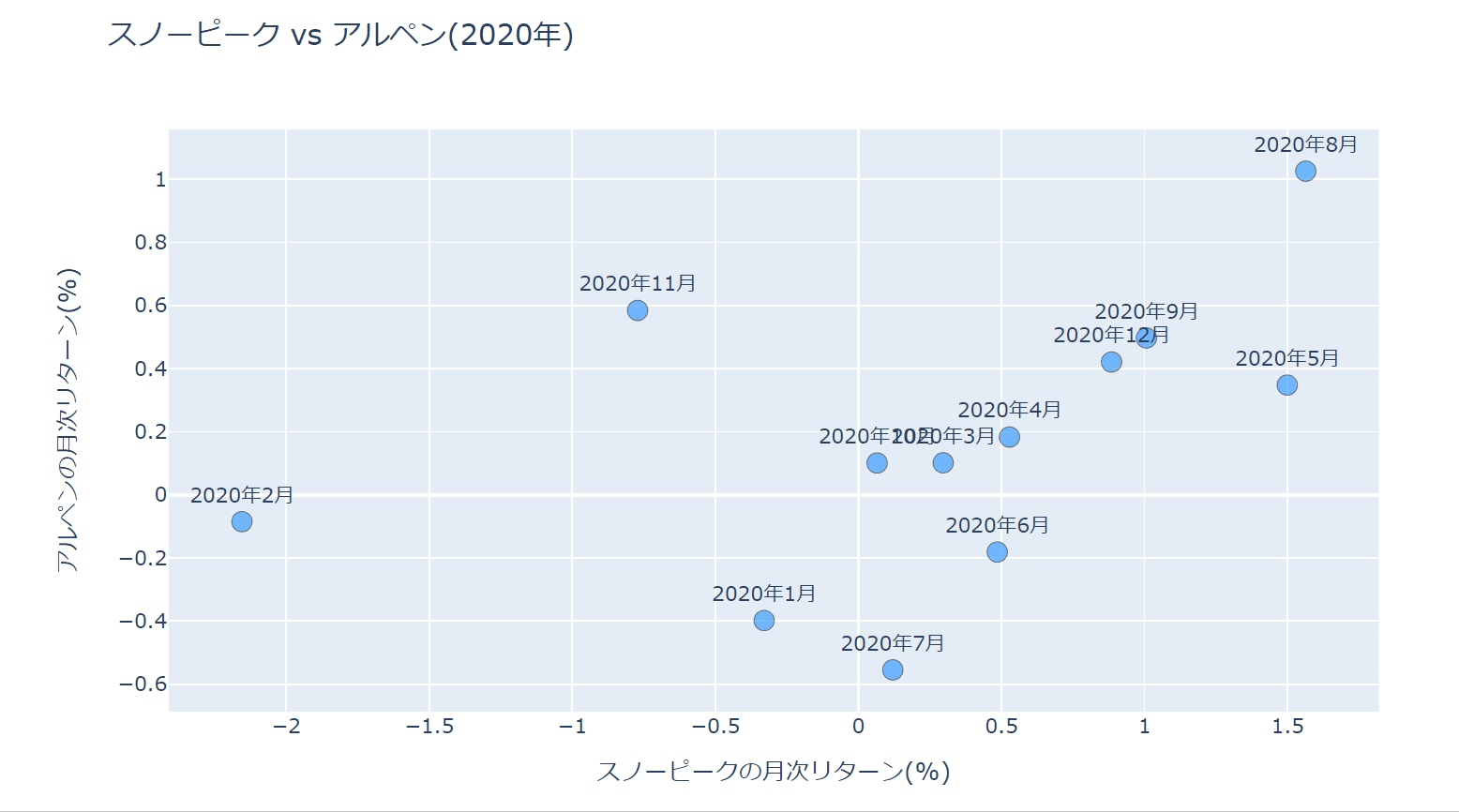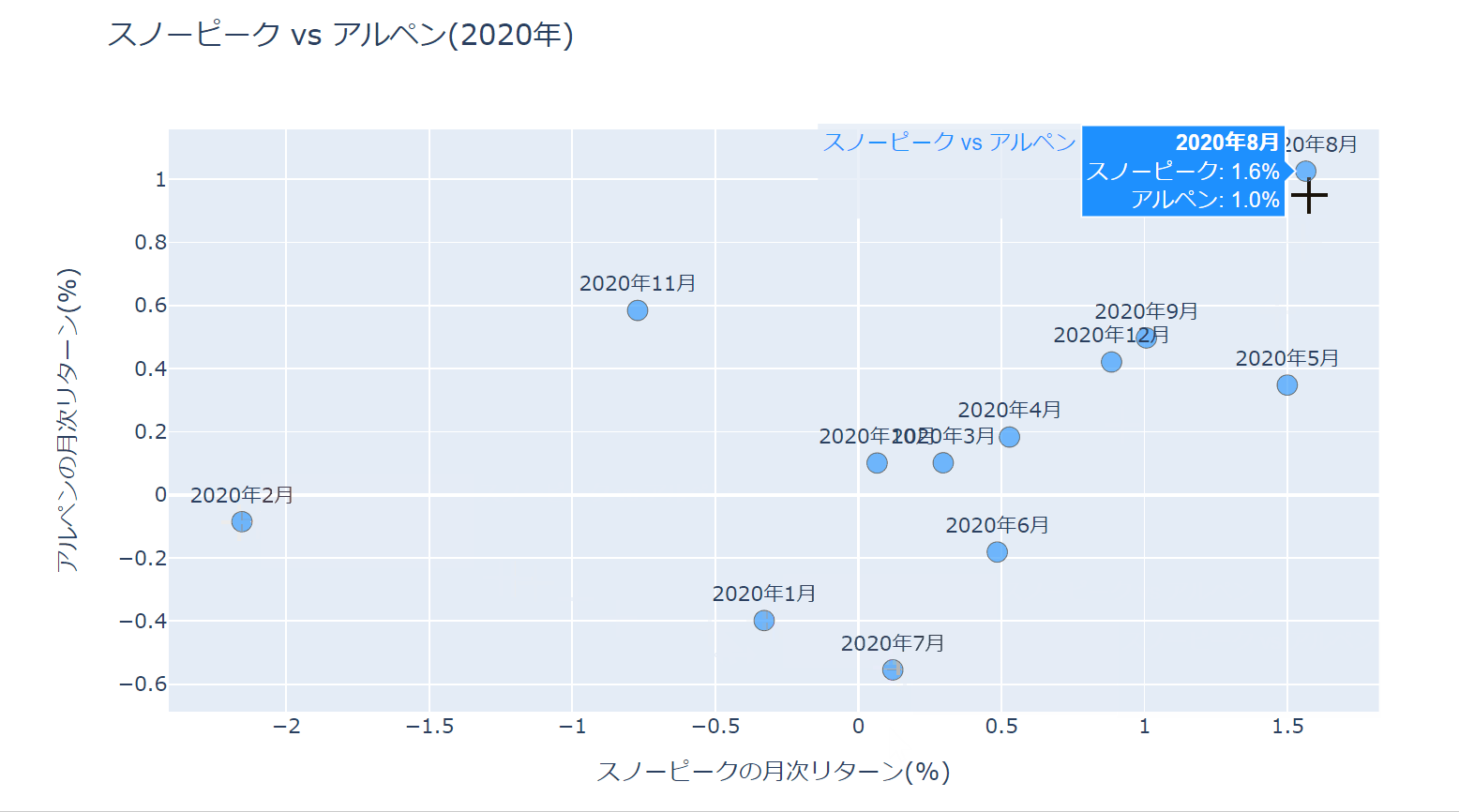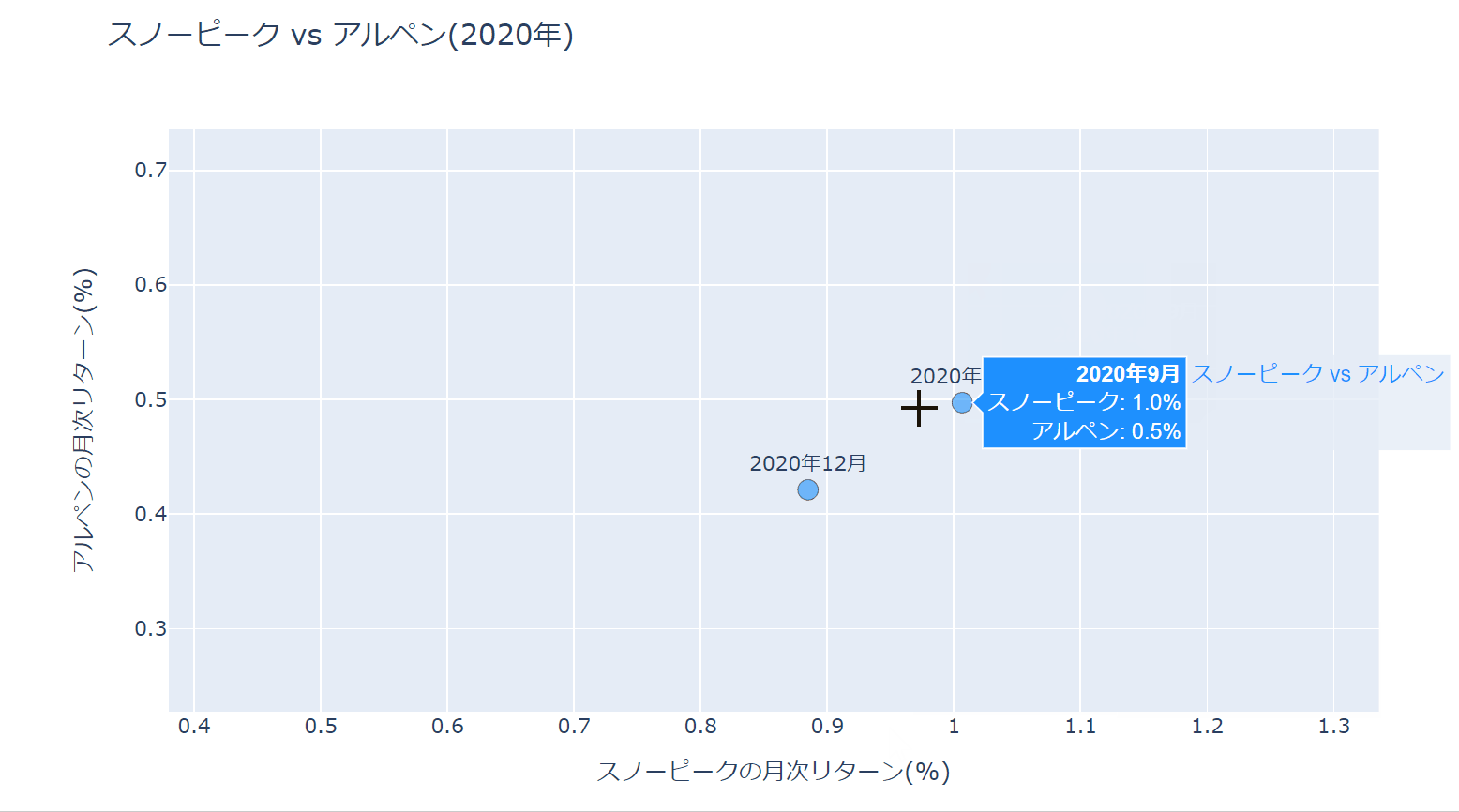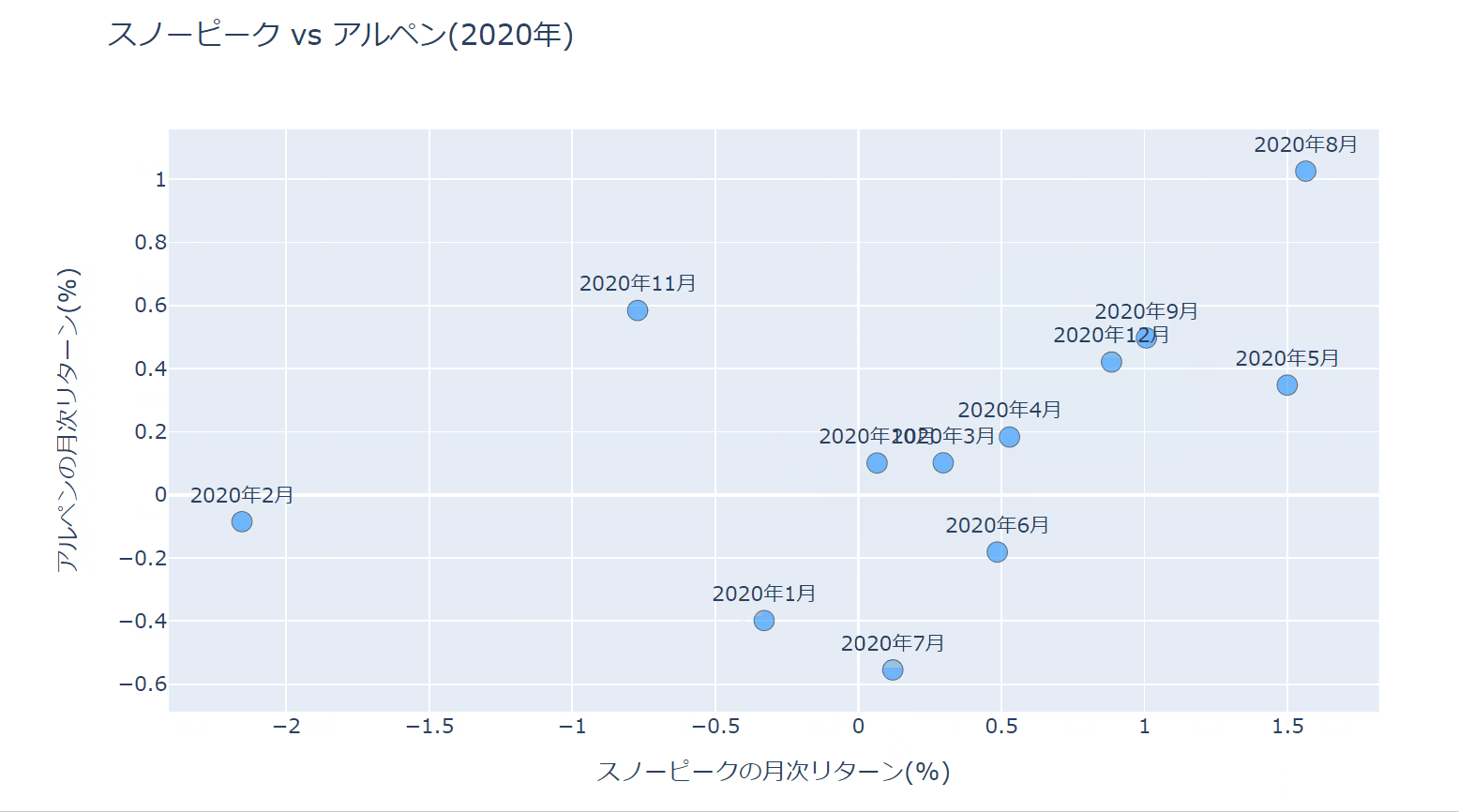
カーソルを当てたときの表示方法を、hovertemplateというプロパティを使って少し改良しています。
%{}で変数を囲むことによりその変数表示させることが可能です。変数の書式はpythonと同じです。
また、変数以外の部分はHTMLと同じ表記になっていますので<b>タグで太字に、<br>タグで改行しています。
レイアウトの設定でhovermode='closest'としていますが、これはカーソルに一番近い点のラベルを表示させるためです。
hoverlabel_align='right'でラベルを右寄せにしています。
出来上がった散布図は以下になります。
まとめ
今回は、plotlyによるインタラクティブな散布図を作成しました。
見た目も良くなりますし、分析の効率化、高度化がはかれると思いますので、是非皆様も試していただければと思います。
まだまだ色んな設定が可能ですが、これらを使えばそれほど困らないかと思います。
より詳細については、こちらで解説していますので、参考にしていただければと思います。
レイアウトの設定については、今後解説する予定です。
では!