今回はデータ分析の際にもっとも多く使うグラフの一つであるヒストグラムの作成方法を解説したいと思います。
plotlyを使うと、以下のようなインタラクティブなヒストグラムを1行や2行程度の簡単なコードで作成することが可能です。
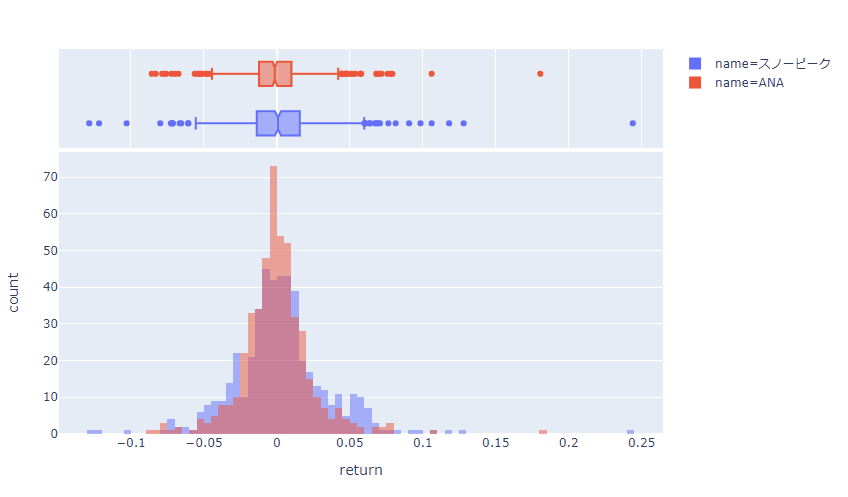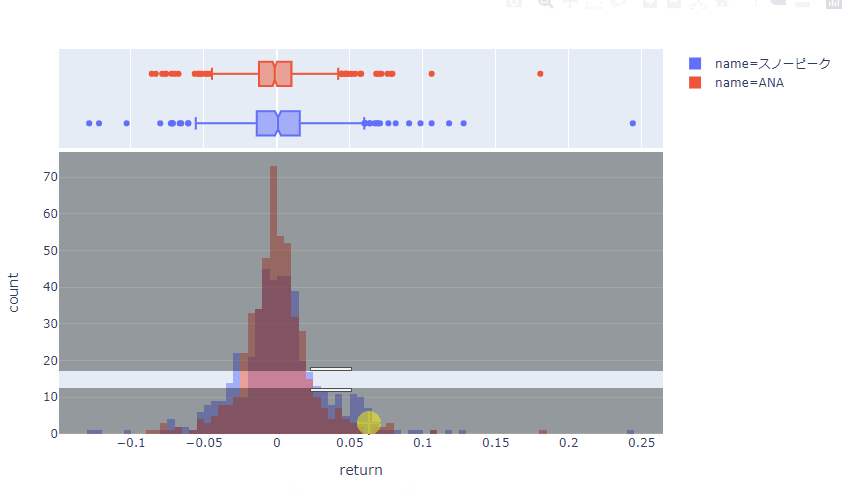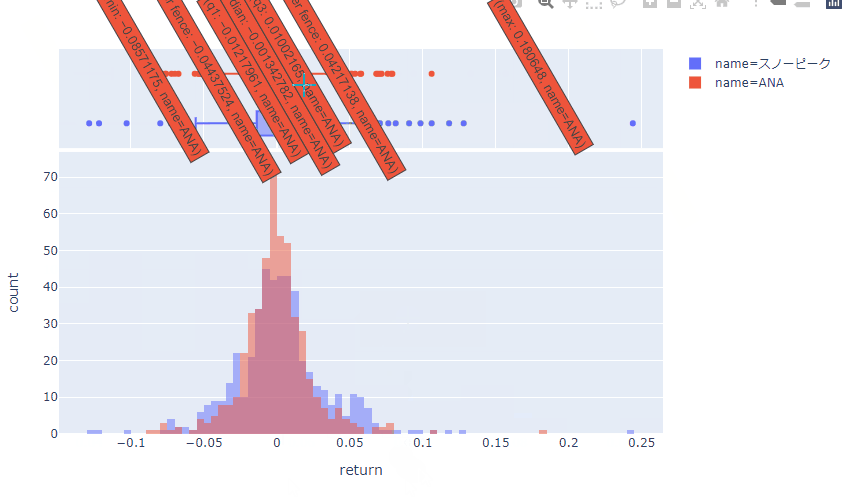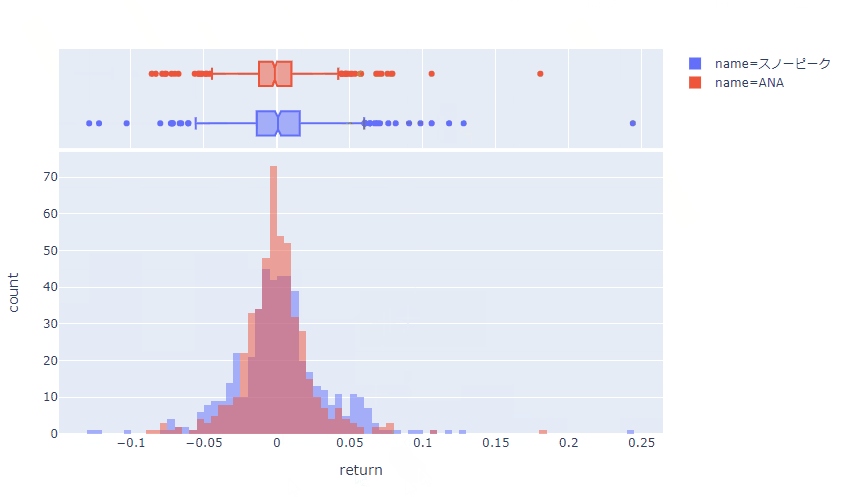
公式HPの解説はこちらです。
目次
Plotly Expressを使ったヒストグラムの作成
では、まずPlotly Expressを使ったヒストグラムの作成方法について簡単に解説します。
以下のようなデータを持っているとします。
Date スノーピーク 2019-06-04 -0.025937 2019-06-05 0.031803 2019-06-06 0.009315 2019-06-07 0.009946 2019-06-10 0.012662 ... ...
plotly.expressをインポートします。
import plotly.express as px
あとは以下の1行でヒストグラムを描くことができます。
px.histogram(df, x='スノーピーク')
まず一つ目の引数には表示するpandasのデータフレームを渡します。
そして、xに表示したい列を渡します。
非常に簡単ですね。
これだけで以下のようなヒストグラムが表示されます。
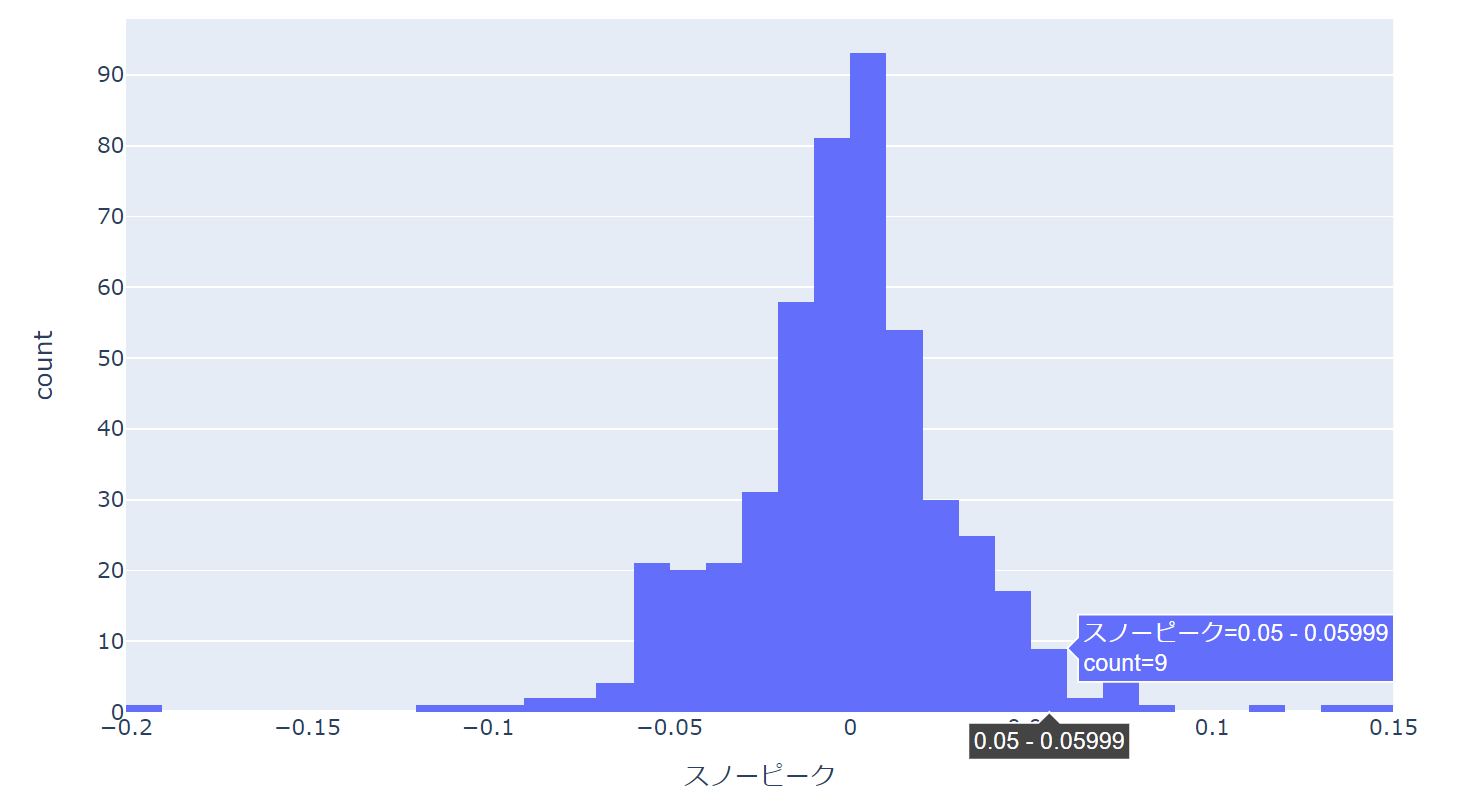
カーソルを当てることで、各ビンの閾値や度数も見ることができます。
binの設定
デフォルトのビンだと結構少ないことも多いですよね。
そういった場合は、nbinsを指定します。
px.histogram(df, x='スノーピーク', nbins=80)
すると少し細かくなります。
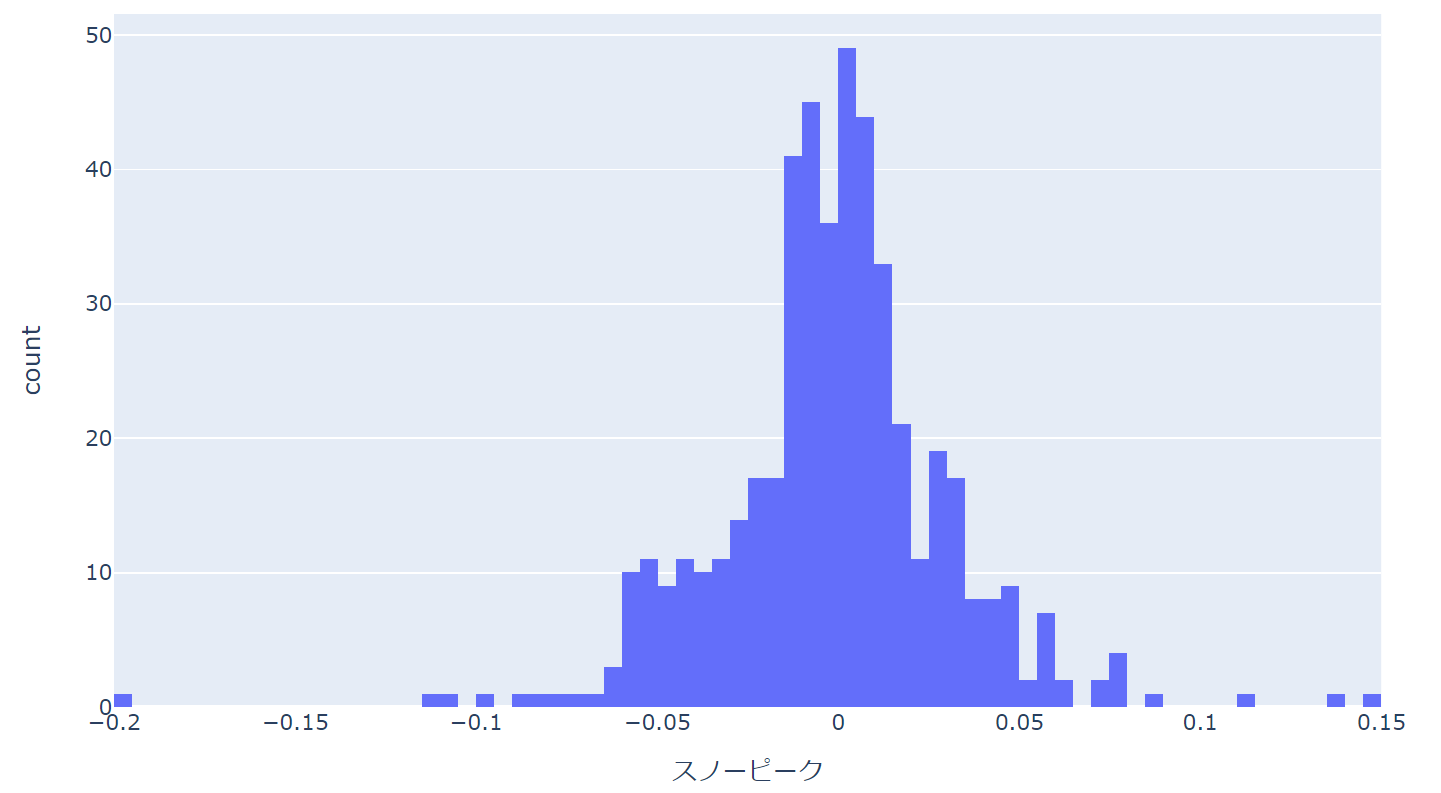
複数データのヒストグラム
各正解ラベルごと特徴量の分布の違いを見るときなど、複数のデータを一つのヒストグラムに表示したい場合はよくあると思います。
その場合は以下のように書きます。
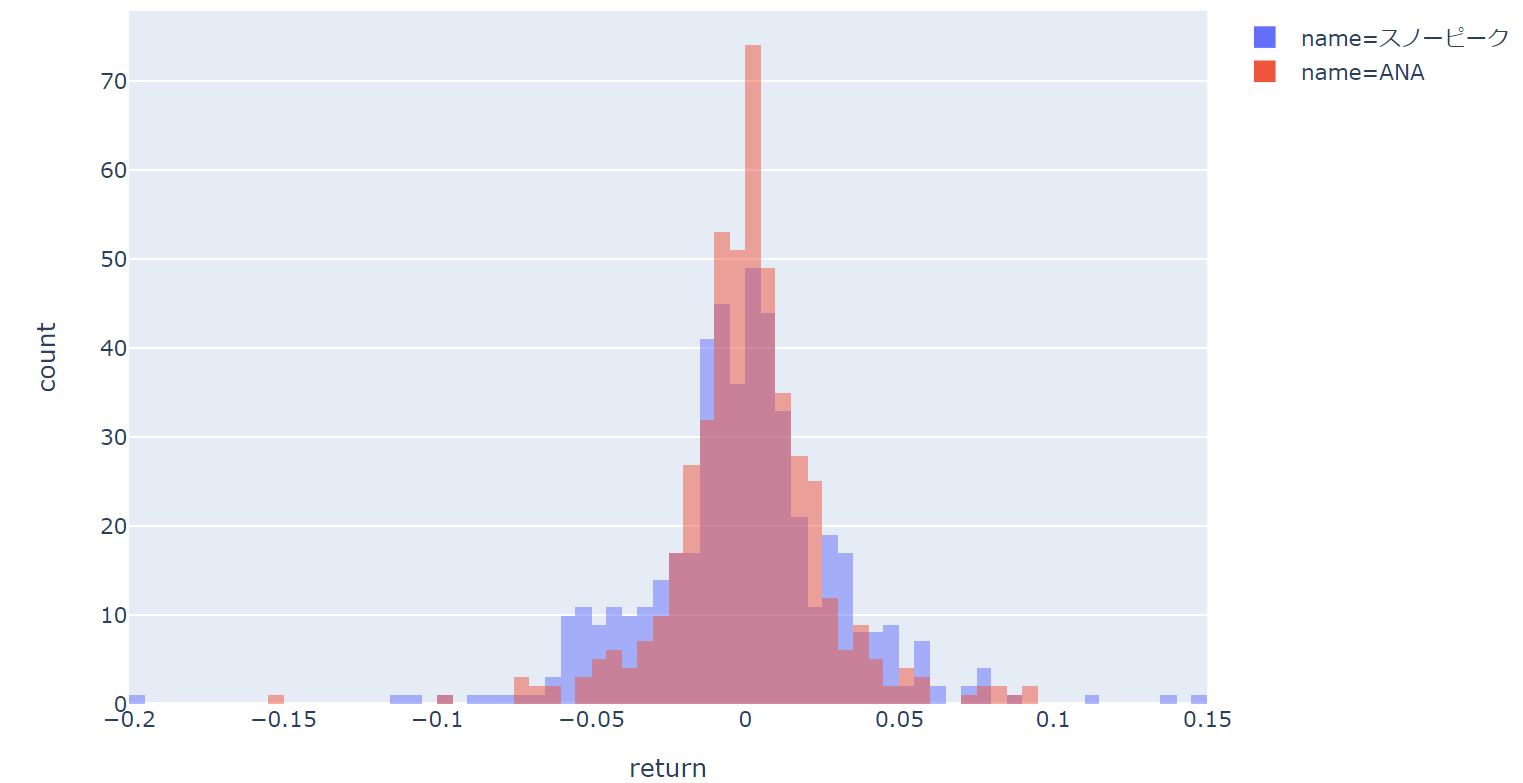
px.histogram(df_vertical, x='return', color='name', barmode='overlay')
plotly.expressを使う場合は表示したいデータを一つの列に設定してやる必要があります。
つまり、上記のdf_verticalという変数は以下のようにreturn列にすべてのリターンが入っており、name列で銘柄が分類されている形になっています。
return name
Date
2021-05-28 0.009943 スノーピーク
2021-05-27 0.005626 スノーピーク
2021-05-26 -0.005594 スノーピーク
2021-05-25 0.047820 スノーピーク
2021-05-24 -0.008054 スノーピーク
... ... ...
2019-06-07 -0.006207 ANA
2019-06-06 0.005702 ANA
2019-06-05 -0.007290 ANA
2019-06-04 -0.017684 ANA
2019-06-03 0.012185 ANA
あと、注意点としてはbarmode="overlay"としないと1つ目のデータの上に2つ目のデータが積み重なってしまいます。
これはクリティカルな間違いになってしまいますので気を付けましょう。
その結果、以下のようなヒストグラムが出来上がります。
密度ベースのヒストグラムを作成する
データの数が違う場合、以下のように度数だけを比較してもよくわかりません。
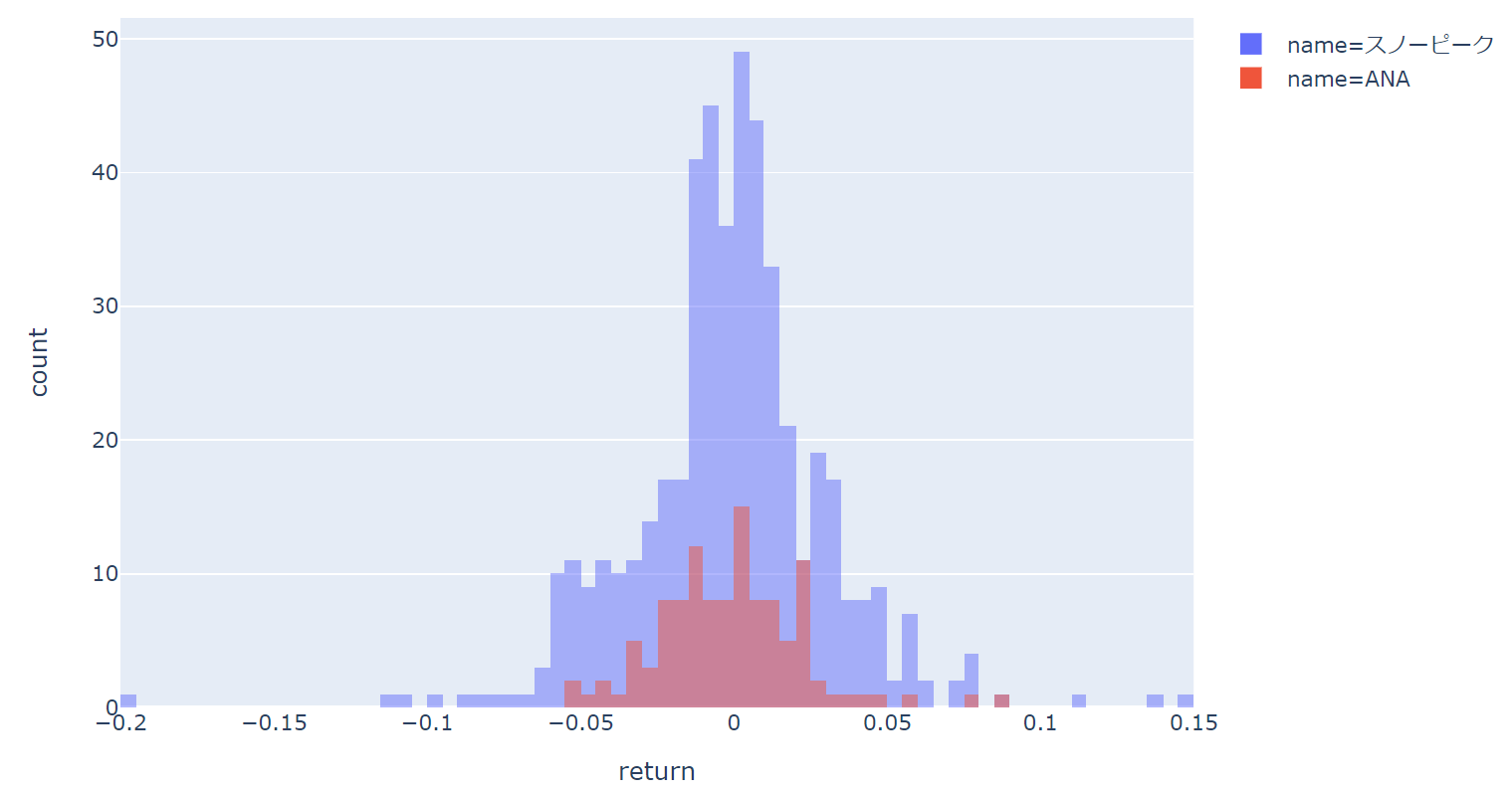
そういった場合に、密度で表示する必要がありますね。
その場合は、以下のようにhistnorm="probability"を引数として追加します(matplotlibではdensity=Trueですね)。
px.histogram(df_vertical_sub, x='return', color='name', barmode='overlay', histnorm='probability')
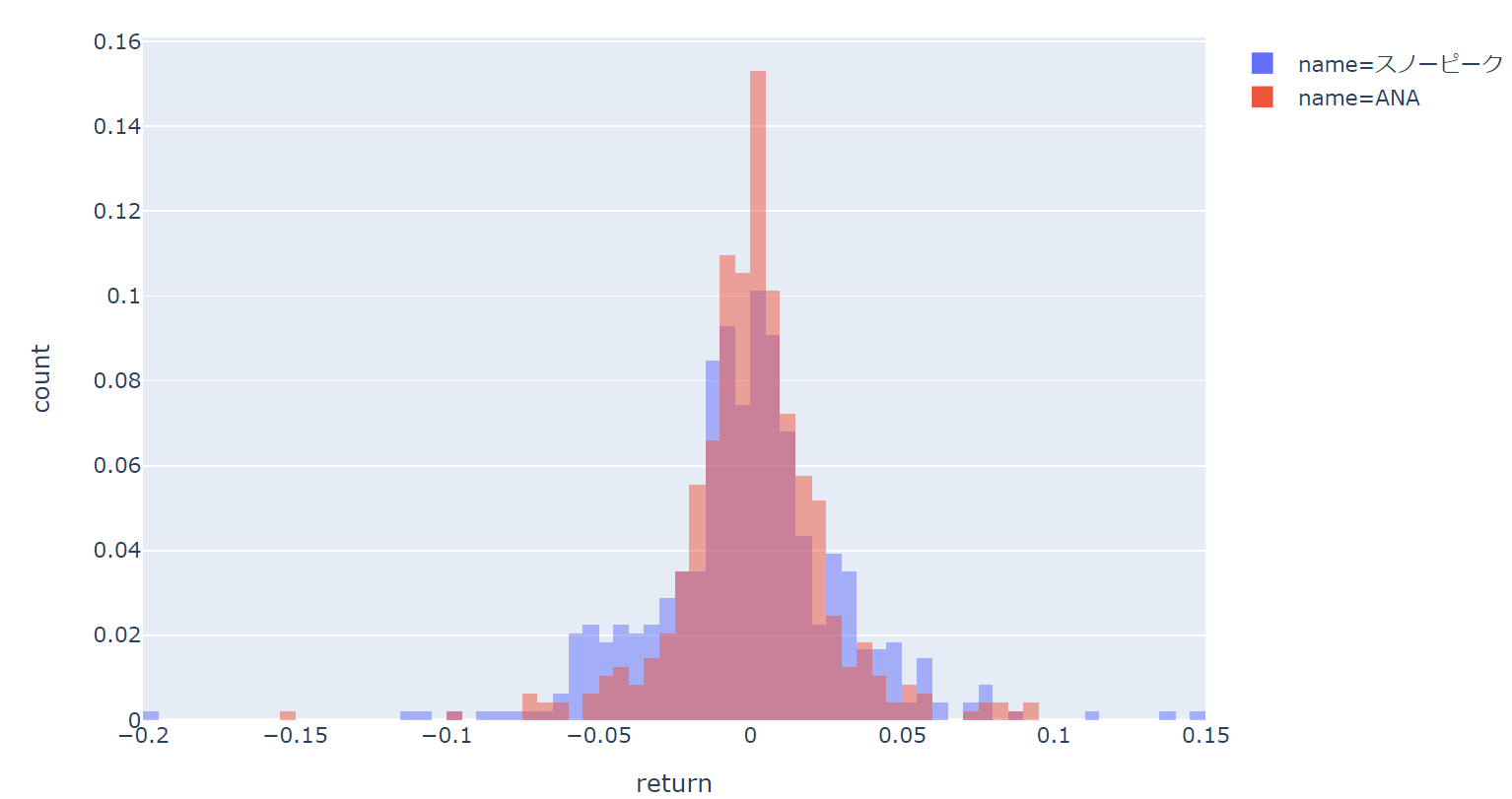
こうすることにより、以下のように密度で表示されます。
スノーピークの方が歪度が大きいな、といった比較が可能になります。
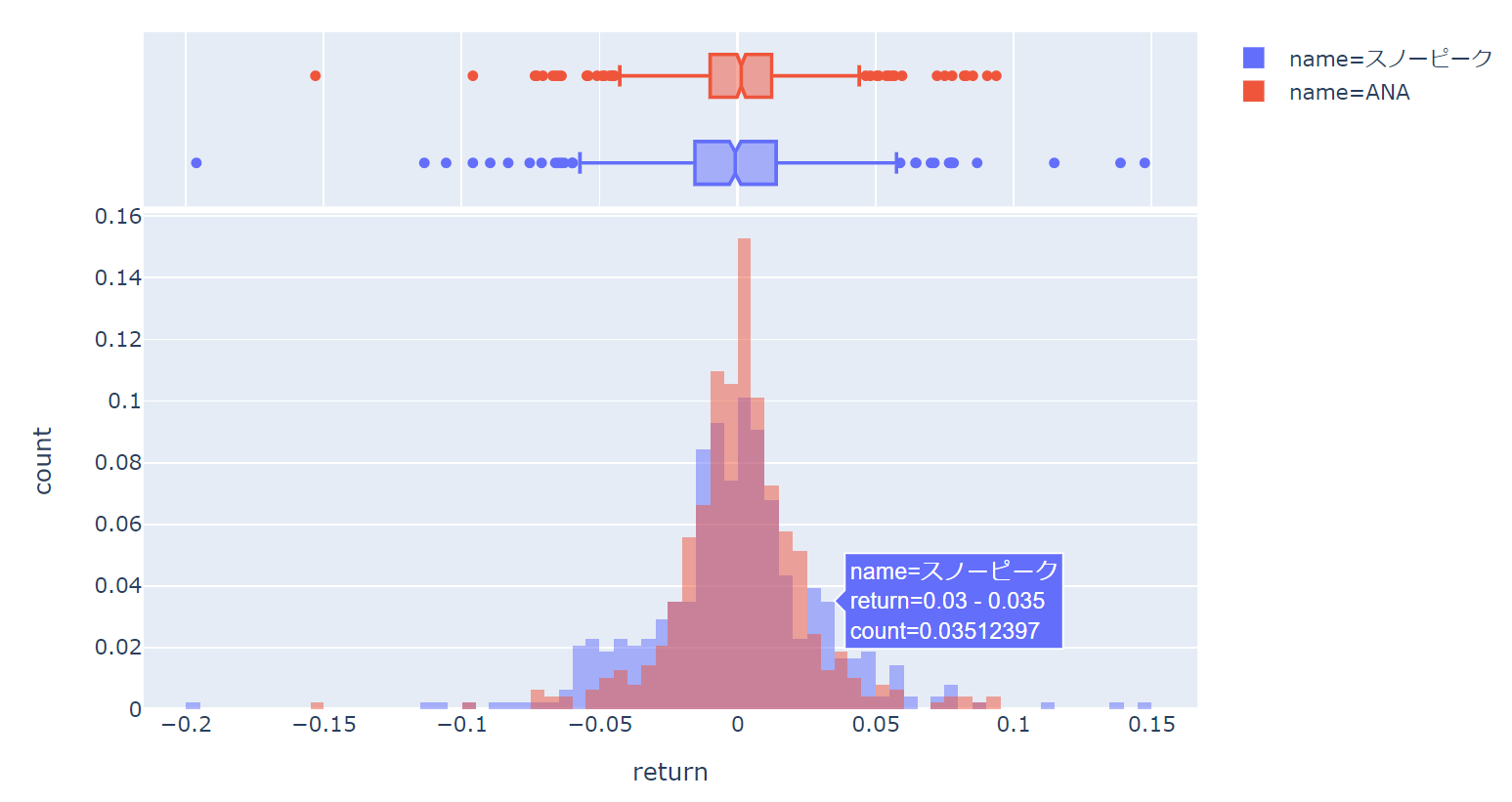
box plotの追加
上に参考情報としてbox plot(箱ひげ図)を描画することができます
px.histogram(df_vertical, x='return', color='name',
barmode='overlay', histnorm='probability',
marginal='box')
引数にmarginal="box"を追加します。
すると以下のようになります。
他にも、violin(violin plot)、rug(rug plot)などが指定できます。
plotly.graph_objectsを使ったヒストグラムの作成
続いて、plotly.expressではなくplotly.graph_objectsを使ってヒストグラムを作成する方法を解説します。
以下のようなデータがあるとします。
Date スノーピーク ANA 2019-06-04 -0.025937 -0.012038 2019-06-05 0.031803 0.018002 2019-06-06 0.009315 0.007344 2019-06-07 0.009946 -0.005670 2019-06-10 0.012662 0.006245 ... ... ... 2021-05-25 0.008119 -0.007957 2021-05-26 -0.045638 0.029076 2021-05-27 0.005626 0.026111 2021-05-28 -0.005594 0.010444 2021-05-31 -0.009845 -0.002067
potly.graph_objectsでは、Histogram()を使います。
まず、potly.graph_objectsをインポートします。
import plotly.graph_objects as go
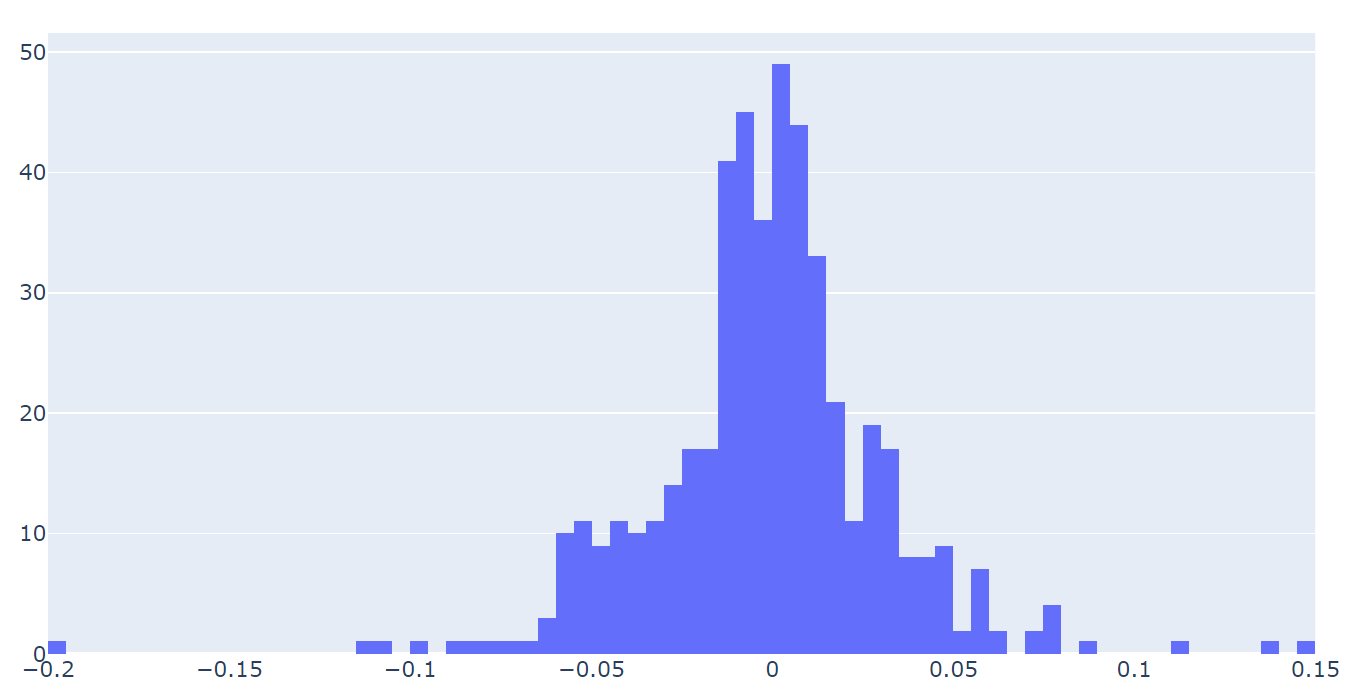
以下のようにgo.Histogram()でヒストグラムのデータを作成し、go.Figure()の引数として渡してやります。
data = go.Histogram(x=df['スノーピーク'], nbinsx=80) fig = go.Figure(data) fig.show()
ビンの数の設定はnbinsxで指定します(覚えにくいですよね…)。
複数データの表示
次に複数のデータのヒストグラムを作成します。
これも線グラフや散布図と同じで、データをリストの形で渡してやることで可能ですが、ここではadd_traceを使って行います。
データをどんどん追加していけるので便利です。
fig = go.Figure()
fig.add_trace(go.Histogram(x=df['スノーピーク'], nbinsx=80,
opacity=0.5, name='スノーピーク',
histnorm='probability'))
fig.add_trace(go.Histogram(x=df['ANA'], nbinsx=80,
opacity=0.5, name='ANA',
histnorm='probability'))
fig.update_layout(barmode='overlay')
fig.show()
以下のようなヒストグラムになります。
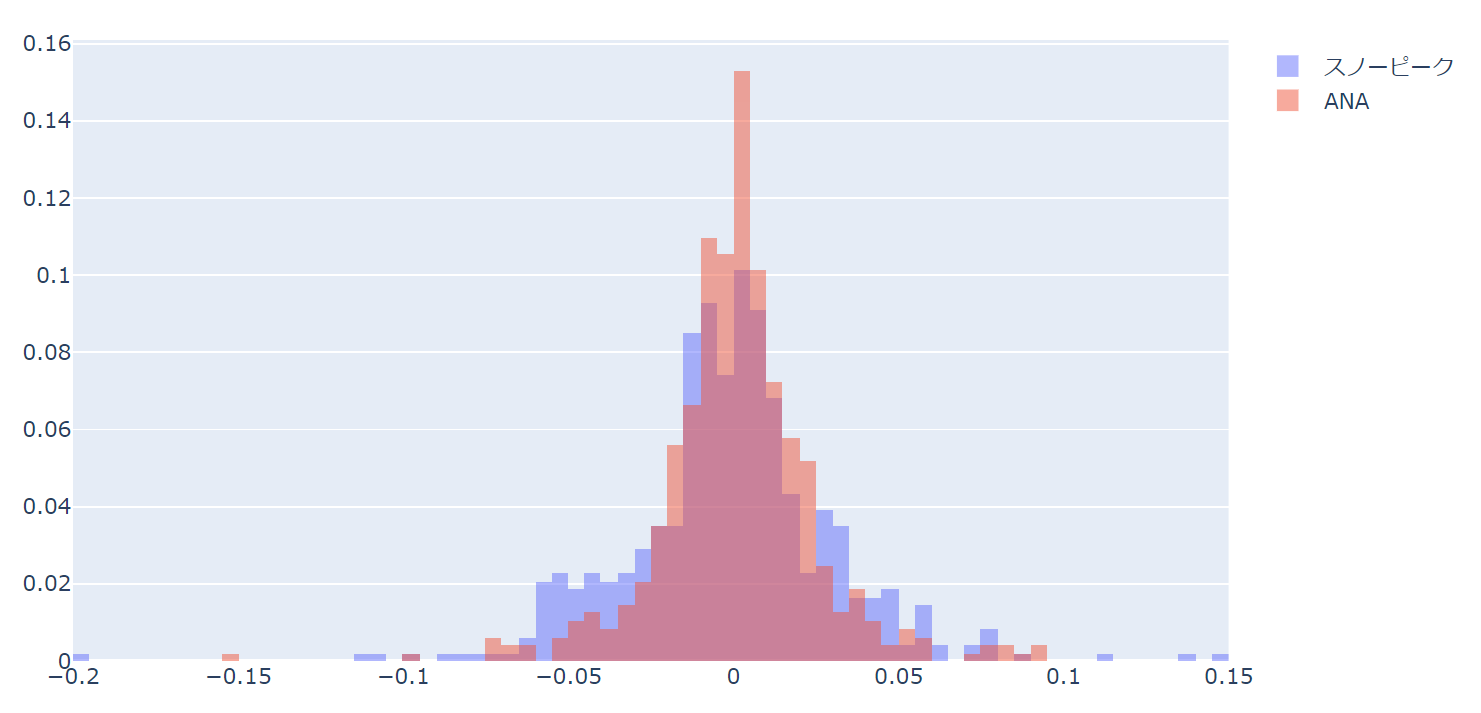
update_layoutでbarmodeをoverlayと指定しています。
これがないと、以下のグラフのように重ならないヒストグラムになります。
こちらの方がよければ、barmodeを指定しなくても大丈夫です。
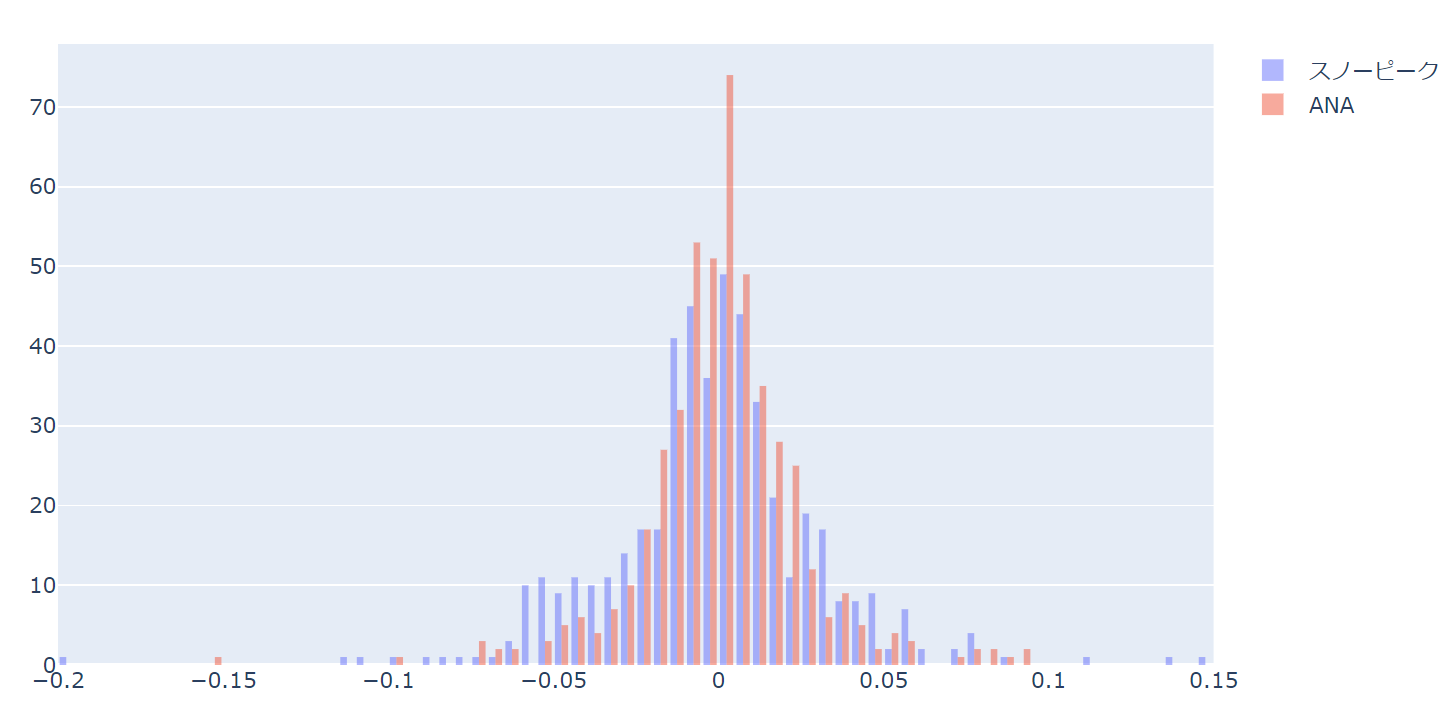
なお、add_traceでは各データ個別の設定だけを行い、共通の設定については以下のようにupdate_tracesでまとめて行うことで、個別に設定する必要がなくなります。
fig = go.Figure() fig.add_trace(go.Histogram(x=df['スノーピーク'], name='スノーピーク')) fig.add_trace(go.Histogram(x=df['ANA'], name='ANA')) fig.update_traces(nbinsx=80, opacity=0.5, histnorm='probability') fig.update_layout(barmode='overlay') fig.show()
binの設定
ビンの数を設定する場合はnbinsxでしたが、ここではビンの範囲、刻みを指定して作成します。
例えば、大きな外れ値があるデータだと以下のようになってしまいます。
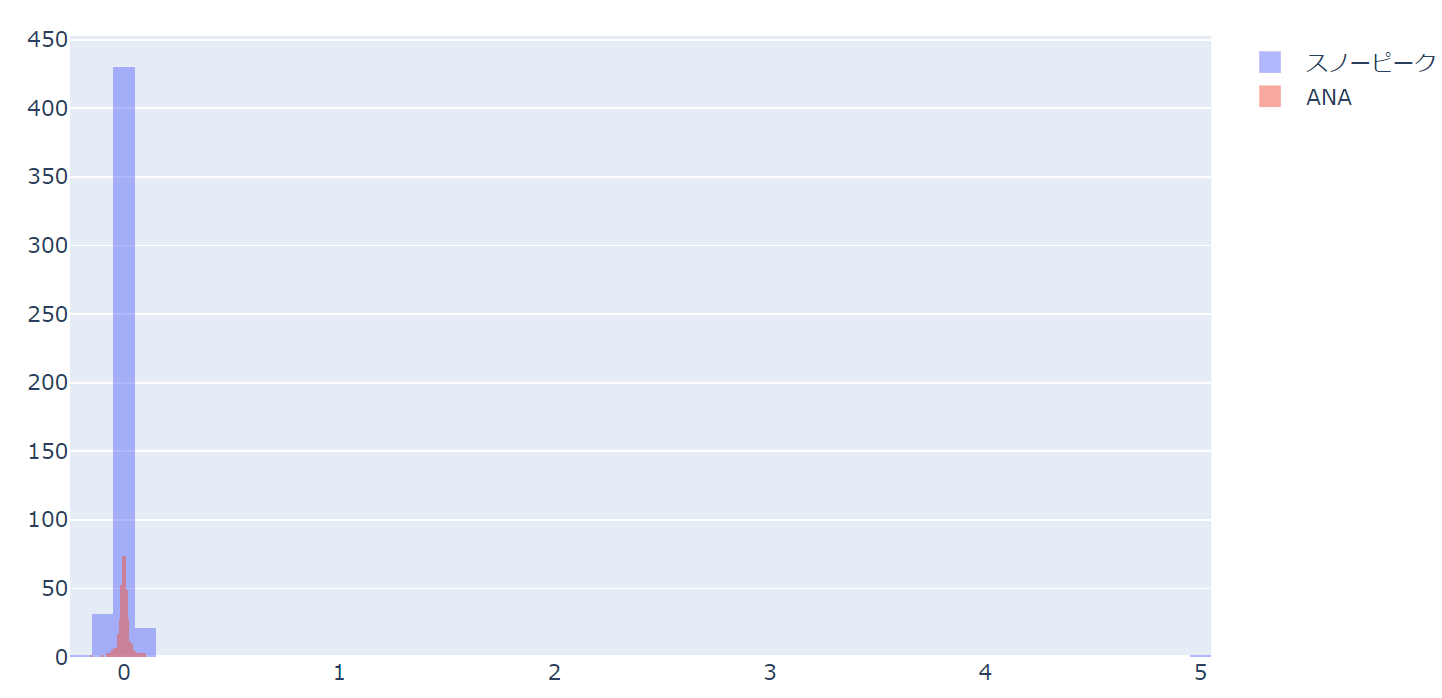
もちろん、これで異常値に気づくことができますが、異常値でない場合は、そのほかの部分の分布が見たくなる場合もあります。
その場合は、xbinsに辞書形式でstart、end、sizeを指定することで対応できます。
fig = go.Figure()
fig.add_trace(go.Histogram(x=df['スノーピーク'], name='スノーピーク'))
fig.add_trace(go.Histogram(x=df['ANA'], name='ANA'))
fig.update_traces(xbins=dict(start=-0.15,
end=0.15,
size=0.005),
opacity=0.5)
fig.update_layout(barmode='overlay')
fig.show()
これでうまく、外れ値は一番上もしくは一番下のビンに入れてくれます(python側でデータをいじる必要がありません)。
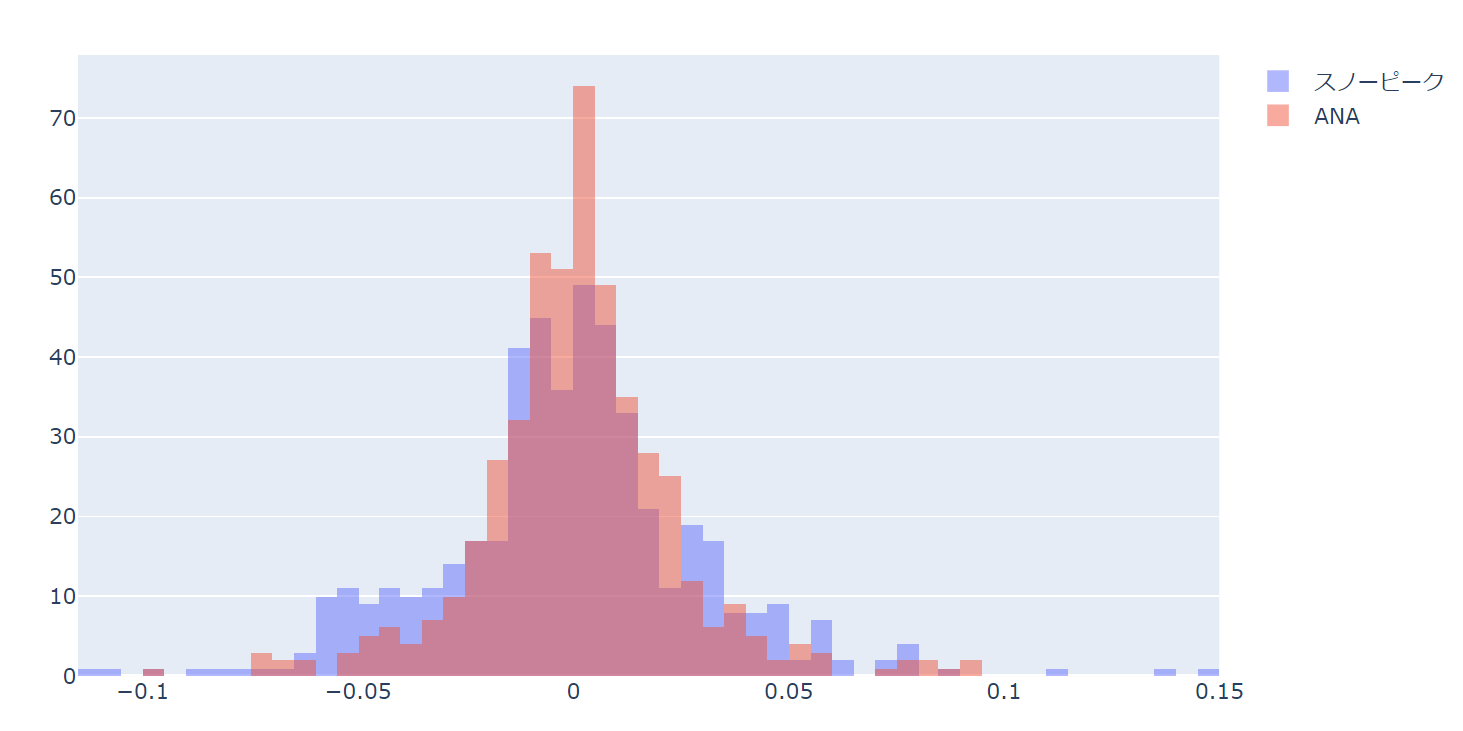
その他
マーカーの色を変えたり、タイトルを付けたり、x軸、y軸のラベルを設定する方法は線グラフや散布図などと可能です。
好みに応じて、やりすぎないように肉付けしましょう。
fig = go.Figure()
fig.add_trace(go.Histogram(x=df['スノーピーク']*100,
marker=dict(color='#6495ed'),
name='スノーピーク'))
fig.add_trace(go.Histogram(x=df['ANA']*100,
marker=dict(color='#ff7f50'),
name='ANA'))
fig.update_traces(xbins=dict(start=-15,
end=15,
size=0.25),
opacity=0.5,
histnorm='probability'
)
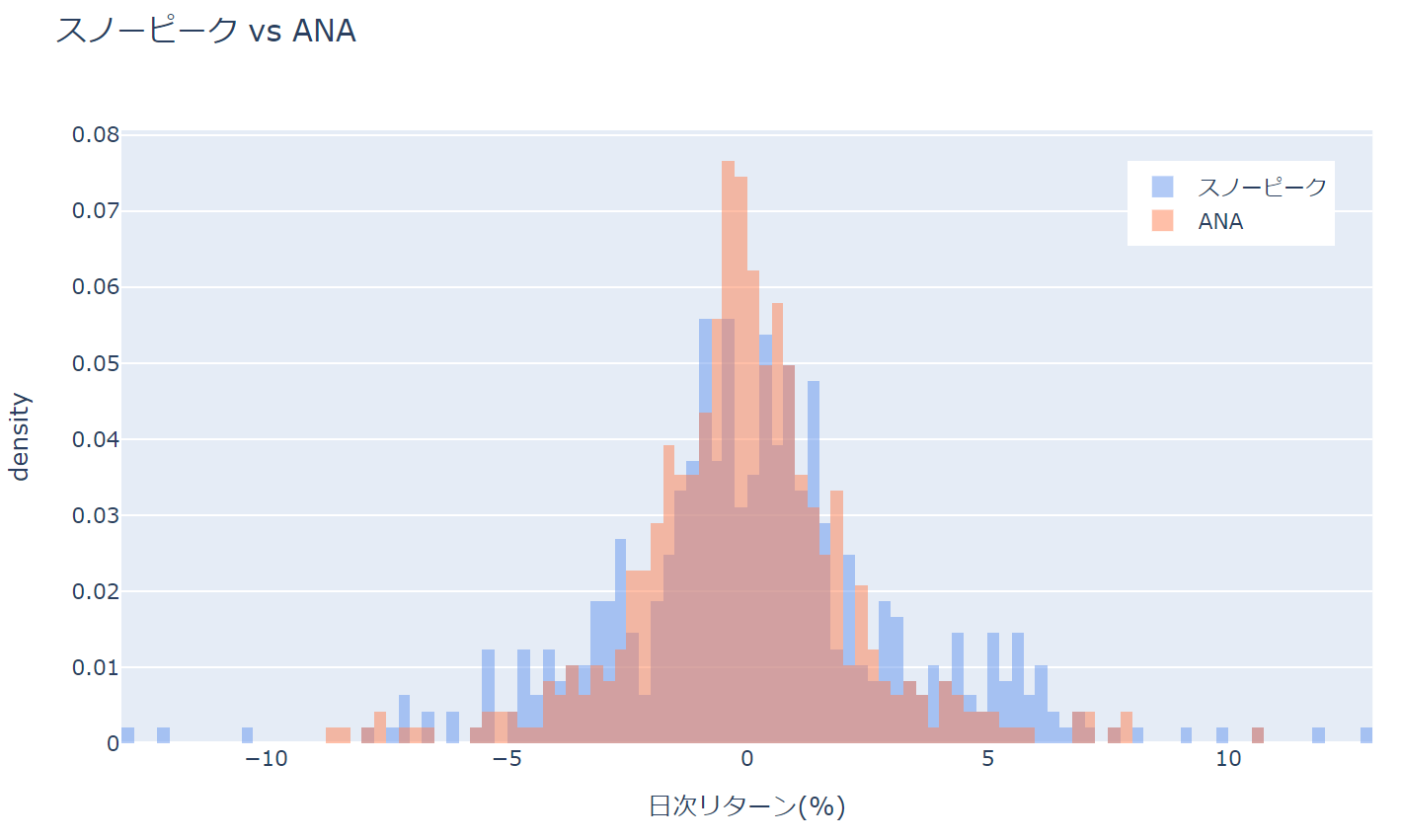
fig.update_layout(barmode='overlay',
title='スノーピーク vs ANA',
xaxis=dict(title='日次リターン(%)'),
yaxis=dict(title='density'))
fig.update_layout(legend=dict(yanchor="top",
y=0.95,
xanchor="right",
x=0.97))
fig.show()
fig.update_layout(legend=dict(...))として凡例の場所を変えています。
レイアウトの設定については別途詳しく解説したいと思いますが、xanchor、yanchorで原点を決め、そこから相対的な位置を指定します。
plotly.figure_factoryを使った分布のプロット
plotly.figure_factoryを使うと分布に対してカーネル密度推定を使ってフィッティングした結果を表示してくれます。
まず、plotly.figure_factoryをインポートします。
import plotly.figure_factory as ff
figure_factoryのcreate_displotというメソッドを呼び出します。
1つ目の引数はデータで、リストの形で渡してやります。
2つ目の引数はデータ名です。
あとは、bins_sizeでビンのサイズを指定しています。
fig = ff.create_distplot([df for c in df.columns], df.columns, bin_size=.0025) fig.show()
これだけで、以下のようなグラフが作成されます。
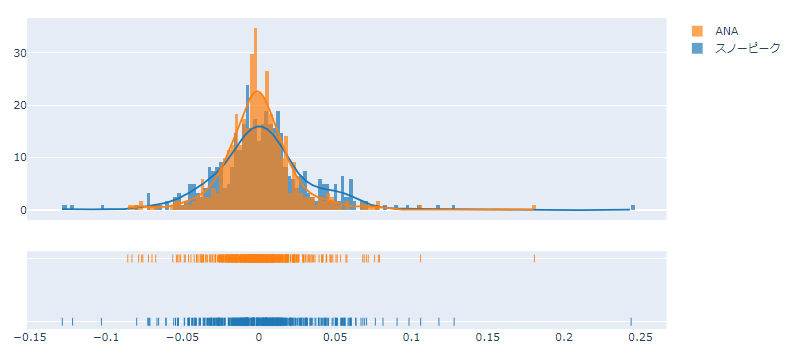
色を変えたりすることも当然可能です。
この場合はそれほどメリットは感じられないかもしれませんが、状況によっては分布のプロットがあった方が比較しやすいですね。
まとめ
今回はplotlyによるヒストグラムの作成方法を見てきました。
私はこれ以外にはあまり凝った使い方をしないので基本的な使い方の解説だけでしたが、他にも便利な設定があれば随時更新していきたいと思います。
次は棒グラフです!
