今回はテキスト分類や文章のセンチメント分析でよく使われるBag-of-Wordsという手法を紹介したいと思います。
Bag-of-Wordsは直観的にわかりやすいモデルで、問題によってはより複雑なモデルと遜色のない精度が出ることもあるので、是非理解しておきましょう!
Bag-of-Wordsとは
Bag-of-Wordsを簡単にまとめると
- 文章の単語(words)をぐちゃっと袋(bag)に入れるモデル
- 単語の出現回数をもとに分類・評価を行う
- 単語の順番は考慮しない
- 出現回数そのものでなく、TF-IDFといった手法を用いて単語の重みを調整する方法もある
簡単に言うと、単語の順番は考慮せずに、単語の出現回数のみを考慮するモデルです。
Bag-of-Wordsという名前は、単語(words)を袋やカバン(bag)にぐちゃっと入れてモデル化することに由来しています。

簡単な例を見てみましょう。例えば、
① 「ここのスタッフは非常に親切でした。」
②「 トイレが少し汚かったのが残念なところです。 」
③「ここのスタッフは非常に親切でした。ただ、トイレが少し汚かったのが残念なところです。」
という3つの文章があった場合、まずこれを単語に分割して、出現回数を計算します。
| ここ | スタッフ | トイレ | 非常に | 少し | 親切な | です | 汚い | 残念な | |
|---|---|---|---|---|---|---|---|---|---|
| ① | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| ② | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| ③ | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 |
元の文章を読まなくても、
①は 「非常に」「親切な」という単語が出ていますので何となく 良いイメージ
②は 「汚い」や「残念な」といった単語から、悪いイメージ
③は両方出てきているのでどっちとも言えないかな
ということがわかると思います。
ですので、センチメント分析では 、この出現回数を特徴量として、ナイーブ・ベイズ、SVM(Support Vector Machine)、ロジットモデルといった分類器に投入します。
ここでは分類器についての解説は行いませんので、一般的な機械学習の本(最後に紹介しています)やサイトで勉強していただければと思います。
さてここで、単純な疑問として以下が出てくるかもしれません。
- ③で一番よく出てくる単語は「です」だけど大丈夫?
- ③ではスタッフは「非常に」親切なのか「少し」親切なのかわからない!
同様にトイレが「非常に」汚いのか、「少し」汚いのかわからない!
これらの項目について、ある程度解決する方法がありますので、次で説明したいと思います。
TF-IDF(Term Frequency - Inverse Document Frequency)
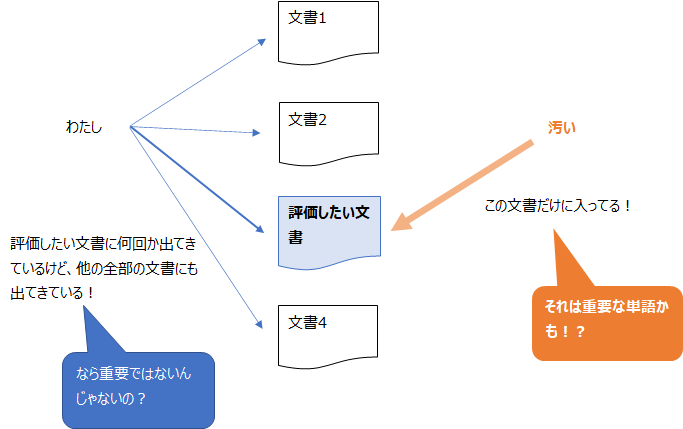
先ほど「③で一番よく出てくる単語は「です」だけど大丈夫?」という疑問を挙げましたが、これに対応する方法がTF-IDF(Term Frequency - Inverse Document Frequency)です。
TF-IDF とは
- どの文章にもよく出てくる単語の重要度は下げて、あまり出てこない単語の重要度を上げるための工夫です。
- TF-IDFは、「単語の出現回数(=TF)」に「その単語が出現する文書数(DF)」で割ることで単語の出現回数に調整を加えるイメージです。
どの文章にもよく出てくる単語というものがあります。
例えば「私」や「です」などです。
こういった単語は、感情にはあまり関係ありませんよね?
ですので、どの文章にもよく出てくる単語の重要度は下げて、あまり出てこない単語は感情などの特徴を表していることが多いということで、そう言った単語の重要度を上げることを考えます。
それが TF-IDF です。
TFはTerm Frequency(逆文書頻度)の略で単純に「単語の出現回数」です。
前に見たものと同じです。
IDFはInverse Document Frequency(文書頻度の逆数)の略で、言ってみれば、その単語が出てくる「ドキュメントの数の逆数」です。
(カッコ内の日本語は、そちらの方がイメージが湧きやすいかと思って個人的に訳したものですので、覚えない方が良いかもしれません。)
色々な定義の仕方がありますが、一般的な形は以下のようになります。
$$\text{idf}(t)=\log\frac{n}{1+\text{df}(t)}$$
\(\text{df}(t)\)はその単語の出現する文書数を表し、\(n\)はすべての文書数です。
つまり、その単語がたくさんの文章に出現していれば、IDFはその逆数なので(分母が大きくるため)小さくなり、めったに出てこない単語であればIDFは大きくなるというものです。
分母に1を足しているのは、単に分母がゼロにならないようにするためのもので、logは出現回数が少ない単語の重みを減らす(ならす)ための工夫と考えていただいても大丈夫です。
ですので、logや1を除いてざっくり書くと、IDFはその単語が出現する文書の全体に対する割合の逆数と見ることができます。
$$\text{idf(t)}\simeq\frac{\text{すべての文書数}}{\text{単語}t\text{が出現する文書数}}$$
TF-IDFはそれらを掛け合わせたものなので、その単語の出現回数を全体の文章の頻度で割ってやることで頻出単語の重みは小さくするように調整します。
$$\begin{align}\text{TF-IDF} &= \text{Term Frequency} \times \text{Inverse Document Freqency}\\
&=\frac{\text{単語}t\text{の出現回数}}{\text{単語}t\text{の出現する文書の全体に対する割合}}\end{align}$$
n-gram
n-gram とは
- いくつの単語をひと固まりとするか。
- 1-gramであれば1つの単語、2-gramであれば2つの単語をひと固まりとする。
- 2-gram以上にすることで、単語のつながりを理解することができる。
- あまり多くしすぎると語彙数が増えてしまい、精度が落ちることもある。
では、次に二つ目の疑問点を解決する方法を考えましょう。
まず、理解しておきたいのが、Bag-of-Wordsは基本的に単語の順番は考慮しない、ということです。
ですので、何が「丁寧なのか」、何が「汚い」のかの判断は難しく、単に「汚い」という単語が多いと、例えば評価を悪くするというものになります。
ただし部分的に単語の順番を考慮することが可能です。
それがn-gramです。n-gramとは、いくつの単語をひと固まりとするか?というものです。
例えば、1-gram(unigramとも言います)では一つの単語をひと固まりとするので前述の分け方は1-gramになります。
2-gram(bigram)は二つの単語をひと固まりとするので、先ほどの
「ここのスタッフは非常に親切でした。ただ、トイレが少し汚かったのが残念なところです。」
という文章であれば、1-gramであれば、
「ここ」「スタッフ」「非常に」「親切」「です」「トイレ」「少し」「汚い」「残念」「ところ」「です」
が、がばっと袋に入ります。
でしたが、2-gramでは、
「ここ スタッフ」「スタッフ 非常に」「非常に 親切」「親切 です」「です トイレ」「トイレ 少し」「少し 汚い」「汚い 残念」「残念 ところ」「ところ です」
が、がばっと袋に入ります。
つまり、この場合、例えば「どれぐらい親切だったのか?」、「どれぐらい汚いのか?」がわかるようになり、少しだけ文脈がわかるようになりましたね。
それにより、モデルの精度も良くなることが期待されます。
同様に3-gram(trigram)であれば三つの単語をひと固まりとします。
ただし、細かくすればいいというものでもなく、細かすぎる場合、ボキャブラリーの数が一気に増えてしまい、モデルが複雑になってしまいます。
また、学習用データに出てこないテストデータの表現が増えてしまい、学習用データでは高精度が出るけどテストデータでは精度が低くなってしまう(オーバーフィッティングする)ことがあります。
ですので、何gramがいいかは問題設定やデータ量を見て色々試しながら決めていくことになります。
以下の論文では、センチメント分析において、bigramはすべてのデータセットでunigramより良い結果を出したことが報告されています。
https://www.aclweb.org/anthology/P12-2018/
まとめ
Bag-of-Wordsは非常にシンプルなモデルだということがお分かりになったのではないでしょうか?
しかしながら、なかなかの精度を出すこともありますので、手っ取り早く作成し、ベースラインとしてはうってつけだと思います。
以下の投稿では、実際にBag-of-Wordsを使って分析やモデルの評価をしていますので、是非ご覧ください!!
単語の分析をしてみると結構楽しいので、ご自身でも一度遊んでみることをお勧めします。
https://data-analytics.fun/2020/03/06/nap-analysis-2/
より深く学びたい方は以下の本を参考にしてみてください。
[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)
自然言語処理の前にロジスティック回帰やサポート・ベクター・マシン、ニューラル・ネットワークの解説があり、応用例としてBag-of-Wordsなどの解説があります。
Bag-of-Wordsの前に機械学習からしっかりと理解したい方向けです。
Pythonのコードが載っていて、実際に手を動かしながら学べるのでオススメです。
Webアプリケーションを作成する章もあります。
ゼロから作るDeep Learning ❷ ―自然言語処理編
Bag-of-Wordsは載っていませんが、手を動かして自然言語処理の基礎を理解することができる良本です。
TensorflowやPyTorchといったライブラリは使用せず、Pythonを使ってスクラッチでモデルを構築していきます。
Word2VecやRNN、LSTMといった自然言語処理の理解には不可欠なモデルが丁寧に解説されています。
非常にわかりやすく、これから自然言語処理を学びたいという方に最適の本です。
Udemy
まったく知らない分野の本をいきなり読むのは大変ですので、もっと気軽にてっとり早く理解したい方は、UdemyのようなMOOCがおすすめです。
通勤時間を使ったり、寝る前や朝一番に20分だけ動画を見て勉強するということも可能ですので、無理なく続けることができます。
割引セールは是非利用したいところですね。
自然言語処理の日本語講座ではこちらの講座をオススメしています。
